数据解析-bs4库使用之红楼梦全文文本爬取
Ps :参考博文 https://blog.csdn.net/qq_38330148/article/details/114004478?spm=1001.2014.3001.5501
一、需求分析
- 需求:
- 使用bs4库进行实战,对诗词名句网的红楼梦小说文本内容进行爬取,包括每一章的标题和内容,并将所有内容保存到本地文本文件中;
- 分析:
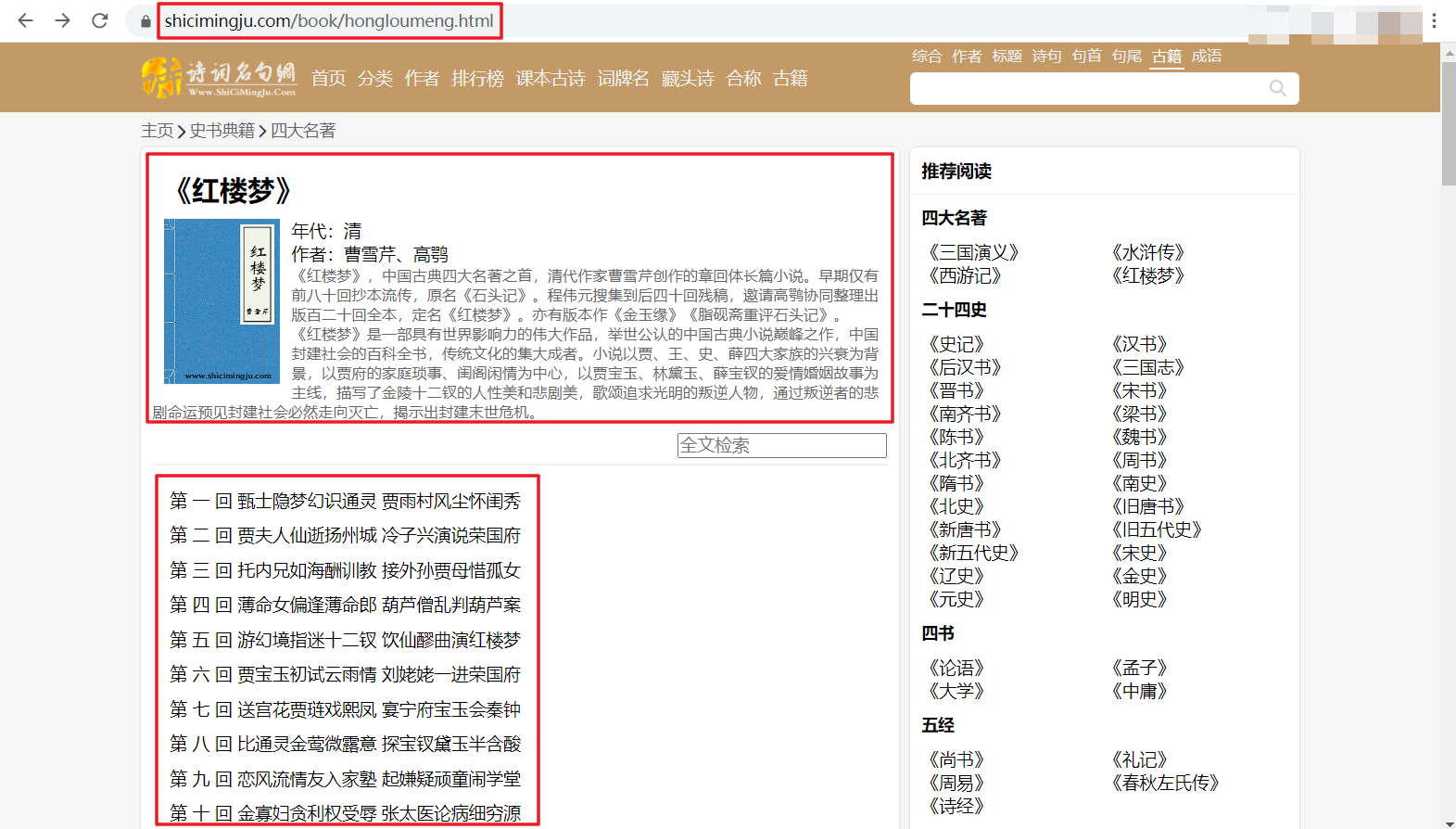
1、首先,我们通过https://www.shicimingju.com/book/hongloumeng.html进入诗词名句网的红楼梦小说主页,如下图所示。其中包含每一章的标题信息,同时我们需要每个章节对应的内容。查看页面源码,会发现,每一个标题标签对应着一个url链接,这样我们只需对此页面内所有章节的链接提取即可获得每一个章节对应的页面。
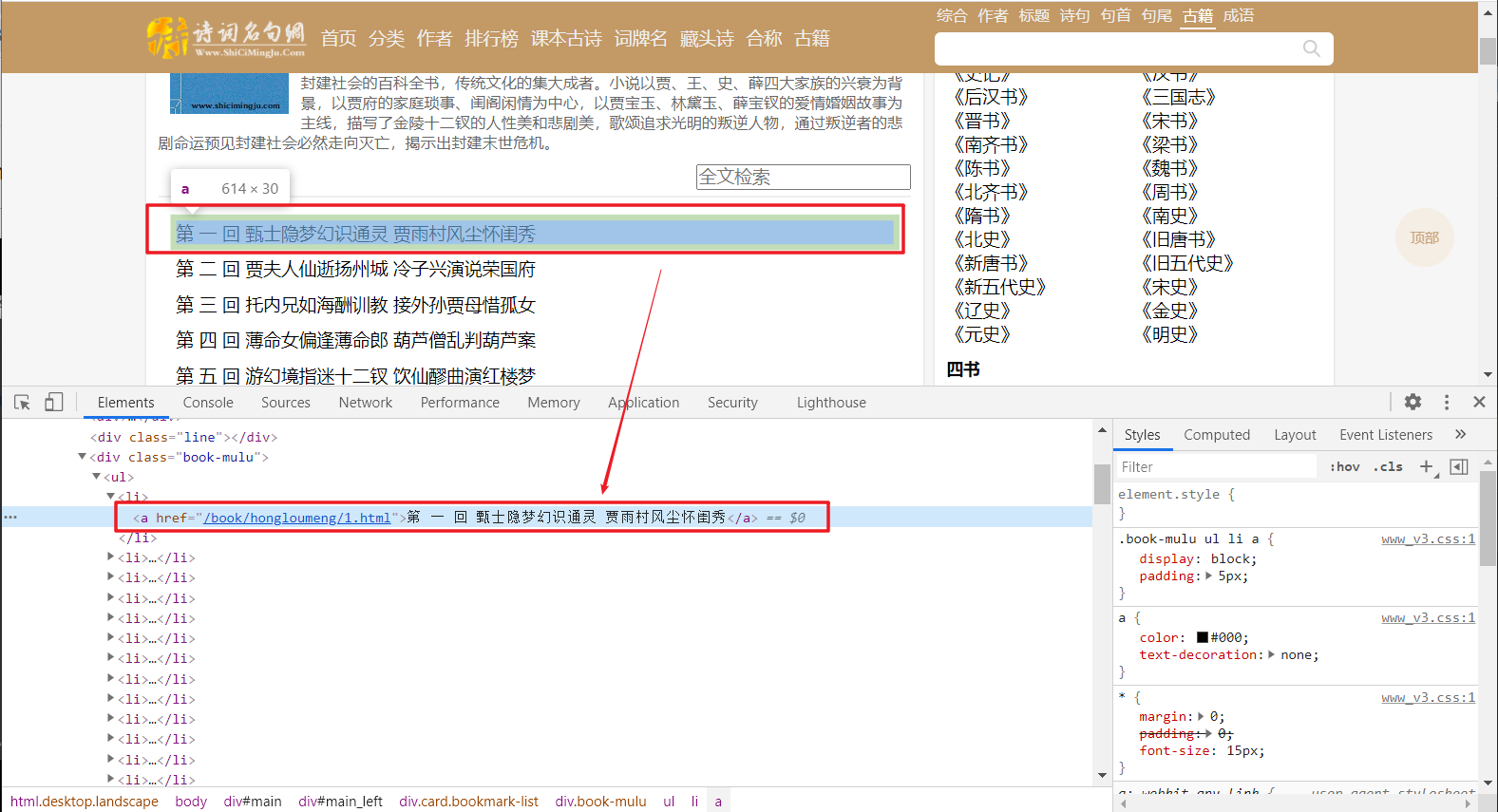
2、打开对应链接,发现章节内容即在源码中,我们对对应标签的文本信息进行提取即可。
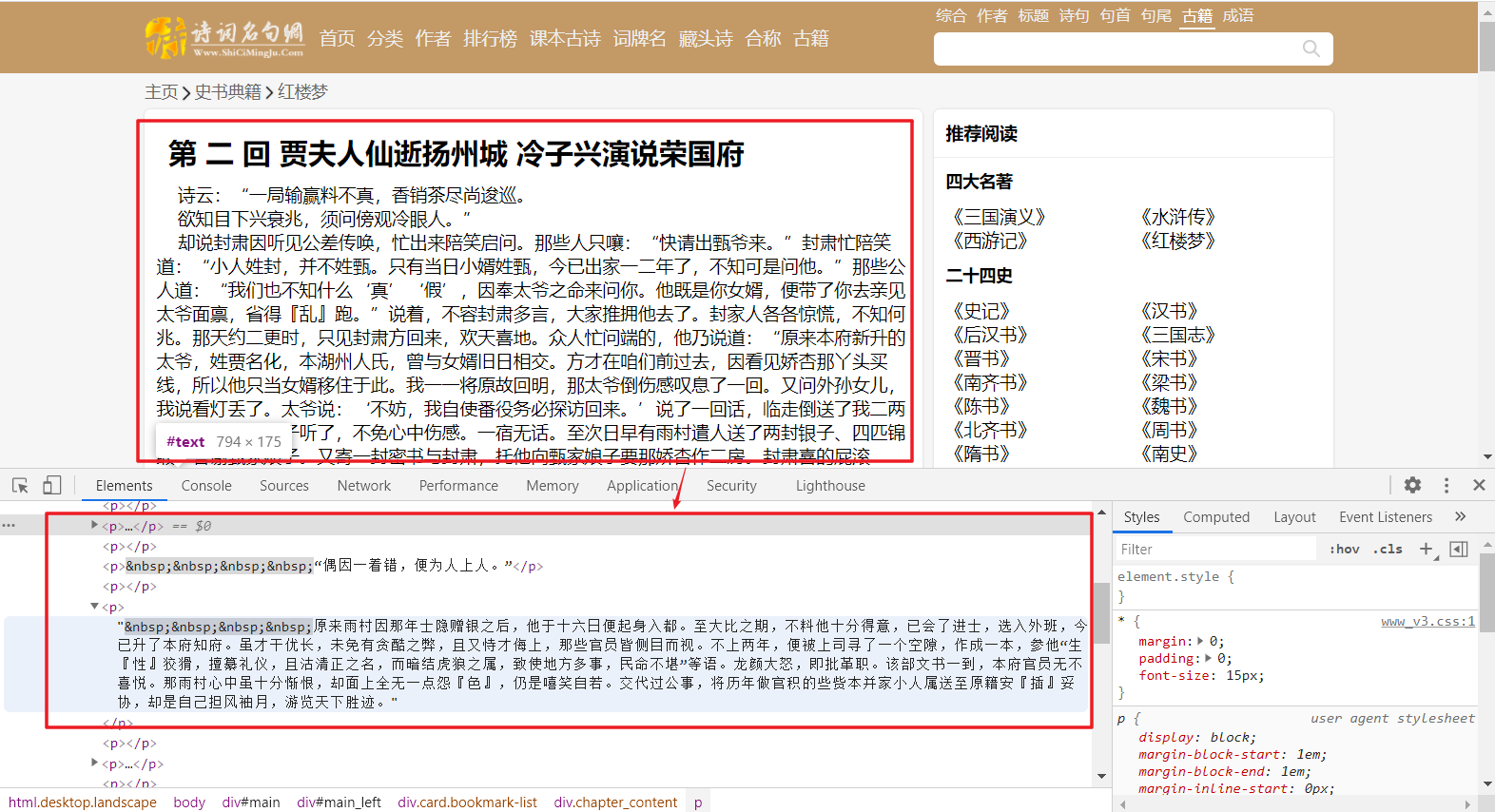
3、- 打开开发者模式,可以发现每一个章节对应的url其实就是索引号不同,很方便即可获取。
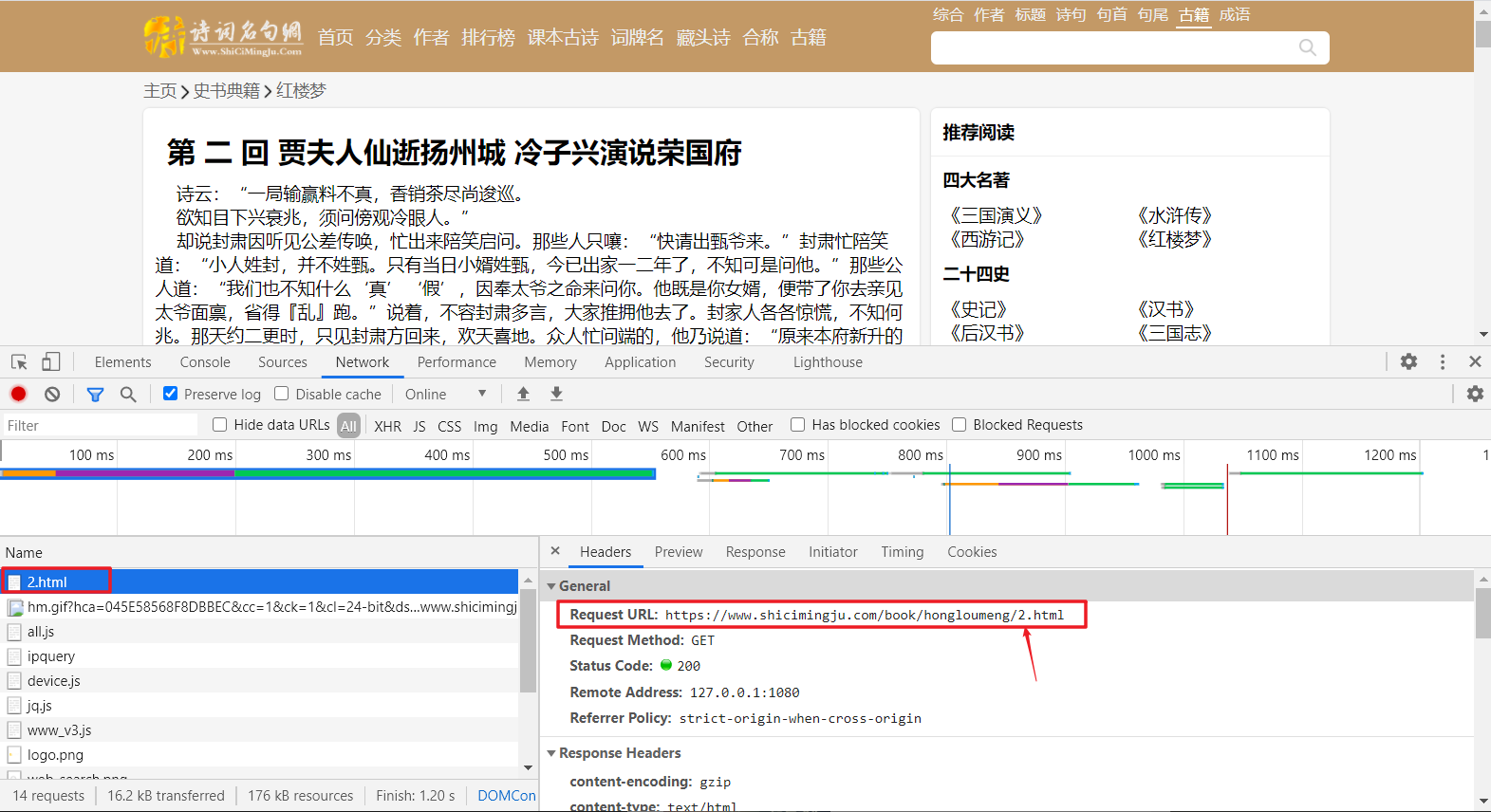

4、关键点在于使用bs4库对每个章节的对应链接进行提取,并访问对应页面,对页面中的章节内容进行提取即可。
二、红楼梦全文文本爬取编码
- 编码
# coding : utf-8
# fun : 爬取红楼梦小说所有的章节标题和章节内容 https://www.shicimingju.com/book/hongloumeng.html
import requests
import json
from bs4 import BeautifulSoup
def book_spider(url):
"""
爬取红楼梦文本信息
:param url: 网站url
:return:
"""
# 1.指定url
url = url
# 2.UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
# 3.发送请求&获取响应数据
page_text = requests.get(url=url, headers=headers)
page_text.encoding = page_text.apparent_encoding # 获取编码
page_text = page_text.text
# 4.对text页面进行章节标题文本提取并获取每个章节对应的url链接
soup = BeautifulSoup(page_text, 'lxml')
aTagList = soup.select('.book-mulu li > a') # 获取a标签信息
titleList = [i.text for i in aTagList] # 获取a标签中的文本信息
urlList = [i["href"] for i in aTagList] # 获取s标签中每个章节的url
# 5.保存章节内容
with open('./红楼梦.txt', 'w', encoding='utf-8') as fp:
fp.write("红楼梦\n") # 写入标题
for chp in zip(titleList, urlList):
write_chapter(chp)
print("已成功下载红楼梦全文!")
def write_chapter(content_list):
"""
将每章节信息提取并写入txt文本
:param content_list:
:return:
"""
# 获取标题和链接
title, url = content_list
intact_url = "https://www.shicimingju.com" + url
# UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
# 发送请求&获取响应信息
page_text = requests.get(url=intact_url, headers=headers, timeout=10)
page_text.encoding = page_text.apparent_encoding # 获取编码
page_text = page_text.text
# 构建soup对象进行解析文本
soup = BeautifulSoup(page_text,'lxml')
content = soup.select('.chapter_content')
txt = "" # 构建文本字符串
for i in content:
txt += i.text
# 持久化存储
with open('./红楼梦.txt', 'a', encoding='utf-8') as fp:
fp.write(title+'\n') # 写入标题
fp.write(txt+'\n') # 写入章节内容
# print("已成功下载{}内容".format(title.split('·')[0]))
print("已成功下载内容:{}".format(title))
if __name__ == '__main__':
# 指定url
url = "https://www.shicimingju.com/book/hongloumeng.html"
# 爬取文本信息
book_spider(url)
- 执行结果
已成功下载内容:第 一 回 甄士隐梦幻识通灵 贾雨村风尘怀闺秀
已成功下载内容:第 二 回 贾夫人仙逝扬州城 冷子兴演说荣国府
已成功下载内容:第 三 回 托内兄如海酬训教 接外孙贾母惜孤女
已成功下载内容:第 四 回 薄命女偏逢薄命郎 葫芦僧乱判葫芦案
已成功下载内容:第 五 回 游幻境指迷十二钗 饮仙醪曲演红楼梦
已成功下载内容:第 六 回 贾宝玉初试云雨情 刘姥姥一进荣国府
已成功下载内容:第 七 回 送宫花贾琏戏熙凤 宴宁府宝玉会秦钟
已成功下载内容:第 八 回 比通灵金莺微露意 探宝钗黛玉半含酸
已成功下载内容:第 九 回 恋风流情友入家塾 起嫌疑顽童闹学堂
已成功下载内容:第 十 回 金寡妇贪利权受辱 张太医论病细穷源
....
向往的地方很远,喜欢的东西很贵,这就是我努力的目标。

