数据解析-正则表达式之糗事百科图片爬取
Ps :参考博文 https://blog.csdn.net/qq_38330148/article/details/113980923
一、需求分析
-
需求 :
大概了解了爬虫中的页面数据解析方法,包括正则表达式、bs4库和xpath方法,并对其中的正则表达式基本语法进行了案例穿插的详细讲解;这一节我们便在聚焦爬虫的页面数据爬取实战中使用正则表达式。这一节的目标是对糗事百科网站: -
分析 :
1、首先,我们通过url:https://www.qiushibaike.com/ 进入糗事百科首页,然后点击左边的热图,我们便可以看到页面上出现大量的图片,而我们的目的就是对这些图片进行爬取并保存。
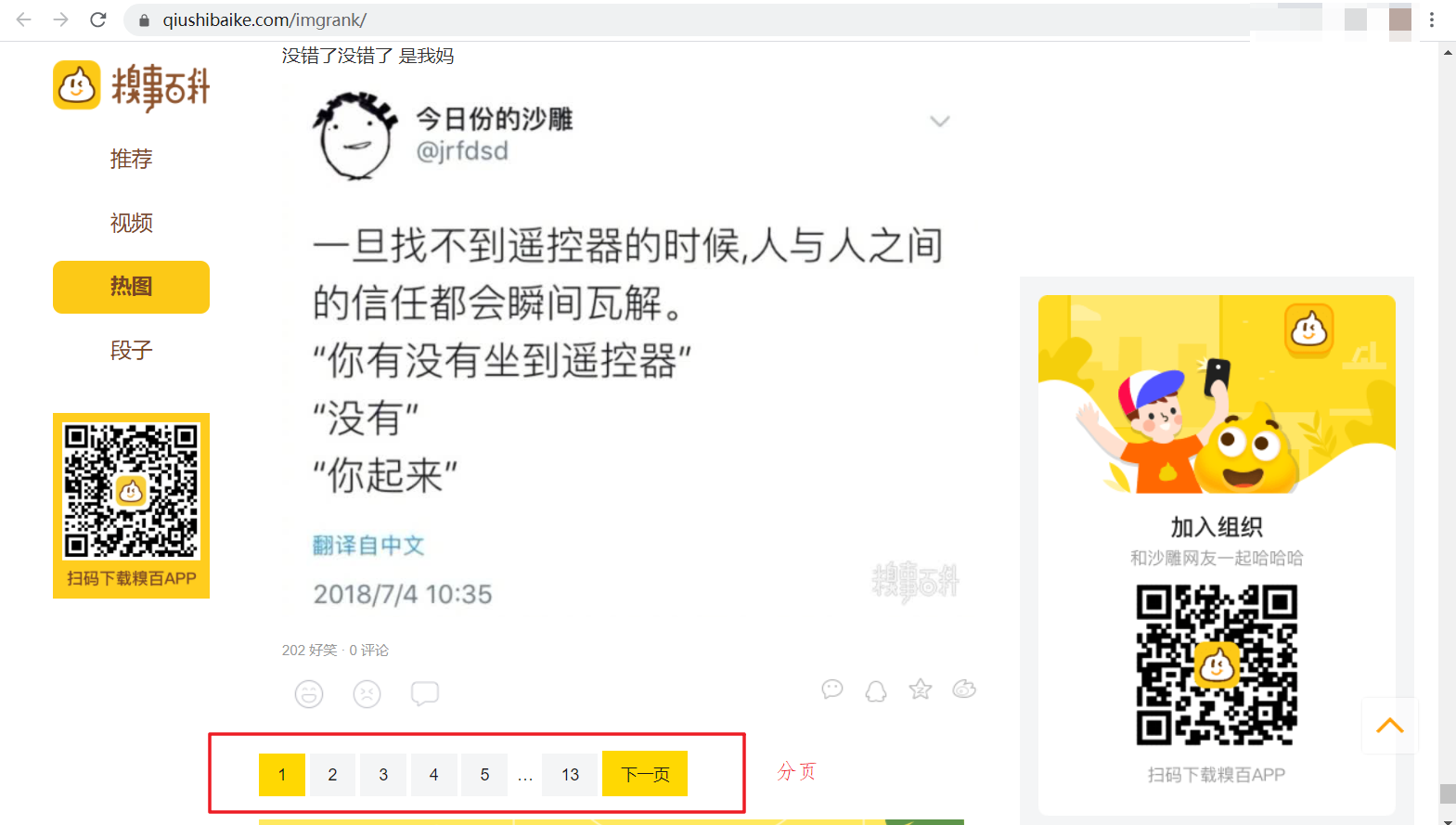
2、我们将页面滚轮拉到底部,会发现还有分页显示,那我们待会便可通过命令行输入需要爬取的页数分别对不同页数进行爬取。
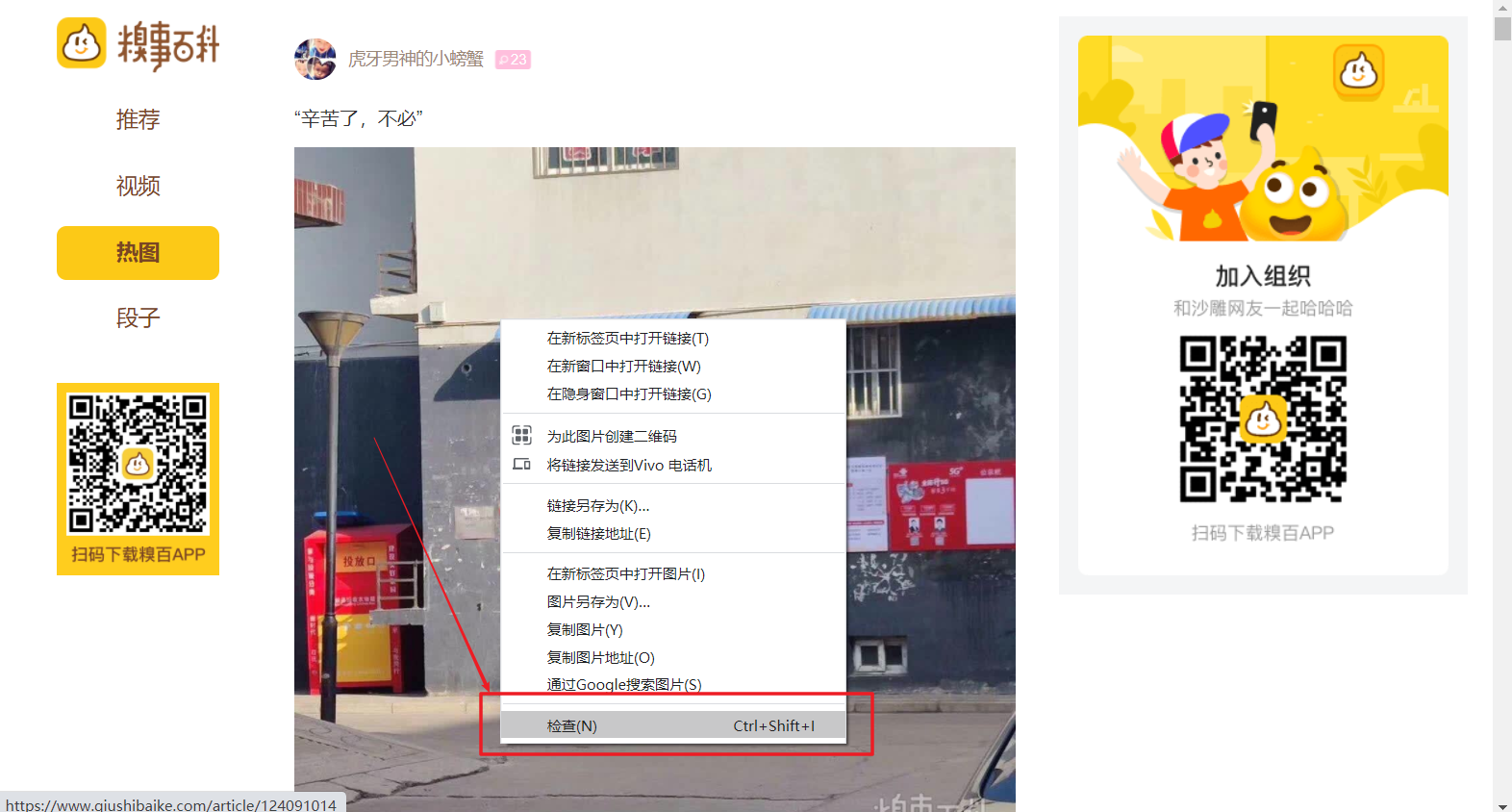
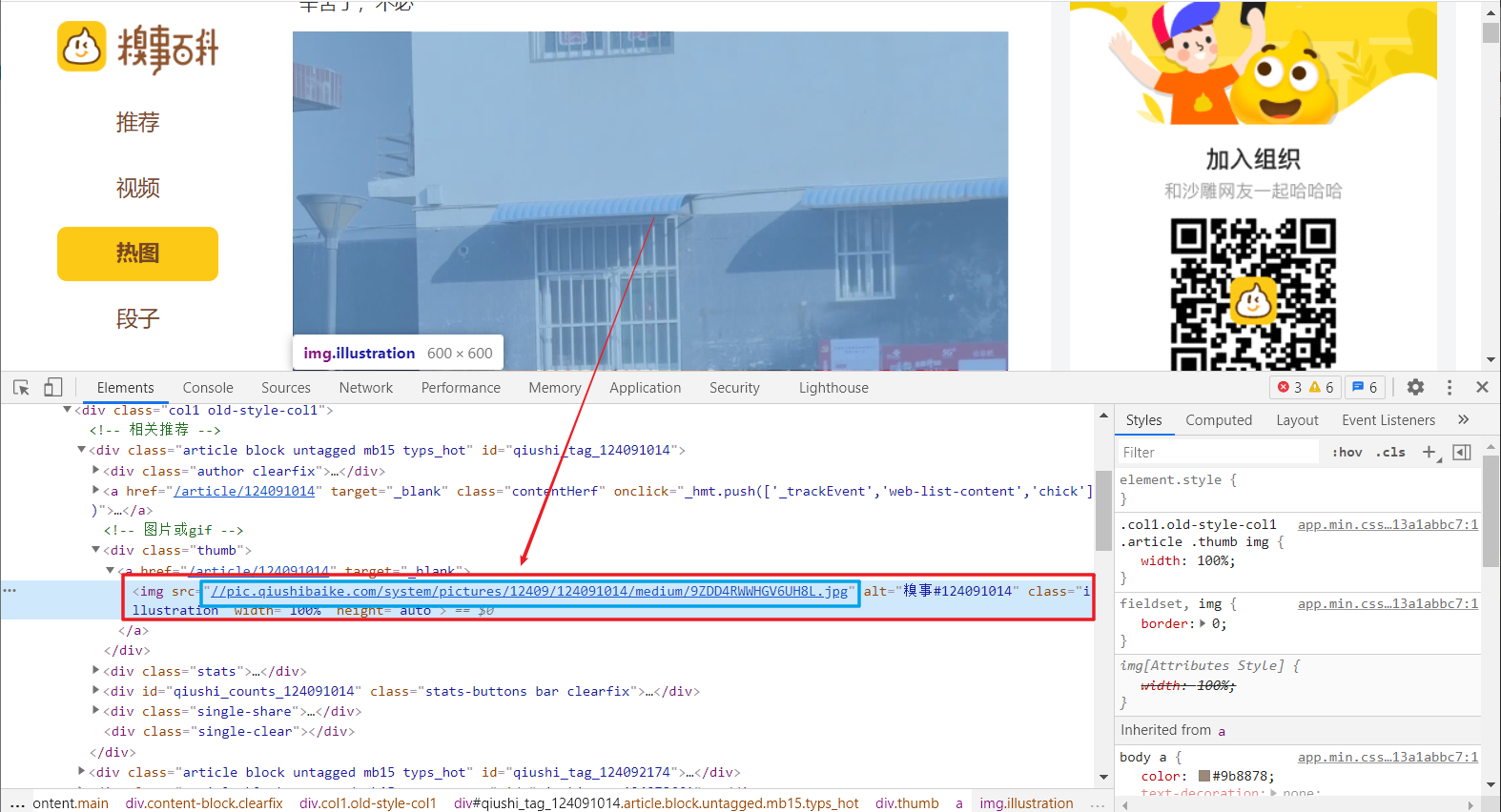
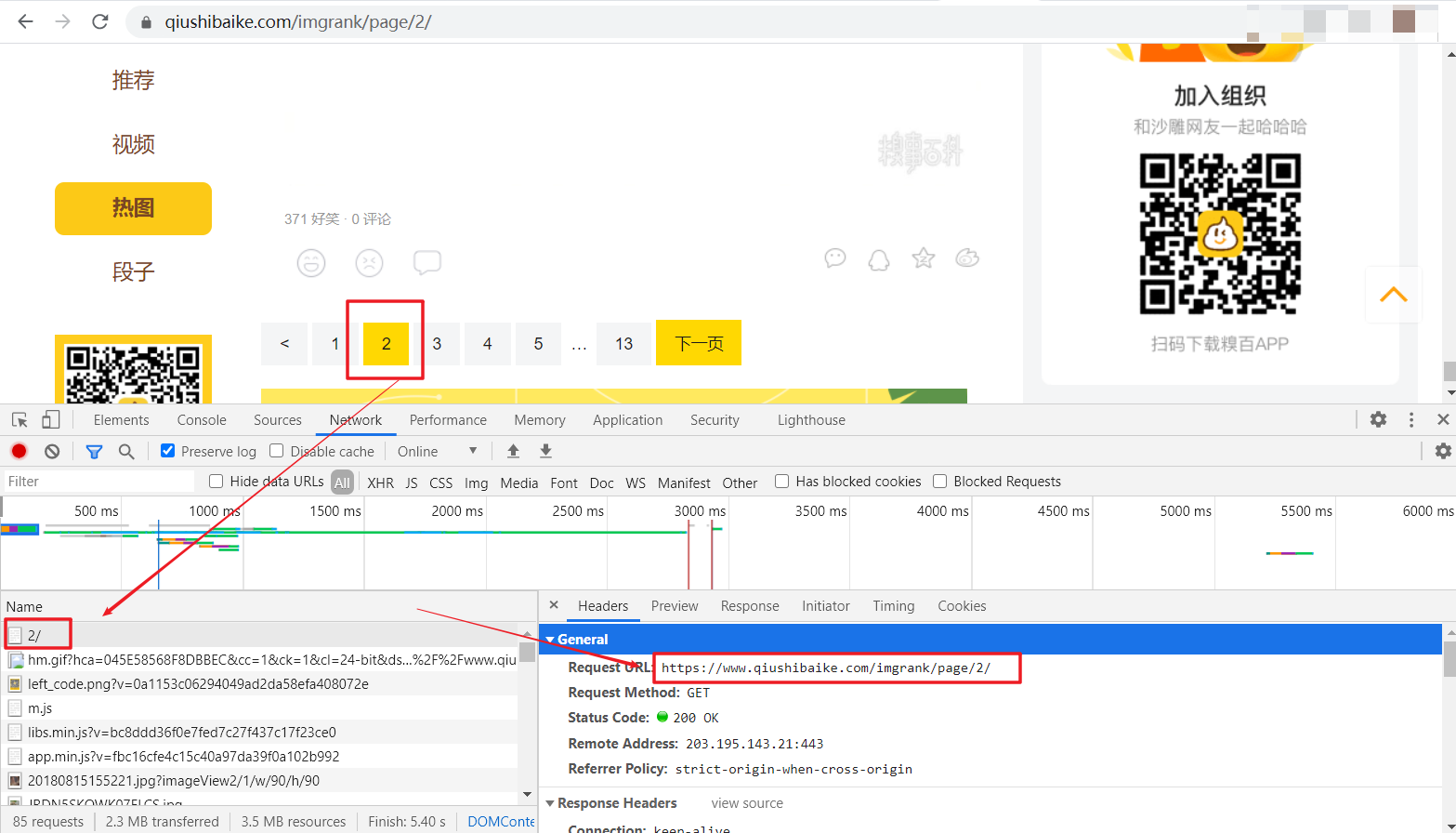
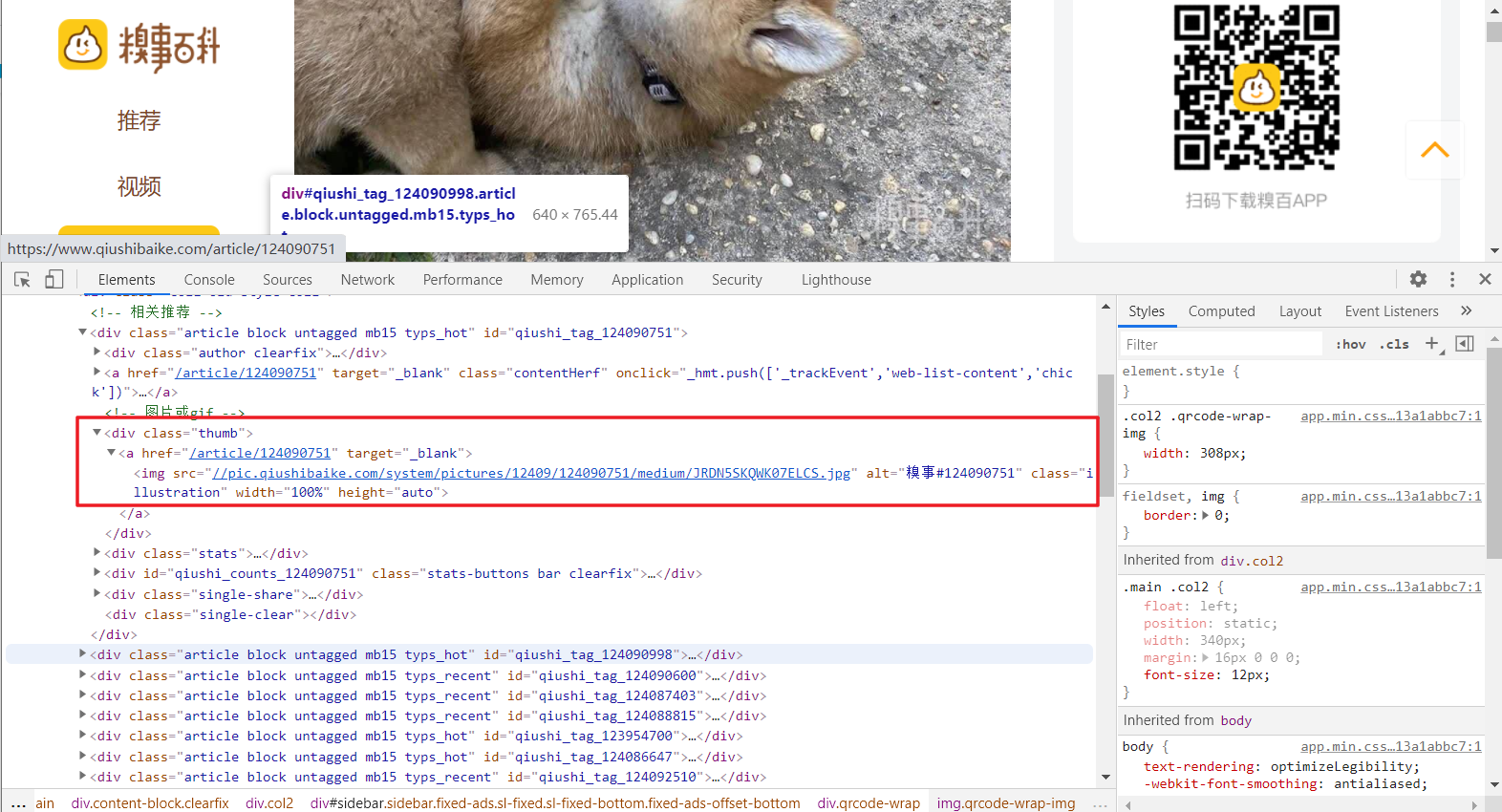
3、首先我们需要考虑的是如何将每一页所有图片的地址链接进行解析爬取,那就需要进行页面源码解析了。鼠标右键单击某张图片,可以看到出现检查选项,点击便会在页面源码中找到图片对应的部分,可以看见其中有img标签,而其中的src属性值正是该图片的链接,但是细心的小伙伴会发现,这url好像不完整。
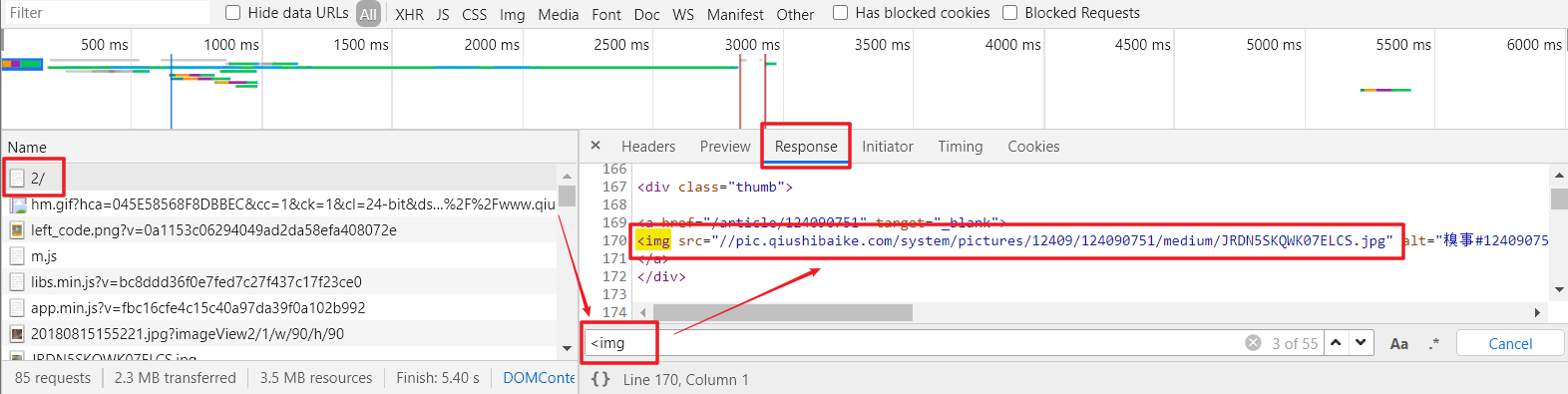
4、前面说的图片url链接不够完整,我们暂且先不考虑,我们首先要做的就是将整个页面上的这种值全部取出来,于是我们继续分析。我们选择第2页的页面进行抓包分析,会发现请求响应中会有一个2/的页面document,这应该就是整个网页的数据了。寻求验证,可以点击其Response,可以看到和页面源码类似的代码,那是不是就含有图片url呢,这里使用一个小技巧,点击Response中的内容,然后按ctrl+F进行搜索,搜索 <img 标签,会发现页面中含有此类信息,那就证明这个请求的响应结果正是我们需要的含有图片链接的网页。既然如此,我们只需要对该网页进行请求,并对获取的页面源码解析,提取出其中热图部分的图片链接即可。还有一点,就是该网页的url :https://www.qiushibaike.com/imgrank/page/2/ 这里的2正是我们选择的第2页,于是我们可以更改这个值来访问其他页面从而达到分页爬取。
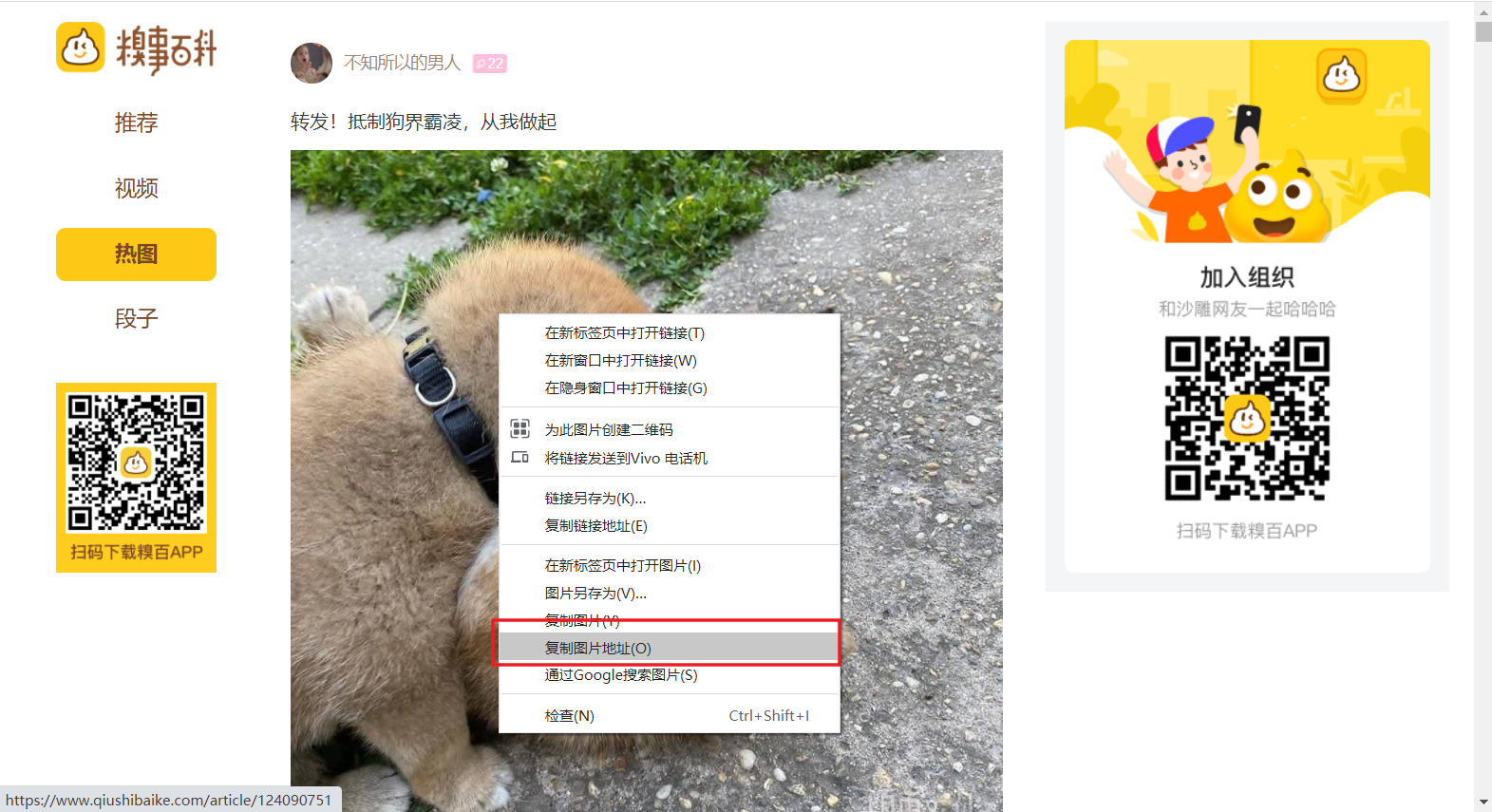
5、网页上的图片链接已经找到,只需批量解析爬取即可,只不过前面有一点问题:标签中的url值并不完整,于是我们单击图片打开复制图片地址,然后在地址栏显示,会发现其实就是少了一个https:前缀而已,那就很简单了,只要对图片链接爬取完毕后批量拼接即可。

6、找到解析的源头,那接下来只要使用某种解析方法对链接进行解析即可。打开查看页面源码,会发现,每张图片的源码格式都相同,只有其中的src属性不同,那我们就可以使用正则表达式进行通配即可。但是有一点需求需要明确,我们只需要网页上的热图的图片,而非全部图片,如下图所示,页面上其他的类似二维码的图片其标签格式也和热图相同,于是我们将标签往上一层,即确定到 <div class="thumb">,进行正则匹配,这样就能保证所有匹配图片为热图而非其他不需要的图片。
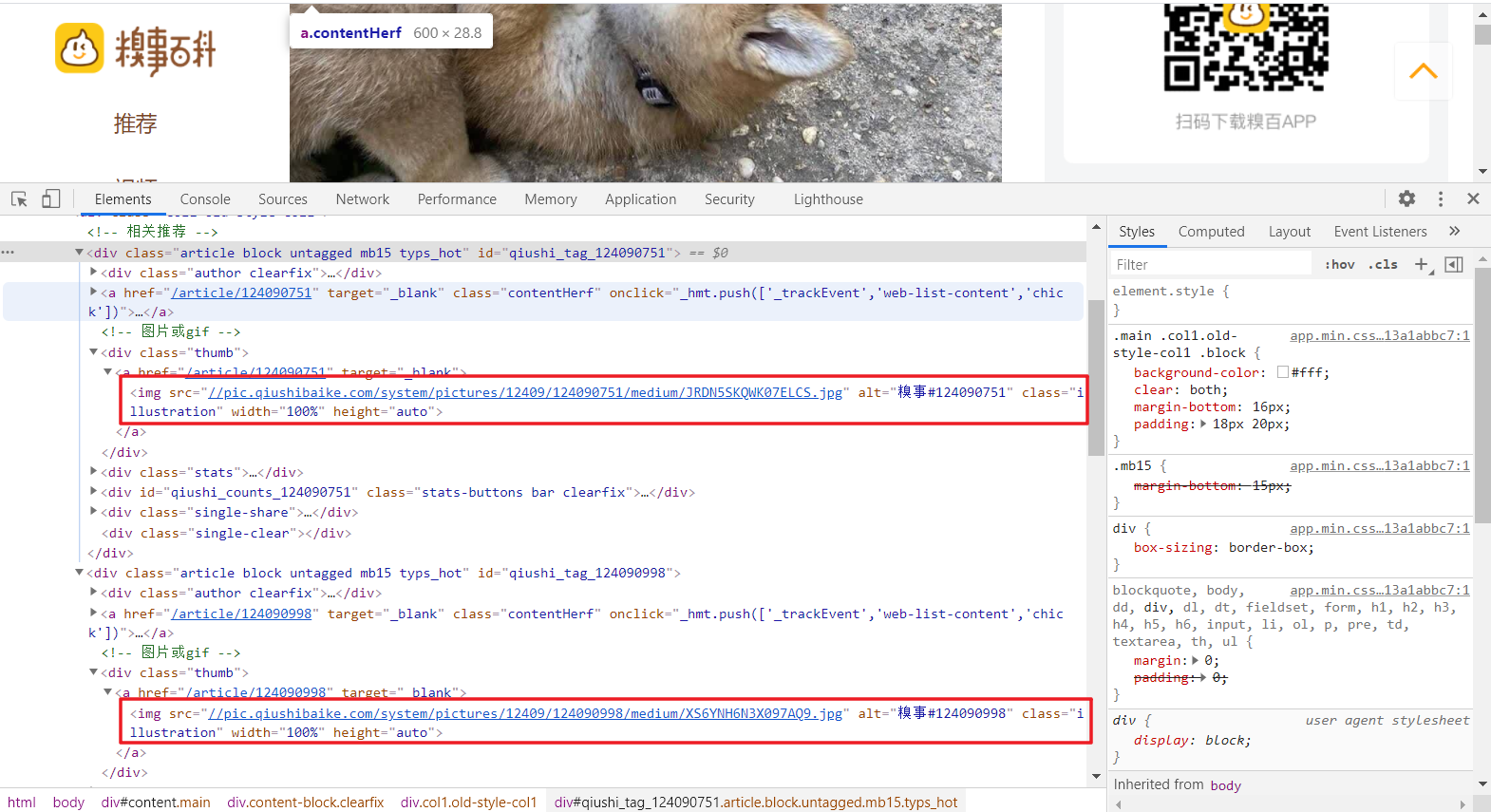
7、这里的正则表达式就比较简单了,博主直接放出来:r'<div class=\"thumb\".*?<img src=\"(.*?)\"',我们将匹配到上一级,然后使用组选择对所需要的链接进行获取。
二、糗事百科图片爬取编码
# coding : utf-8
import requests
import json
import re
import os
def qiutu_spider(url,num):
"""
爬取糗图百科热图所有图片
:param url: 网页url
:param num: 页数索引
:return:
"""
# 1.指定url
url = url
# 2.UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
# 3.发送请求并获取响应数据
page_text = requests.get(url,headers=headers).text
# 4.正则解析所有图片链接
url_list = parse_text(page_text)
# 5.抓取图片
for i, img_url in enumerate(url_list):
# 获取图片数据
img_data = requests.get(img_url, headers=headers).content
# 保存文件名
img_name = './HotImages/{}_{:003}.jpg'.format(num, i)
with open(img_name, 'wb') as fp:
fp.write(img_data)
print("下载成功:{}".format(img_name))
def parse_text(str):
"""
正则表达式解析图片链接
:param str: 页面源码
:return:
"""
# 正则表达式
pat = re.compile(r'<div class=\"thumb\".*?<img src=\"(.*?)\"', re.DOTALL) # 或者re.S
# 找出所有图片链接
url_list = ['https:' + i for i in pat.findall(str)]
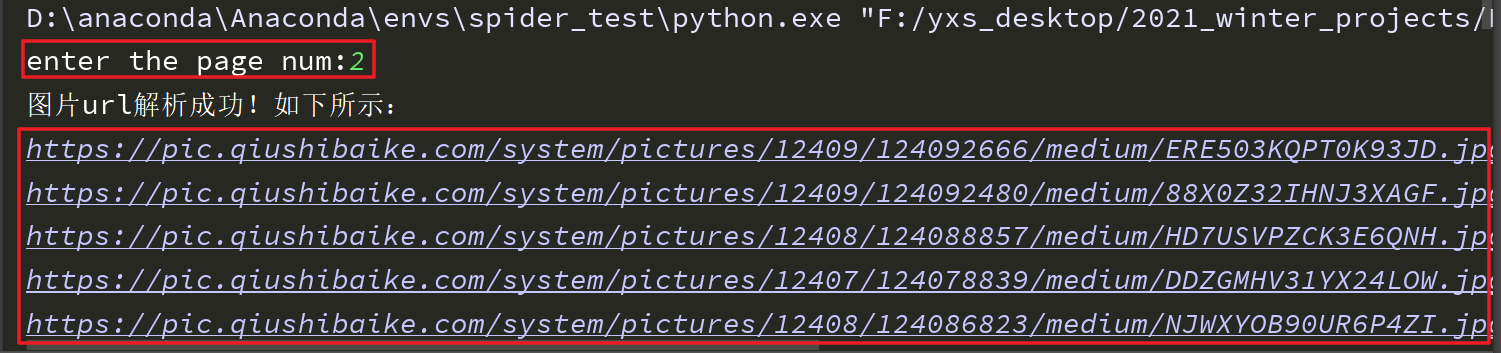
print("图片url解析成功!如下所示:")
for url in url_list:
print(url)
return url_list
if __name__ == '__main__':
# 创建文件夹
if not os.path.exists('./HotImages'):
os.mkdir('./HotImages')
# 指定url
url = "https://www.qiushibaike.com/imgrank/page/"
# 输入爬取页数
num = int(input("enter the page num:"))
# 爬取图片
for i in range(1, num+1):
url_single = url + str(i)
qiutu_spider(url, i)
- 运行结果
三、注意项
- 这里的图片保存,其实和前面讲解的文本保存一样,只不过对文件进行读写时是对于二进制数据。从而获取页面响应信息为response.content。
# 获取图片数据
img_data = requests.get(img_url, headers=headers).content
# 保存文件名
img_name = './HotImages/{}_{:003}.jpg'.format(num, i)
with open(img_name, 'wb') as fp:
fp.write(img_data)

