数据解析基础之正则表达式
一、爬虫网页数据解析
1.1、爬虫常用的数据解析分类
- 正则表达式(万金油)
- Beautiful Soup库 (bs4)
- xpath方法(最常用)
1.2、爬虫数据解析原理概述
- 其实聚焦爬虫中关注的局部文本内容,通常是在页面HTML源码中的标签之间或者标签对应的属性中。
- 进行指定标签的定位
- 标签或者标签对应的属性中存储的数据值进行提取解析
二、正则表达式
2.1、概要
- 正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。通俗理解:就是使用一种规则性的表达式来寻找文本字符串中通用的数据;
2.2、常见语法
2.2.1、点(.)
- 点(.)可以匹配所有字符:匹配出换行符以外的任意单个字符(按行匹配)
- 示例 :
import re
content = """苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
"""
p = re.compile(r'.色')
for one in p.findall(content):
print(one)
- 注意:
- re模块是使用正则表达式的python官方库,在使用之前需要进行import,其中re.compile()表示对正则表达式进行编译,将普通的字符串编译为可通配的正则表达式。p.findall(content)用于在文本中通过表达式进行匹配数据。结果如下:

2.2.2、星号(*)
- 星号(*)重复匹配任意次:表示匹配前面的子表达式任意次,包括0次
- 示例 :
import re
content = """苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
"""
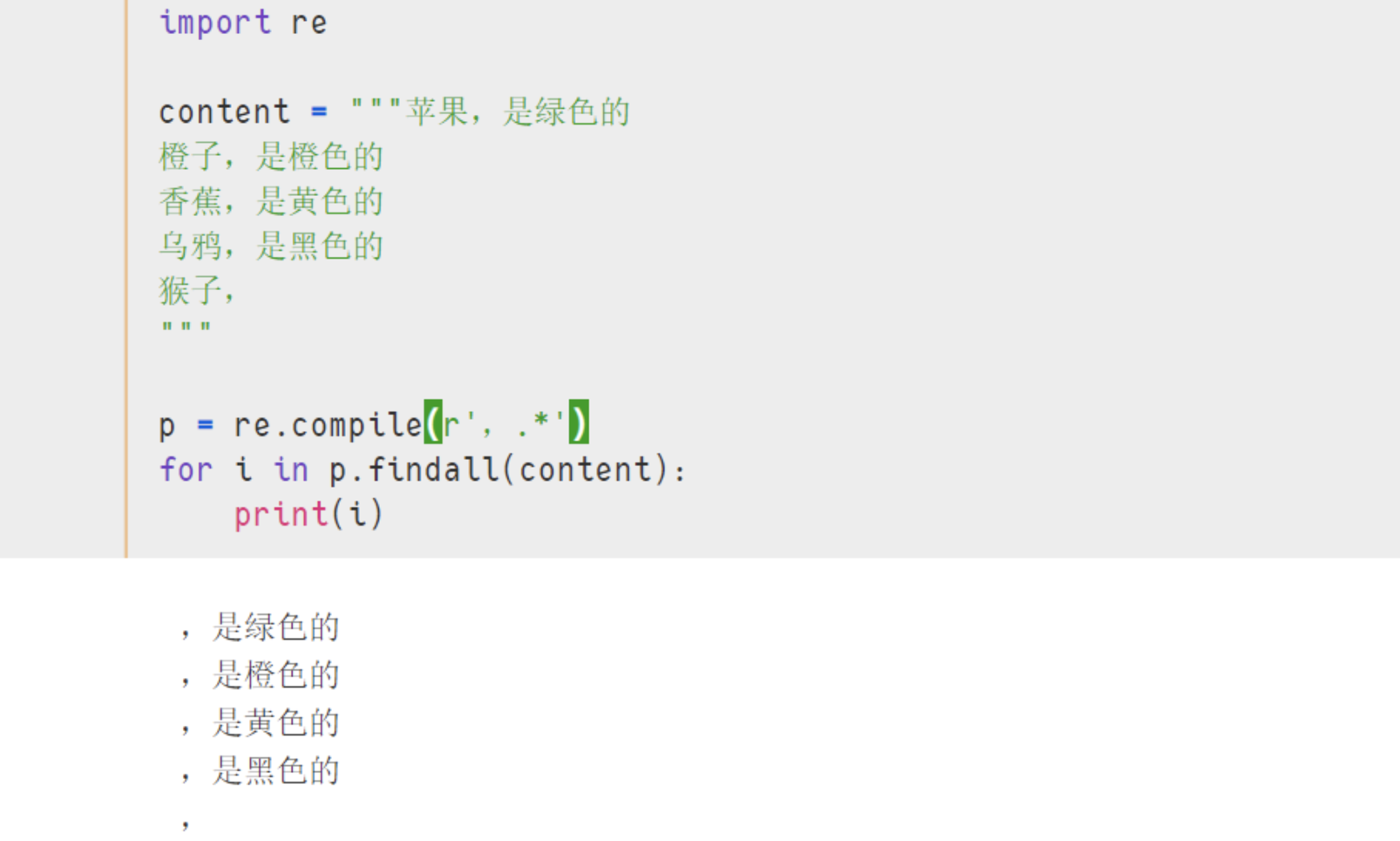
p = re.compile(r',.*')
for i in p.findall(content):
print(i)
- 解析:',.*'表示匹配前面一个字符是全角逗号,后面紧接着多个字符,可以发现结果都是按行匹配的。结果如下
2.2.3、加号(+)
- 加号(+)重复匹配多次:表示匹配前面的子表达式一次或多次,不包括0次(用法同上)
2.2.4、花括号({})
- 花括号({})匹配指定次数:表示前面的字符匹配指定的次数,其表示范围(最小次数和最大次数)
- 示例 :
import re
content = """
红彤彤,绿油油,黑乎乎,绿油油油
"""
p = re.compile(r"绿油{3,4}")
for i in p.findall(content):
print(i)
- 解析:'绿油{3,4}'表示匹配绿字且紧接着的油字出现最少3次最多4次的字符串,符合的只有绿油油油和绿油油油油。结果如下:

2.2.5、问号(?)
- 问号(?)匹配0或1次:表示前面的字符匹配0或1次,等价于
2.2.6、贪婪模式和非贪婪模式
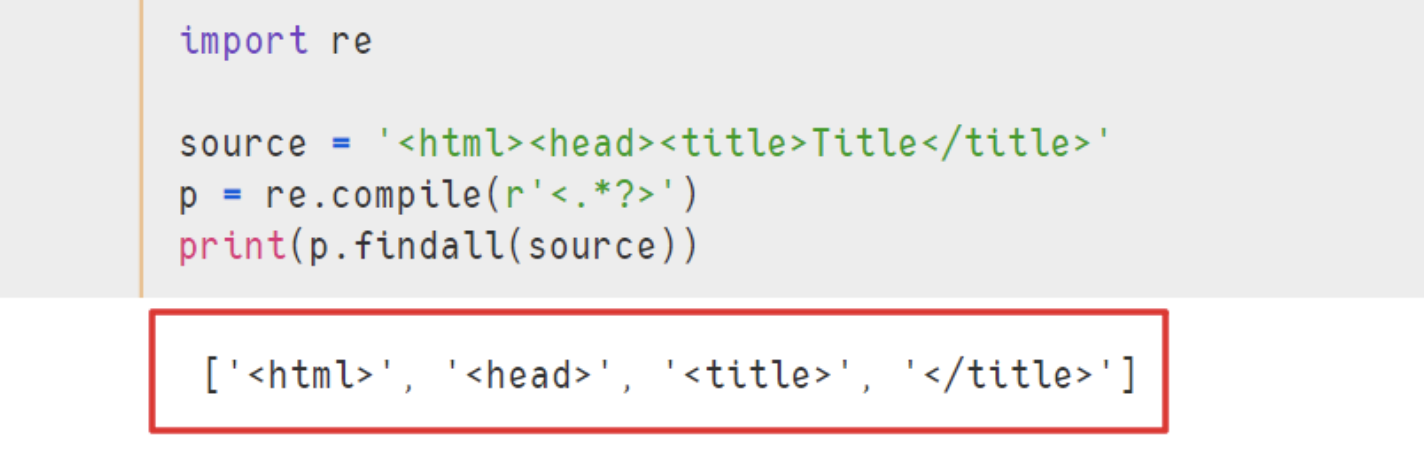
- 假设我们需要将下面字符串中所有的html标签提取出来:
source = '<html><head><title>Title</title>'
得到这样的列表:
['<html>','<head>','<title>','</title>']
于是我们使用以下代码
import re
p = re.compile(r'<.*>')
print(p.findall(source))
出现的匹配结果如下:
['<html><head><title>Title</title>']
-
我们代码中r'<.>'表示匹配所以包含左右尖括号,中间含任意个字符的字符串,即我们想要的html标签,但是匹配的结果与我们预想的并不一样,这是为何呢?因为我们前面讲述的、+、?都是贪婪性质的,所谓贪婪,是指其尽可能匹配更多的字符内容。而在这里我们想要的是让其一个标签一个标签的匹配,那就需要非贪婪模式,非贪婪模式其实就在匹配次数后加?即可,这里的话我们使用r'<.*?>'会发现即可将标签一个一个匹配出来。
-
示例 :
import re
source = '<html><head><title>Title</title>'
p = re.compile(r'<.*?>')
print(p.findall(source))
2.2.7、反斜杠(\)
- 反斜杠(\)对元字符转义:在正则表达式中有多种用途
1、比如说,点表示匹配任意单个字符,如果我们本身需要匹配点这个字符,则需要使用其进行转义
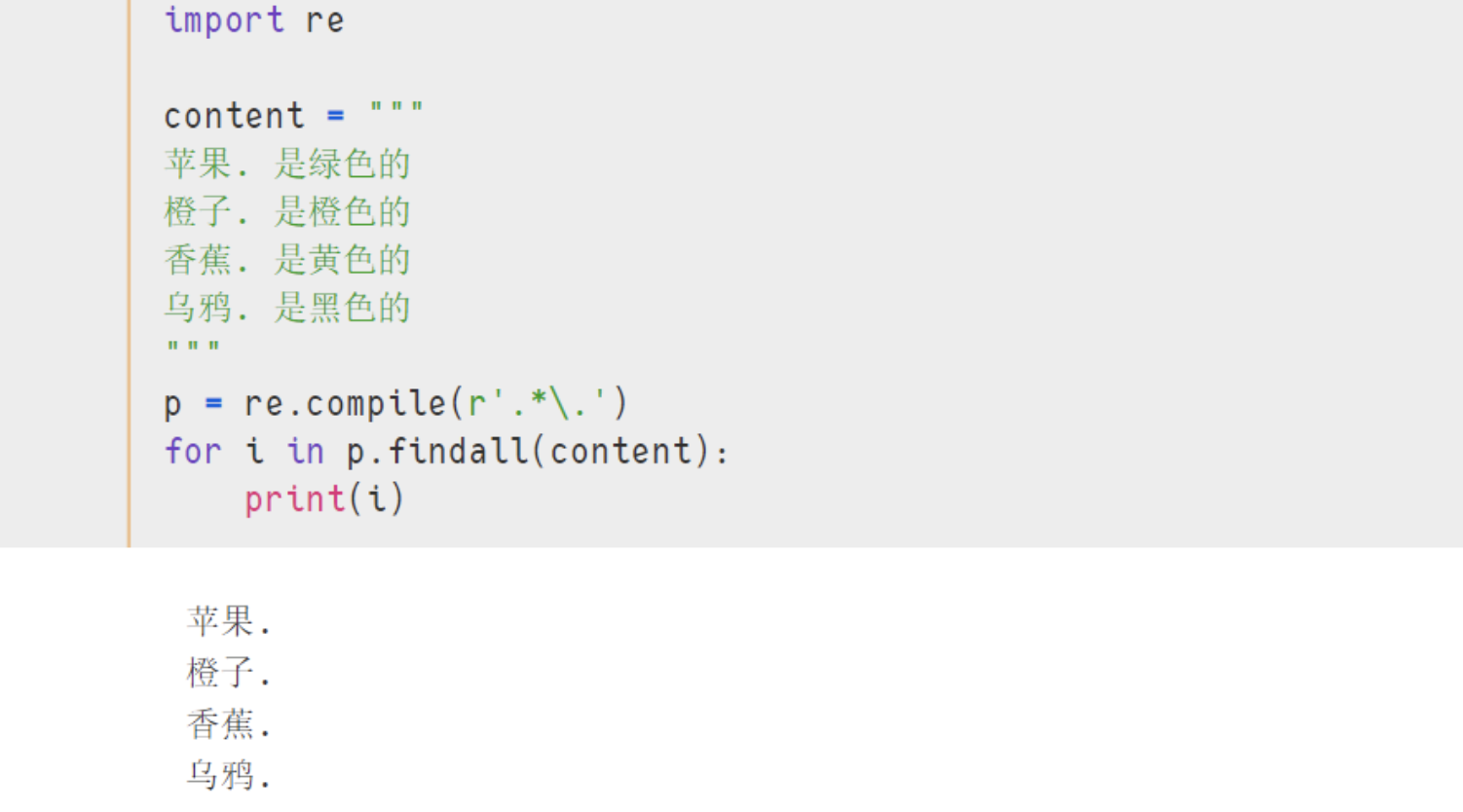
- 示例:
import re
content = """
苹果. 是绿色的
橙子. 是橙色的
香蕉. 是黄色的
乌鸦. 是黑色的
"""
p = re.compile(r'.*\.')
for i in p.findall(content):
print(i)
- 结果
2、反斜杠后面接一些字符,表示匹配某种类型的单个字符:
-
\d 匹配0-9之间任意一个数字字符,等价于表达式 [0-9]
-
\D 匹配任意一个不是0-9之间的数字字符,等价于表达式 [^0-9]
-
\s 匹配任意一个空白字符,包括 空格、tab、换行符等,等价于表达式 [\t\n\r\f\v]
-
\S 匹配任意一个非空白字符,等价于表达式 [^ \t\n\r\f\v]
-
\w 匹配任意一个文字字符,包括大小写字母、数字、下划线,等价于表达式 [a-zA-Z0-9_]。注意:缺省情况也包括 unicode文字字符,如果指定 ASCII码标记,则只包括ASCII字母。
-
示例:
import re
source = """
tom
tony
jery
"""
p = re.compile(r'\w{2,4}',re.A) # re.A参数表示匹配ASCII字符
print(p.findall(source))
2.2.8、方括号([])
- 方括号([])匹配单个字符:即匹配其中包含的字符,如[abc]可以匹配abc中的任意一个字符;[a-z]匹配范围内的字符;[^a-z]表示非小写字母。
2.2.9、起始位置和单行、多行模式
-
^表示匹配文本的起始位置,正则表达式中可以设定单行模式和多行模式。如果是单行模式,表示匹配整个文本的开头位置;如果是多行模式,表示匹配文本每行的开头位置。
-
$ 表示匹配文本的结束位置,单行多行同上,如\d+$
-
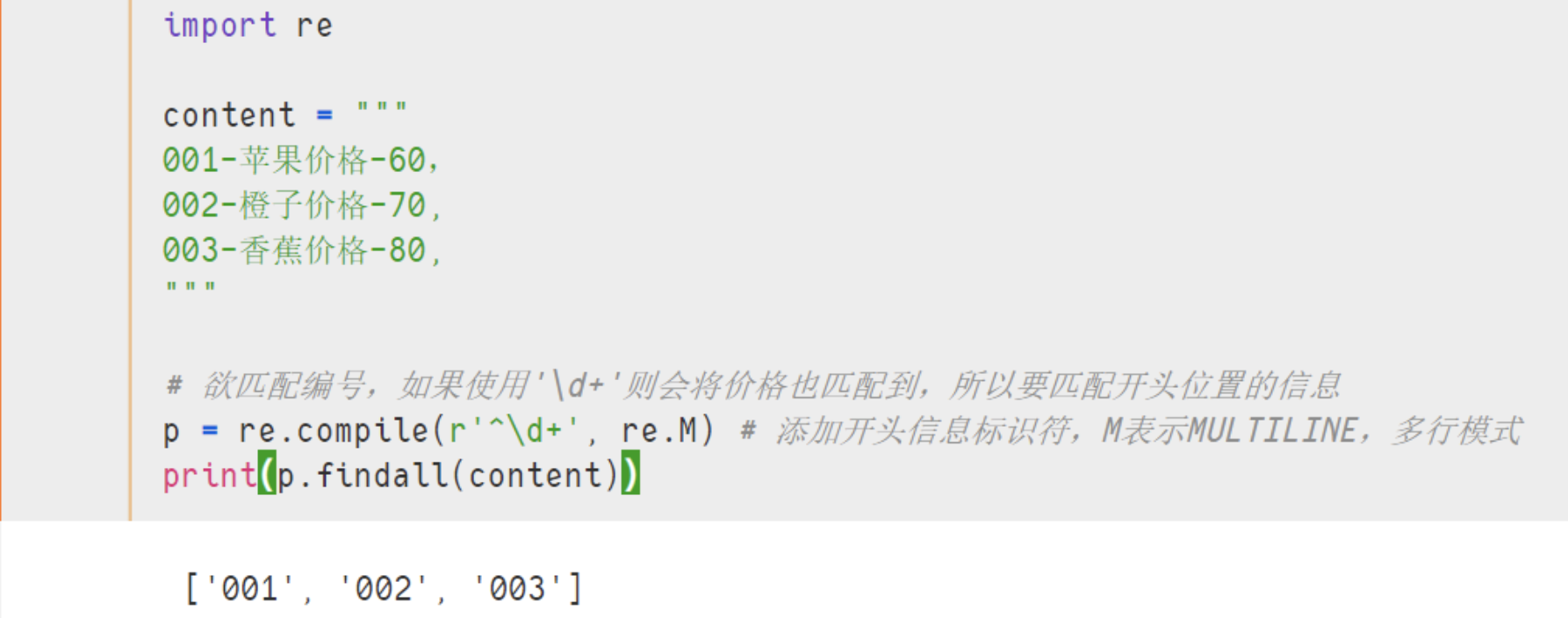
示例 :
import re
content = """
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
"""
# 欲匹配编号,如果使用'\d+'则会将价格也匹配到,所以要匹配开头位置的信息
p = re.compile(r'^\d+', re.M) # 添加开头信息标识符,M表示MULTILINE,多行模式
print(p.findall(content))
- 结果 :
2.2.10、括号(()):组选择
-
括号(())称之为正则表达式的组选择,即从正则表达式匹配的内容里面扣取出其中的某些需要的部分。
-
示例 :
import re
content = """
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
"""
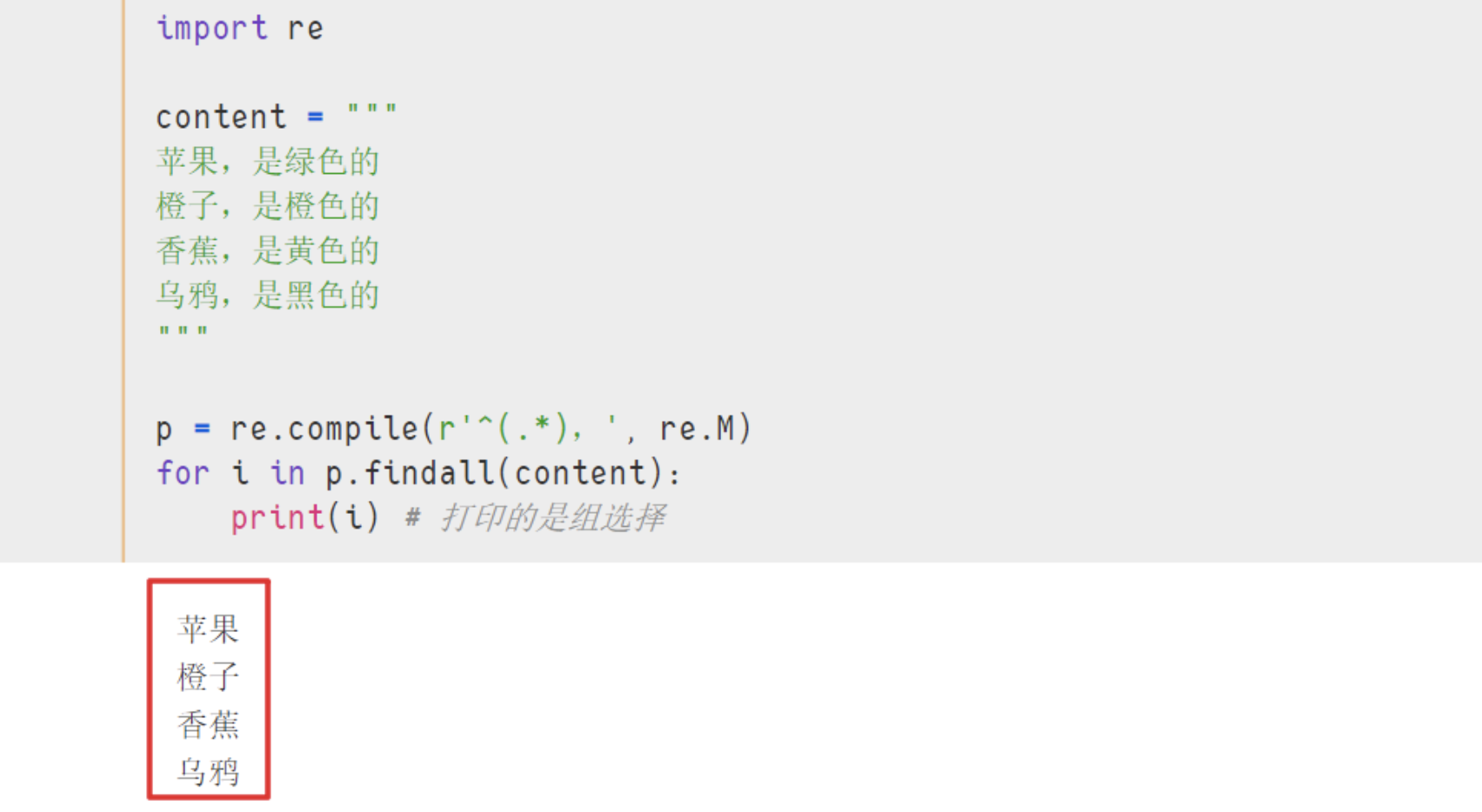
p = re.compile(r'^(.*),', re.M)
for i in p.findall(content):
print(i) # 打印的是组选择
- 结果 :
-
注:如果多行匹配的多个组,则每一行都是一个组选择的元组
-
示例 :
import re
content = """
张三,手机号码15945678901
李四,手机号码13945677701
王二,手机号码13845666901
"""
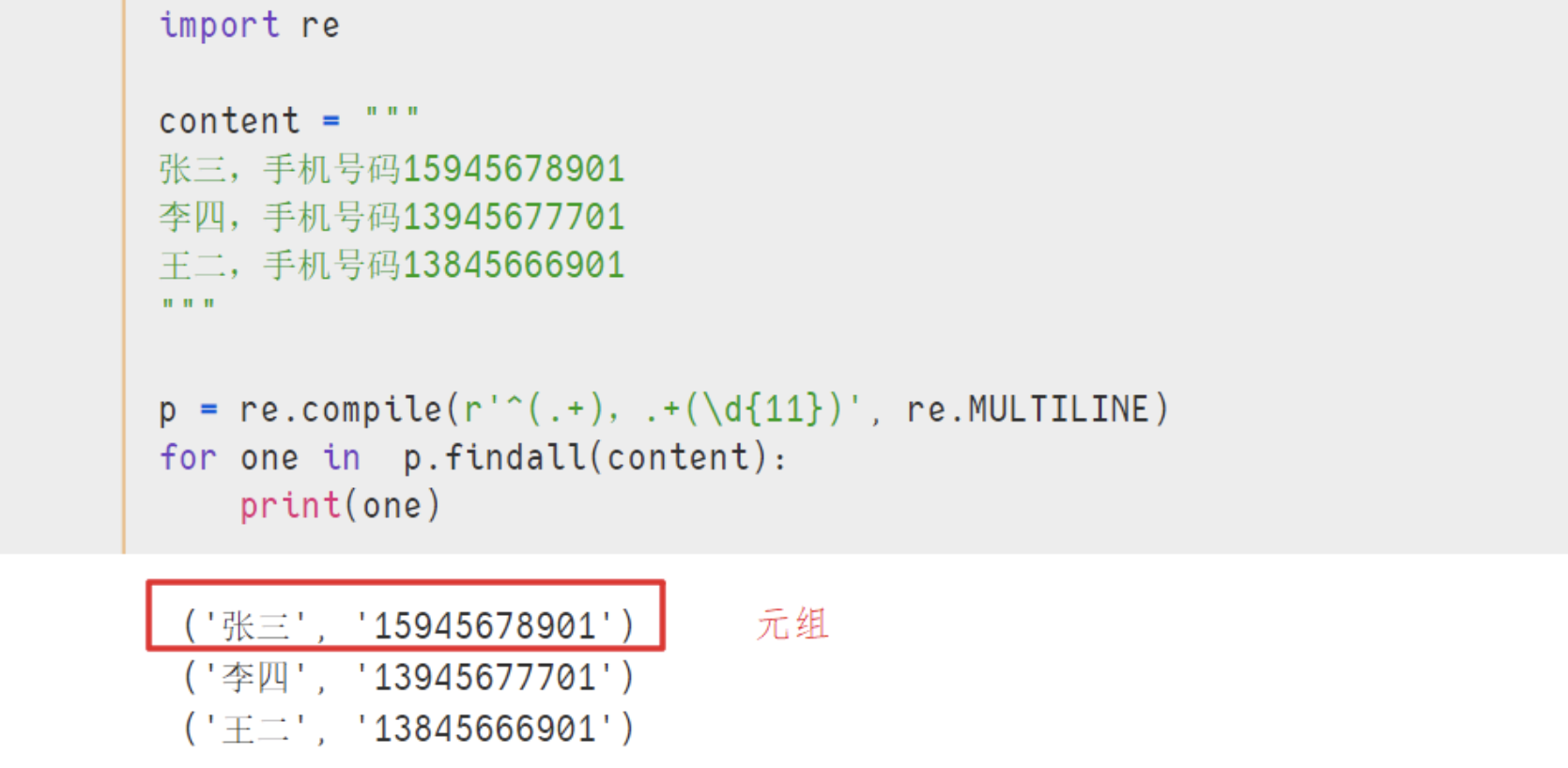
p = re.compile(r'^(.+),.+(\d{11})', re.MULTILINE)
for one in p.findall(content):
print(one)
- 结果 :
2.2.11、正则表达式切割字符串
- 示例 :
import re
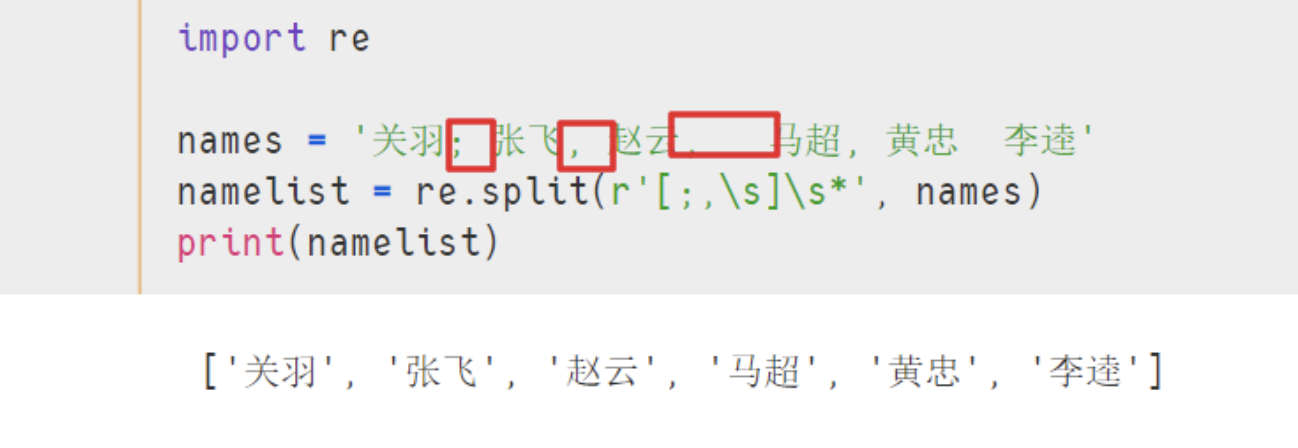
names = '关羽; 张飞, 赵云, 马超, 黄忠 李逵'
namelist = re.split(r'[;,\s]\s*', names)
print(namelist)
- 结果 :
2.2.12、匹配换行符
- 点(.)不能匹配换行符,如果我们使用时想让其匹配换行符,可以在compile()方法中添加re.DOTALL参数。
2.2.13、匹配模式替换
1、使用sub方法进行替换
- 示例 :
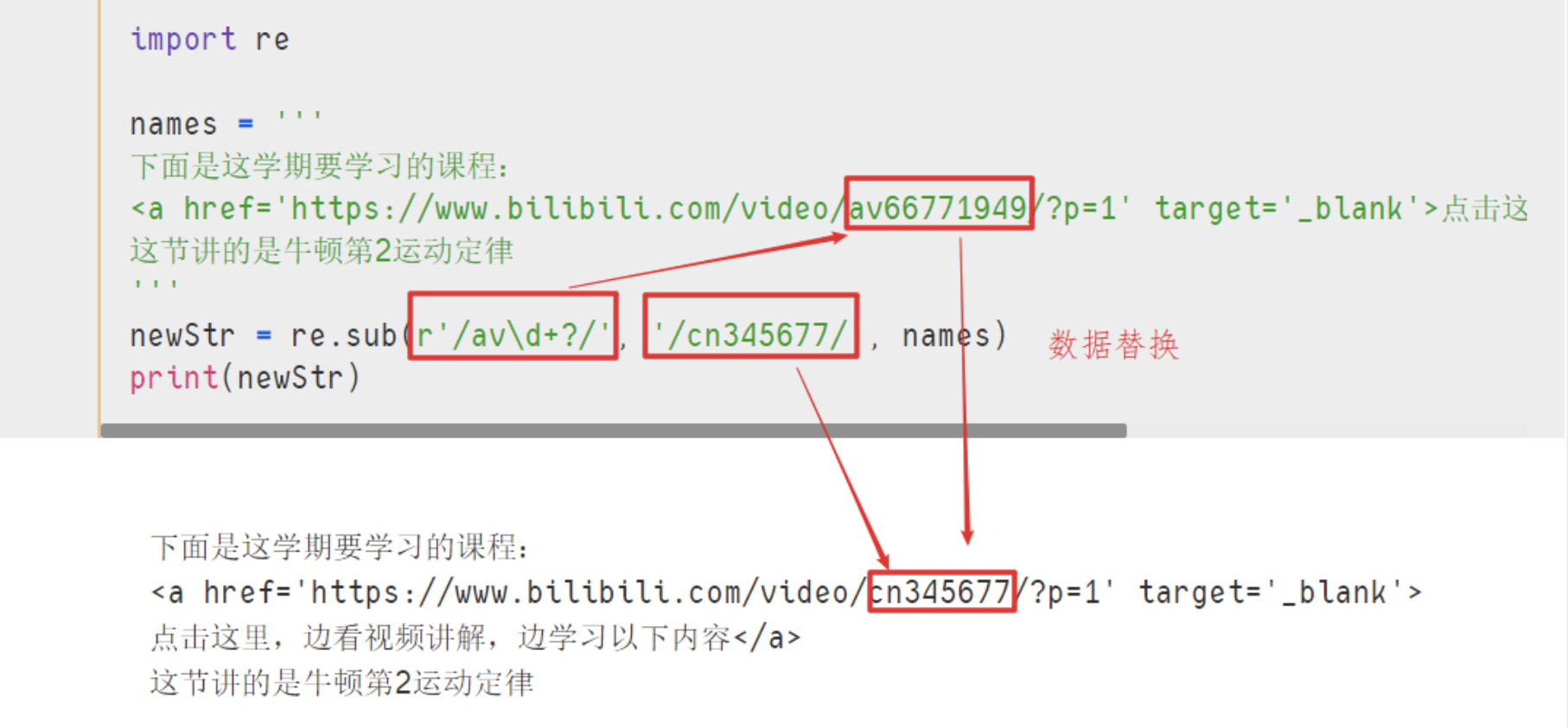
import re
names = '''
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
'''
newStr = re.sub(r'/av\d+?/', '/cn345677/', names)
print(newStr)
- 结果 :
2、使用指数函数替换
- 示例 :
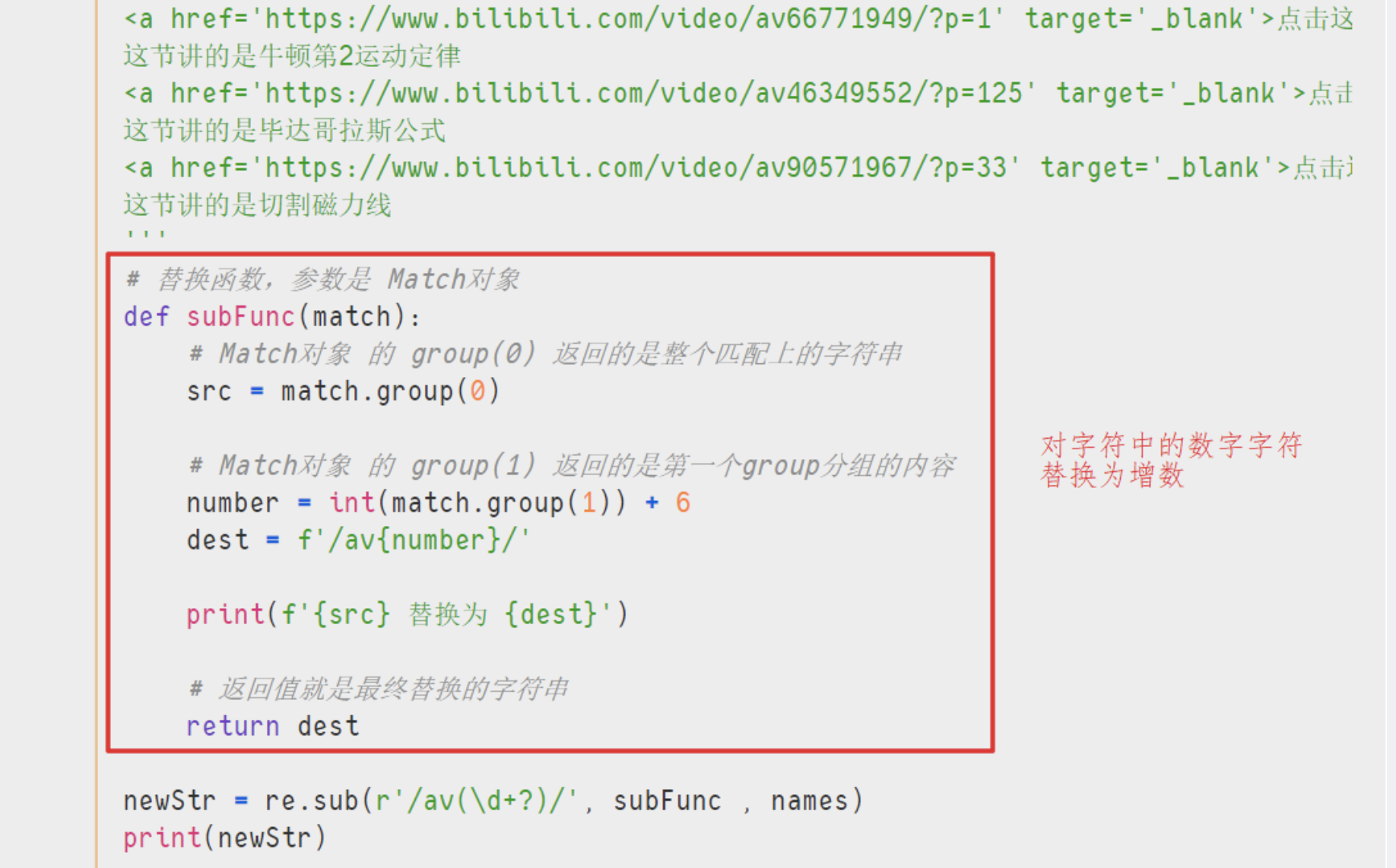
import re
names = '''
下面是这学期要学习的课程:
<a href='https://www.bilibili.com/video/av66771949/?p=1' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是牛顿第2运动定律
<a href='https://www.bilibili.com/video/av46349552/?p=125' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是毕达哥拉斯公式
<a href='https://www.bilibili.com/video/av90571967/?p=33' target='_blank'>点击这里,边看视频讲解,边学习以下内容</a>
这节讲的是切割磁力线
'''
# 替换函数,参数是 Match对象
def subFunc(match):
# Match对象 的 group(0) 返回的是整个匹配上的字符串
src = match.group(0)
# Match对象 的 group(1) 返回的是第一个group分组的内容
number = int(match.group(1)) + 6
dest = f'/av{number}/'
print(f'{src} 替换为 {dest}')
# 返回值就是最终替换的字符串
return dest
newStr = re.sub(r'/av(\d+?)/', subFunc , names)
print(newStr)
- 结果 :
向往的地方很远,喜欢的东西很贵,这就是我努力的目标。

