requests模块之药监企业信息爬取
Ps :参考博文 https://blog.csdn.net/qq_38330148/article/details/113933959
一、需求分析
- 需求 :主要对国家药监局化妆生产许可证的企业信息进行爬取(首页地址:http://scxk.nmpa.gov.cn:81/xk/)。
- 分析 :
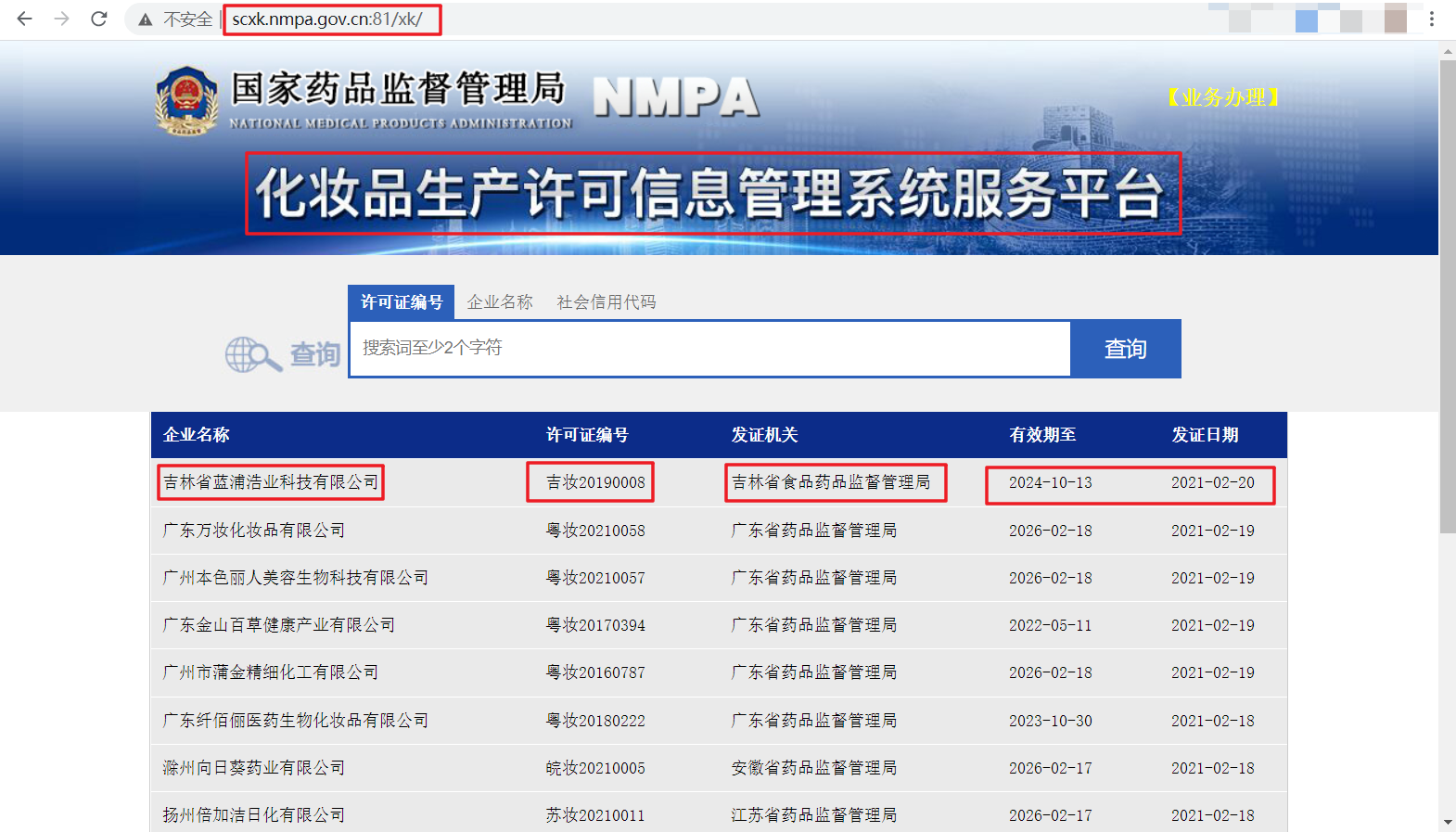
1、首先,我们通过url:http://scxk.nmpa.gov.cn:81/xk/进入网页,可以看到如下图的药监局化妆品许可证信息的页面。其中包含各企业的简要信息,包括企业名称、许可证编号等。
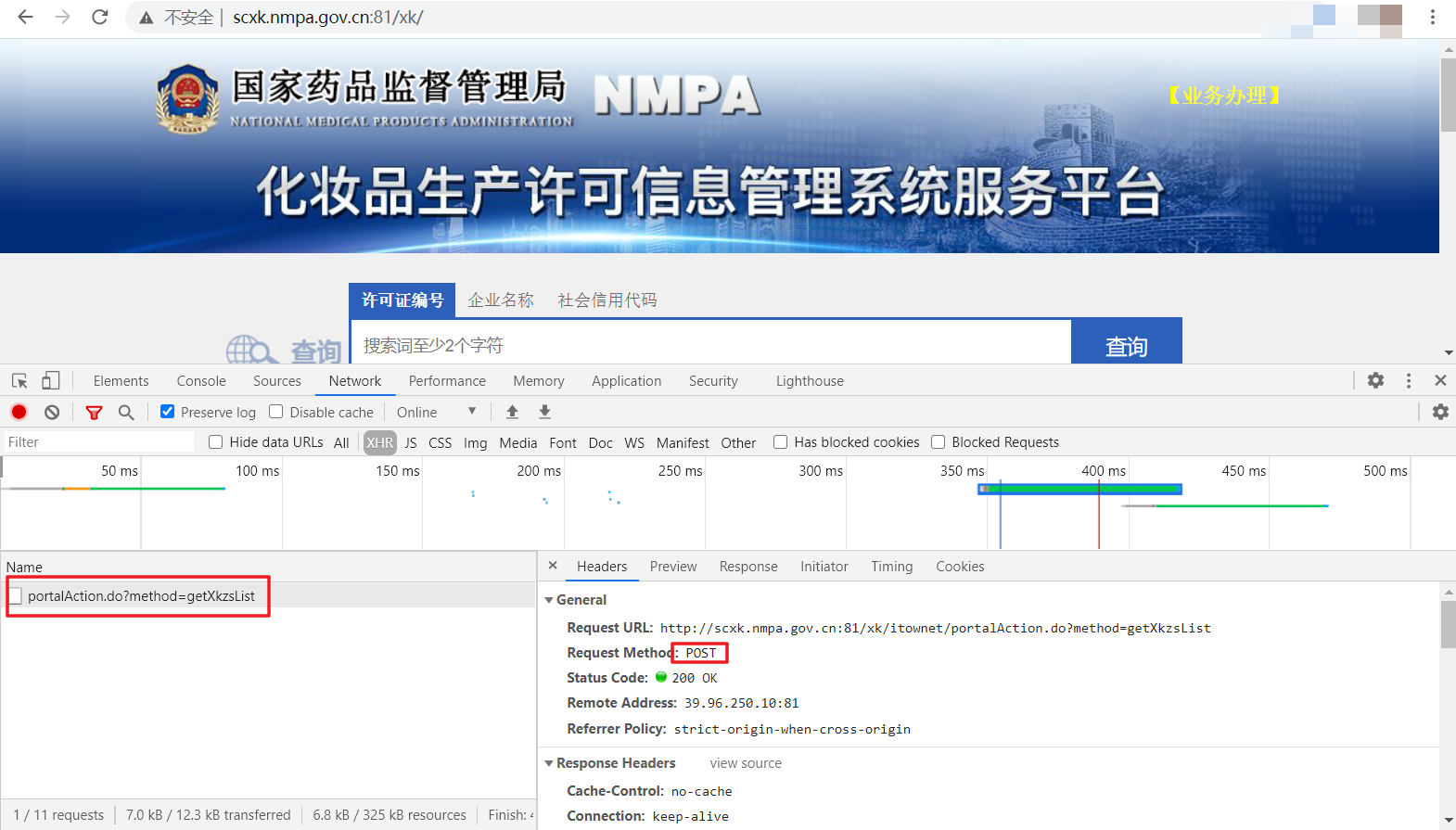
2、我们打开开发者模式进行网页分析时,会发现这些简要信息也是异步渲染显示的,因此对首页进行爬取是无法获取的,于是和前几个案例一样,进行POST请求,同时,该请求包含多个参数,这样参数都可以固定,当然,其中的page表示页面索引,我们可以设置索引方便访问多个页面数据,参数封装与前面大同小异,不多赘述。

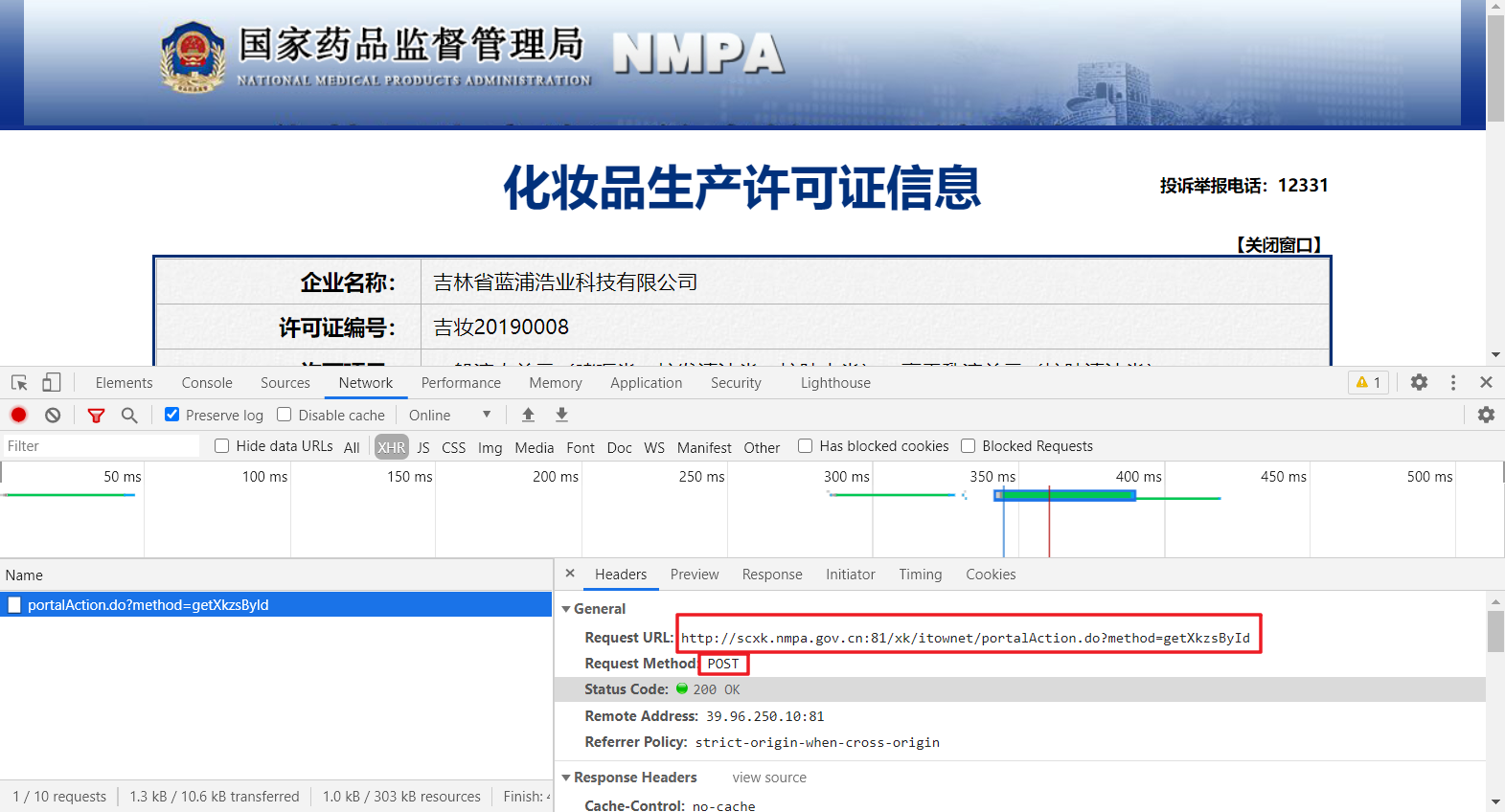
3、但是我们真正需要的并不是上面页面的简要信息,我们需要的是每个企业名称点进去的超链接显示出来的许可证详情信息,如下图所示。


4、既然每一个企业名称对应一个超链接,我们可以先在首页中获取每个企业信息中的链接,然后根据对应的链接再依次访问并获取详细信息。于是我们在详情页打开开发者模式,可以发现,详情数据的请求也是ajax页面加载,并且每个页面的url相同,只是在POST参数中有一个id参数,并且各不相同。基本可以断定,该id参数就是每个详细页的唯一标识,既然如此,那我们只需要知道每个详细页的id即可直接访问并获取页面了,那该编码id如何获取?
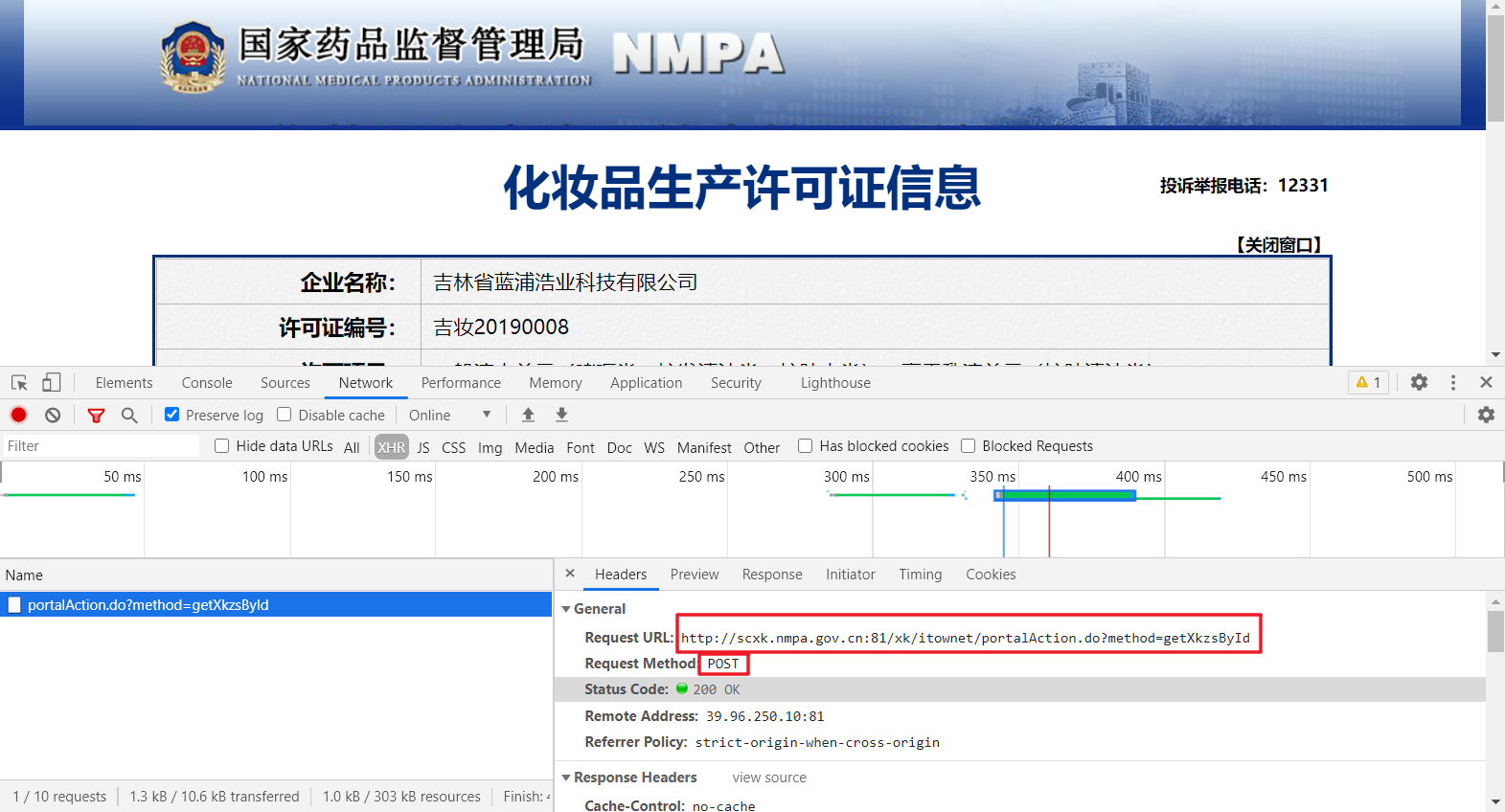
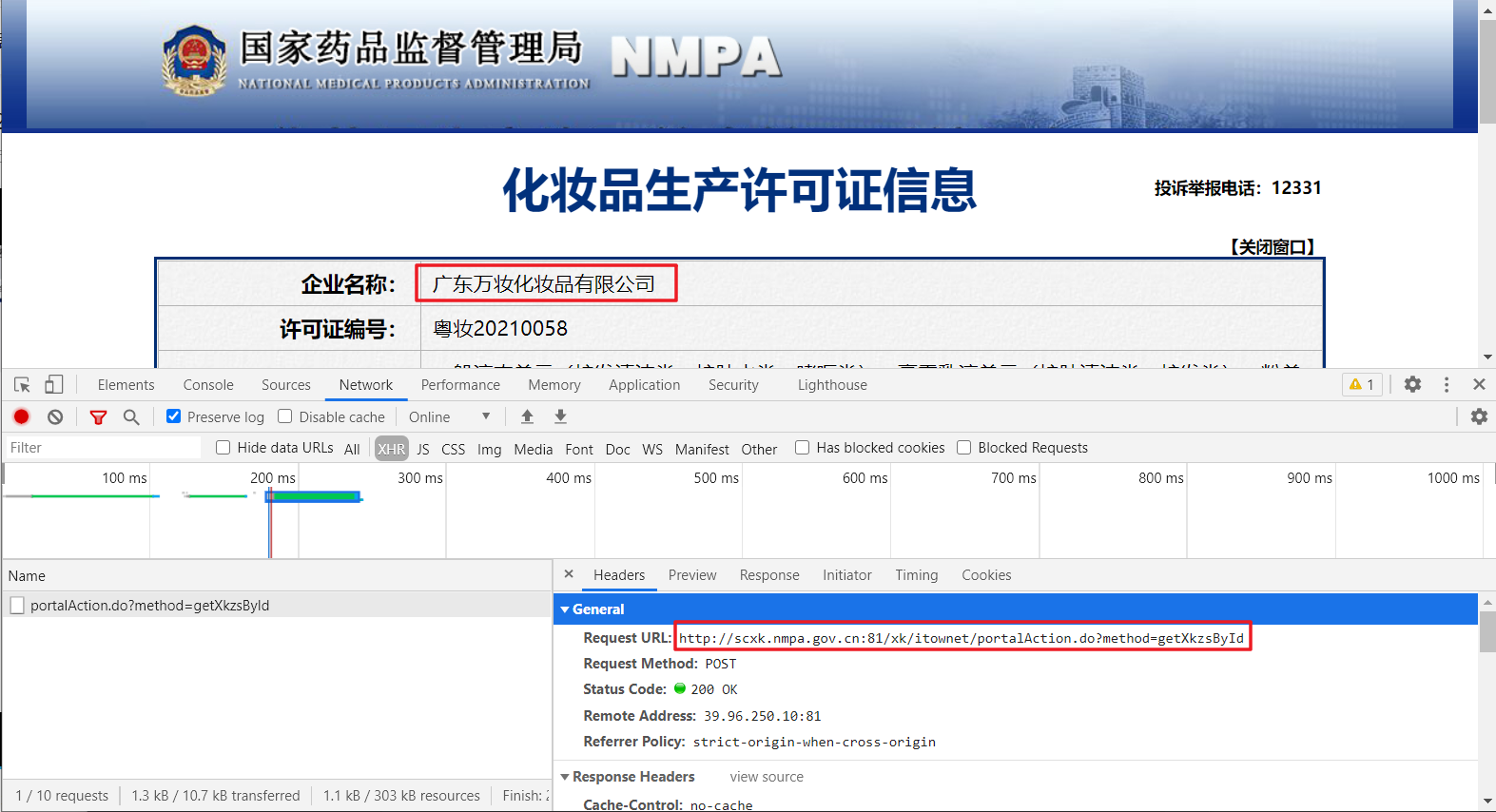
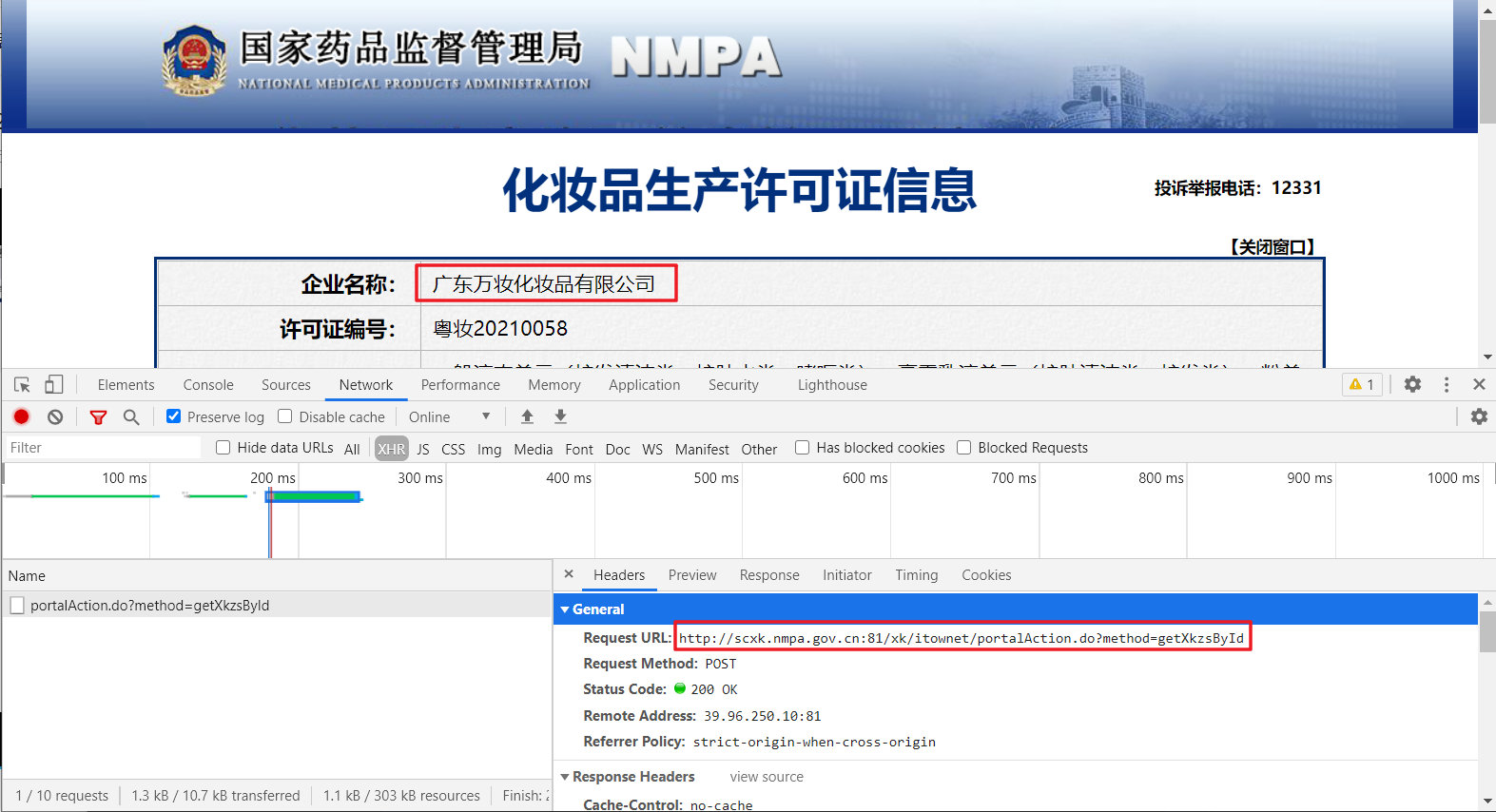

5、我们重新返回首页,发现在简要信息也获取时,网站响应的json数据中就包含了每个公司对应的id,那就好办了,我们可以根据需要页面数先访问首页,获取对应的id,然后再对id参数封装访问详细页数据即可爬取每个公司的信息。

二、药监企业信息爬取编码
# coding : utf-8
import requests
import json
def nmpa_spider(url=None):
"""
根据首页url动态爬取信息
:param url: url链接
:param num: 欲爬取页数数量
:return: json_list
"""
if url is None:
print("url should not be None!")
return
# ----------获取公司信息的id----------
# 1.指定url
url = url
num = 10 # 页数
# 2.UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
# 3.设置请求参数
id_list = [] # 初始化保存id的list
for i in range(1, num):
# 遍历每一页
params = {
'on': 'true',
'page': str(i),
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': ''
}
# 4.发送请求
response = requests.post(url=url, data=params,headers=headers)
# 5.获取响应数据
jsons = response.json() # 获取响应的json数据
for dic in jsons["list"]:
id_list.append(dic["ID"])
print("已成功爬取id {}条!".format(len(id_list)))
#----------获取每页公司信息的详细信息----------
# 1.根据id构建url
detail_url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById"
# 2.设置请求参数
json_list = [] # 初始化公司信息list
for id in id_list:
params = {
'id': id
}
# 3.发送请求
response = requests.post(url=detail_url, data=params, headers=headers)
# 4.获取响应数据
page_json = response.json()
json_list.append(page_json)
print("已成功爬取公司信息 {}条!".format(len(json_list)))
return json_list
def parse_json(json_list):
"""
解析json数据并持久化存储
:param json_list: json数据的list
:return:
"""
dict_head = {
'企业名称':'epsName',
'许可证编号':'productSn',
'法定代表人':'legalPerson',
'发证日期':'xkDateStr',
'有效期至':'xkDate',
'状态':'xkType'
}
fp = open('./nmpa.txt', 'a', encoding='utf-8')
# ----------交叉合并----------
# 双列表交叉合并作为表头
# key_list = list(dict_head.keys()) # 获取key列表
# empty_list = [' ' for i in range(len(key_list))] # 生成空格
# new_list = list([y for x in zip(key_list, empty_list) for y in x]) # 交叉合并
# new_list.append('\n')
# ----------格式化输出----------
new_list = [] #
for i in list(dict_head.keys()):
new_list.append('{:<20}'.format(i))
new_list.append('\n')
fp.writelines(new_list) # 写入表头,按行写入
for json in json_list: # 遍历json信息list
info_list = []
for k in list(dict_head.values()): # 获取json信息关键字
info_list.append('{:<40}'.format(json[k]))
info_list.append('\n')
fp.writelines(info_list)
print("已成功保存信息:{}".format(json["epsName"]))
print("已成功保存{}条公司信息!请在nmpa.txt文件中查看!".format(len(json_list)))
if __name__ == '__main__':
# 主页url
url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList"
# 获取具体信息的json数据
json_list = nmpa_spider(url)
# 持久化存储
parse_json(json_list)
向往的地方很远,喜欢的东西很贵,这就是我努力的目标。

