
Spring Cloud 生产环境性能优化
先思考几个问题:
- 什么是百万并发连接?
- 什么是吞吐量?
- 操作系统能否支持百万连接?
- 操作系统维持百万连接需要多少内存?
- 应用程序维持百万连接需要多少内存?
- 百万连接的吞吐量是否超过了网络限制?
百万的并发连接挑战意味着什么:
- 100 万的并发连接数
- 10 万个连接/秒——(如果每个连接以这个速率持续约10秒)
- 1 GB/秒的连接——快速连接到互联网。
- 100 万个数据包/秒——据估计目前的服务器每秒处理50K的数据包,以后会更多。过去服务器每秒可以处理100K的中断,并且每一个数据包都产生中断。
- 10 微秒的延迟——可扩展服务器也许可以处理这个规模,但延迟可能会飙升。
- 10 微秒的抖动——限制最大延迟
- 并发10核技术——软件应支持更多核的服务器。通常情况下,软件能轻松扩展到四核。服务器可以扩展到更多核,因此需要重写软件,以支持更多核的服务器。
一、操作系统参数优化
在 Linux 下,我们可以通过 ulimit -a 命令查看典型的机器默认的限制情况:
其中的 open files 是指一个进程能同时打开的文件句柄数量,默认值为1024,对于一些需要大量文件句柄的程序,如web服务器、数据库程序等,1024往往是不够用的,在句柄使用完毕的时候,系统就会频繁出现"too many open files"错误。
在Linux平台上,无论是编写客户端程序还是服务端程序,在进行高并发TCP连接处理时,由于每个TCP连接都要创建一个socket句柄,而每个socket句柄同时也是一个文件句柄,所以其最高并发数量要受到系统对用户单一进程同时可打开文件数量的限制以及整个系统可同时打开的文件数量限制。
1:解决文件句柄数量受限
1.1:单一进程的文件句柄数量受限
我们可以ulimit命令查看当前用户进程可打开的文件句柄数限制:
[root@localhost ~]# ulimit -n 1024
这表示当前用户的每个进程最多允许同时打开1024个文件,除去每个进程必然打开的标准输入、标准输出、标准错误、服务器监听socket、进程间通讯的unix域socket等文件,剩下的可用于客户端socket连接的文件数就只有大概1024-10=1014个左右。也就是说,在默认情况下,基于Linux的通讯程序最多允许同时1014个TCP并发连接。
对于想支持更高数量的TCP并发连接的通讯处理程序,就必须修改Linux对当前用户的进程可同时打开的文件数量的软限制(soft limit)和硬限制(hardlimit)。其中:
软限制是指Linux在当前系统能够承受的范围内进一步限制用户能同时打开的文件数。硬限制是指根据系统硬件资源状况(主要是系统内存)计算出来的系统最多可同时打开的文件数量。
通常软限制小于或等于硬限制,可通过ulimit命令查看软限制和硬限制:
[root@localhost ~]# ulimit -Sn 1024 [root@localhost ~]# ulimit -Hn 4096
修改单一进程能同时打开的文件句柄数有2种方法:
1、直接使用ulimit命令,如:
[root@localhost ~]# ulimit -n 1048576
执行成功之后,ulimit n、Sn、Hn的值均会变为1048576。但该方法设置的值只会在当前终端有效,且设置的值不能高于方法2中设置的值。
2、对 /etc/security/limits.conf 文件,添加或修改:
* soft nofile 1048576 * hard nofile 1048576
* hard nofile 1048576
其中,
*代表对所有用户有效,若仅想针对某个用户,可替换星号。soft即软限制,它只是一个警告值。hard代表硬限制,是一个真正意义的阈值,超过就会报错。nofile表示打开文件的最大数量。
注:1048576 = 1024 1024,为什么要取这个值呢? 因为在linux kernel 2.6.25之前,通过ulimit -n(setrlimit(RLIMIT_NOFILE))设置每个进程的最大打开文件句柄数不能超过NR_OPEN(10241024),也就是100多w(除非重新编译内核),而在25之后,内核导出了一个sys接口可以修改这个最大值(/proc/sys/fs /nr_open). 具体的changelog在 https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=9cfe015aa424b3c003baba3841a60dd9b5ad319b
注意文件保存之后,需要注销或重启系统方能生效。
1.2:整个系统的文件句柄数量受限
解决完单一进程的文件句柄数量受限问题后,还要解决整个系统的文件句柄数量受限问题。我们可通过以下命令查看Linux系统级的最大打开文件数限制:
[root@iZ2zehwfmp0tro35kljx2kZ ~]# cat /proc/sys/fs/file-max 764408 [root@iZ2zehwfmp0tro35kljx2kZ ~]# cat /proc/sys/fs/file-nr 1440 0 764408
file-max表示系统所有进程最多允许同时打开的文件句柄数,是Linux系统级硬限制。通常,这个系统硬限制是Linux系统在启动时根据系统硬件资源状况计算出来的最佳的最大同时打开文件数限制,如果没有特殊需要,不应该修改此限制。
要修改它,需要对 /etc/sysctl.conf 文件,增加一行内容:
fs.file-max = 1048576
保存成功后,需执行下面命令使之生效:
[root@localhost ~]# sysctl -p
2:端口数量受限
解决完文件句柄数量受限的问题后,就要解决IP端口数量受限的问题了。一般来说,对外提供请求的服务端不用考虑端口数量问题,只要监听某一个端口即可。可客户端要模拟大量的用户对服务端发起TCP请求,而每一个请求都需要一个端口,为了使一个客户端尽可能地模拟更多的用户,也就要使客户端拥有更多可使用的端口。
由于端口为16进制,即最大端口数为2的16次方65536(0-65535)。在Linux系统里,1024以下端口只有超级管理员用户(如root)才可以使用,普通用户只能使用大于等于1024的端口值。
我们可以通过以下命令查看系统提供的默认的端口范围:
[root@localhost ~]# cat /proc/sys/net/ipv4/ip_local_port_range 32768 61000
即只有61000-32768=28232个端口可以使用,即单个IP对外只能同时发送28232个TCP请求。
修改方法有以下2种:
1、执行以下命令:
echo "1024 65535"> /proc/sys/net/ipv4/ip_local_port_range
该方法立即生效,但重启后会失效。
2、修改 /etc/sysctl.conf 文件,增加一行内容:
net.ipv4.ip_local_port_range = 1024 65535
保存成功后,需执行下面命令使之生效:
[root@localhost ~]# sysctl -p
修改成功后,可用端口即增加到65535-1024=64511个,即单个客户端机器只能同时模拟64511个用户。要想突破这个限制,只能给该客户端增加IP地址,这样即可相应成倍地增加可用IP:PORT数。
具体可参考yongboy的这篇文章。
http://www.blogjava.net/yongboy/archive/2013/04/09/397594.html
3:TCP参数调优
要想提高服务端的性能,以达到我们高并发的目的,需要对系统的TCP参数进行适当的修改优化。
方法同样是修改 /etc/sysctl.conf 文件,增加以下内容(修改后必须运行 sysctl -p 命令才会生效):
net.ipv4.tcp_tw_reuse = 1 # 开启重用,允许将 TIME_WAIT 套接字重新用于新的 TCP 连接 # 使用命令 cat /proc/sys/net/ipv4/tcp_tw_reuse 可以查看当前值!
当服务器需要在大量TCP连接之间切换时,会产生大量处于TIME_WAIT状态的连接。TIME_WAIT意味着连接本身是关闭的,但资源还没有释放。将net_ipv4_tcp_tw_reuse设置为1是让内核在安全时尽量回收连接,这比重新建立新连接要便宜得多。
net.ipv4.tcp_fin_timeout = 15 # 保持在FIN-WAIT-2状态的时间 # 使用命令 cat /proc/sys/net/ipv4/tcp_fin_timeout 可以查看当前值!
这是处于TIME_WAIT状态的套接字在回收前必须等待的最小时间。改小它可以加快回收。
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216
提高TCP的最大缓冲区大小,其中:
- net.core.rmem_max:表示接收套接字缓冲区大小的最大值(以字节为单位)。
- net.core.wmem_max:表示发送套接字缓冲区大小的最大值(以字节为单位)。
net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216
提高Linux内核自动对socket缓冲区进行优化的能力,其中:
- net.ipv4.tcp_rmem:用来配置读缓冲的大小,第1个值为最小值,第2个值为默认值,第3个值为最大值。
- net.ipv4.tcp_wmem:用来配置写缓冲的大小,第1个值为最小值,第2个值为默认值,第3个值为最大值。
net.ipv4.tcp_rmem用来配置读缓冲的大小,三个值,第一个是这个读缓冲的最小值,第三个是最大值,中间的是默认值。我们可以在程序中修改读缓冲的大小,但是不能超过最小与最大。为了使每个socket所使用的内存数最小,我这里设置默认值为4096。
net.ipv4.tcp_wmem用来配置写缓冲的大小。
读缓冲与写缓冲的大小,直接影响到socket在内核中内存的占用。
而net.ipv4.tcp_mem则是配置tcp的内存大小,其单位是页,1页等于4096字节。三个值分别为low, pressure, high
- ·low:当TCP使用了低于该值的内存页面数时,TCP不会考虑释放内存。
- ·pressure:当TCP使用了超过该值的内存页面数量时,TCP试图稳定其内存使用,进入pressure模式,当内存消耗低于low值时则退出pressure状态。
- ·high:允许所有tcp sockets用于排队缓冲数据报的页面量,当内存占用超过此值,系统拒绝分配socket,后台日志输出“TCP: too many of orphaned sockets”。
一般情况下这些值是在系统启动时根据系统内存数量计算得到的。 根据当前tcp_mem最大内存页面数是1864896,当内存为(18648964)/1024K=7284.75M时,系统将无法为新的socket连接分配内存,即TCP连接将被拒绝。实际测试环境中,据观察大概在99万个连接左右的时候(零头不算),进程被杀死,触发outof socket memory错误(dmesg命令查看获得)。每一个连接大致占用7.5K内存(下面给出计算方式),大致可算的此时内存占用情况(990000 7.5/ 1024K = 7251M)。这样和tcp_mem最大页面值数量比较吻合,因此此值也需要修改。
另外net.ipv4.tcp_max_orphans这个值也要设置一下,这个值表示系统所能处理不属于任何进程的 socket数量,当我们需要快速建立大量连接时,就需要关注下这个值了。当不属于任何进程的socket的数量大于这个值时,dmesg就会看 到”too many of orphaned sockets”。
net.core.netdev_max_backlog = 4096
每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。默认为1000。
net.core.somaxconn = 4096
表示socket监听(listen)的backlog上限。什么是backlog呢?backlog就是socket的监听队列,当一个请求(request)尚未被处理或建立时,他会进入backlog。而socket server可以一次性处理backlog中的所有请求,处理后的请求不再位于监听队列中。当server处理请求较慢,以至于监听队列被填满后,新来的请求会被拒绝。默认为128。
net.ipv4.tcp_max_syn_backlog = 20480
表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_syncookies = 1
表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭。
net.ipv4.tcp_max_tw_buckets = 360000
表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。默认为180000。
net.ipv4.tcp_no_metrics_save = 1
一个tcp连接关闭后,把这个连接曾经有的参数比如慢启动门限snd_sthresh、拥塞窗口snd_cwnd,还有srtt等信息保存到dst_entry中,只要dst_entry没有失效,下次新建立相同连接的时候就可以使用保存的参数来初始化这个连接。
net.ipv4.tcp_syn_retries = 2
表示在内核放弃建立连接之前发送SYN包的数量,默认为4。
net.ipv4.tcp_synack_retries = 2
表示在内核放弃连接之前发送SYN+ACK包的数量,默认为5。
完整的TCP参数调优配置如下所示:
net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_fin_timeout = 15 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216 net.core.netdev_max_backlog = 4096 net.core.somaxconn = 4096 net.ipv4.tcp_max_syn_backlog = 20480 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_max_tw_buckets = 360000 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_syn_retries = 2 net.ipv4.tcp_synack_retries = 2
其它一些参数
vm.min_free_kbytes = 65536
用来确定系统开始回收内存的阀值,控制系统的空闲内存。值越高,内核越早开始回收内存,空闲内存越高。
vm.swappiness = 0
控制内核从物理内存移出进程,移到交换空间。该参数从0到100,当该参数=0,表示只要有可能就尽力避免交换进程移出物理内存;该参数=100,这告诉内核疯狂的将数据移出物理内存移到swap缓存中。
存疑:
待考查?
net.ipv4.ip_conntrack_max = 1020000
net.ipv4.netfilter.ip_conntrack_max = 1020000
二、Nginx 优化
nginx配置文件优化
- nginx进程数,建议按照cpu数目来指定,一般为它的倍数: - worker_processes 4; - 为每个进程绑定cpu: - worker_cpu_affinity 00000001 00000010 00000100 00001000; - nginx进程打开的最多文件描述符数目: - worker_rlimit_nofile 102400; - 使用epoll的I/O复用模型: - use epoll; - 每个进程允许的最多连接数: - worker_connections 102400; - keepalive超时时间: - keepalive_timeout 60; - 客户端请求头部的缓冲区大小: (分页大小可以用命令getconf PAGESIZE取得): - client_header_buffer_size 4k; - 打开文件指定缓存,默认是没有启用的,max指定缓存数量,建议和打开文件数一致,inactive是指经过多长时间文件没被请求后删除缓存: - open_file_cache max=102400 inactive=20s; - 指定多长时间检查一次缓存的有效信息: - open_file_cache_valid 30s; - 设置最少使用次数,如果超过这个数字,文件描述符一直是在缓存中打开的: - open_file_cache_min_uses 1;
三、zuul 优化
一、突破 Tomcat 默认 200 并发连接上限
通过配置以下 tomcat 线程参数,可以提升并发连接上限:
server: tomcat: # 最大工作线程数,默认200, 4核8g内存,线程数经验值800 # 操作系统做线程之间的切换调度是有系统开销的,所以不是越多越好。 max-threads: 2000 # 目前起作用,测试到上万都没问题 # 最小工作空闲线程数,默认10, 适当增大一些,以便应对突然增长的访问量 min-spare-threads: 100 # 总保持备用线程数 accept-count: 2000 # 等待队列长度,默认100 max-connections: 2000 # 最大连接数,NIO默式默认 10000,其它为 maxThreads
一、accept-count:最大等待数
官方文档的说明为:当所有的请求处理线程都在使用时,所能接收的连接请求的队列的最大长度。当队列已满时,任何的连接请求都将被拒绝。accept-count的默认值为100。
详细的来说:当调用HTTP请求数达到tomcat的最大线程数时,还有新的HTTP请求到来,这时tomcat会将该请求放在等待队列中,这个acceptCount就是指能够接受的最大等待数,默认100。如果等待队列也被放满了,这个时候再来新的请求就会被tomcat拒绝(connection refused)。
二、maxThreads:最大线程数
每一次HTTP请求到达Web服务,tomcat都会创建一个线程来处理该请求,那么最大线程数决定了Web服务容器可以同时处理多少个请求。maxThreads默认200,肯定建议增加。但是,增加线程是有成本的,更多的线程,不仅仅会带来更多的线程上下文切换成本,而且意味着带来更多的内存消耗。JVM中默认情况下在创建新线程时会分配大小为1M的线程栈,所以,更多的线程异味着需要更多的内存。线程数的经验值为:1核2g内存为200,线程数经验值200;4核8g内存,线程数经验值800。
三、maxConnections:最大连接数
官方文档的说明为:
这个参数是指在同一时间,tomcat能够接受的最大连接数。对于Java的阻塞式BIO,默认值是maxthreads的值;如果在BIO模式使用定制的Executor执行器,默认值将是执行器中maxthreads的值。对于Java 新的NIO模式,maxConnections 默认值是10000。
对于windows上APR/native IO模式,maxConnections默认值为8192,这是出于性能原因,如果配置的值不是1024的倍数,maxConnections 的实际值将减少到1024的最大倍数。
如果设置为-1,则禁用maxconnections功能,表示不限制tomcat容器的连接数。
maxConnections和accept-count的关系为:当连接数达到最大值maxConnections后,系统会继续接收连接,但不会超过acceptCount的值。
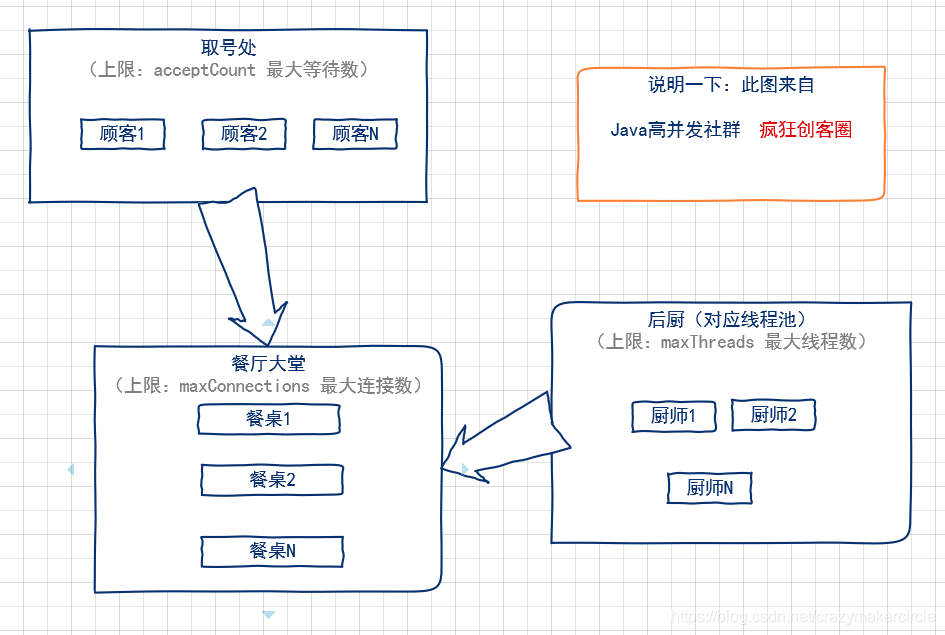
1.4.3 图解:maxConnections、maxThreads、acceptCount关系
用一个形象的比喻,通俗易懂的解释一下tomcat的最大线程数(maxThreads)、最大等待数(acceptCount)和最大连接数(maxConnections)三者之间的关系。
我们可以把tomcat比做一个火锅店,流程是取号、入座、叫服务员,可以做一下三个形象的类比:
- (1)acceptCount 最大等待数
可以类比为火锅店的排号处能够容纳排号的最大数量;排号的数量不是无限制的,火锅店的排号到了一定数据量之后,服务往往会说:已经客满。 - (2)maxConnections 最大连接数
可以类比为火锅店的大堂的餐桌数量,也就是可以就餐的桌数。如果所有的桌子都已经坐满,则表示餐厅已满,已经达到了服务的数量上线,不能再有顾客进入餐厅了。 - (3)maxThreads:最大线程数
可以类比为厨师的个数。每一个厨师,在同一时刻,只能给一张餐桌炒菜,就像极了JVM中的一条线程。
整个就餐的流程,大致如下:
- (1)取号:如果maxConnections连接数没有满,就不需要取号,因为还有空余的餐桌,直接被大堂服务员领上餐桌,点菜就餐即可。如果 maxConnections 连接数满了,但是取号人数没有达到 acceptCount,则取号成功。如果取号人数已达到acceptCount,则拿号失败,会得到Tomcat的Connection refused connect 的回复信息。
- (2)上桌:如果有餐桌空出来了,表示maxConnections连接数没有满,排队的人,可以进入大堂上桌就餐。
- (3)就餐:就餐需要厨师炒菜。厨师的数量,比顾客的数量,肯定会少一些。一个厨师一定需要给多张餐桌炒菜,如果就餐的人越多,厨师也会忙不过来。这时候就可以增加厨师,一增加到上限maxThreads的值,如果还是不够,只能是拖慢每一张餐桌的上菜速度,这种情况,就是大家常见的“上一道菜吃光了,下一道菜还没有上”尴尬场景。
maxConnections、maxThreads、acceptCount关系图如下
Zuul 信号量上限配置(暂时不用,我们使用了熔断器线程池)
zuul: semaphore: max-semaphores: 250 # 当Zuul的隔离策略为SEMAPHORE时, 设置默认最大信号量,会影响 ribbon 往后方调用
Zuul 默认每个路由的信号量是 100。
注:我们知道 Hystrix 有隔离策略:THREAD 以及 SEMAPHORE ,默认是 SEMAPHORE 。
查询资料发现是因为zuul默认每个路由直接用信号量做隔离,并且默认值是100,也就是当一个路由请求的信号量高于100那么就拒绝服务了,返回500。
线程池提供了比信号量更好的隔离机制,并且从实际测试发现高吞吐场景下可以完成更多的请求。但是信号量隔离的开销更小,对于本身就是10ms以内的系统,显然信号量更合适。
当 zuul.ribbonIsolationStrategy=THREAD时,Hystrix的线程隔离策略将会作用于所有路由。
此时,HystrixThreadPoolKey 默认为“RibbonCommand”。这意味着,所有路由的HystrixCommand都会在相同的Hystrix线程池中执行。可使用以下配置,让每个路由使用独立的线程池:
https://blog.csdn.net/w1014074794/article/details/88571880
Hystrix 熔断器线程池配置
uul: ribbon-isolation-strategy: thread # threadPool: useSeparateThreadPools: true # 每个路由使用独立的线程池,只有在隔离策略是thread才有效 hystrix: threadpool: default: core-size: 100 # 线程池核心线程数,它会影响总体的并发数,默认 10 maximumSize: 2000 # 此属性设置最大线程池大小。这是可在拒绝命令执行的最大并发量。请注意, 如果您必须同时设置 allowMaximumSizeToDivergeFromCoreSize allowMaximumSizeToDivergeFromCoreSize: true #此属性允许 maximumSize 的配置生效,如果maximumSize 大于 coreSize 配置,则在 keepAliveTimeMinutes 时间后回收线程 maxQueueSize: -1 #(最大排队长度。默认-1,使用SynchronousQueue。其他值则使用 LinkedBlockingQueue。如果要从-1换成其他值则需重启,即该值不能动态调整,若要动态调整,需要使用到下边这个配置 command: default: execution: isolation: thread: timeoutInMilliseconds: 1000 # 熔断超时时间,它和 ribbon 超时时间谁小以谁为准 hystrix: command: ms-consumer: execution: isolation: thread: timeoutInMilliseconds: 60000
Ribbon 上限配置
ms-consumer: ribbon: ConnectTimeout: 6000 # 与熔断超时有关 ReadTimeout: 6000 #MaxTotalHttpConnections: 2000 MaxTotalConnections: 2000 MaxConnectionsPerHost: 2000
注意:如果配置了 MaxConnectionsPerHost 但是没有配置 Zuul 信号量,默认并发会被限制在 100。
ribbon.ReadTimeout, ribbon.SocketTimeout这两个就是ribbon超时时间设置,当在yml写时,应该是没有提示的,给人的感觉好像是不是这么配的一样,其实不用管它,直接配上就生效了。
还有zuul.host.connect-timeout-millis,
zuul.host.socket-timeout-millis这两个配置,这两个和上面的ribbon都是配超时的。区别在于,如果路由方式是serviceId的方式,那么ribbon的生效,如果是url的方式,则zuul.host开头的生效。(此处重要!使用serviceId路由和url路由是不一样的超时策略)
如果你在zuul配置了熔断fallback的话,熔断超时也要配置,不然如果你配置的ribbon超时时间大于熔断的超时,那么会先走熔断,相当于你配的ribbon超时就不生效了。
熔断超时是这样的:
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds: 60000
default代表默认
熔断器降级触发条件(知
#熔断器失败的个数==进入熔断器的请求达到1000时服务降级(之后的请求直接进入熔断器) hystrix.command.default.circuitBreaker.requestVolumeThreshold=1000
断路器
(1)hystrix.command.default.circuitBreaker.requestVolumeThreshold(当在配置时间窗口内达到此数量的失败后,进行短路。默认20个)
For
example, if the value is 20, then if only 19 requests are received in
the rolling window (say a window of 10 seconds) the circuit will not
trip open even if all 19 failed.
简言之,10s内请求失败数量达到20个,断路器开。
(2)hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds(短路多久以后开始尝试是否恢复,默认5s)
(3)hystrix.command.default.circuitBreaker.errorThresholdPercentage(出错百分比阈值,当达到此阈值后,开始短路。默认50%)
fallback
hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests(调用线程允许请求HystrixCommand.GetFallback()的最大数量,默认10。超出时将会有异常抛出,注意:该项配置对于THREAD隔离模式也起作用)
https://blog.csdn.net/tongtong_use/article/details/78611225
consumer feign 配置
feign: client: config: default: connectTimeout: 20000 readTimeout: 20000 httpclient: enabled: true max-connections: 2000 # 默认值200 max-connections-per-route=: 2000 # 默认值为50 ribbon: MaxConnectionsPerHost: 2000 MaxTotalConnections: 2000 ConnectTimeout: 60000 # 请求连接的超时时间 默认的时间为 1 秒 ReadTimeout: 60000 # 请求处理的超时时间
Feign参数调优
在默认情况下 spring cloud feign在进行各个子服务之间的调用时,http组件使用的是jdk的HttpURLConnection,没有使用线程池。
xxx 回退最大线程数 hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests=50 #核心线程池数量 hystrix.threadpool.default.coreSize=130 #请求处理的超时时间 hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=100000
SpringBoot 关于Feign的超时时间配置
无独有偶,我今天也遇到了一个关于 feign 超时时间配置的问题。
今天项目现场提过来一个问题 “公司发过来的封装好的 springboot 项目中的 feign 调用超时时间需要修改”,细问之后,具体的需求场景是这样的:
1、首先要对 feign 的超时时间做设置
2、然后具体的要求是,只要对某一个微服务的其中一个接口进行特殊配置,对其余的所有接口做一个统一配置
公司 feign 版本 spring-cloud-starter-openfeign 2.2.3.RELEASE ,其他版本自行尝试
基于 @FeignClient 的声明式接口调用
一个实际的代码示例:
@FeignClient(name = "${microservice.servicename.id:shanhy-id}", path = "/${microservice.servicename.id:shanhy-id}", url = "${microservice.serviceurl.id:}") public interface IdFeignClient { (代码略) }
顺着这个问题,我思考了一下,扒了下 feign 调用的相关源码,下面直接给出结论(因为比较忙时间有限这里就不做源码分析了):
1、feign 调用与超时有关的参数分为 连接超时时间 connect-timeout 和 读取超时时间read-timeout
2、这两个参数的默认值分别为 10秒 和 60秒
3、如果要对这两个参数进行配置,那么对应的配置方法如下
feign.client.config.default.connect-timeout=5000 feign.client.config.default.read-timeout=30000
(单位毫秒)
4、当前代码工程中有好几个 @FeignClient 声明,分别调用了不同的其他服务,如果要单独为这个 shanhy-id 服务设置这两个超时时间,那么对应的配置方法如下:
feign.client.config.shanhy-id.connect-timeout=2000 feign.client.config.shanhy-id.read-timeout=5000
注意和默认的区别就是中间那一段,将 default 替换为 shanhy-id,这个和 @FeignClient 中的 name 属性一致
5、如果需要针对某一个服务中的某一个或几个接口做特殊配置,那么就为这个特殊接口单独写一个 @FeignClient 接口定义,并为设置一个 contextId 设置一个和 name 不重名的名字,保证唯一,下面是例子:
@FeignClient(name = "${microservice.servicename.id:shanhy-id}", path = "/${microservice.servicename.id:shanhy-id}", url = "${microservice.serviceurl.id:}", contextId = "shanhy-id-2" ) public interface IdFeignClient { (代码略) }
然后对应的配置为:
feign.client.config.shanhy-id-2.connect-timeout=3000 feign.client.config.shanhy-id-2.read-timeout=15000
其实系统启动的时候,会为每一个 @FeignClient 定义的接口形成代理类然后进行配置,contextId 是当前 FeignClient 相关参数在 FeignContext 上下文中的 key,通过 contextId 来区分不同 FeignClient 的配置,如果 contextId 没有配置则使用 name 作为上限文中的 key,与超时时间之外的其他相关配置详见 FeignClientConfiguration
至此,问题解决。
问题:
The Hystrix timeout of 60000ms for the command service-basic is set lower than the combination of the Ribbon read and connect timeout, 240000ms。
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=60000
请求处理的超时时间,单位为毫秒
ribbon.ReadTimeout=60000
请求连接的超时时间,单位为毫秒
ribbon.ConnectTimeout=60000
对当前实例的重试次数,默认为0
ribbon.MaxAutoRetries=0
切换实例的重试次数,默认为0
ribbon.MaxAutoRetriesNextServer=1
我原本的配置为:
这句话的意思是:你熔断器(Hystrix )的时间小于,负载均衡(Ribbon )的超时时间了
具体的超时时间排序应该为:
具体服务的hytrix超时时间 > 默认的hytrix超时时间 > ribbon超时时间
其中ribbon的计算方法为:
ribbonTimeout = (60000 + 60000) * (0 + 1) * (1 + 1) = 240000
所以如果默认的或者体服务的hytrix超时时间小于ribbon超时时间就会警告
将Hystrix超时时间设置超过240000即可。
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=1800000 #请求处理的超时时间,单位为毫秒 ribbon.ReadTimeout=60000 #请求连接的超时时间,单位为毫秒 ribbon.ConnectTimeout=60000 #对当前实例的重试次数,默认为0 ribbon.MaxAutoRetries=0 #切换实例的重试次数,默认为0 ribbon.MaxAutoRetriesNextServer=1
