

k8s入坑之路(1)kubernetes基础概念
了解kubertnetes

kubernetses在古希腊语中意味着舵手的意思,docker把自己比作一条鲸鱼承载着各种集装箱货物在大海遨游。谷歌就要用kubernetes掌握这条鲸鱼带领着他的航行方向。

kubetnetes是一个open-source system 开源系统,是为了自动化,让我们的应用部署、扩缩容、管理容器化的应用自动化。
kebetnetes是谷歌15年的生产环境的经验积累,经过了大量的实践验证过的,并且融合社区优秀的ider和经验。2017年kubernetes在容器编排大战中胜出。

一切以服务为中心, 使用者不用去关心运行的环境运行的细节,构建在kubernetes上的系统不仅可以独立运行在物理机虚拟机私有云公有云等在任何宿主机运行都是无差别的。
在kubernetes中的服务,可以自动的扩缩容、更新、升级、部署。在受到相应的指令后,他会触发一个调度流程,选中目标节点部署或停止相应的服务,如果有新的服务启动会自动的加入相应的负载均衡器自动的生效,运行的过程中kubernetes会定期检查他们的实例数以及他们运行的状态。当发现 某个实例不可用的情况会销毁重新创建一个实例。不需要人工参与
kubernetes是以docker的技术标准为基础,去打造一个全新的分布式架构系统。kubernetes并不需要底层一定是docker,需要的只是docker的一种技术标准,只要实现了这个标准的产品都可以替代docker。
kubernetes核心概念
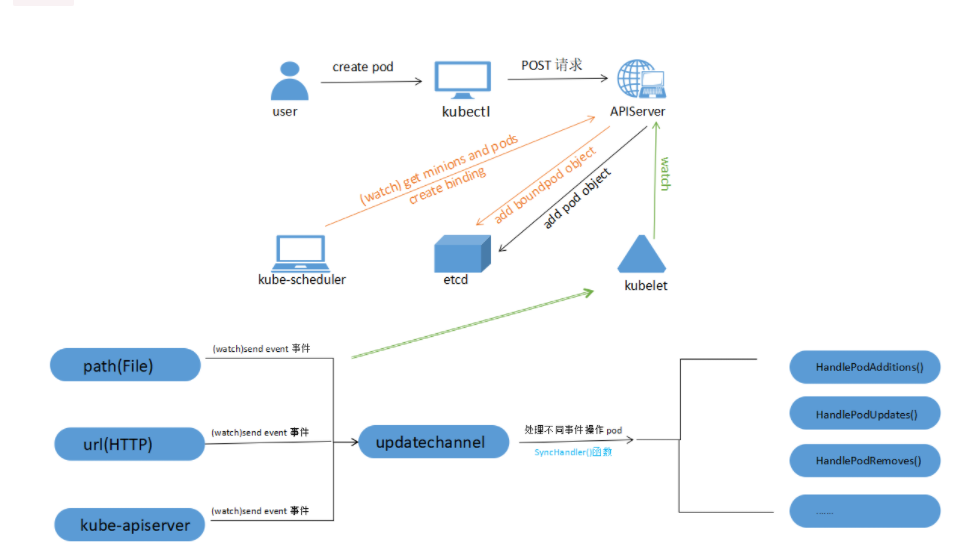
pod创建过程:
1.通过yaml或命令创建新的pod
2.kubectl将事件写入apiserver
3.apiserver将该pod事件写入etcd
4.watch API监听apiserver状态
5.将事件放入FIFO队列,Informe取出事件,将事件写入DeltaFIFO缓存中,kubescheduler通过pod是否绑定主机,为pod进行调度绑定并写入etcd。
6.LocalStore读取缓存进行更新,store同步,更新controller。controller读取node节点是否部署。
7.kubelet通过send even触发事件进行创建。
pod replicaset deployment
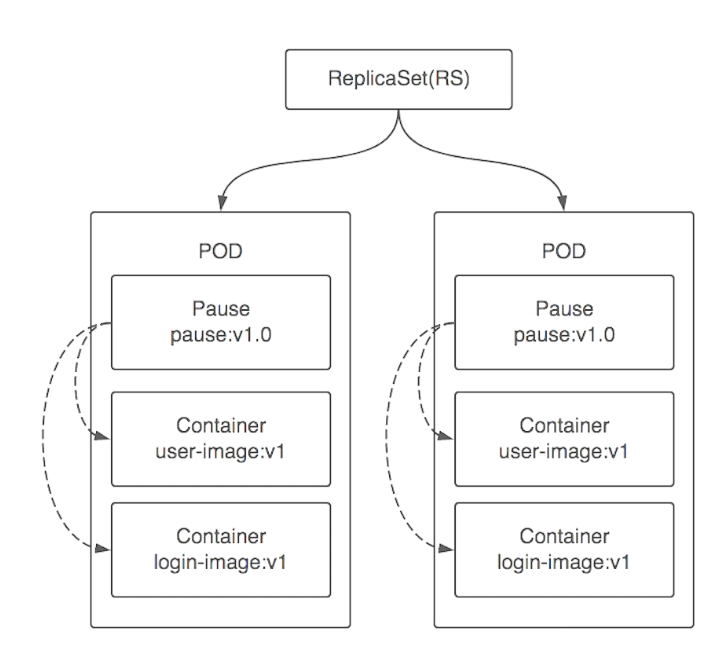
pod运行在containerd之上,每个pod中都运行了pause镜像。负责将pod中的容器link到一起以及容器的健康检查。同一个pod中的容器共享一个networknamespace以及一个命名空间所以同一个pod下的容器会共享一个hostname,一个ip地址。通过端口来指定不通的服务。
replicaset(复制集)是运行于pod之上,复制pod副本集数量的创建监测等,当replicaset中pod出现问题不满足副本集数量时会将故障的pod销毁,重新部署。在kubetnetes1.6以后官方将rs特意的隐藏掉不需要用户过多的去关注,转而又deployment封装rc。
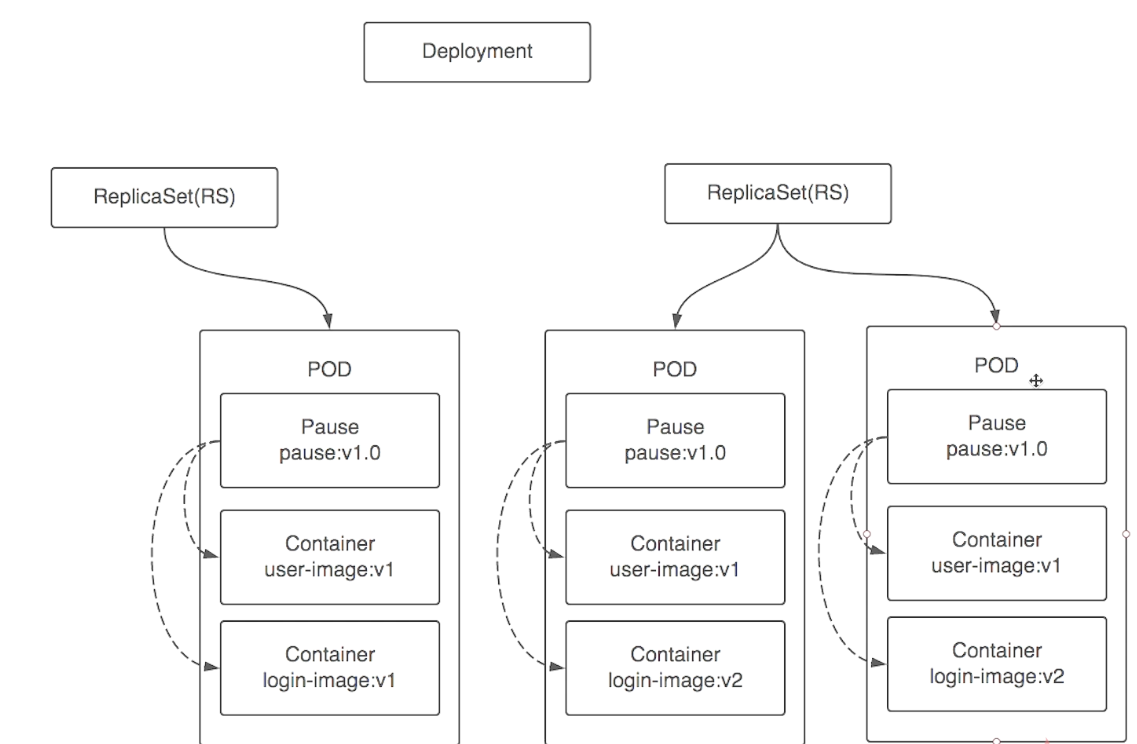
deployment更新本质上是管理rs。当有更新时会按照定义的策略去重新创建一个rc及pod,删掉旧的rs下指定数量的pod,然后新的在更新一个pod。旧的rs把pod及rc都删除。
deployment滚动更新:
service流程:
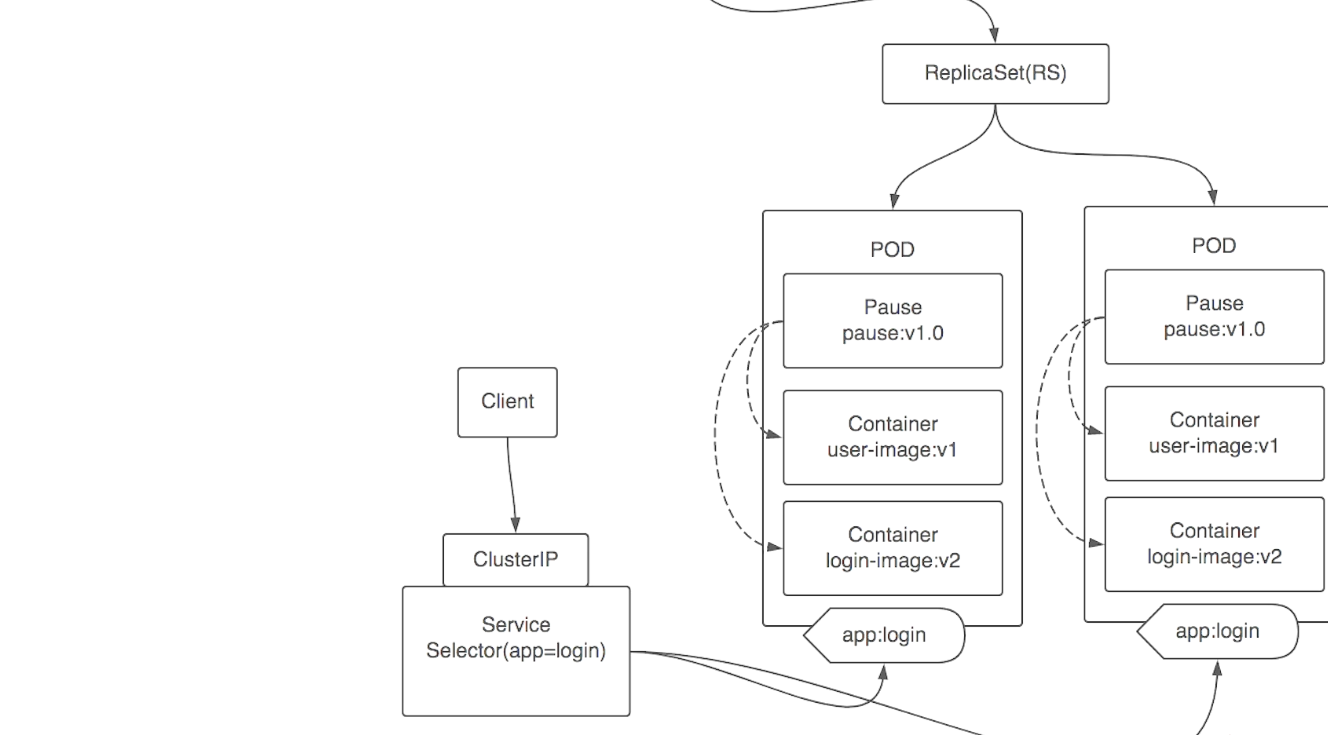
service通过标签选择同一命名空间下的pod进行负载,service对外提供了一个clusterIP可供集群内访问。通过ClusterIP将请求发送到service,service通过内核级IPVS将后端pod信息录入然后进行负载,请求到达pod所在的node后由kube-proxy进行分发到具体的pod。
service要实现负载需与node中kube-proxy进行结合。kube-proxy负载与service的通信。
kube-proxy和service背景
说到kube-proxy,就不得不提到k8s中service,下面对它们两做简单说明:
kube-proxy其实就是管理service的访问入口,包括集群内Pod到Service的访问和集群外访问service。 kube-proxy管理sevice的Endpoints,该service对外暴露一个Virtual IP,也成为Cluster IP, 集群内通过访问这个Cluster IP:Port就能访问到集群内对应的seri vc e下的Pod。 service是通过Selector选择的一组Pods的服务抽象,其实就是一个微服务,提供了服务的LB和反向代理的能力,而kube-proxy的主要作用就是负责service的实现。 service另外一个重要作用是,一个服务后端的Pods可能会随着生存灭亡而发生IP的改变,service的出现,给服务提供了一个固定的IP,而无视后端Endpoint的变化。
kube-proxy内部原理:
kube-proxy当前实现了两种proxyMode:userspace和iptables。其中userspace mode是v1.0及之前版本的默认模式,从v1.1版本中开始增加了iptables mode,在v1.2版本中正式替代userspace模式成为默认模式。
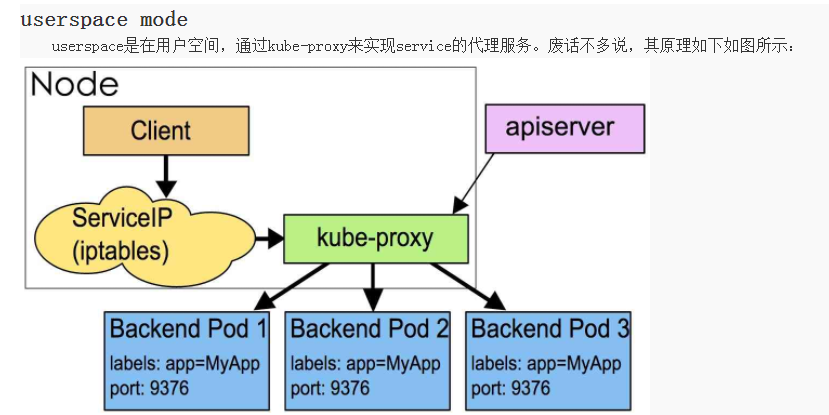
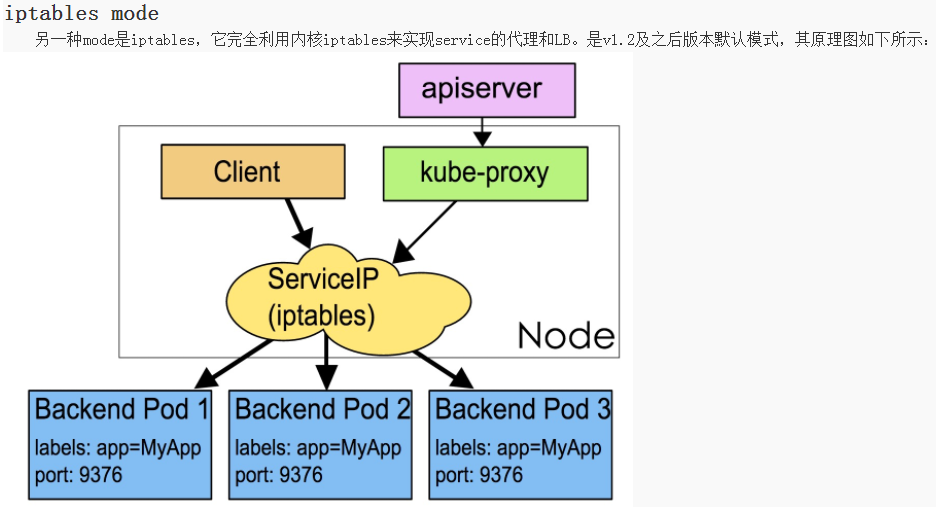
iptables mode因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存在上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折扣。这也导致,目前大部分企业用k8s上生产时,都不会直接用kube-proxy作为服务代理,而是通过自己开发或者通过Ingress Controller来集成HAProxy, Nginx来代替kube-proxy。
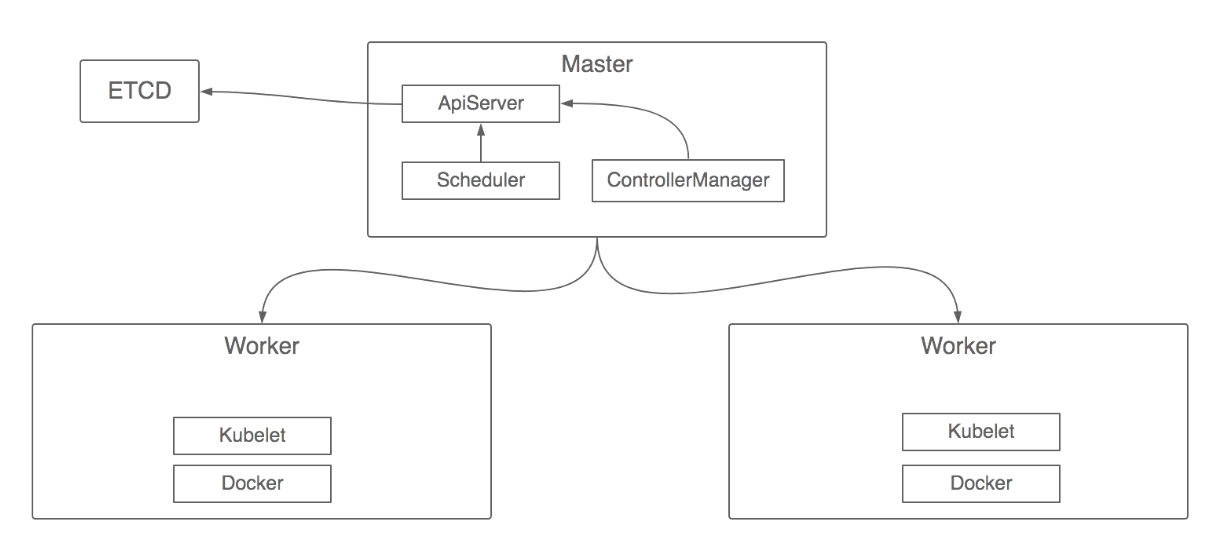
kubernetes的架构设计
kubernetes认证的密码学原理
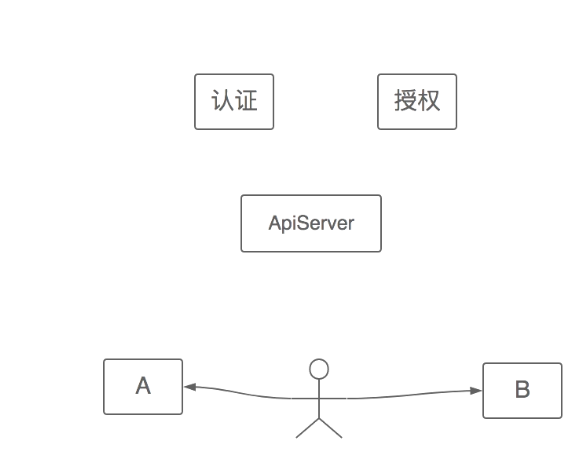
通过apiserver进行认证与授权
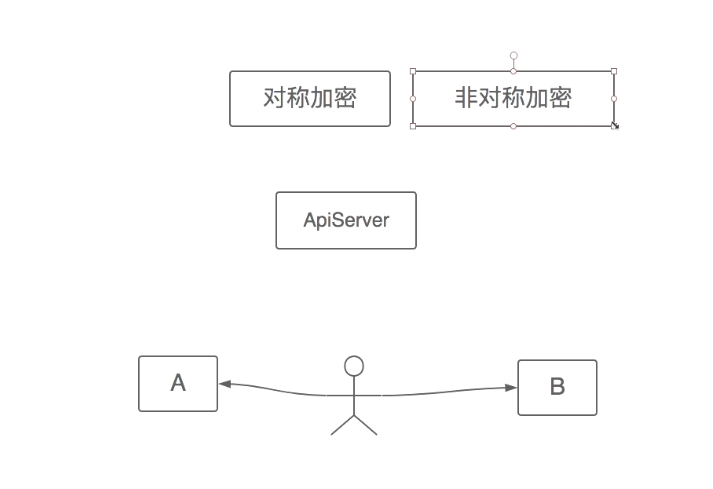
加密分为对称加密与非对称加密,对称加密是指双方约定好公私钥进行加密解密校验通信。非对称加密是指在对称加密之前先校验此次通信加密的合法性,先行校验随后在进行对称加密。为了保证非对称加密的可靠性,所以用到了中立的ca证书,来进行校验服务端是否可信。TLS/SSL加密协议
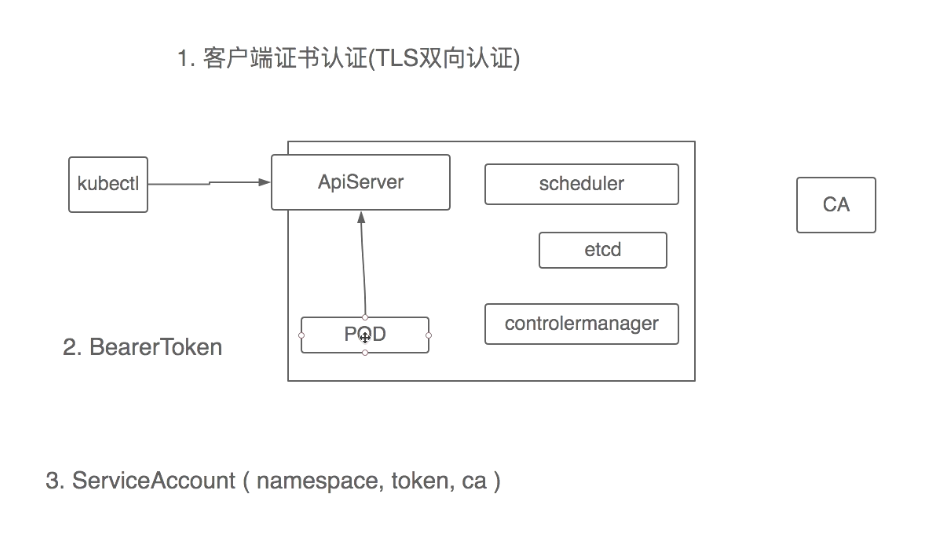
kubernetes提供了三种认证方式基于证书的TLS双向认证。以及秘钥token认证,内部通讯使用ServiceAccount将证书以及token等信息挂载到pod指定目录中然后pod可与serviceapi进行通信。
kubernetes授权

三种授权策略,kubernetes1.6版本以后使用RBAC模型。
RBAC是什么?
RBAC 是基于角色的访问控制(Role-Based Access Control )在 RBAC 中,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。这就极大地简化了权限的管理。这样管理都是层级相互依赖的,权限赋予给角色,而把角色又赋予用户,这样的权限设计很清楚,管理起来很方便。
RBAC介绍。
RBAC 认为授权实际上是Who 、What 、How 三元组之间的关系,也就是Who 对What 进行How 的操作,也就是“主体”对“客体”的操作。
Who:是权限的拥有者或主体(如:User,Role)。
What:是操作或对象(operation,object)。
How:具体的权限(Privilege,正向授权与负向授权)。
然后 RBAC 又分为RBAC0、RBAC1、RBAC2、RBAC3 .
kubernetes授权设计:
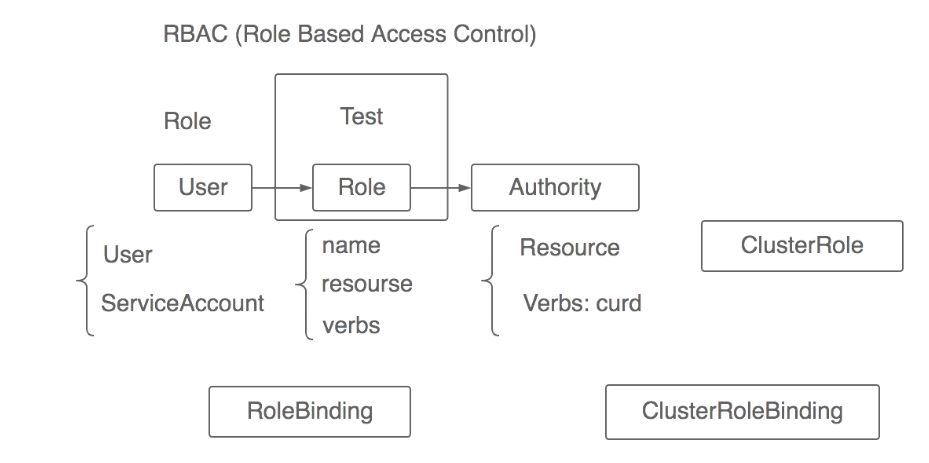
RBAC设计分为用户层,角色层,资源权限层。
用户层分为普通用户user,集群内部访问用户ServiceAccount。
资源动作层,包含resource(namespace等), verbs:一般的动作分为:list create update place小更新 delete等。
角色层分为当前角色名称,包含资源(当前namespace下),执行动作等。
k8s内部并无数据库来存储关系表所以需要RoleBinding,角色绑定。然后可以执行当前角色namespace下资源相对应的工作。如需全局权限则需要ClusterRole,并进行ClusterRolebinding。
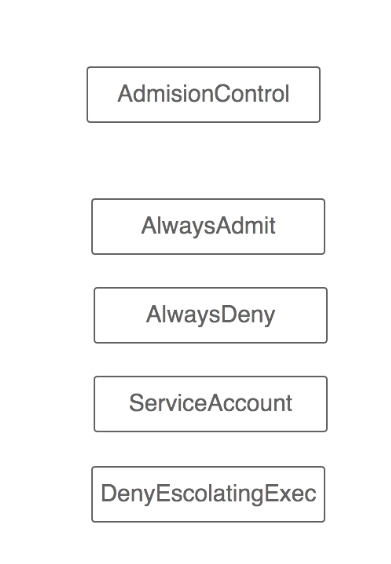
角色授权完毕后还需准入控制,对角色进行入口或请求控制Adminsioncontrol。
大体有AlwayAdmit允许所有,AlwaysDeny拒绝所有,ServiceAccoun
t协助serviceaccount对没有角色的pod等颁发当前namespace下默认的serviceaccount。DenyEscolatingExec拒绝exec动作。
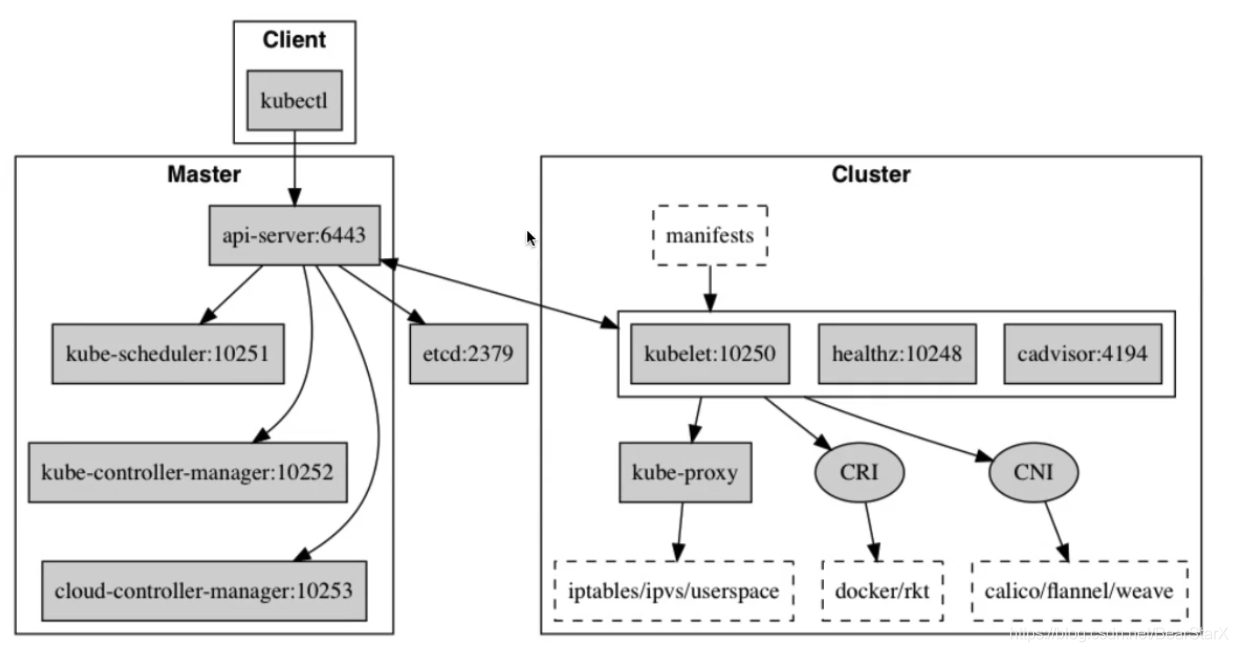
kubenetes各组件端口
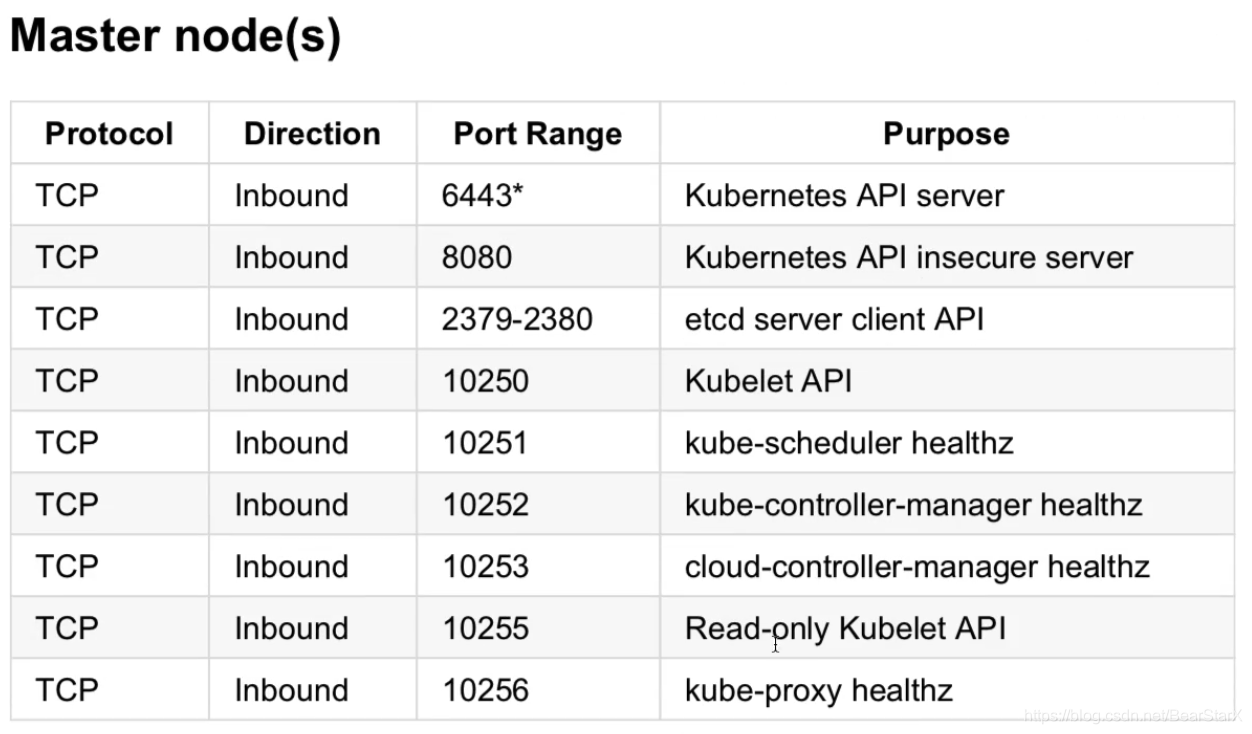
以下是Master节点的端口列表
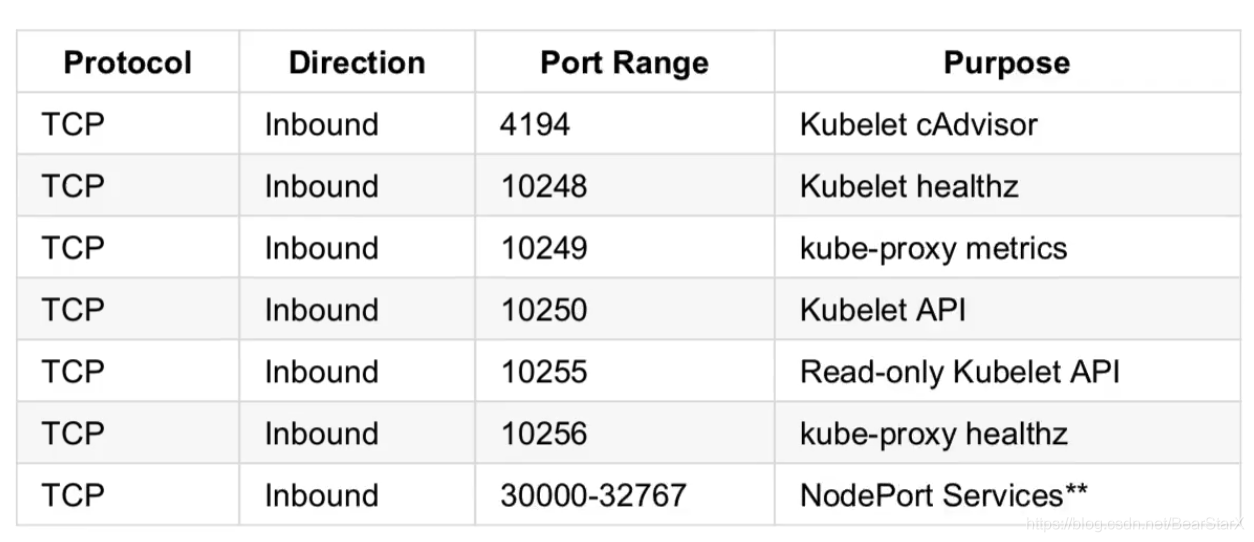
以下是node节点的端口列表
api-service: 使用6443端口进行通信,可开启8080网页登录查看信息。默认会生成kubernetes的service 使用cluster网关ip 后端对应master service-ip。
kube-controller: metric端口为10252,内部加密通讯端口为10257。
kube-scheduler: metric端口为10251,内部加密通讯端口为10259。
kubelet: 监听的端口10250,api会检测他是否存活 。10248 –healthz-port: 健康检查服务的端口 。10255 –read-only-port: 只读端口,可以不用验证和授权机制,直接访问 。4194 –cadvisor-port: 当前节点 cadvisor 运行的端口。
kube-proxy: metric端口为10249,healthz端口10256。
NodePort:默认生成端口30000-32767
ingress: metric端口10254
nocache: 端口53
calico: 端口9099
etcd: 对外访问端口2379,内部通信2380端口。
prometheus: 9090端口
grafan: 3000端口
alertmanager: 9093端口
kafka: 9092端口
es : 9200端口
elk组件各版本7.6.2 zookeeper版本3.6 kafka2.12 promethus版本2.2 docker版本1.17 1.16 k8s版本1.20.2 1.17 1.19 1.16.10几个版本有问题ipset无锁冲突 grafan7.x
