爬虫 爬取微信公众号
本文在网上找到有三种爬取方法
1.使用订阅号功能里的查询链接 , (此链接现在反扒措施严重,爬取几十页会封订阅号,仅供参考,)
详情请访问此链接:https://cuiqingcai.com/4652.html
2.使用搜狗搜索的微信搜索(此方法只能查看每个微信公众号的前10条文章)
详情请访问此链接:https://blog.csdn.net/qiqiyingse/article/details/70050113
3.先抓取公众号的接口,访问接口获取全部文章连接(详细讲解此方法,如下:)
1> 使用抓包工具Charles抓取公众号接口:
下载Charles请访问:https://www.charlesproxy.com/download/
使用方法 百度 一大堆
废话少说,进入正题:
首先登陆微信(电脑,手机端都可以,Charles也可以抓取手机端的接口,不过需要设置,推荐登陆电脑客户端微信)点击订阅号,点进去需要爬取的微信公众号。
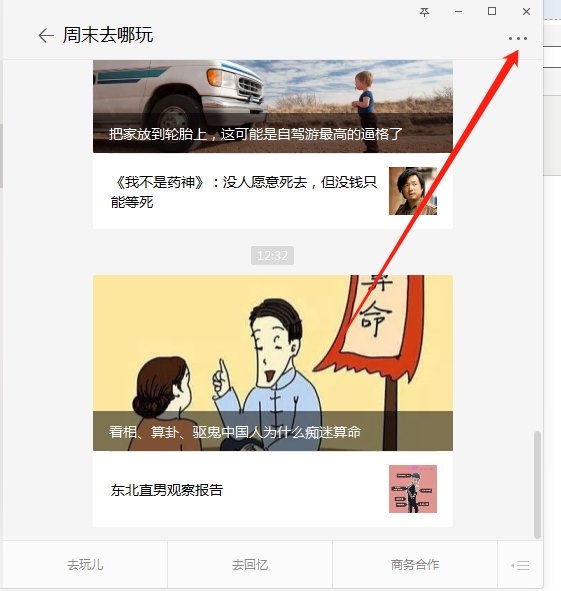 点击右上角,有一个历史文章查看
点击右上角,有一个历史文章查看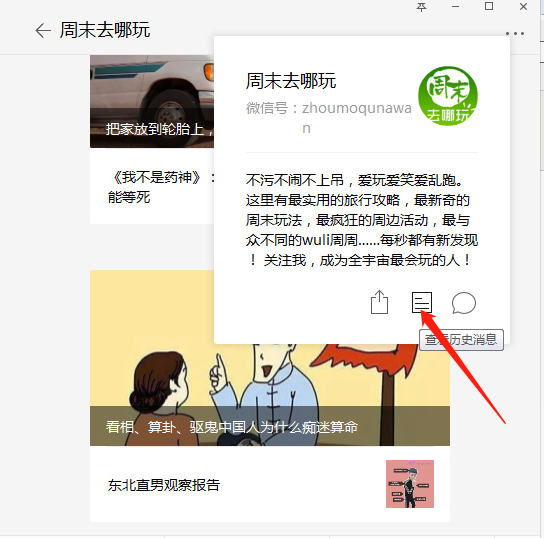 ,准备好点击此处
,准备好点击此处
运行装好的charles。 然后点击查看历史文章的按钮,此时charles出现一个
 ,
, 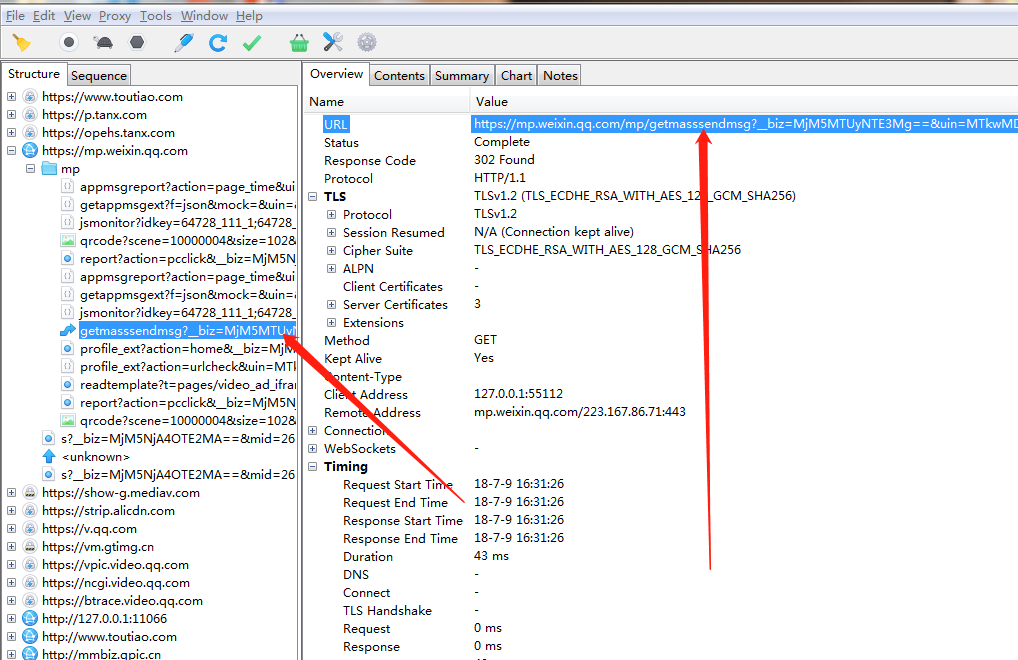
此接口就是此公众号的接口,复制此接口,在浏览器中打开此网址如图:
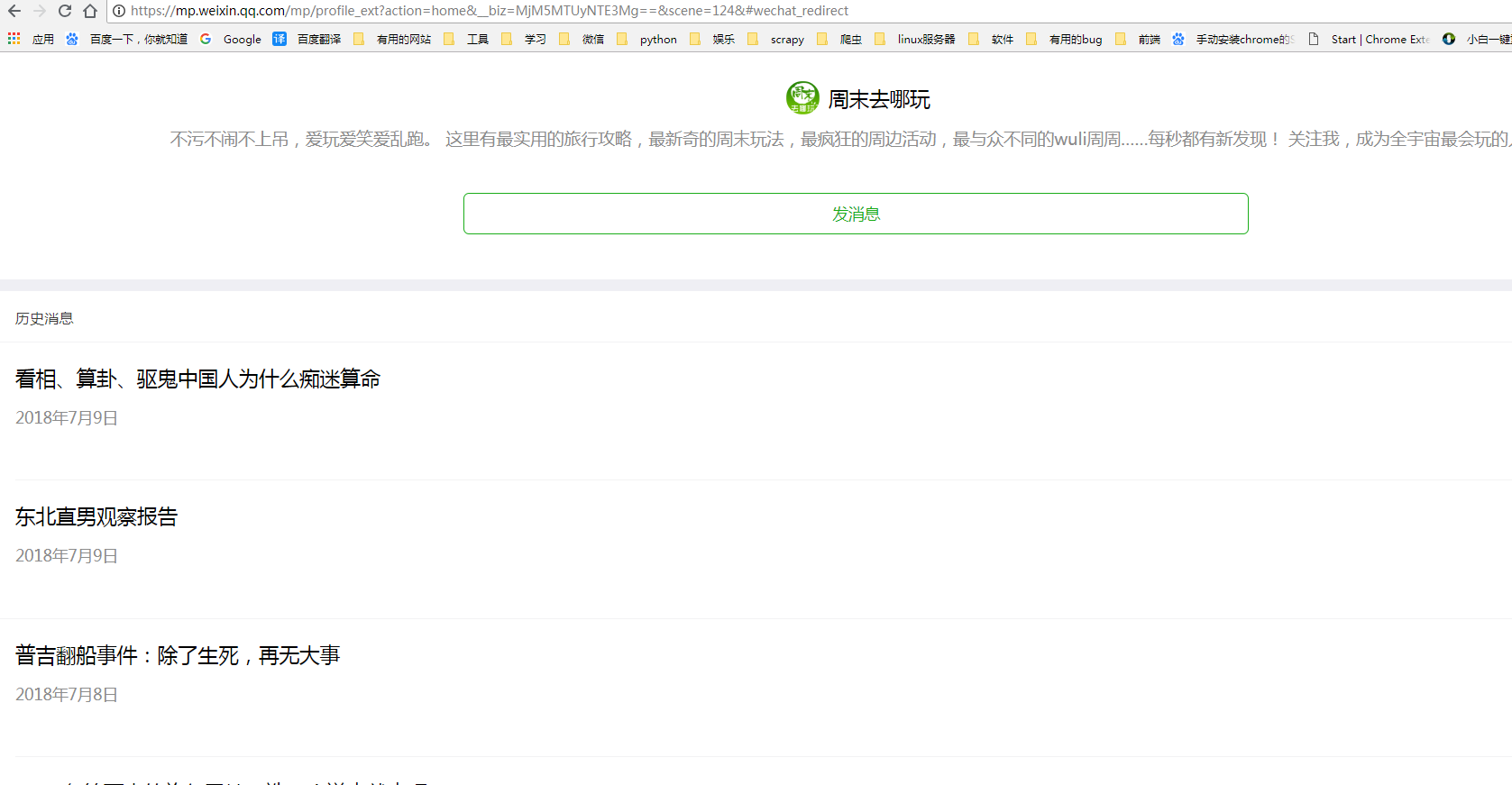
如果提示请在微信中打开此链接,有两个原因:
001 。需设置headers为微信浏览器的headers
002 。 链接有效时间为半个小时,超过半小时 链接里的key值过期,重新获取一下链接即可
谷歌浏览器设置headers:
按F12打开开发者选项 , 点击此处
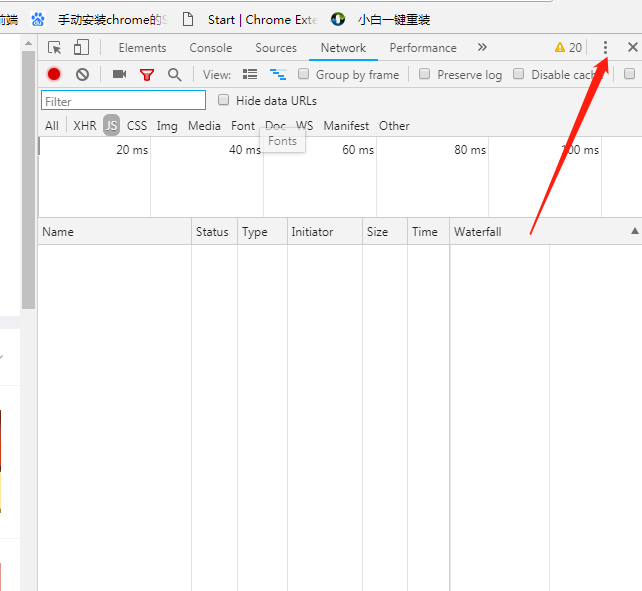
点击

点击
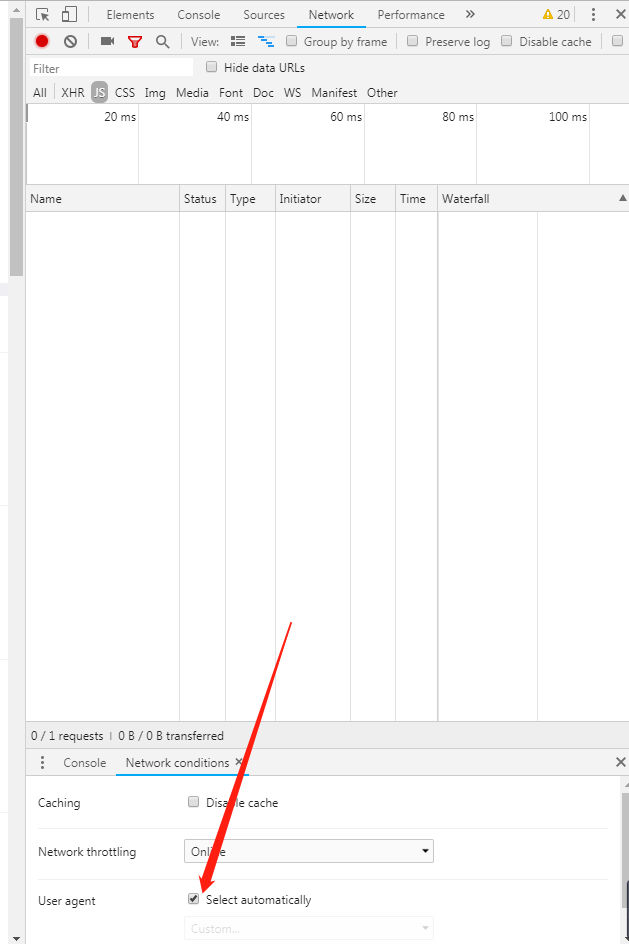
点击

再次冲输入微信浏览器的headers
微信headers : Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.884.400 QQBrowser/9.0.2524.400
.到此,可以进行第二部 selenuim+chromdriver,因为使用的是js加载,
2 。selenuim+chromdriver , 打开上文找到的接口,模拟浏览器翻页,一直翻页到最下边,获取整个文章的链接,并保存。
不多赘述,直接上代码!
1 from selenium import webdriver 2 import time , requests 3 from lxml import etree 4 from pyquery import PyQuery as pq 5 import re 6 7 8 9 url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MjM5MTUyNTE3Mg==&scene=124&#wechat_redirect" 10 11 # Chromedriver 12 opt = webdriver.ChromeOptions() 13 # prefs = {'profile.default_content_setting_values': {'images': 2}} 14 # opt.add_experimental_option('prefs', prefs)#这两行是关闭图片加载 15 opt.add_argument('Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.884.400 QQBrowser/9.0.2524.400')#设置headers 16 # # opt.add_argument('--headless')#此行打开无界面 17 driver = webdriver.Chrome(options=opt) 18 19 driver.get(url) 20 21 top = 1 22 while 1: 23 html = etree.HTML(driver.page_source) 24 downss = html.xpath('//*[@id="js_nomore"]/div/span[1]/@style') 25 if downss[0] == "display: none;": 26 time.sleep(0.5) 27 js = "var q=document.documentElement.scrollTop="+str(top*2000) 28 driver.execute_script(js)#模拟下滑操作 29 top += 1 30 time.sleep(1) 31 else: 32 break 33 html = etree.HTML(driver.page_source) 34 bodyContent = html.xpath('//*[@id="js_history_list"]/div/div/div/div/h4/@hrefs')#获取文章的所有链接 35 36 #保存本地 37 fp = open("./aother.txt", "w+") 38 for i in bodyContent: 39 fp.write(str(i) + "\n") 40 driver.close() 41 fp.close()
接下来就可以挨个爬取文章链接,为所欲为了
,到此,欧了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号