

wfst的compose算法
介绍一些compose算法,以及这部分的代码实现。
原理部分参考: 走进语音识别中的 WFST(二)
可以看下示例图:
我们先来看一下 Composition 的效果,图(a)和图(b)Composition 后生成了图(c),从这么简单的效果图我们大致可以看出来其实这个操作就是找出满足下面这个条件的转移:第一个 WFST 的某个转移上的输出标签等于第二个 WFST 的某个转移上的输入标签,然后把这些转移上的 label 和 weight 分别进行操作:

当然上面的大白话肯定是不严谨、不完全正确的,下面我们将结合下伪代码来介绍正确的生成方式。需要注意的是,这里是一个 epsilon-free 的算法,即第一个 WFST 的任意转移上的输出 label 不能为空(εε)并且第二个 WFST 的任意转移上的输入 label 也不能为空(εε)。


下图做了个流程的示范,笔写比较方便一点。其实只要认真看懂了上面的伪代码这边就可以跳过不看了。


下面在代码里验证一下刚刚的例子:
$ cat A.fst 0 1 a b 0.1 0 2 b a 0.2 1 3 a a 0.4 1 1 c a 0.3 2 3 b b 0.5 3 0.6 $ cat B.fst 0 1 b c 0.3 1 2 a b 0.4 2 2 a b 0.6 2 0.7 $ cat words.txt a 1 b 2 c 3
#注意,符号表不能有0 fstcompile --isymbols=words.txt --osymbols=words.txt A.fst|fstarcsort --sort_type=olabel > A.bfst fstcompile --isymbols=words.txt --osymbols=words.txt B.fst|fstarcsort --sort_type=ilabel > B.bfst fstprint A.bfst >A.fst.txt fstprint B.bfst >B.fst.txt fsttablecompose A.bfst B.bfst | fstarcsort > C.bfst #fstcompose A.bfst B.bfst >C.bfst #两个之间结果是一样的 fstprint C.bfst > C.fst fstdraw --width=25 --height=20 --isymbols=words.txt --osymbols=words.txt C.bfst > Cfst.dot #画出dot图 fstdraw --width=25 --height=20 --isymbols=words.txt --osymbols=words.txt A.bfst > Afst.dot fstdraw --width=25 --height=20 --isymbols=words.txt --osymbols=words.txt B.bfst > Bfst.dot dot -Tpng Afst.dot > A.png #画png图 dot -Tpng Bfst.dot > B.png dot -Tpng Cfst.dot > C.png
这里已经我的注释里面了,符号表words.txt里是不能有0的,可以试一下,有0结果就会错了,猜测是fst默认0是终止吧,尽量我们不用0吧。
我们来看下生成的最终的png图,和例子是一样的。
A: 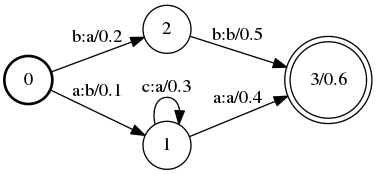
B: 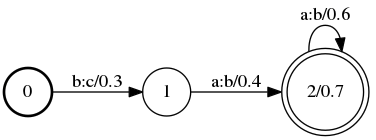
C: 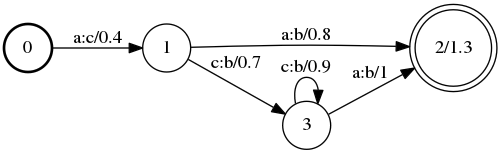

 浙公网安备 33010602011771号
浙公网安备 33010602011771号