

scrapy-redis 更改队列和分布式爬虫
这里分享两个技巧
1.scrapy-redis分布式爬虫
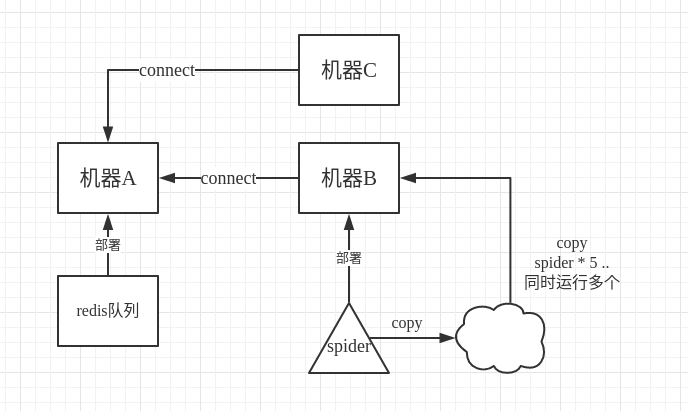
我们知道scrapy-redis的工作原理,就是把原来scrapy自带的queue队列用redis数据库替换,队列都在redis数据库里面了,每次存,取,删,去重,都在redis数据库里进行,那我们如何使用分布式呢,假设机器A有redis数据库,我们在A上把url push到redis里面,然后在机器B上启动scrapy-redis爬虫,在机器B上connect到A,有远程端口可以登入,在爬虫程序里,保存的时候注意启用追加模式,而不是每次保存都删除以前的东西,这样的话,我们可以在B上面多次运行同一个程序。
如图所示,其实连copy都不要,直接另开一个终端,接着运行同样的程序即可。
当然我们也可以在机器C上同样这样运行,所以这就是分布式爬虫。
2.队列不存url改为关键字。
我们的redis队列里保存的是url,正常情况下没毛病,当我们的url不是通过extract网页获取的时候,而是通过构造关键字得到的时候,而且关键字还是很大量的情况下,我们就没有必要在redis里面保存url了,而是直接保存关键字,这样省很大 的内存空间,我们把构造url的任务放到即将要request的时候进行。
当然,这里是改了源码的,如果想这么操作的话,建议在虚拟python环境下进行,安全可靠。
site-packages/scrapy_redis/spiders.py
def make_request_from_data(self, data): """Returns a Request instance from data coming from Redis. By default, ``data`` is an encoded URL. You can override this method to provide your own message decoding. Parameters ---------- data : bytes Message from redis. """ data=data.split(',') if data[1]=='360': a = data[0].strip() vb = {} vb['word'] = a vb['sid'] = 'e13f45a56c8e03b5a2262a6fcab43082' vb['pq'] = vb['word'] url2 = 'https://sug.so.360.cn/suggest?callback=suggest_so&encodein=utf-8&encodeout=utf-8&format=json&fields=word' data2 = urllib.urlencode(vb) geturl2 = url2 + '&' + data2 url = bytes_to_str(geturl2, self.redis_encoding) return self.make_requests_from_url(url)
而在我们的push程序里,是这样子了:
for res in open(file_name,'r'): client.lpush('%s:start_urls' % redis_key, res+',360')
这里只改写了scrapy_redis/spiders.py文件里的类RedisMixin的 make_request_from_data 函数,人家作者吧接口单独预留了,让我们能够看得很清楚,还是很厉害的。
另外,scrapy-redis框架储存内容的时候,是以list形式 储存的,client.lpush ,redis关于list的操作详见 Redis 列表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号