
SRILM语言模型格式解读
先看一下语言模型的输出格式
\data\ ngram 1=64000 ngram 2=522530 ngram 3=173445 \1-grams: -5.24036 'cause -0.2084827 -4.675221 'em -0.221857 -4.989297 'n -0.05809768 -5.365303 'til -0.1855581 -2.111539 </s> 0.0 -99 <s> -0.7736475 -1.128404 <unk> -0.8049794 -2.271447 a -0.6163939 -5.174762 a's -0.03869072 -3.384722 a. -0.1877073 -5.789208 a.'s 0.0 -6.000091 aachen 0.0 -4.707208 aaron -0.2046838 -5.580914 aaron's -0.06230035 -5.789208 aarons -0.07077657 -5.881973 aaronson -0.2173971 (注:上面的值都是以10为底的对数值)
ARPA是常用的语言模型存储格式, 由主要由两部分构成。模型文件头和模型文件体构成。
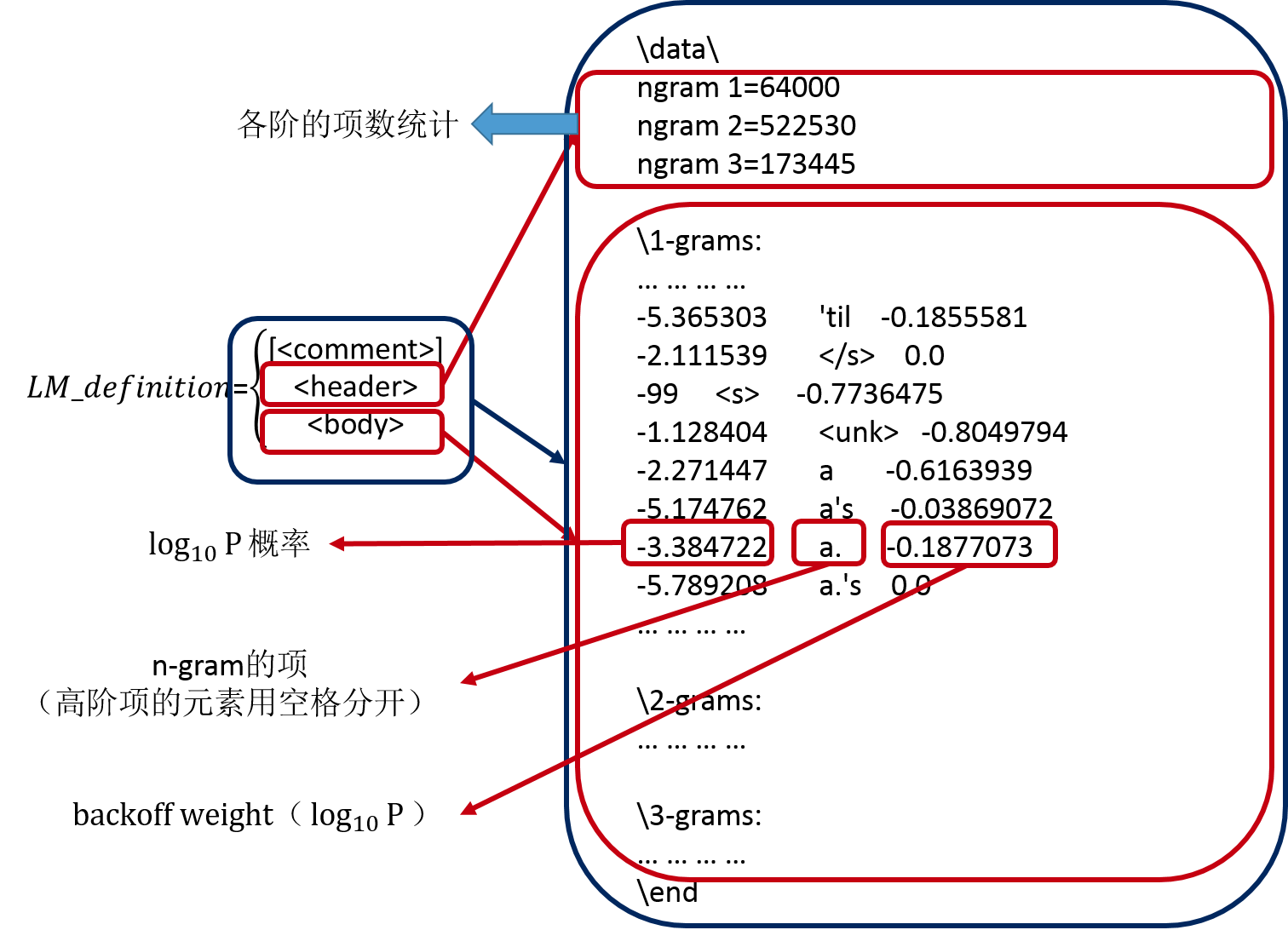
上面是一个语言模型的一部分,三元语言模型的综合格式如下:
\data ngram 1=nr # 一元语言模型 ngram 2=nr # 二元语言模型 ngram 3=nr # 三元语言模型 \1-grams: pro_1 word1 back_pro1 \2-grams: pro_2 word1 word2 back_pro2 \3-grams: pro_3 word1 word2 word3 \end\
第一项表示ngram的条件概率,就是P(wordN | word1,word2,。。。,wordN-1)。
第二项表示ngram的词。
最后一项是回退的权重。
举例来说,对于三个连续的词来说,我们计算三个词一起出现的概率:
P(word3|word1,word2)
表示word1和word2出现的情况下word3出现的概率,比如P(锤|王,大)的意思是已经出现了“王大”两个字,后面是"锤"的概率,这个概率这么计算:
if(存在(word1,word2,word3)的三元模型){ return pro_3(word1,word2,word3) ; }else if(存在(word1,word2)二元模型){ return back_pro2(word1,word2)*P(word3|word2) ; #实际使用的时候是对数,就直接相加 }else{ return P(word3 | word2); }
上面的计算又集中在计算P(word3 | word2)的概率上,就是如果不存在王大锤的三元模型,此时不管何种路径,都要计算P(word3 | word2) 的概率,计算如下:
if(存在(word2,word3)的二元模型){ return pro_2(word2,word3); }else{ return back_pro2(word2)*pro_1(word3) ; }
这个计算的,我们拿个具体的例子来演示一下 :
假设这是我们测的一句3-gram PPL
放 一首 音乐 好 吗 p( 放 | <s> ) = [2gram] 0.00584747 [ -2.23303 ] p( 一首 | 放 ...) = [3gram] 0.00935384 [ -2.02901 ] p( 音乐 | 一首 ...) = [3gram] 0.610533 [ -0.214291 ] p( 好 | 音乐 ...) = [2gram] 2.31318e-06 [ -5.63579 ] p( 吗 | 好 ...) = [3gram] 0.999717 [ -0.000122777 ] p( </s> | 吗 ...) = [3gram] 0.999976 [ -1.04858e-05 ] 1 sentences, 5 words, 0 OOVs 0 zeroprobs, logprob= -10.1123 ppl= 48.4592 ppl1= 105.306
这是我截取的语言模型里的概率,对照上面的解释,我们知道左边是概率,右边是回退概率,都以log10P 来计
-2.233032 <s> 放 -2.999944 -2.02901 <s> 放 一首 -0.7478155 一首 音乐 -3.733402 -1.902389 音乐 好 -3.254402 -0.2142911 放 一首 音乐
对着看:
1.p( 放 | <s> )=p(<s> 放)= -2.233032 OK
2.p( 一首 | 放 ...)=p( 一首 | <s>, 放) = p(<s> 放 一首)=-2.02901 OK
3.p( 音乐 | 一首 ...)=p( 音乐 | 放 , 一首 )=p(放 一首 音乐) = -0.2142911 OK
最难的看下 p( 好 | 音乐 ...),因为这里显示的是2-gram ,而实际上我们是测的3-gram,就要用到上面的公式了:
4.p( 好 | 音乐 ...)=p( 好 | 一首,音乐 )=p(一首 音乐 好) #注意,因为没有p(一首 音乐 好) 的三元组,所以要回退了
=p(音乐 好) x back_p(一首 音乐)= -1.902389 + -3.733402 = -5.635791 OK
下面的就不一一演示了,这样就知道PPL的每一步是怎么算出来的,也别以为PPL上面显示的2-gram,就只跟前一个有关系,其实你算的是3-gram,就都跟前两个词有关系,只不过有些算的是回退的概率。
那么回退的这个概率公式是什么?
如果语料里的词不在wordlist里面呢?语言模型会有什么变化?
做个实验:
语料 welcome.corpus.pat
欢迎你
欢迎加入大家庭
欢迎加入小组
生成词表 small.wlist
#!/bin/bash ./tools/wrdmrgseg_ggl-v3.sh ./118k-kuwomusic.new.vocab.dict2 welcome.corpus.pat corpus.pat.wseg #分词 rm small.wlist echo '</s>' >> small.wlist echo '<s>' >> small.wlist LANG=C;LC_ALL=C;awk '{for(i=1;i<=NF;i++){print$i}}' corpus.pat.wseg | sort -u >> small.wlist
词表内容:(龟速是随便加的一个词,无视他)
</s>
<s>
你
加入
大家庭
小组
欢迎
龟速
生成语言模型 welcome.lm1
ngram-count -order 3 -debug 1 -text corpus.pat.wseg -vocab small.wlist -gt3min 1 -lm lm/welcome.lm1
然后我们换一个语料,词表不变:
欢迎你
欢迎加入大家庭
欢迎加入小组
加入大胡欢迎
再生成语言模型,welcome.lm2
比较一下:
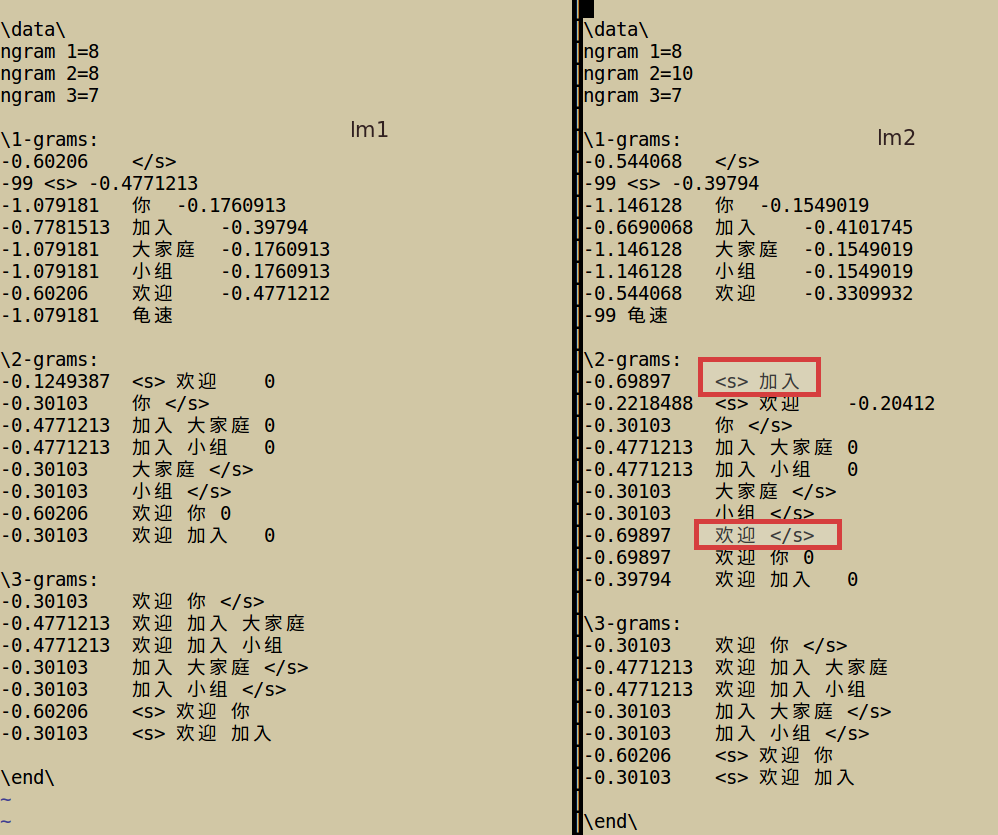
很明显可以看出,右边多了两个,红色矩形标出,这就是我们多加了的那句语料造成的,而大胡在词表中未出现,所以在这里隔开了,注意,不是换行,对 <s> 加入 只有sentence start ,而没有 sentence end
语言模型困惑度
ngram -ppl devtest2006.en -order 3 -lm europarl.en.lm > europarl.en.lm.ppl
其中测试集采用 wmt08 用于机器翻译的测试集 devtest2006.en,2000 句;
参数 - ppl 为对测试集句子进行评分 (logP(T),其中 P(T) 为所有句子的概率乘积)和计算测试集困惑度的参数;
europarl.en.lm.ppl 为输出结果文件;其他参数同上。输出文件结果如下:
file devtest2006.en: 2000 sentences, 52388 words, 249 OOVs
0 zeroprobs, logprob= -105980 ppl= 90.6875 ppl1= 107.805
第一行文件 devtest2006.en 的基本信息:2000 句,52888 个单词,249 个未登录词;
第二行为评分的基本情况:无 0 概率;logP(T)=-105980,ppl==90.6875, ppl1= 107.805,均为困惑度。其公式稍有不同,如下:
ppl=10^{-{logP(T)}/{Sen+Word}}; ppl1=10^{-{logP(T)}/Word}
其中 Sen 和 Word 分别代表句子和单词数。
我们自己实操一下:
我 要 去 上海 明珠路 五百 五 十五 弄 p( 我 | <s> ) = [2gram] 0.126626 [ -0.897477 ] p( 要 | 我 ...) = [2gram] 0.194285 [ -0.71156 ] p( 去 | 要 ...) = [2gram] 0.205612 [ -0.686952 ] p( 上海 | 去 ...) = [2gram] 0.00419823 [ -2.37693 ] p( 明珠路 | 上海 ...) = [2gram] 6.65196e-06 [ -5.17705 ] p( 五百 | 明珠路 ...) = [2gram] 0.00264877 [ -2.57696 ] p( 五 | 五百 ...) = [2gram] 0.0768465 [ -1.11438 ] p( 十五 | 五 ...) = [2gram] 0.0159186 [ -1.79809 ] p( 弄 | 十五 ...) = [2gram] 0.0543947 [ -1.26444 ] p( </s> | 弄 ...) = [2gram] 0.0667069 [ -1.17583 ] 1 sentences, 9 words, 0 OOVs 0 zeroprobs, logprob= -17.7797 ppl= 59.9746 ppl1= 94.519
>>> pow(10,-1.0/10*(-17.7797)) 59.97496455867574 >>> pow(10,-1.0/9*(-17.7797)) 94.51967555580339
可以看下这边的详细公式:
logprob是每个n-元组概率的对数和,在上面的示例中,确实是最后一列之和即为logprob
S 代表 sentence,N 是句子长度,p(wi) 是第 i 个词的概率。N个相乘,再开N次方根,起到了规约的作用。

模型插值后的权重变化
文本
$ head l1.wseg l2.wseg ==> l1.wseg <== 导航 去 上海 导航 去 苏州 导航 去 北京 ==> l2.wseg <== 听 周杰伦 的 歌曲 听 汪峰 的 歌曲 听 刘德华 的 歌曲
\data\ |\data\ |-1.380211 苏州 -0.07638834 ngram 1=7 |ngram 1=8 | ngram 2=8 |ngram 2=9 |\2-grams: ngram 3=7 |ngram 3=10 |-0.4259687 <s> 听 0.05551729 | |-0.4259687 <s> 导航 0 \1-grams: |\1-grams: |-0.455932 上海 </s> -0.60206 </s> |-0.69897 </s> |-0.4259687 刘德华 的 0.07918127 -99 <s> -0.4771213 |-99 <s> -0.50515 |-0.455932 北京 </s> -1.079181 上海 -0.1760913 |-1.176091 刘德华 -0.50515 |-0.90309 去 上海 0 -1.079181 北京 -0.1760913 |-0.69897 听 -0.9030898 |-0.90309 去 北京 0 -0.60206 去 -0.4771211 |-1.176091 周杰伦 -0.50515 |-0.90309 去 苏州 0 -0.60206 导航 -0.4771213 |-0.69897 歌曲 -0.50515 |-0.8239088 听 刘德华 0.07918127 -1.079181 苏州 -0.1760913 |-1.176091 汪峰 -0.50515 |-0.8239088 听 周杰伦 0.07918127 |-0.69897 的 -0.50515 |-0.8239088 听 汪峰 0.07918127 \2-grams: | |-0.4259687 周杰伦 的 0.07918127 -0.1249387 <s> 导航 0 |\2-grams: |-0.4259687 导航 去 0 -0.30103 上海 </s> |-0.1249387 <s> 听 0.3979399 |-0.30103 歌曲 </s> -0.30103 北京 </s> |-0.1249387 刘德华 的 0.30103 |-0.4259687 汪峰 的 0.07918127 -0.60206 去 上海 0 |-0.5228788 听 刘德华 0.30103 |-0.4259687 的 歌曲 0 -0.60206 去 北京 0 |-0.5228788 听 周杰伦 0.30103 |-0.455932 苏州 </s> -0.60206 去 苏州 0 |-0.5228788 听 汪峰 0.30103 | -0.1249387 导航 去 0 |-0.1249387 周杰伦 的 0.30103 |\3-grams: -0.30103 苏州 </s> |-0.1249387 歌曲 </s> |-0.455932 去 上海 </s> |-0.1249387 汪峰 的 0.30103 |-0.60206 听 刘德华 的 \3-grams: |-0.1249387 的 歌曲 0 |-0.455932 去 北京 </s> -0.30103 去 上海 </s> | |-0.90309 导航 去 上海 -0.30103 去 北京 </s> |\3-grams: |-0.90309 导航 去 北京 -0.60206 导航 去 上海 |-0.30103 听 刘德华 的 |-0.90309 导航 去 苏州 -0.60206 导航 去 北京 |-0.60206 <s> 听 刘德华 |-0.90309 <s> 听 刘德华 -0.60206 导航 去 苏州 |-0.60206 <s> 听 周杰伦 |-0.90309 <s> 听 周杰伦 -0.1249387 <s> 导航 去 |-0.60206 <s> 听 汪峰 |-0.90309 <s> 听 汪峰 -0.30103 去 苏州 </s> |-0.30103 听 周杰伦 的 |-0.60206 听 周杰伦 的 |-0.1249387 的 歌曲 </s> |-0.4259687 <s> 导航 去 \end\ |-0.30103 听 汪峰 的 |-0.30103 的 歌曲 </s> ~ |-0.30103 刘德华 的 歌曲 |-0.60206 听 汪峰 的 ~ |-0.30103 周杰伦 的 歌曲 |-0.60206 刘德华 的 歌曲 ~ |-0.30103 汪峰 的 歌曲 |-0.60206 周杰伦 的 歌曲 ~ | |-0.60206 汪峰 的 歌曲 ~ |\end\ |-0.455932 去 苏州 </s> ~ |~ | ~ |~ |\end\ ~ |~ |~ ~ |~ |~ ~ |~ |~ l1.lm l2.lm l3.lm
这个简单的例子可以看到,插值后的模型,元组的概率会变差,符合正常的直观理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号