
NLP - 语法纠错
from NLP - 语法纠错不完全调研
一、背景
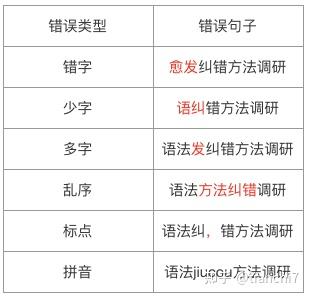
由于用户在文本输入法,语音输入法使用上的随意性,后续又缺少审核,极易产生语法错误内容。*年来随着自媒体的热潮,人人都是信息的生产者,互联网上语法错误的内容暴增,有分析表明中文网络新闻标题和正文的语法错误率超过 1%,这些语法不通顺的文本极大影响了用户体验。以输入 “语法纠错方法调研” 为例,可能产生的错误如下所示:
目前许多文本内容相关的产品都内嵌了语法纠错服务,优秀的语法纠错系统进而帮助提升用户体验。例如在搜索场景中,搜索引擎会对用户输入的 query 纠错后再精准返回搜索结果,在语音交互场景中,语音系统会将用户的语音转换成正确的文本后再进行后续的意图识别与交互。
因此文本语法纠错(Grammatical Error Correction)的研究应运而生,它是指自动检测出句子语法不通顺的错误,然后将检测出的错误进行纠正,进而减少人工校验成本。其在搜索 query,OCR,ASR,写作辅助与文章审核等场景中有着广泛的应用。本人最*对于学术界和工业界的语法纠错相关研究进展进行了调研和总结,下面将进行详细介绍。
本文的组织如下:
- 背景
- 语法纠错
- 中文错别字检测
- 工业界方法
- 评测方法
- 总结
- 参考论文
二、语法纠错
2.1 综述
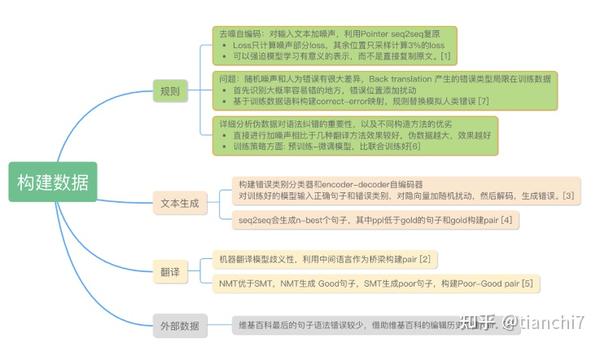
虽然语法纠错(Grammatical Error Correction)在很多实际场景有着重要的应用,但是这个任务在学术界一直是不温不火的状态,*年研究成果较机器翻译、信息抽取等少很多。纠错任务的传统方案一般是 pipeline 方法:错误检测,候选召回,候选排序三步走,随着*年来 seq2seq 等 NMT 方法在文本生成上的突出效果,学术界更多的方案采用端到端的生成正确句子的方法。根据调研发现目前学术界的研究方向主要分为一下三个部分:
- 训练数据自动构造方法。深度学习模型的训练尤其是 seq2seq 通常需要大规模的训练数据,然而错误与正确文本的训练数据 pair 是非常少的,因此很多方法都研究构建伪数据来增强训练数据,尽可能使伪造数据*似于现实情况。
- 基于序列标注的纠错方法。基于 Token 级进行修改(增删改)。
- 基于文本生成的纠错方法。利用生成模型直接使用错误文本生成正确文本。
由于 GEC 的学术研究很少基于中文数据,本章的调研将对这三个部分在英文的研究进行介绍。内容简要总结如下:
2.2 学术界相关工作
2.2.1 构建数据方法
语法纠错的数据主要是以句子对的方式表现,包括错误句子和改正句子。 然而由于纠错需要较多的语言知识和背景,标注成本很高,很难获得大规模的训练数据。尤其要是采用 seq2seq 模型对数据的需求会更大,因此大部分的语法纠错研究关注在如何模拟真实的场景自动构建大规模的训练数据。很多研究证明,借助于自动构建的数据对语法纠错模型有显著作用。文章 [6] 详细分析了构造数据对语法纠错的重要性以及不同构造方法的优劣,对于引入构造数据,有几个关键因素,1) 构造数据的方法;2)构造数据的种子语料;3)训练策略。作者基于 Transformer 的 Encoder-Decoder 结构实验发现,直接进行加噪声相比于几种翻译方法效果较好,种子数据的领域影响不大,预训练 - 微调的策略相比联合训练要好,同时数据量级越大效果越好。
下面具体介绍几大类数据构建的方法:
- 基于规则的方法
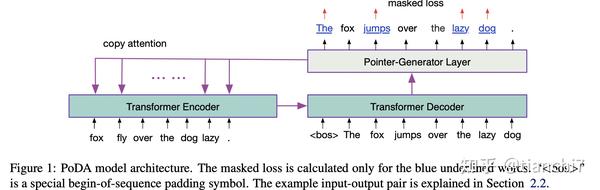
对于这个任务,很容易想到可以根据图 1 的几种错误类别制定策略构建数据,包括随机删词,随机加词,随机替换词,随机乱序等。文章 [1] 借鉴去噪自编码的方法,对文本进行随机处理加噪声,然后使用 seq2seq 对其复原,将训练好的 seq2seq 迁移到真实数据上进行微调,模型 loss 采用 MaskedLoss, 也就是只计算加噪声部分的 loss,其余部分只计算 3% 的位置。可以强迫模型学习有意义的表示,而不是直接复制原文。
2. 基于文本生成的方法
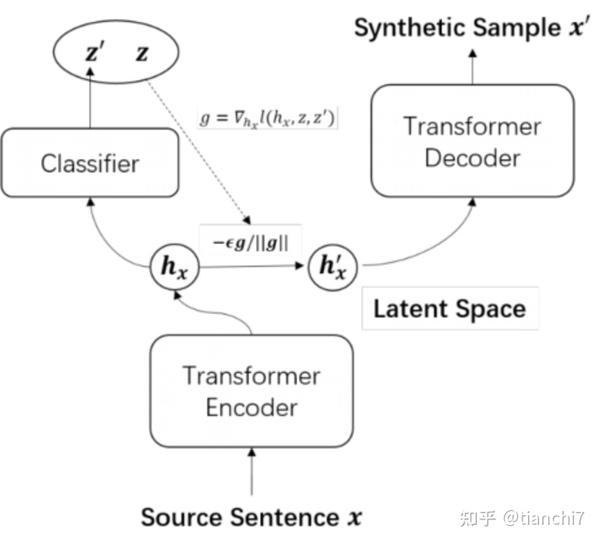
既然目标是用错误文本生成正确文本,那么自然而然也会想到用正确文本生成错误文本。很多研究利用 seq2seq 模型自动生成纠错 pair。文章 [3] 构建了一个分类器和 encoder-decoder 自编码器,首先将错误句子编码得到隐向量,模型有两个目标,一是进行错误类别分类,另一个是利用隐向量进行 decoder 自编码。巧妙的是它如何生成特定类型的数据,对于刚才训练好的模型,输入正确句子和指定错误类别 z,首先对隐向量 h 加上随机扰动 r,基于扰动向量预测错误类别 z',最小化分类 loss,然后就可以更新这个扰动 r,再基于更新后的表示进行解码,就可以生成指定类型的错误了 ,具体如下图所示。
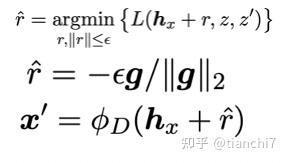
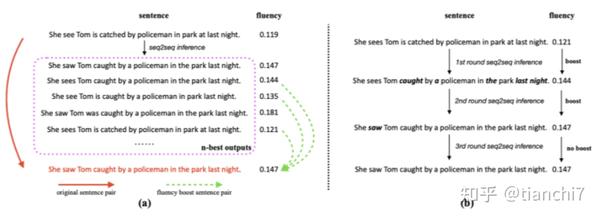
文章 [4] 提出了一种 fluency boost sentence pairs 的训练数据补充方法。出发点是基于错误句子 - 正确句 pair 训练的 seq2seq 模型会生成 n-best 个句子。那么这些句子中 ppl 低于正确的句子就还可以和正确句子组合成一个 pair,这样子补充的数据就又可以在训练中利用。
3. 借助翻译的方法
构建数据主要是想构建语法错误或逻辑上的错误,而现在的机器翻译模型的效果也很易产生错误,因此可以利用某个中间语言作为桥梁构建错误样本,就是先将句子翻译成英文,再翻译回来,构建成 pair [2]。文章 [5] 借助于 NMT 翻译模型显著好于 SMT 翻译模型的特点,利用 NMT 生成 Good 句子,利用 SMT 生成 poor 句子,构建 Poor-Good pair,利用这个 pair 构建训练数据 。但是翻译方法会存在一个问题是,语法错误会比较固定。
4. 借助外部数据
Google 借助于维基百科最后的句子可能是语法错误较少的句子,根据编辑历史构造 pair [2]。这种方法依然会存在问题,包括 pair 的大幅变化,未全部改正,百科的 spam 等等。
5. 选择替换位置
从经验来看,人不一定是在所有的地方都容易写错,那么实际数据的错误位置分布也应该是不均衡的。文章 [7] 首先识别大概率容易错的地方。在这里有个巧妙的地方就是,他根据 seq2seq 解码的时候每个步骤的预测概率来判断当前词是不是可能有问题,然后根据 attention 对齐去找到原文本对应的位置。找到位置后再进行替换,生成错误句子。
如上所述的自动构建数据方法还是存在一些问题:
- 预定义的加噪声规则或者(错误 - 正确对)替换方法会让模型去学习到这些策略。而这些策略与真实的场景还是有点差异或覆盖不全,进而限制模型的泛化性能
- 一些基于生成或翻译的方法,无法定位错误片段,其可能表达的意思与输入有很大不同了。
- 构建的样本可能带入噪声,伪正例对模型训练会造成困扰。
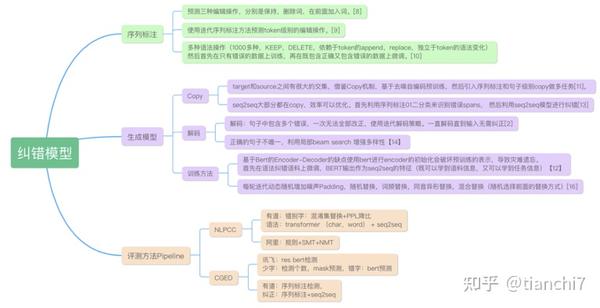
2.2.2 序列标注模型
目前纠错模型的研究方向主要是两种,一是基于序列标注的纠正,出发点在于 seq2seq 生成文本的可控性较差,decode 的推理速度也比较慢。在语法纠错的场景中,错误文本和正确文本的交集特别大,因此可以联系到字符串编辑距离的方式,如何通过较少的 token 编辑操作将错误文本改造成正确文本。
文章 [9] 是比较早用 tag 方式做纠错的,他首先定义了 copy, appends, deletes, replacements, ,case-changes 这些编辑操作,比如下图的错误句子 X 和正确句子 y,可以得出编辑方法 e,然后对每个 token 打上标记。再使用迭代序列标注方法预测 token - 级别的编辑操作。

文章 [8] 设置了两种标签 keep 和 delete,然后在 keep 和 delete 的基础上添加额外标签 P(表示在当前位置需要在前面加入短语 P,P 是空或单词或短语),如下图所示 。实验设置的词表 V 大小只有 500(覆盖 85% 的训练数据),在实际应用场景可能会很大,所以整个预测空间是 2V(V 代表词表大小,2 是 keep 或 delete)。模型上在 BERT 的输出后添加 MLP 或 transformer decoder 进行序列标注。
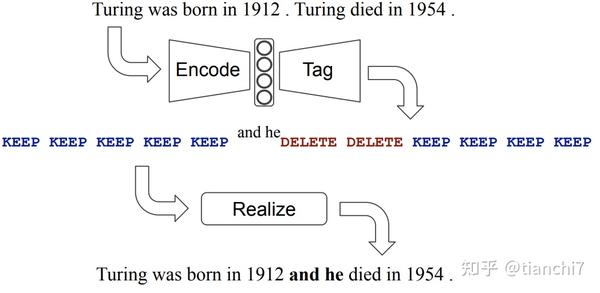
文章 [10] 详细定义了多种语法操作的 tag。tag 空间达到了 5000 个,包括 KEEP,DELETE,1167 个依赖于 token 的 append,3802 个 replace,和 29 个独立于 token 的语法变化(包括 CASE:大小写,MERGE:将当前 TOKEN 和后面 TOKEN 合并成一个,SPLIT:将当前 TOKEN 拆成两个,单复数转换,时态转换等等)。因为语法纠错的数据都是 wrong-correct pair,所以首先需要做的是预处理,对错误句子的每个 token 打上前面定义的 tag,这部分需要较为复杂的处理,具体实现可以去论文里参考代码。 序列标注的数据生成好了,那么后面就很简单了,模型上就是基于 bert 的 tagging 模型,采用迭代序列标注的方法多轮 tagging。这个方法是 grammaly 在 conll 数据上的 sota,应该是和工业应用场景比较接*,基于 tag 方法的纠错就是需要这种细致的数据处理和 tag 定义。
这几种基于编辑的方法上准确率会很高,可控性和解释性很强。但是需要对数据的细致分析和处理,tag 的定义取舍要求较高。由于一般不会把 tag 的集合设置过大,在封闭集上效果会较好,但开放集上的复杂情况和长尾问题很难处理。目前还没发现这种方法在中文上的应用。
2.2.3 生成模型
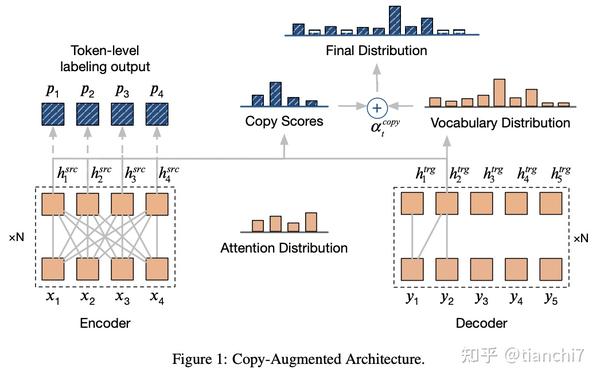
语法纠错的目的是利用原句得到正确的句子,与机器翻译的任务很相似,所以将机器翻译的生成模型引入到语法纠错中取得了很好的效果。与机器翻译的区别是,target 和 source 是同一种语言,且有很大的交集,也比较容易想到可以借鉴文本摘要中的 Copy 机制 。那么主要的研究方向包括,数据使用及训练策略,如何解决 target 和 source 交集过多的问题,解码策略。
- 数据使用及训练策略:
文章 [11] 首先基于去噪自编码方法在大规模数据上预训练,同时引入 token 级序列标注(判断这个 token 是否错误)和句子级别 copy(判断改句子是否正确,正确就是应该全 copy)做多任务提升 copy 机制在正确句子上的效果。
文章 [16] 不同于在预处理阶段静态扩增数据,在每轮迭代的时候动态随机增加噪声 Padding,随机替换,词频替换,同音异形替换,混合替换(随机选择前面的替换方式)。原理上就类似于 bert 的 dynamic mask,提升数据的泛化性。
目前将 bert 引入到 Encoder-Decoder 中有两种方案,一种是使用 bert 进行 encoder 的初始化,但是 seq2seq 很容易会破坏预训练的表示,在大规模的 seq2seq 数据上会导致灾难遗忘。另一种是使用预训练表示作为额外特征, 然而预训练语言模型不会对输入数据和语法纠错任务泛化。文章 [12] 首先在检测数据上微调序列标注的 BERT 模型,然后使用 Bert 的输出和原始输入训练基于 feature-based-Bert 的 Enc-Dec 模型。主要动机是想如何把预训练 bert 的表示融入到 enc-dec 框架中。
- copy 浪费效率
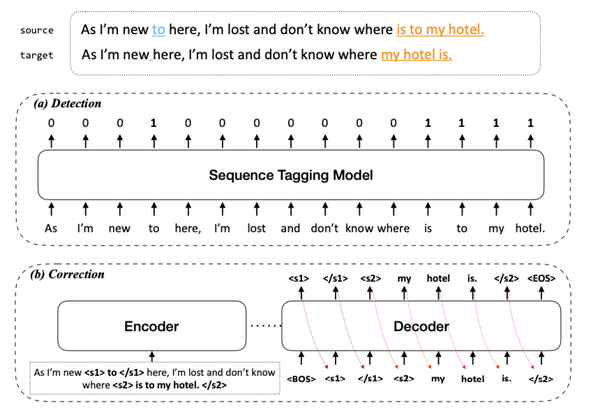
语法纠错的 seq2seq 大部分都在 copy,所以这个地方的效率可以被优化。文章 [13] 首先利用序列标注 01 二分类来识别错误 spans, 然后利用 seq2seq 模型进行纠错。
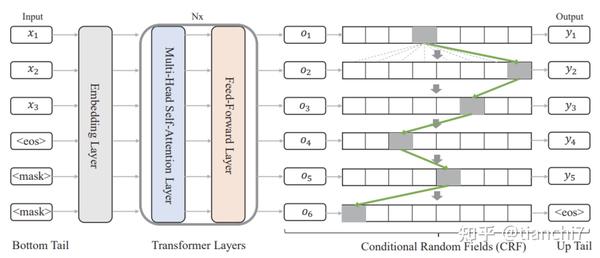
文章 [29] 针对生成模型无中生有和难以与原文本对齐,Tag 编辑方法的标签空间较大且需要多轮解码的问题。提出了一种基于非自回归序列预测框架的模型,类似于序列标注,不过 tag 的空间就是词表。
- 解码策略:
由于句子中可能会包含多次错误,一次生成可能无法全部改正,所以很多研究使用迭代解码策略。每一轮选择置信度高的候选作为下一轮的输入,一直解码直到输入无需纠正 [2]
基于 beam search 的解码在语法纠错场景中提供的修改信息很少,很可能大部分都在复制。正如这个任务也不希望过多的对原句修改,因为非必要的修改会破坏输入句子中正确的部分。因此如何鼓励模型在必要的错误上尽可能的修改成为了关键。普通的 beam search 会聚焦某个路径,只会修改特定相似的错误类型和错误 token。而全局的多样性 beam search 会产生很多不同路径,然而也可以产生非正确的候选。文章 [14] 提出了 diverse local beram search ,当一个 token 只有在需要修改时候,采用 diverse beam search。

三、中文错别字检查
3.1 综述
英文是由 26 个字母组成,英文单词拼错了可能就不在词表中了。 而中文是由几千个常用字组成,受限于拼音输入法或者手写输入法,相似字非常容易误用。所以中文语法纠错领域存在一个特殊的任务:中文错别字纠错(Chinese Spelling Error Check)。特别地,错别字任务的输入输出是完全对齐的,也就是错一个字改一个字。
中文错别字任务有一个问题就是要不要分词,因为中文分词系统都是在干净的语料上训练的,拼写错误会导致很多不正确的分割,导致错误会更加困难处理,例如” 他 | 去 | 手 | 都 | 北京 “和” 他 | 去 | 文具店 | 买了 | 纸币(纸 | 笔)“。基于字的模型是对分词错误更加鲁棒,但字模型无法利用词级别信息,导致改正难以解释,早期很多方法表示基于词的模型效果更好。但是基于词的模型通常利用了很多子模块和独立处理很多特殊 case,导致系统复杂性高,很难全局优化。早期比较经典的方法可以查看文章 [32],详细介绍了混合的错别字系统。目前学术界研究更多的是基于字的端到端模型。同时中文输入法的差异会导致较大的错误率,中文错别字大部分都是字形相似,字音相似的错误。错别字的类型主要有两种,一种是语义上的错误,比如使用错误,上下文搭配错误,另一种还有知识性错误,如人名实体,POI 等。学术界主要关注的也是语义上的错误,对于知识性的错误工业界关注更多。下面会详细介绍一下学术界的一些相关进展。
3.2 学术界相关工作
3.2.1 Confusionset-guided Pointer Networks for Chinese Spelling Check ACL2019 腾讯云
错别字的输入和输出大部分都是一致的,所以如果利用 seq2seq 模型的话,copy 机制是必不可少的,然后同时引入混淆集作为指导。解码时如果预测到词表上的,则在该位置原词的混淆集中选,如果预测到原文则 copy。
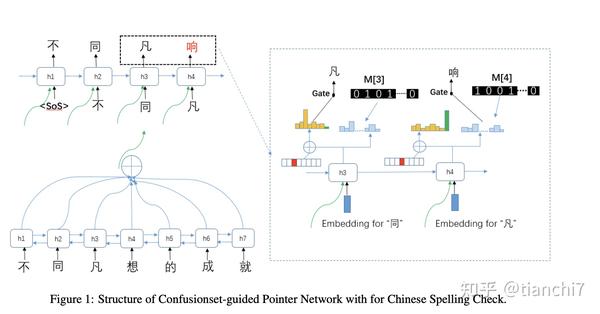
实验结果上表明加了混淆集之后提升明显,但是是否会对混淆集的依赖比较大,跟测试数据与混淆集的相关性比较重要。按最*研究进展来看,在中文错别字领域使用 seq2seq 有点舍*求远了。
3.2.2 A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check EMNLP 2018 腾讯 AILAB
错别字大部分都是字形和拼音的相似导致的错误,所以大部分自动构建错别字训练数据的方法都是基于混淆集的随机替换,方法比较固定,因此也没有论文专门研究构建方法。 这篇论文引入 OCR 和 ASR 构建形似和音似的数据方法,在 lstm 的检测模型上效果比较显著。在字形相似度上,首先选中正确句子中的某个字,然后对这个字的图加高斯噪声,然后利用 ocr 识别,如果不一样则可认为是一个错误字对。

但会产生很多 badcase,比如领可能被错误识别成铈,而人的打字中很少会犯这种错误,所以再引入笔画的相似度来衡量错误字对。Asr 的构建方法也类似,同时忽略拼音差异大或者错误太多的 case。
实验结果上看效果比较显著,也比较符合常理,这个任务对数据的要求太高了。这种构建方式比较直观,在 badcase 上的处理也比较好,但是这种复杂的构建方式相比普通的混淆集会有多大的增益还未确定,在 ocr 和 asr 上的纠错应该会比较好。
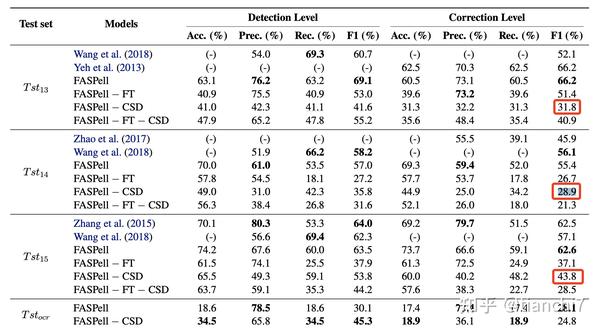
3.2.3 FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm EMNLP-WorkShop 2019- 爱奇艺
这篇文章应该是比较早用 bert 做中文错别字的,之前的方法都是基于混淆集进行构造候选,然后使用过滤法排序,但是很容易在少量数据上过拟合。同时只利用混淆集的候选也不太灵活,并且混淆集的构建是局限在固定的阈值,字的相似性没有充分被利用。
首先 Finetune Bert 语言模型:
- 对于无错误句子:
- 和原始 bert 训练方法一样。
- 对于有错误句子:
- mask 错误 token,将正确字作为 target;
- 为防止过拟合,同时 mask 掉部分正确的字为原字,将正确字作为 target
在解码阶段,原有的方法是对多个特征设置不同的权重。本文提出的方法是同时利用上下文 bert 的置信度和字的相似度(字形和拼音)。首先基于训练集绘制原字 - 候选字相似度,和 bert 置信度的散点图,画出能将检测错,纠正错与纠正正确分开的曲线。然后最后选择的时候根据这个曲线进行选择。

使用了这个方法,如下图所示的例子排名第二的候选也可能被选上来。
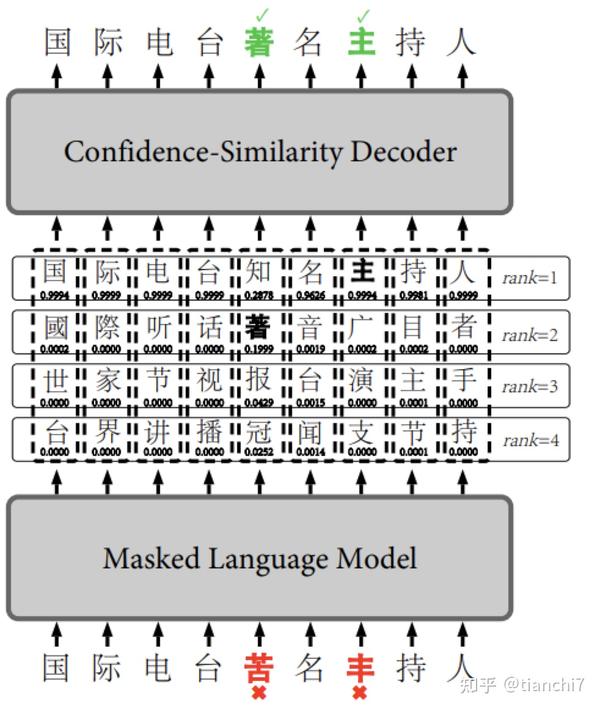
通过 ablation_study 可以看到这个解码的策略影响还是挺大的。直观上也比较理解,因为 bert 的预测基本上是语义上最可能的,而人表达的字很可能是和原字相似的,借助这个信息去选择排序符合真实场景。
3.2.4 Spelling Error Correction with Soft-Masked BERT ACL2020- 字节跳动
错别字 bert 的基本方法是首先在无标注数据集上预训练,再通过数据增强的方式利用混淆集构造训练数据,然后对给定句子的每个位置预测候选中最可能的字。存在的问题是预训练的时候只会 mask 掉 15% 的字,模型只学到了 mask token 的分布,其他的字不会进行改正,导致模型的召回可能不够。
这篇文章因此提出了一种 soft mask 的策略,由检测网络和纠正网络组成。基于 Bi-GRU 的检测网络预测每个字的错误概率,然后利用该概率构造每个字的 soft-masking embedding, 当检测概率为 1 的时候,则该字就等于 mask 的向量,当概率为 0 的时候,该字就等于原始字向量。后面接入正常的纠正 Bert 模型。
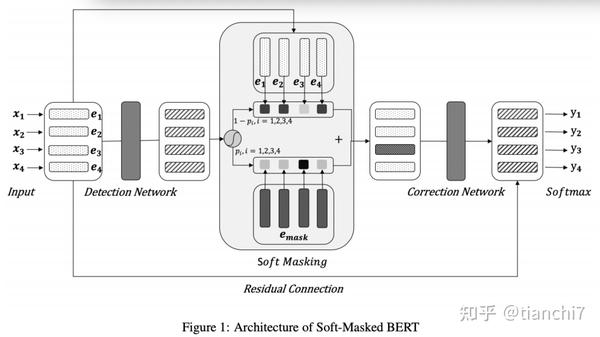
训练阶段损失函数由两部分组成,分别是检测网络和纠正阶段的损失函数。实验结果 在 SIGHAN 上的效果有一定提升,但不是很明显,比 bert-finetune 提高一个点。
3.2.5 SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check ACL-2020 蚂蚁金服
本文的出发点是错别字 bert 模型训练时只利用了语义的相似性,而错别字中有很多的拼音相似和字形相似的信息没有被利用,faspell 在后处理阶段利用了这些信息,本文提出融合这些信息到模型中。Bert 的 MLM 训练时,分类层的参数使用的是输入层 word Embedding 的参数。那么重点就是如何将每个字的音似和形似信息融入到分类层每个字对应的参数中。首先在混淆集上构建了两个图,分别拼音相似图和字形相似图,如果两个字在混淆集中则两个字的边权重是 1,否则是 0。如下图右侧所示:
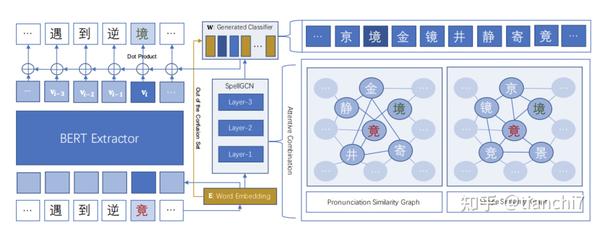
那么卷积操作是在这两种图上进行操作,然后利用注意力机制结合两种图的表示,最终的表示结合了前面每一层的表示和最终的表示。由于混淆集只是所有字的一部分,那么词表对应的分类参数中在混淆集中的可以使用 gcn 的表示,其余的使用 bert 的字表示。实验结果在 SIGHAN 上的效果有一定提升,但不是很明显,相比于 bert 1 个点左右。
3.2.6 Chunk-based Chinese Spelling Check with Global Optimization EMNLP 2020 阿里巴巴
目前的基于字的系统缺少词信息,基于词的系统过于复杂难以全局优化。 这篇文章提出了基于组块解码的方法,利用全局优化修改单字和多字词错误。 结合发音,字形,语义混淆集处理多种不同错误。基于组块的解码将单字,多字词,短语,成语视为组块。


具体纠错解码流程如上所示,类似于 seq2seq 的 beam search。其中几个重要步骤包括候选生成和排序:
- 候选生成。假设句子中的每个组块(从位置 i 到 i+num_max_len)都可能错误,根据三方面的混淆集,生成解码的可能候选。chunk_ij = [c_i,...,c_j] 根据拼音,字形(编辑距离在一),语义(利用 Faspell 语言模型根据上下文信息产生 top-k 候选,编辑距离在一),同时应该在词表中。词表来源于 gigaword 和成语俗语表
- 纠正。多特征包括字级别的编辑距离、拼音的编辑距离、组块个数、词级别 N-gram 语言模型的困惑度,基于 bert 的字级别模型的概率提升,来源于拼音混淆集的个数,来源于字形混淆集的个数、来源于语义混淆集的个数。
- 利用 MERT(Minimum Error Rate Training)算法进行排序。给定 topn 的输出,学习排序算法的特征。
实验结果来看相较 faspell 和 spellgcn 提升比较明显,相比于 bert 在多字词方面提升比较明显,bert 通常是只改一个字或者替换一个不合适的词。

3.2.7 Plome ACL2021
由于 Bert 预训练的大放异彩,很多研究都开始做错别字的预训练,引入拼音和字形信息成为主流方向,今年 acl 出现了多篇引入拼音和字形到 bert 预训练的相关论文 [20,21,23,25,26],区别在于如何建模拼音和字形的表示,和把这些表示引入到模型的哪里。
文章 [20] 将字音和字形信息引入到 bert 的输入中,基于字的拼音序列利用 GRU 建模拼音表示,基于字的笔画序列利用 GRU 建模字形表示。模型在输出该位置的字的概率,也要输出该位置的正确拼音改了吧,模型的损失为二者损失之和。预测阶段也是结合二者作为预测结果。
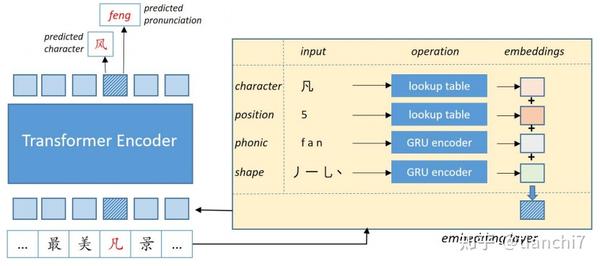
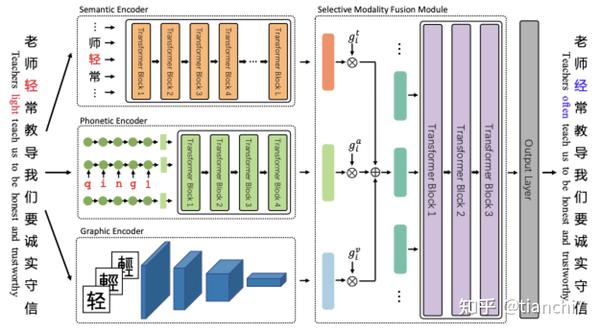
文章 [23] 分别设计了字的语义编码(采用 Bert 编码),字音编码(首先利用单向 GRU 对每个字的拼音编码,然后用多层 transformer 对字拼音表示序列编码)和字形编码(利用 Res Net 对每个字的图片进行编码),最后将三种表示基于门控的方式进行融合起来。
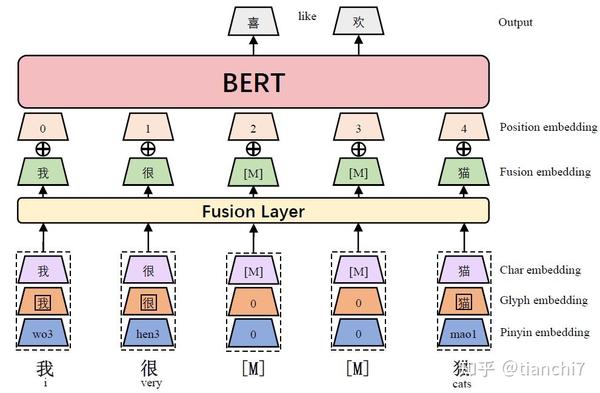
文章 [26] 不是单独为纠错设计的,但也是引入了字音字形信息。字形嵌入使用不同字体的汉字图像进行向量化,拼音嵌入使用拼音序列基于 CNN 进行向量化。最后将三者表示融合在一起作为 bert 的输入向量。
四、工业界纠错系统
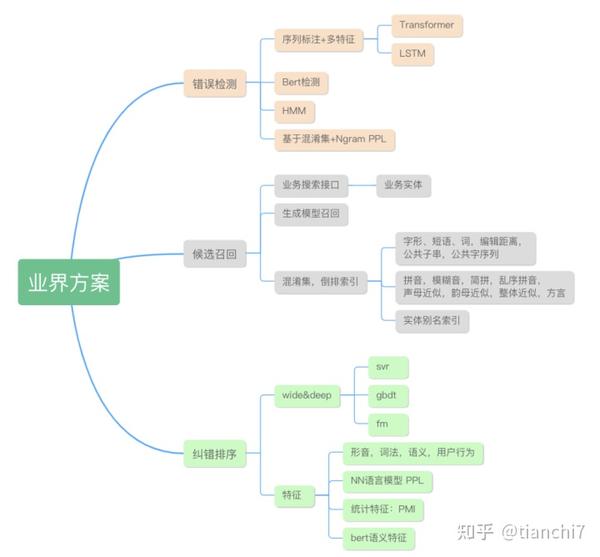
由于端到端系统的不可控性,工业界大多采用分阶段的纠错架构,错误检测,候选召回,候选排序和结果评价。不同于学术界只关注语义上的错误,工业界的一大重点是知识性的错误,而且各个应用场景侧重点可能会不同。下面介绍几个经典场景的纠错系统,有些偏早期,现在可能已经迭代变更了。
4.1 Query 纠错
4.1.1 百度中文纠错
百度将错误类型分为以下三部分,也就是说纠错需要具有对词法句法的理解,对上下文信息的理解,对知识的理解:

方法上采用了经典的三步 Pipeline:错误检测 -> 候选召回 -> 纠错排序
- 错误检测:检测句子中错误位置和错误类型
- 模型上采用 transformer/lstm+CRF 序列标注模型
- 模型输入层引入多种特征:词法句法分析,字词多粒度特征,
- 候选召回:对检测出来的错误位置召回正确普安段候选。
- 离线候选挖掘,利用大规模的错误对齐语料,通过对齐模型,得到字、词、短语级混淆矩阵。
- 在线候选预排序,对召回的大量候选,结合语言模型和混淆矩阵特征进行候选粗筛。
- 纠错排序:deep&wide, deep 结合当前错误点上下文表示,wide 部分基于形音、词法、语义、用户行为等特征学习原词与候选词的多维度距离表示。 通过 GBDT&LR 进行排序
系统有以下几个主要特点:
语言模型:传统的语言模型是基于上文的词预测该位置的词,与语法纠错场景有一定的 gap,为了更贴*语法纠错的使用场景,使用受限语言模型,基于原词生成该位置的词。

知识型错误:对标题进行检索或者上下文的关联知识辅助排序。

低频知识:在训练数据中出现很少,对语言模型的预测概率和 ppl 计算影响较大。因此不能单单依靠语言模型的结果,要进行语义分析得到语义特征,辅助排序
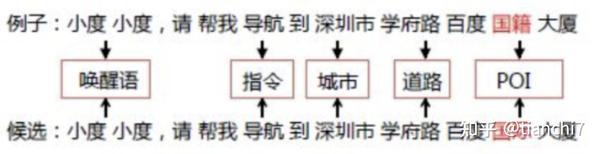
4.2 ASR 纠错
ASR(Automatic Speech Recognition)错误大部分都是发音相似的错误,所以比通用错别字系统覆盖范围要窄。但是其在*音同音的纠错上可以借鉴。
4.2.1 阿里语音纠错
阿里的语音纠错主要架构如图所示,检测 - 召回 - 排序三步 pipeline。
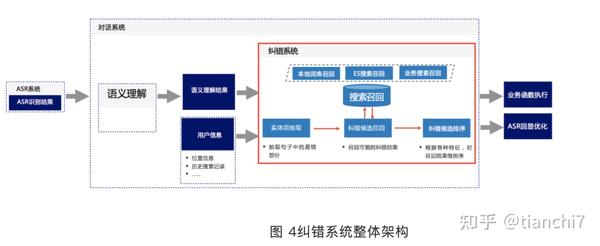
ASR 场景中实体错误较多,因此阿里语音纠错着重实体检测纠正。常用的实体序列标注模型都是基于正确数据训练出来的,与纠错场景的实际应用分布不一致,所以需要构造包含错误的样本。首先使用业务规则增加 20% 的包含错别字的数据,使得训练数据和线上场景分布一致,实体抽取结果提升 10 个点。
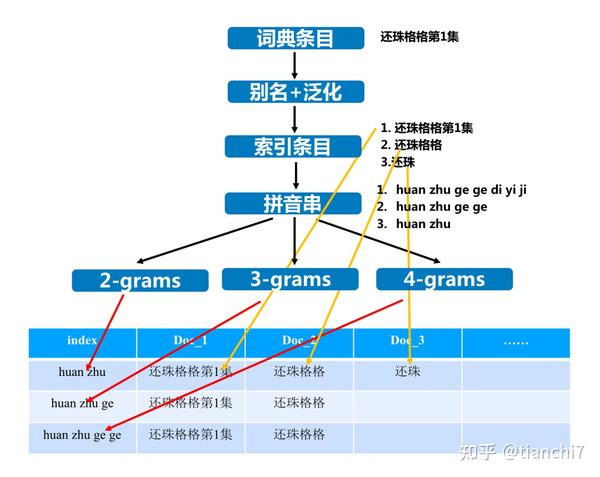
识别出实体后的重点是召回纠错候选,主要有三种方式
- 建立索引时使用各阶拼音 n-gram 作为键值,召回时优先查询高阶键值,无法满足数量阈值时回退到低阶键值查询,保证召回数量。
- 使用 Elastic Search 检索进行召回。采用词条拼音名作为索引项,按照词条长度以及城市信息对索引表进行分片。
- 使用业务搜索接口,比如高德地名查询、虾米音乐查询、优酷视频查询等。进一步丰富召回内容。
最后对召回的实体进行纠错候选进行排序,模型上采用 pointwise 的二分类 svr 模型,使用哪个的特征包括:
- 拼音层面:声母*似(*翘舌等)、韵母*似(前后鼻音等)、整体*音、方言等
- 字层面:编辑距离、公共子串、公共子序列等
- 业务层面:PV、城市信息等
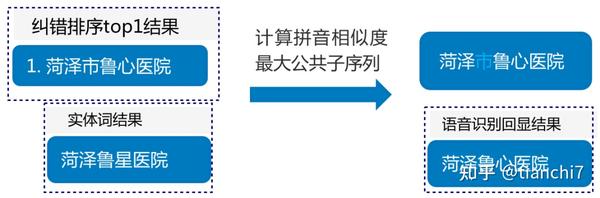
特别地、系统同时在后续预处理做了回显优化。用户的语音输入是 “菏泽鲁星医院”,而匹配的词条是 “菏泽市鲁心医院”。识别的错误是将 “心” 识别成了 “星”,但是匹配词条中还有被用户省略的 “市” 这个字。使用词条直接替换会导致识别结果和用户真实发音不一致,这是回显优化需要尽量避免的情况。阿里提出了一种基于拼音相似的公共子序列算法,通过查询原始串和替换串的拼音,找出拼音相似的最长连续路径。
4.2.2 小爱音箱的语音识别纠错
主要是*音字纠错模型。 一对一纠错,不考虑音频信息,只考虑文本信息。错误样本构建方式如下所示。

小米认为标准拼音对汉字音似建模有误差,比如 "挖" 和 "华" 读音很相似,标准拼音的编辑距离为 2 ("wa","hua"),因此提出了非标准拼音方案更准确描述 ASR 语音错误
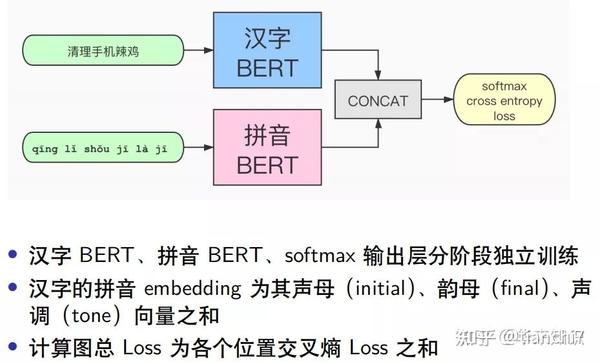
模型上是两个 Bert 模型的 ensemble,先用汉字语料训练一个端到端的纠错模型,再训练一个拼音到汉字的纠错模型,两个模型拼接后通过输出层 softmax 训练每个位置的交叉熵损失。特别的是将汉字拆成声母韵母声调,而不是单独的英文字母。
trick:
- 词表,限制纠错词表范围,只在相似词中选择,提升准确率
- 递归预测,把纠正后的句子再输入模型,直至两次结果相同
4.3 其他应用,写作辅助等
系统大同小异,可以在链接中查看。
4.3.1 滴滴 asr 纠错
4.3.2 讯飞
4.3.3 英文 grammarly
4.3.4 *安 AI 纠错
五、评测比赛
*几年也有部分评测比赛关注语法纠错任务,中文包括 NLPCC2018,连续举办的 CGED,英文包括 bea 2019 等。中文的评测主要是对外国人写的中文句子进行纠正,在数据分布上可能和中国人的书写错误有些差异。下面介绍几个中文的评测方案:
5.1 NLPCC 2018
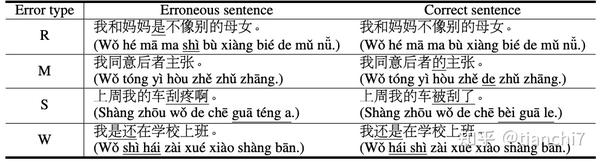
训练数据来源于外国人学习中文的网站 https://lang-8.com/,中文学习者写的原句和中国人写的纠正句作为 pair。测试数据来源于 PKU Chinese Learner Corpus。主要有四种错误类型:R(多字); M(缺字);S: (错别字,词语选择错误)W:(词序错误)。目标是将错误句子改成正确句子,评测指标采用 M2。

5.1.1 有道 NLPCC
三步 Pipeline
- 首先移除表面错误(错别字和标点错误)
- 使用混淆集替换每个字,计算 PPL,选择所有候选中 ppl 最低的。复杂度会比较高。
2. 检测和改正语法错误
- 首先构建 source_sent-target_sent pair。如果没有错误,target=source,利用 Ngram 语言模型过滤掉 source 的 ppl 显著低于 target ppl 的 pair。
- 模型上使用基于 transformer 的 seq2seq 方法
3. ensemble,结合上述两个结果生成最终结果。
- 基于词的模型在中文的拼写错误和字级别语法错误上表现不好,但是在词级别的语法错误上表现较好。那么对于 NMT 模型可以使用不同粒度的文本输入,采用了下图所示的多种方案进行 ensemble,包括只有 char,char+subword,sub-word,sub-word+char 四种方式。
- 最后使用 Ngram 语言模型进行排序。

5.1.2 阿里 NLPCC
- 基于规则的方法:利用 Gigaword 进行分词,如果 segment 不在词表中则:
- segment 包含至少两个字,如果翻转后在字典中则加入候选;
- 如果连接前一个或后一个 segment 在词表中则加入候选;
- 加入每个 segment 的同音词和*音词。
然后使用 Ngram 语言模型判断候选替换后是否正确。
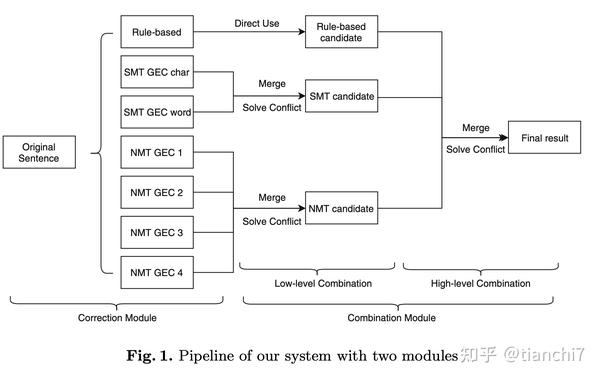
2. 基于 SMT 的 GEC 模型。
3. 基于 NMT 的 GEC 模型: 因为在错误样本的分词会导致分词错误,所以采用基于字的双层 LSTM。
最后基于 low-lovel (同种模型合并)和 high-level(不同模型合并)的合并策略去合并冲突。
合并冲突的时候,首先使用生成句子和候选句子对齐得到 editing_set,设计了一下几种合并策略。
- 选择一种作为优先
- 选择编辑距离最短的
- 选择两种候选的交集部分
- 基于 NGRAM 语言模型的选择方法
5.2 CGED 2020
这个任务是自动诊断外国人写的中文中的语法错误和纠正。错误类型主要包括多字,少字,选择错误,词序错误。
任务相比 NLPCC 更为细分了,包括以下几个子任务:
- 检测,句子级的二分类,判断是否有语法错误
- 识别,多标签分类,判断具体错误类别
- 位置级,识别出 start_pos,end_pos 和错误类别
- 改正,改正是语法纠错更难的任务,这个评测了两种比较好修改的类型,对于选词错误和缺失词进行改正。
5.2.1 讯飞 CGED
主要方法是检测 - 纠正的 pipeline。 检测上使用 res bert 的序列模型,也就是将输入 embedding 和 Bert 最后一层表示残差连接,就是将底层的字信息加以利用。对于纠正,根据不同的类别处理:
- 对于错字,区分了单字错误和多字错误。对于单字错误首先使用 bert 预测的 top20 和 3500 个常用字作为候选, 然后使用 ngram 得分,形音相似,bert 的预测概率进行排序。 对于多字错误也是每个位置采用 bert 预测的 20 个候选,然后将这些字连在一起作为候选词,同时对词逆序如果逆序后在词表里也加入候选。排序阶段除了上述的特征同时考虑错误词和正确词的 Levenshtein 距离。
- 对于少字,首先预测少字个数,然后加 mask 预测,再对所有候选使用 ngram ppl 排序。
相比于 Seq2seq 这种纠正的方法比较依赖于检测模型的准确率,检测准了后面纠正的可控性很高。
5.2.2 有道 CGED
首先进行自动构造数据。包括词级别和字级别的增删改翻转策略等等,具体可以查看上面的论文。策略越详细可以更好的模拟真实情况,增加泛化性。
在错误检测方面,使用 Bert 的序列标注模型。
在错误纠正方面,一个是引入 copy 的 transformer based seq2seq 模型。一个是上面介绍的 GECToR 方法。另外,因为中文中有很多经常容易混淆的词或字,设计了一种候选短语生成方法,根据检测模型预测的错误类型和位置替换原句中的词,然后从 CGED 的训练数据中利用语言模型选取 k 个最准确的候选短语。然后将这些候选和 seq2seq 模型,GECToR 模型的结果一起作为候选给后处理模块排序。
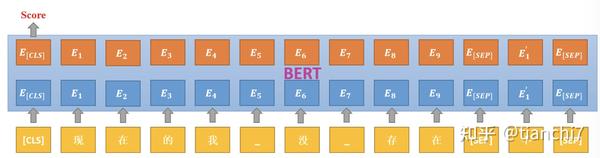
在纠正排序阶段,设计了基于 bert 的打分模型,模型的输入是句子和对应的纠正候选,然后返回该候选的 0-1 之间的得分。如下图所示,类似于 Bert 的 NSP 任务。
六、总结:难点及优化方向
最后稍微总结一下语法纠错任务的一些难点和重点方向。
6.1 数据优化
- 资源建设:混淆集资源(形似,音似,其他易错),词典资源(实体,POI 等) 。
- 数据增强:如何模拟各个场景中人类易产生的语法错误,增强的数据如何使用 Pretrain+Finetune?
- 数据噪声:无论是人工标注还是自动增强都会引入大量的噪声,对后续模型训练造成困扰。那么标注数据噪声及漏标注数据的处理也会很关键 [33]。
6.2 模型和架构优化
- 资源的利用:
- 对于实体词的纠正如何融入到模型中。
- 模型对新词新表达方式容易误判,数据更新需要重新训练,如何进行可持续性优化。
2. Tag 式序列标注:
- tag 训练数据的处理会比较繁杂,预处理、后处理的细节非常多。
- tag 的定义需要精细化,如何让 tag 包括大部分情况。
- tag 标签集合太小,泛化性不够,集合太大的话预测空间很大。
3. 生成模型:
- 生成模型的不可控,难解释。
- 对训练数据的量级需求大。
- Copy 很多,影响效率。解码阶段的推理速度慢。
4. Pipeline 方法:
- 不同阶段的错误会逐级传递。
- 每个模型单独学习,模型之间知识无法共享。
- 混淆集之外的非字形、拼音相似纠正处理的不太好。
5. 语言模型效率优化
很多方案中都使用了语言模型的 ppl 作为特征,那么传统的语言模型最多到 5-gram 就会到了计算的极限,而纠错通常也需要长距离的语义信息。另一方面基于 BERT 的 MLM 式语言模型在速度上会比较慢,计算 ppl 的 inference 阶段只能每次 mask 一个字,预测每个位置概率,增加了 n-1 倍复杂度,严重影响效率。那么如何优化语言模型的效率也是重点 [34, 35]。
七、 引用:
- Denoising based Sequence-to-Sequence Pre-training for Text Generation. EMNLP 2019.
- Corpora Generation for Grammatical Error Correction. NAACL 2019 Google
- Improving Grammatical Error Correction with Data Augmentation by Editing Latent Representation COLING 2020
- Fluency Boost Learning and Inference for Neural Grammatical Error Correction. ACL 2018
- Improving Grammatical Error Correction with Machine Translation Pairs EMNLP2020
- An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction EMNLP 2019
- Improving Grammatical Error Correction Models with Purpose-Built Adversarial Examples ENNLP 2020
- Encode, Tag, Realize: High-Precision Text Editing. EMNLP 2019.
- Parallel Iterative Edit Models for Local Sequence Transduction EMNLP 2019
- GECToR – Grammatical Error Correction: Tag, Not Rewrite. ACL 2020 workshop
- Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data. NAACL 2019.
- Encoder-Decoder Models Can Benefit from Pre-trained Masked Language Models in Grammatical Error Correction. ACL2020
- Improving the Efficiency of Grammatical Error Correction with Erroneous Span Detection and Correction EMNLP2020
- Generating Diverse Corrections with Local Beam Search for Grammatical Error Correction COLING2020
- A Self-Refinement Strategy for Noise Reduction in Grammatical Error Correction EMNLP 2020
- MaskGEC: Improving Neural Grammatical Error Correction via Dynamic Masking. AAAI-2020
- Wronging a Right: Generating Better Errors to Improve Grammatical Error Detection EMNLP2020
- Adversarial Grammatical Error Correction EMNLP2020
- Heterogeneous Recycle Generation for Chinese Grammatical Error Correction COLING 2020
- PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction ACL2021
- PHMOSpell: Phonological and Morphological Knowledge Guided Chinese Spelling Check ACL2021
- Exploration and Exploitation: Two Ways to Improve Chinese Spelling Correction Models ACL 2021
- Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking ACL 2021
- Global Attention Decoder for Chinese Spelling Error Correction ACL 2021
- Correcting Chinese Spelling Errors with Phonetic Pre-training ACL2021
- ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information ACL2021
- Dynamic Connected Networks for Chinese Spelling Check ACL 2021
- Instantaneous Grammatical Error Correction with Shallow Aggressive Decoding ACL 2021
- Tail-to-Tail Non-Autoregressive Sequence Prediction for Chinese Grammatical Error Correction ACL 2021
- Do Grammatical Error Correction Models Realize Grammatical Generalization? ACL 2021
- Grammatical Error Correction as GAN-like Sequence LabelingACL 2021
- A Hybrid Model for Chinese Spelling Check
- Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition ICLR2021
- Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning ACL 2020
- Levenshtein Transformer NIPS 2019

 浙公网安备 33010602011771号
浙公网安备 33010602011771号