
PyTorch-Kaldi 语音识别工具包
翻译: https://arxiv.org/pdf/1811.07453.pdf
ABSTRACT
开源软件的可用性在语音识别和深度学习的普及中发挥了重要作用。例如,Kaldi 现在是用于开发最先进的语音识别器的既定框架。 PyTorch 用于使用 Python 语言构建神经网络,并且由于其简单性和灵活性,最近在机器学习社区中引起了极大的兴趣。
PyTorch-Kaldi 项目旨在弥合这些流行工具包之间的差距,试图继承 Kaldi 的效率和 PyTorch 的灵活性。 PyTorch-Kaldi 不仅是这些软件之间的简单接口,而且还嵌入了一些用于开发现代语音识别器的有用功能。例如,该代码专门设计用于自然插入用户定义的声学模型。作为替代方案,用户可以利用几个预先实现的神经网络,可以使用直观的配置文件进行自定义。 PyTorch-Kaldi 支持多种特征和标签流以及神经网络的组合,可以使用复杂的神经架构。该工具包与丰富的文档一起公开发布,旨在在本地或 HPC 群集上正常工作。
在几个数据集和任务上进行的实验表明,PyTorch-Kaldi 可以有效地用于开发现代最先进的语音识别器。
1 Introduction
在过去几年中,我们目睹了自动语音识别(ASR)技术的逐步改进和成熟 [1,2],这些技术已经达到了前所未有的性能水平,现在已被全球数百万用户使用。
深度学习正在发挥这一技术突破的关键作用 [3],这有助于克服基于高斯混合模型(GMM)的先前语音识别器。除了深度学习之外,其他因素也在该领域的进展中发挥了作用。许多与语言相关的项目,如 AMI [4],DICIT [5],DIRHA [6] 以及 CHiME [7],Babel 和 Aspire 等语音识别挑战,都极大地促进了 ASR 的进步。 Librispeech [8] 等大型数据集的公开发布也为建立共同的评估框架和任务发挥了重要作用。
在其他因素中,开发软件的开发,如 HTK [9],Julius [10],CMU-Sphinx,RWTH-ASR [11],LIA-ASR [12] 以及最近的 Kaldi 工具包 [进一步帮助推广 ASR,使新型 ASR 应用的研究和开发变得更加容易。
Kaldi 目前是最受欢迎的 ASR 工具包。它依赖于有限状态传感器(FST)[14] 并提供了一组 C ++ 库,用于有效地实现最先进的语音识别系统。此外,该工具包包括一大套食谱,涵盖了所有最流行的语音语料库。在开发这种 ASR 专用软件的同时,一些通用的深度学习框架,如 Theano [15],TensorFlow [16] 和 CNTK [17],已经在机器学习社区中得到普及。这些工具包为神经网络设计提供了极大的灵活性,可用于各种深度学习应用。
2 The PyTorch-Kaldi Project
PyTorch-Kaldi 采用的架构概述如图 1 所示。主要脚本run_exp.py是用 python 编写的,管理 ASR 系统中涉及的所有阶段,包括特征和标签提取,训练,验证,解码和评分。 该工具包将在以下小节中详细介绍

主脚本将 INI 格式的配置文件作为输入。配置文件在项目文档中有完整描述,它由几个部分组成。 [Exp] 部分指定了一些高级信息,例如用于实验的文件夹,训练时期的数量,随机种子。它还允许用户指定是否必须在 CPU,GPU 或多个 GPU 上进行实验。配置文件继续使用 [dataset *] 部分,这些部分指定有关要素和标签的信息,包括存储它们的路径,上下文窗口的特征 [23] 以及语音数据集必须在其中的块数。分裂。神经模型在 [architecture *] 部分中描述,而 [model] 部分定义了这些神经网络如何组合。后一部分利用了一个由 run_exp.py 脚本自动解释的简单元语言。最后,配置文件定义 [decoding] 部分中的解码参数。
使用 Kaldi 执行特征提取,其本身提供 c ++ 库(例如,compute-mfcc-feats,compute-fbank-feats,compute-plp-feats)以有效地提取最流行的语音识别特征。计算出的系数存储在二进制存档(扩展名为. ark)中,然后使用从 kaldi-io-for-python 项目继承的 kaldi-io 实用程序导入到 python 环境中。然后由函数 load-chunk 处理这些功能。 ,执行上下文窗口组合,混洗,以及均值和方差归一化。如前所述,PyTorch-Kaldi 可以管理多个特征流。例如,用户可以定义利用 MFCC,FBANK,PLP 和 fMLLR [24] 系数组合的模型。
用于训练声学模型的主要标签源自语音特征与由 Kaldi 利用语音决策树计算的依赖于上下文的电话状态序列之间的强制对齐过程。 为了实现多任务学习,PyTorch-kaldi 支持多个标签。 例如,可以联合加载上下文相关和上下文无关的目标,并使用后者执行单音正则化 [25,26]。 也可以使用基于执行不同任务的神经网络生态系统的模型,如在语音增强和语音识别之间的联合训练 [27,28,29] 或最近提出的合作网络的背景下所做的那样。 深度神经网络 [30]。
PyTorch-Kaldi 自动将完整数据集拆分为多个块,这些块由从完整语料库中随机抽样的标签和特征组成。然后将每个块存储到 GPU 或 CPU 存储器中并由神经训练算法 run_nn.py 处理。该工具包在每个时期动态地组成不同的块。然后从它们中获得一组小批量。小批量由几个用于梯度计算和参数优化的训练样例组成。
迷你批次的聚集方式很大程度上取决于神经网络的类型。对于前馈模型,迷你批次由随机改组的特征和从块中采样的标签组成。对于经常性网络,小型机必须由完整的句子组成。然而,不同的句子可能具有不同的持续时间,使得形成相同大小的小批量所需的零填充。 PyTorch-Kaldi 根据它们的长度按升序对语音序列进行排序(即,首先处理短句)。这种方法最大限度地减少了零填充的需要,并且证明有助于避免批量规范化统计数据的可能偏差。此外,已经证明有效地略微提高性能并改善梯度的数值稳定性。
每个小批量由 PyTorch 实现的神经网络处理,该神经网络将特征作为输入,并作为输出在依赖于上下文的电话状态上的一组后验概率。 该代码旨在轻松插入自定义模型。 如图 2 中报告的伪代码中所报告的,可以通过在 neural_nets.py 中添加新类来简单地定义新模型。 该类必须由初始化方法和定义要执行的计算的正向方法组成,初始化方法通过初始化方法指定参数。

作为替代方案,在工具箱中原生地实现了许多预定义的最先进的神经模型。 当前版本支持标准 MLP,CNN,RNN,LSTM 和 GRU 模型。 此外,它支持一些先进的循环架构,例如最近提出的 Light GRU [31] 和双正则化 RNN [32]。 SincNet 模型 [33,34] 也用于直接从原始波形执行语音识别。 可以使用实现随机搜索算法的实用程序来调整模型的超参数(例如学习速率,神经元数量,层数,丢失因子等)[35]。
由神经网络产生的声学后验概率在馈送基于 HMM 的解码器之前通过它们的先验归一化。 解码器将声学分数与由 n-gram 语言模型导出的语言概率合并,并尝试使用beam-search算法检索在语音信号中发出的单词序列。 使用 NIST SCTK 评分工具包计算最终的字错误率(WER)分数。
3 实验设置
在以下子部分中,描述了实验活动所采用的语料库和 DNN 设置。
第一组实验是使用 TIMIT 语料库进行的,考虑到标准的音素识别任务(与 Kaldi s5 配方 [13] 一致)。
为了在更具挑战性的情景中验证我们的模型,还在 DIRHA-English 数据集 444 的远距离谈话条件下进行了实验。该数据集由语言数据联盟(LDC)分发。 [36,37]。 训练基于原始的 WSJ-5k 语料库(由 83 名发言者发出的 7318 个句子组成),这些语句被一系列在家庭环境中测量的脉冲响应所污染 [37]。 测试阶段是使用数据集的实际部分进行的,其中包括由六位美国本土人士在上述环境中发出的 409 个 WSJ 句子。
使用 CHiME 4 数据集 [7] 进行了额外的实验,该数据集基于在四个嘈杂环境(公共汽车,咖啡馆,步行区和街道交叉点)中记录的语音数据。 训练集由 43690 个嘈杂的 WSJ 句子组成,由五个麦克风(安排在平板电脑上)记录,共有 87 个扬声器。 在这项工作中考虑的测试集 ET-real 基于由四个扬声器发出的 1320 个真实句子,而子集 DT-real 已经用于超参数调整。 CHiME 实验基于单通道设置 [7]。
最后,使用 LibriSpeech [8] 数据集进行实验。 我们使用由 100 小时组成的训练子集和用于超参数搜索的 dev-clean 集。 使用继承自 Kaldi s5 配方的 fglarge 解码图在测试清洁部分上报告测试结果。
实验考虑了不同的声学特征,即 39 个 MFCC(13 个静态 +Δ+ΔΔ),40 个对数滤波器组特征(FBANKS),以及 40 个 fMLLR 特征 [24](根据 s5 配方中的报告提取) Kaldi),使用 25 ms 的窗口计算,重叠为 10 ms。
根据 Glorot 的方案 [38] 初始化前馈模型,而使用正交矩阵初始化复发权重 [39]。循环 dorpout 被用作正则化技术 [40]。正如 [41,42] 中提出的那样,仅对前馈连接采用批量归一化。使用运行 24 个时期的 RMSprop 算法完成优化。在每个时期之后监测开发组的表现,并且当相对性能改善低于 0.1%时学习率减半。在开发数据集上调整模型的主要超参数(即,学习速率,隐藏层数,每层隐藏神经元,丢失因子以及双正则化项λ)。
4 基线
在本节中,我们将讨论使用 TIMIT,DIRHA,CHiME 和 LibriSpeech 数据集获得的基线。 作为展示 PyTorch-Kaldi 工具包主要功能的展示,我们首先报告了对 TIMIT 进行的实验验证。
表 1 显示了使用不同特征的几种前馈和重复模型获得的性能。 为了确保架构之间的更准确的比较,针对每个模型和特征进行了五个改变初始化种子的实验。 因此,该表报告了所有实验的平均电话错误率(PER)555 标准偏差范围在 0.15 和 0.2 之间。

结果表明,正如预期的那样,由于扬声器适应过程,fMLLR 功能优于 MFCC 和 FBANKs 系数。 循环模型明显优于标准 MLP 模型,特别是在使用 LSTM,GRU 和 Li-GRU 架构时,通过乘法门有效地解决了梯度消失问题。 使用 Li-GRU 模型 [31] 获得最佳结果(PER = 14.2%),该模型基于单个门,因此比标准 GRU 节省了 33%的计算。

表 2 详述了 PyTorch-Kaldi 中用于改善 ASR 性能的一些常用技术的影响。第一行(基线)报告使用基本循环模型实现的性能,其中不采用dropout 和 batch normalization的强大技术。第二行突出显示在训练期间逐渐增加序列长度时实现的性能增益。在这种情况下,我们通过在 100 步(即,大约 1 秒的语音)截断语音句子开始训练,并且我们在每个时期逐渐加倍最大序列持续时间。这种简单的策略通常可以提高系统性能,因为它鼓励模型首先关注短期依赖关系,并仅在稍后阶段学习长期关联。第三行显示了添加循环的 dropout 时所实现的改进。与 [40,42] 类似,我们对所有时间步骤应用相同的dropout mask以避免梯度消失问题。相反,第四行显示了 batch normalization 带来的好处 [19]。最后,最后一行显示了在应用单音素 正则化时所实现的性能 [26]。在这种情况下,我们通过两个 softmax 分类器采用多任务学习策略:第一个估计依赖于上下文的状态,而第二个预测单音目标。如 [26] 中所观察到的,我们的结果证实该技术可以成功地用作有效的正则化器。
到目前为止讨论的实验基于单个神经模型。在表 3 中,我们将最佳 Li-GRU 系统与更复杂的架构进行比较,该架构基于由一系列特征提供的前馈和后续模型的组合。据我们所知,后一种系统实现的 PER = 13.8%会在 TIMIT 测试集上产生最佳发布的性能。

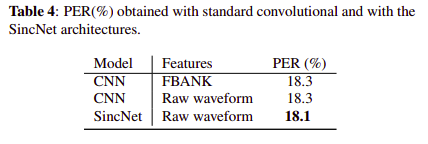
以前的成就是基于用 Kaldi 计算的标准声学特征。 但是,在 PyTorch-Kaldi 中,用户可以使用自己的功能。 表 4 显示了通过标准 FBANKs 系数或原始声波波形直接馈送的卷积模型所获得的结果。基于原始样本的标准 CNN 与由 FBANK 特征馈送的标准 CNN 类似地执行。 使用 SincNet [33] 可以略微提高性能,这是第一次突出显示处理语音识别原始波形的有效性。
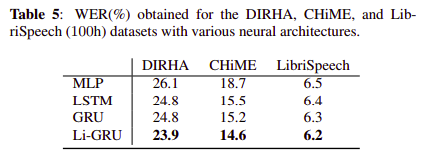
我们现在将实验验证扩展到其他数据集。 在这方面,表 5 显示了在 DIRHA,CHiME 和 Librispeech(100h)数据集上取得的性能。该表始终显示出使用 Li-GRU 模型的更好性能,证实了我们之前在 TIMIT 上取得的成就。 DIRHA 和 CHiME 的结果显示了所提出的工具包在嘈杂条件下的有效性。 特别是,DIRHA 代表了一项非常具有挑战性的任务,其特点是存在相当大的噪音和混响。 在此数据集上获得的 WER = 23.9%表示迄今为止在单麦克风任务上发布的最佳性能。 最后,使用 Librispeech 获得的性能在所考虑的 100 小时子集上优于相应的 p - 范数 Kaldi 基线(WER=6.5%)。
5 结论
本文描述了 PyTorch-Kaldi 项目,这是一项旨在弥合 Kaldi 和 PyTorch 之间差距的新举措。该工具包旨在使 ASR 系统的开发更简单,更灵活,允许用户轻松插入其定制的声学模型。 PyTorch-Kaldi 还支持神经架构,功能和标签的组合,允许用户使用复杂的 ASR 流水线。实验证实,PyTorch-Kaldi 可以在一些流行的语音识别任务和数据集中实现最先进的结果。
目前版本的 PyTorch-Kaldi 已经公开发布,并附有详细的文档。该项目仍处于初始阶段,我们邀请所有潜在的贡献者参与其中。我们希望建立一个足够大的开发人员社区,以逐步维护,改进和扩展我们当前工具包的功能。在未来,我们计划增加在我们的框架中编码的预先实现的模型的数量,并且我们希望通过集成神经语言模型训练以及对端到端 ASR 系统的适当支持来扩展当前项目。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号