借助Chrome和插件爬取数据
![]()
工具
- Chrome浏览器
- TamperMonkey
- ReRes
Chrome浏览器
chrome浏览器是目前最受欢迎的浏览器,没有之一,它兼容大部分的w3c标准和ecma标准,对于前端工程师在开发过程中提供了devtools和插件等工具,非常方便使用。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source和Network功能,分别查看DOM结构,源码和网络请求。同时,有很多基于Chrome浏览器的插件又给我们赋予了浏览器级别的能力,来处理数据。
TamperMonkey
Tampermonkey 是一个chrome插件,是一款免费的浏览器扩展和最为流行的用户脚本管理器。简单来说就是可以指定进入某些页面的时候调用指定的JS代码,这样我们就可以将页面中的某些数据整理出来,并保存到localStorage或者indexeddb中。
ReRes
ReRes是一个chrome的插件,它可以支持将某个在线的JS重定向到另一个JS上,也就是用另一个JS来替代原来页面中的JS,这个新的JS中我们可以修改一部分逻辑来满足我们的需求。
抓取流程
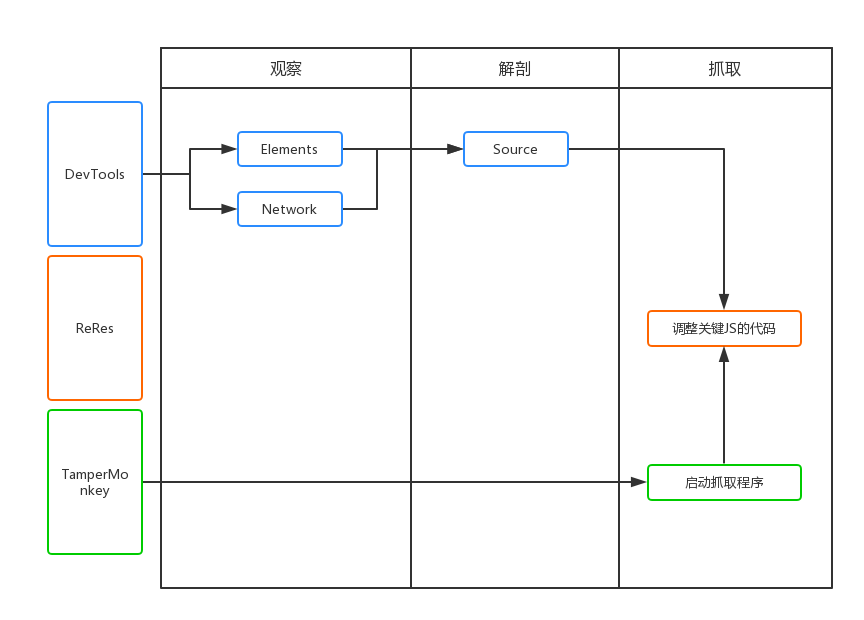
如上图所示,抓取分为三个步骤,分别是观察,解刨和抓取。
观察
首先是观察,我们需要通过devtools中的Elements和Network标签页,对要抓取的页面进行阅读,数据可能是在DOM元素中,也可能是通过Ajax接口直接返回,总之找到从哪里拿数据最合适。
当然,如果数据如果都是Ajax接口的方式返回,都会很容易抓取,但有时候我们可能会碰到比较讲究的网站,它们回对数据进行加密,返回的一个乱码的字符串,这个时候我们需要对代码进行解剖。
解剖
也就是对页面中的逻辑代码进行拆解和分析,找到关键的代码为我所用。通常网站的JS代码都是混淆和压缩过的,我们可以使用Chrome开发工具中的Source工具对代码进行基本的格式化,来方便阅读。然后简单介绍一下我寻找关键代码的方法:
- 元素标签寻找法
- 元素事件寻找法
- Ajax接口名称寻找法
当然,这里在寻找关键字的时候,需要使用Chrome开发者工具的Search功能。
元素标签寻找法
当我们找到一个关键的DOM元素的时候,你认为页面JS会对这个元素做操作,比如取值,删除,等,就可以通过这个元素自带的id或者class来搜索,通常,这些id和类名是不会被混淆的,可以直接找到。
元素事件寻找法
当我们认为某个元素绑定过click或者其他事件,而且具有重要意义,就可以通过Elements面板中的Event Listeners中寻找最有可能的事件,然后查看对应的JS代码。
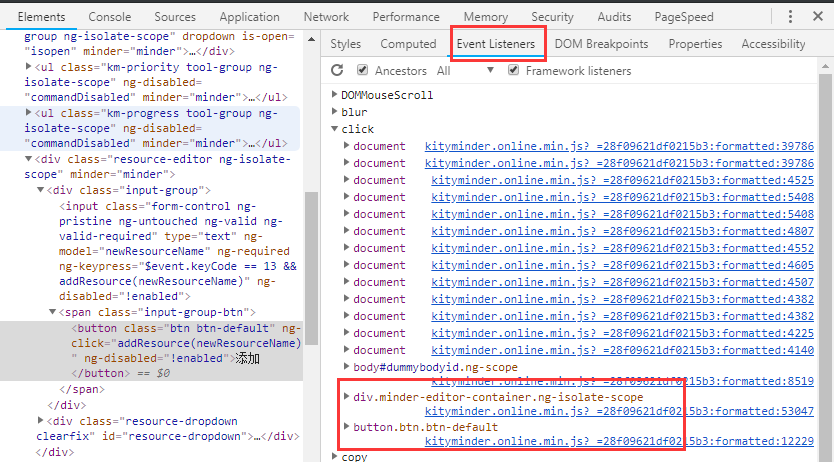
当然如果在Elements面板中的DOM结构上直接标记了方法名,如下图所示,你就可以直接全局Search【CheckInput】。
<input type="submit" name="Editor$Edit$lkbPost" value="发布草稿" onclick="return CheckInput();" id="Editor_Edit_lkbPost" class="Button">
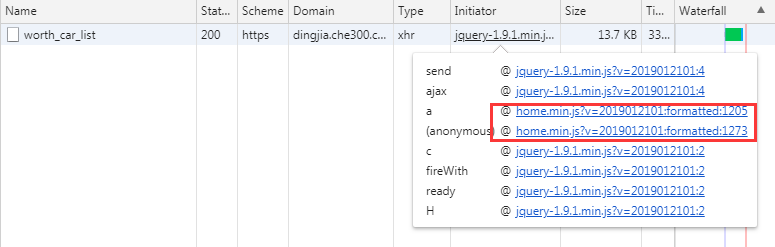
Ajax接口名称寻找法
当我们找到想要的接口的时候,我们在Network中能够找到这个接口的名称,直接全局Seach,或者通过Initiator中JS调用的堆栈信息找到具体调用的代码。
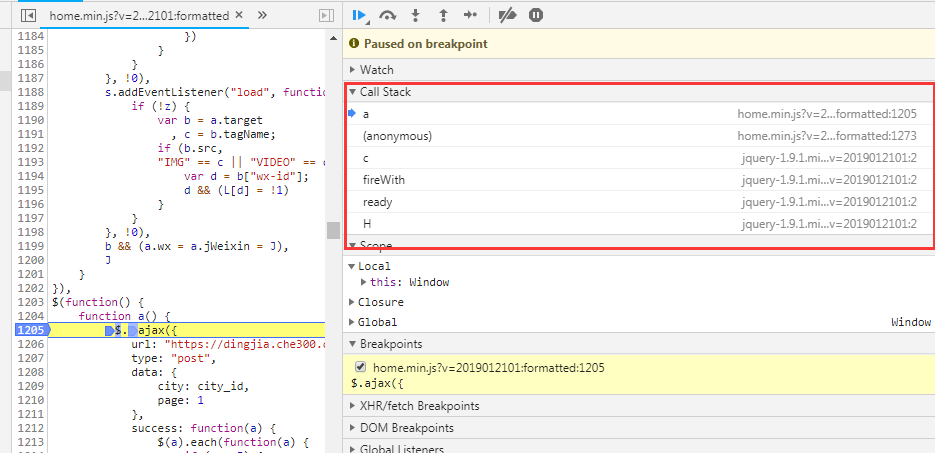
通过这三个步骤,我们基本已经能够找到我们需要的业务代码,剩下就是不断在这个基础上去找加密和解密的逻辑,同样是通过打断点,然后在Source面板中的Callbacks中寻找函数调用的堆栈,然后找到其他的逻辑。
抓取
抓取数据无非就是将数据通过自动化的方式提取,保存到指定的位置即可。
这里我们就要依赖我们的两个插件TamperMonkey和ReRes。我通常将关键JS保存到本地进行修改,然后通过使用ReRes将线上JS映射到本地JS上,然后就可以为所欲为,比如,使用封装好的解密函数解密数据,将数据保存到indexeddb中。
使用TamperMonkey主要是来定义一些全局变量,以及开始启动抓取过程,比如遍历DOM节点,模拟点击事件,记录已抓取的数据的位置。

总结
依赖Chrome浏览器去抓取数据,只是一种方便快捷的抓取方式,当然并不是很实用,因为Chrome不能直接操作数据库,我们的数据还是缓存在了浏览器中,导出就需要花点时间。本文只是讲了部分抓取数据的思路,具体可以使用Puppeteer、Phantomjs等工具来抓取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号