raid讲解 转
最近发现某国外网友制作的一张
RAID讲解图
不得不佩服这位网友的奇思妙想
几个饮水机和桶
就把复杂问题生动形象地化解了
▼▼▼

>>>>
1. Standalone:
第一张图很好理解,我们日常使用的PC就采用这样的数据读取方式。数据存放在一块硬盘里,且只有一块硬盘,那么自然我们的数据只能从该硬盘中读取。
>>>>
2. Hot swap:
第二张图也不难理解,看地上那个水桶。所谓Hot swap概念上来说类似于热备份。它的数据读取方式类似于Standalone,唯一不同的是,有一块备用的硬盘在时刻准备着。一旦正在使用的硬盘出现了问题,那么备用硬盘就要及时更换上,以免造成损失。但这样的方式也存在着一些弊端,比如硬盘更换需要时间,这对很多企业来说是致命的。
>>>>
3. Cluster:
第三个图是什么意思呢?Cluster是集群的意思。你可以看作两台独立的PC, 用户可以到左边的饮水机来取得数据,也可以到右边的饮水机来获得数据,但是这样比较浪费硬件资源,在企业级里不可能让多台服务器提供同样数据和同样服务的。
>>>>
4. RAID 0:
通常称为带区,是利用带区数据映射技巧的特定性能。它的优势就是数据的读写速度较快,但是没有冗余功能,如果一个磁盘(物理)损坏,则所有的数据都无法使用。
>>>>
5. RAID 1:
是一种称为“磁盘镜像”的容错配置。数据在被写到其中一块硬盘的同时,也被复制到另一块硬盘中。这样的方式可以防止硬盘损坏带来的数据丢失,但是即使是2块硬盘,其存储的空间也相当于只有一块硬盘的大小。而且I/O传输速率却无法得到改善,也就是饮水机的出水口并没有变大或者变多。
>>>>
6. RAID 5:
分布式奇偶校验的独立磁盘结构,常使用缓冲技术来降低性能的不对称性。采取RAID 5的方式,I/O传输速率会得到大大的提高,而且一块硬盘坏了也没有关系,还有备用的其他硬盘。RAID 5的另一个好处是它允许“热插拔”,这意味着如果阵列中的某磁盘出现故障,该磁盘可以与新磁盘交换而无需关闭服务器或NAS,也不必中断正在访问服务器或NAS的用户。
>>>>
7. RAID 0+1:
这就是我们常说的RAID 10,也就是是RAID 1和0的组合。它结合了RAID 1的镜像和RAID 0的带区。可提供最佳性能,但也很昂贵,需要两倍于其他RAID级别的磁盘。
鱼还是熊掌?
传统用户的容量与性能烦恼
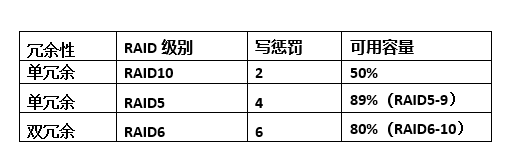
看完上面的图和讲解,有关RAID的概念是不是就一目了然了?其实除了上面这些,RAID还有其他一些形态,比如RAID 2、RAID 4、RAID 7等,不过经过这么多年的发展,RAID的形态已经基本固定了,主流的形式有这么几种:RAID 10、RAID 5、RAID 6(与RAID 5类似)。
从性能的角度,由于写惩罚的影响,RAID 10 的写性能通常优于RAID 5和RAID 6,因此对于性能关键型应用,客户希望底层采用RAID 10的方式。然而从磁盘利用率的维度,RAID 10的可用容量只有50%,却也是最不合算的(见下图)。
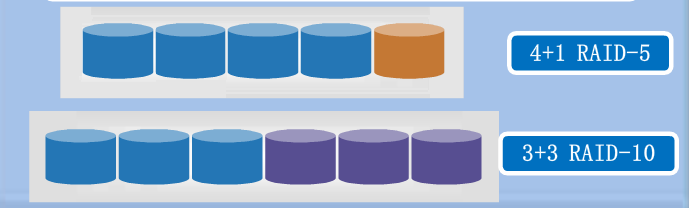
因此面对这种鱼和熊掌的难题,通常客户会采用以下办法:
➤ 假设客户一共购买了11块大小相同的硬盘(如600G 15K,标称随机 IOPS 180),为了获得更好的写入性能,取6块硬盘构建RAID10的组合,写入IOPS 540,挂载给数据库应用,容量利用率50%,也就是1.8TB(此处忽略1024和1000的磁盘容量计数差别)。剩下的5块硬盘构建RAID5的组,以获取更多的容量,写入IOPS 225,容量2.4TB,挂载给备份应用。
这种方式实现了性能与容量的平衡,但也有一些缺陷,由于切分了很多磁盘组,磁盘组之间的IO资源是无法共享的。因此作为应对方案出现了资源池化的技术。

池化RAID的优点显而易见。回到前面的例子,数据库可能在白天比较忙,备份通常在晚上工作,两者有一个时间差,但任何一个应用都可以使用11块硬盘的IOPS。即使采用空间利用率最高的RAID5,也有495的随机IOPS,基本保证数据库应用。也有些用户希望追求极限IOPS,因为这个时候的延迟会最小,他们就采用RAID 10的策略,随机IOPS可以达到990,数据库应用跑的很爽,晚上跑备份也很快,只是容量会牺牲一些。
现在大家可以看到,磁盘块级虚拟化解决了数据孤岛的问题,均衡了所有的前端IO到磁盘。是不是看起来很完美?其实这种方式依然不能在性能和容量之间求得一个很好的平衡(无论RAID 5还是RAID 10还是会牺牲一些容量或性能)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号