tesseract-ocr字库训练图文讲解
第一步合成图片集
你需要把使用jTessBoxEditor工具把你的训练素材及多张图片合并成一张tif格式的图片集
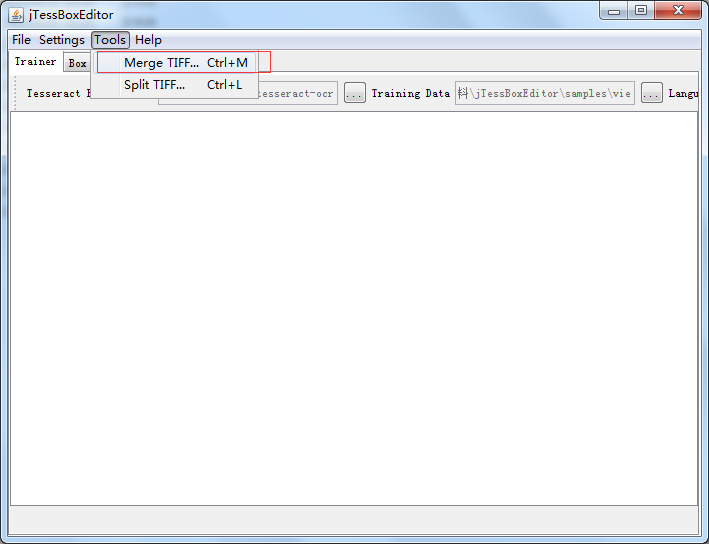
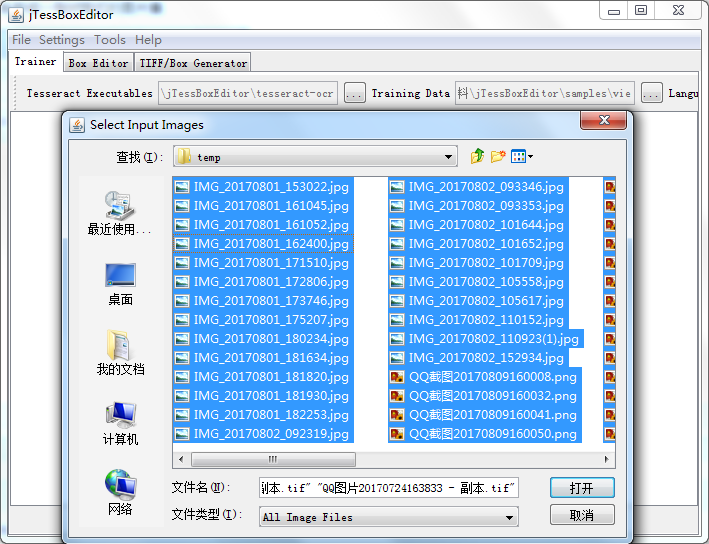

第二步 生成box文件
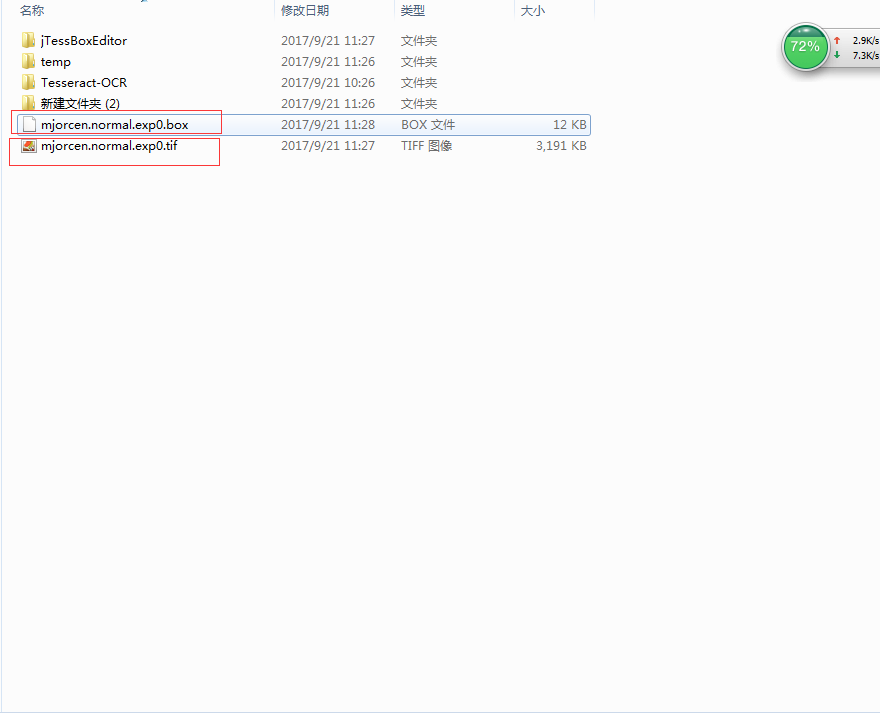
运行tesseract命令,tesseract mjorcen.normal.exp0.tif mjorcen.normal.exp0 batch.nochop makebox,生成box文件 ,
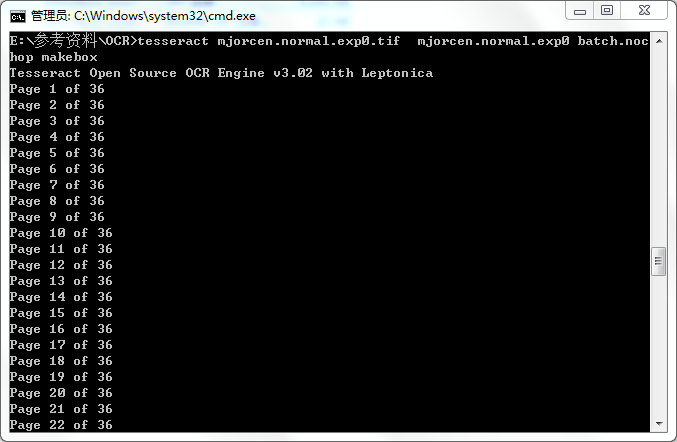
第三步
用 jTessBoxEditor打开生成的图片集 mjorcen.normal.exp0.tif ,注意 mjorcen.normal.exp0.tif 与对应的box文件一定要和他处于同一个文件夹下,然后就可以开始调整了,调整完之后保存
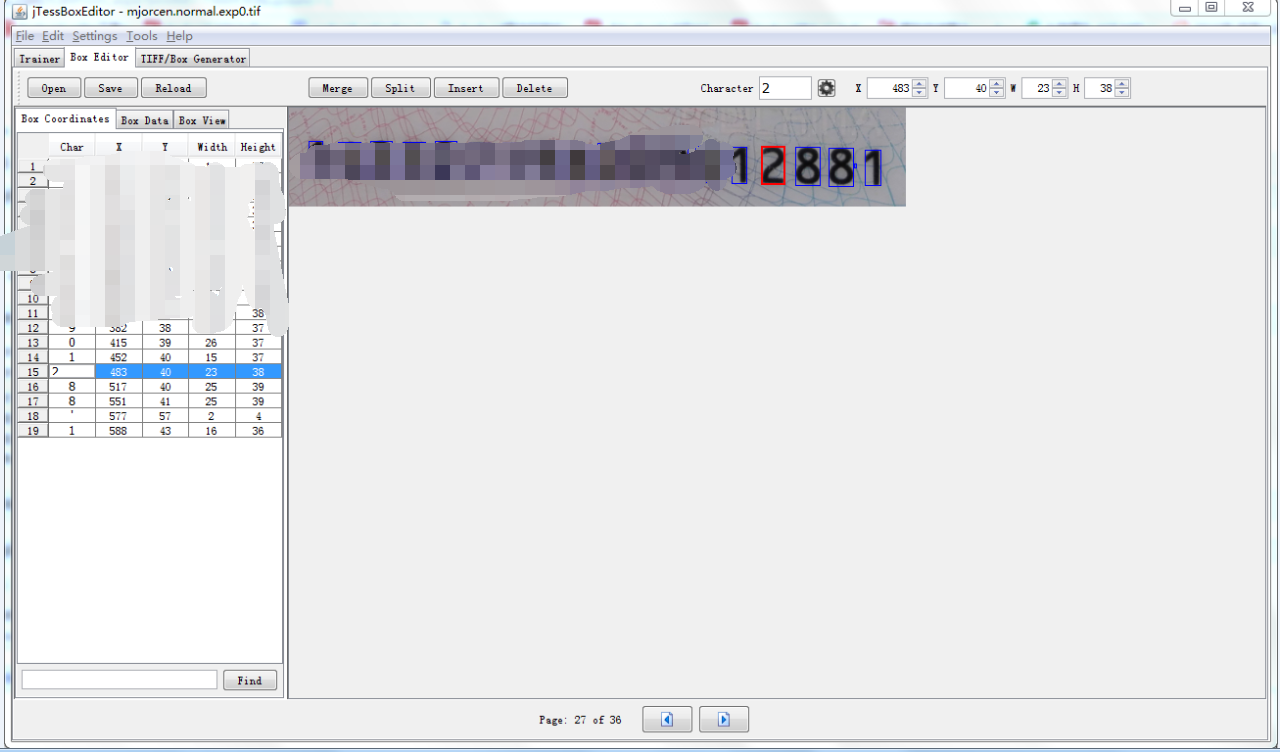
第四步 训练
首先在目录下新建一个名字为“font_properties”的文本文件,并且输入文本 normal 0 0 0 0 0,表示非斜体,粗体的一般字体
执行 tesseract mjorcen.normal.exp0.tif mjorcen.normal.exp0 nobatch box.train 进行测试训练
执行 unicharset_extractor mjorcen.normal.exp0.box 目录下生成一个名为unicharset的文件
接下来开始正式进行训练
1、执行 shapeclustering -F font_properties.txt -U unicharset mjorcen.normal.exp0.tr

2 、执行 mftraining -F font_properties.txt -U unicharset -O unicharset mjorcen.normal.exp0.tr

3 执行 cntraining mjorcen.normal.exp0.tr

目录下会生成对应下列五个文件,在这五个文件前加上normal.进行重命名

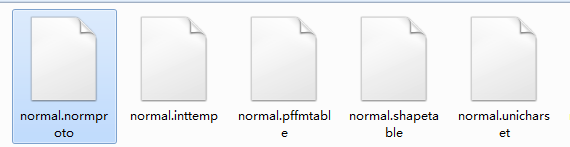
4 执行 combine_tessdata normal. 合并五个文件,此时目录下的normal.traineddata 就是训练好的字库文件
第五步 测试字库
把normal.traineddata 复制到Tesseract-OCRt程序目录下的“tessdata”目录
在Tesseract-OCRt程序目录下执行 tesseract.exe mjorcen.normal.exp0.png out –l normal

out.txt文件中会保存你识别到的数据;
这个其实网上资料很多,但大都描述的不够详细和完整,这里我一步一步把使用tesseract-ocr 训练字库的方法和步骤进行了描述,亲测是没有问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号