Alluxio集群搭建并整合CDH(MR/Hive/Spark)
Linux环境:centos7.4
CDH:5.16.1
Java:1.8.0_131
Alluxio:2.3.0
集群配置
机器数量:50
内存:64G
硬盘:4T
CPU核心数:32
编译
此处不再赘述,详见我另一篇文章 https://www.cnblogs.com/daemonyue/p/12975286.html
修改配置文件
cp conf/alluxio-site.properties.template conf/alluxio-site.properties
vim alluxio-site.properties
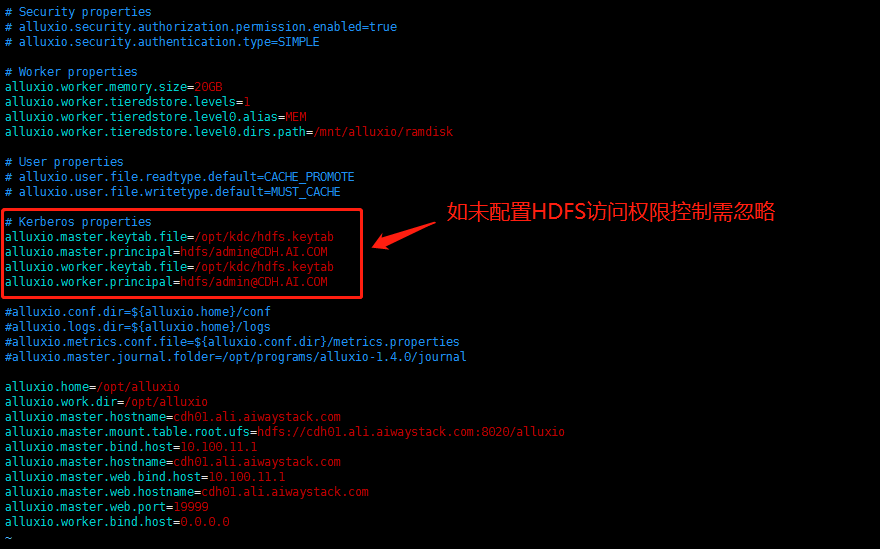
敲黑板
● 由于博主这边的集群使用了安全权限控制,此处涉及四条Kerberos相关的配置,如集群没有使用安全权限控制需自行忽略。
● 如有Alluxio整合Kerberos权限控制的需求,只需添加这四条配置即可。
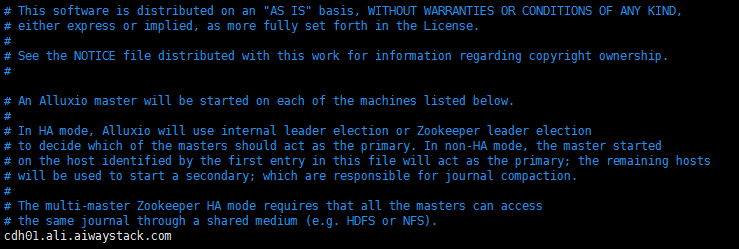
vim masters
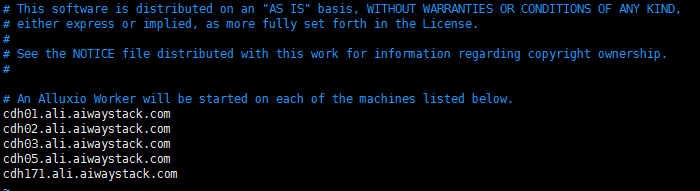
vim workers
集群
复制文件夹到每台机器
各个机器alluxio用户相互之间免密登陆
软连接配置
为每个机器设置java软连接,需要在这些目录其中之一配置软连接
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/spark/bin:/opt/spark/sbin:/root/bin
如果配置好了可以忽略,否则:
ln -s /usr/java/jdk1.8.0_131/bin/java /usr/bin/java
如果这里没有配置好的话,后面步骤就会出现如下错误
Error: Cannot find 'java' on path or under $JAVA_HOME/bin.
启动 Alluxio
创建ramdisk文件夹
之前配置的文件夹路径,需要先手动创建出来

format
./bin/alluxio format

启动
./bin/alluxio-start.sh all Mount
如果是root用户起的,使用Mount,如果是非root用户起的,用SudoMount。第一次需要这样,之后启动直接./bin/alluxio-start.sh all就可以
经过比较长时间的等待,启动完成
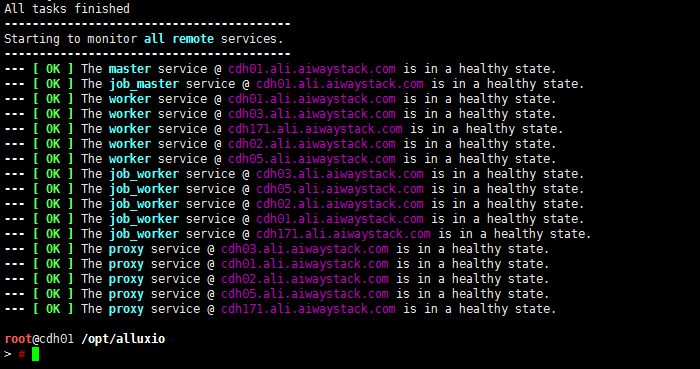
查看web端
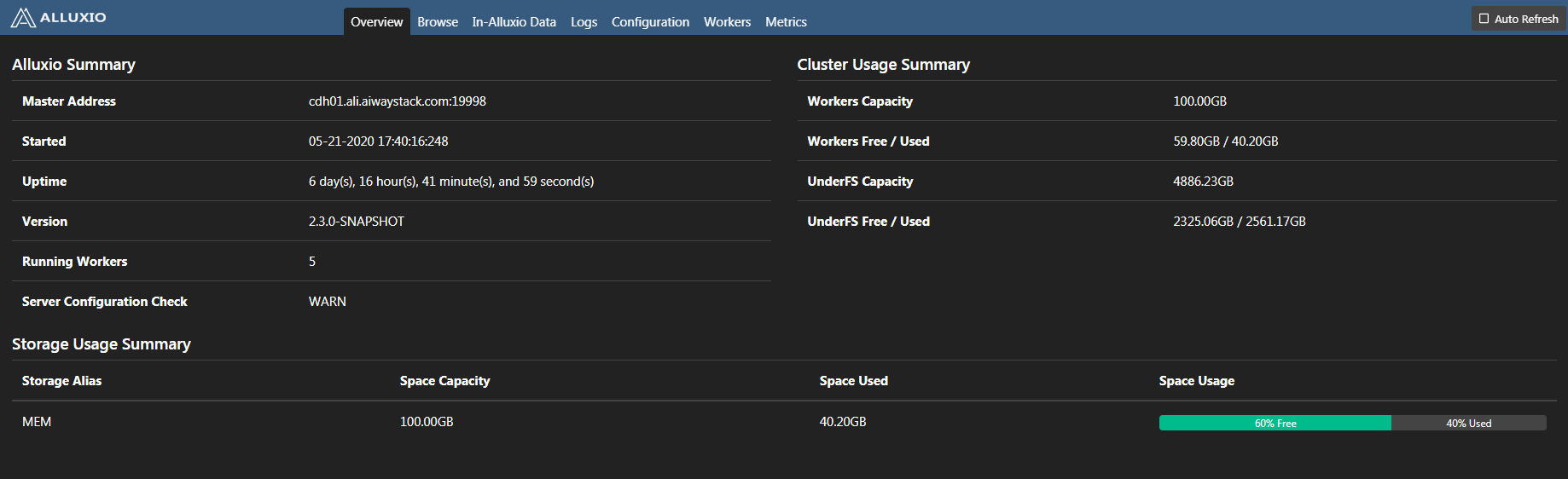
使用 Alluxio
这里可以把它理解为简单的文件系统,操作这个文件系统和hdfs非常相似
./bin/alluxio fs 操作命令
比如:
./bin/alluxio fs mkdir /test
集成 MapReduce
修改配置文件
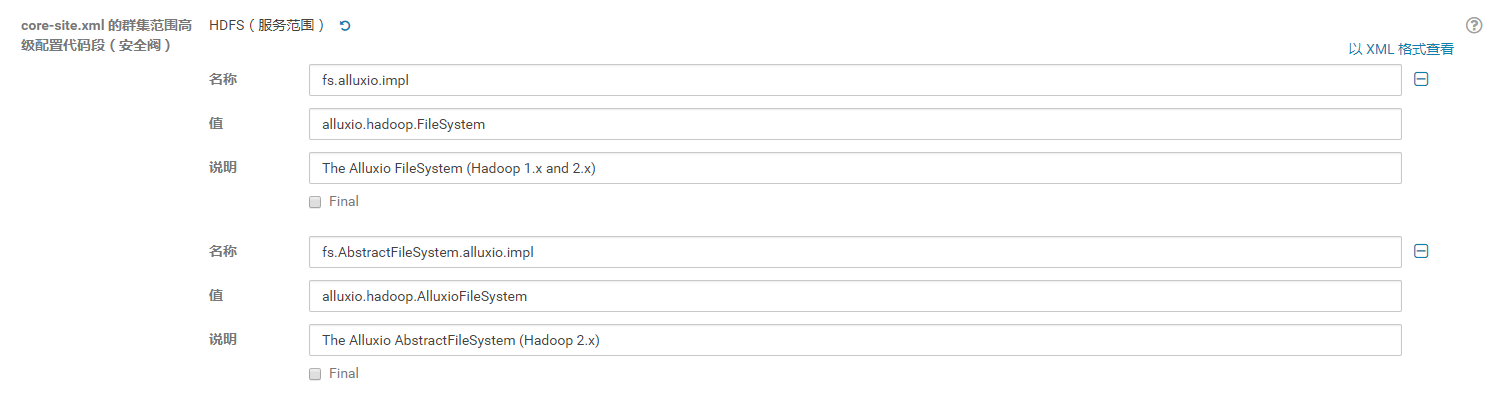
Hadoop的core-site.xml
<!--alluxio集成mapreduce的操作-->
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
<description>The Alluxio FileSystem (Hadoop 1.x and 2.x)</description>
</property>
<property>
<name>fs.AbstractFileSystem.alluxio.impl</name>
<value>alluxio.hadoop.AlluxioFileSystem</value>
<description>The Alluxio AbstractFileSystem (Hadoop 2.x)</description>
</property>
CDH UI则为
hadoop的hadoop-env.sh
export HADOOP_CLASSPATH=/opt/alluxio/client/alluxio-2.3.0-SNAPSHOT-client.jar:${HADOOP_CLASSPATH}
拷贝jar包到hadoop
cp /opt/alluxio/client/alluxio-2.3.0-SNAPSHOT-client.jar /opt/cloudera/parcels/CDH/lib/hadoop/lib/
● 分发更新后的hadoop配置文件和lib的jar包到每一个hadoop集群节点,重启hadoop和alluxio
检查集成mapreduce是否成功
integration/checker/bin/alluxio-checker.sh mapreduce
集成 Hive
修改配置文件
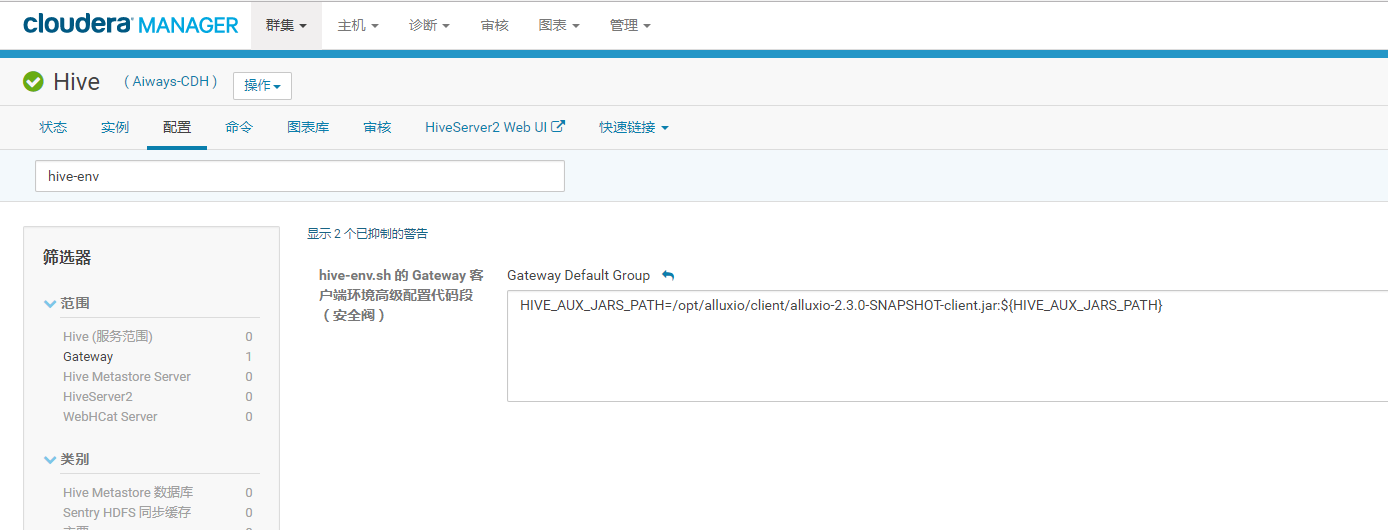
Hive的hive-env.sh
export HIVE_AUX_JARS_PATH=/opt/alluxio/client/alluxio-2.3.0-SNAPSHOT-client.jar:${HIVE_AUX_JARS_PATH}
CDH UI则为
在Alluxio上创建Hive表
有不同的方法可以将Hive与Alluxio整合。这一节讨论的是如何将Alluxio作为文件系统的一员(像HDFS)来存储Hive表。这些表可以是内部的或外部的,新创建的表或HDFS中已存在的表。
使用文件在Alluxio中创建新表
Hive可以使用存储在Alluxio中的文件来创建新表。设置非常直接并且独立于其他的Hive表。一个示例就是将频繁使用的Hive表存在Alluxio上,从而通过直接从内存中读文件获得高吞吐量和低延迟。
这里有一个示例展示了在Alluxio上创建Hive的内部表。你可以从http://grouplens.org/datasets/movielens/ 下载数据文件(如:ml-100k.zip)。然后接下该文件,并且将文件u.user上传到Alluxio的ml-100k/下:
./bin/alluxio fs mkdir /ml-100k
./bin/alluxio fs copyFromLocal ~/ml-100k/u.user alluxio://cdh01:19998//ml-100k
然后创建新的内部表:
hive> CREATE TABLE u_user (
userid INT,
age INT,
gender CHAR(1),
occupation STRING,
zipcode STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\u001'
LOCATION 'alluxio://cdh01:19998//ml-100k';
在ALluxio中使用已经存储在HDFS中的表
下面的HiveQL语句会将表数据的存储位置从HDFS转移到Alluxio中:
hive> alter table u_user set location "alluxio://cdh01:19998/user/hive/warehouse/u_user";
将表的元数据恢复到HDFS
下面的HiveQL语句可以将表的存储位置恢复到HDFS中:
hive> alter table TABLE_NAME set location "hdfs://cdh01:8020/user/hive/warehouse/u_user";
集成 Spark
修改配置文件
Spark的spark-defaults.conf
spark.driver.extraClassPath /opt/alluxio/client/alluxio-2.3.0-SNAPSHOT-client.jar
spark.executor.extraClassPath /opt/alluxio/client/alluxio-2.3.0-SNAPSHOT-client.jar
拷贝jar包到spark
cp /opt/alluxio/client/alluxio-2.3.0-SNAPSHOT-client.jar /opt/cloudera/parcels/CDH/lib/spark/lib/
cp /opt/alluxio/client/alluxio-2.3.0-SNAPSHOT-client.jar /opt/cloudera/parcels/CDH/jars/
● 分发更新后的配置文件和lib的jar包到每一个hadoop集群节点,重启相关服务。
其实对于spark本身而言,这样子一配置就算是集成alluxio了,因为spark只是计算框架,不需要做存储,从实现上来说也只是作为客户端可以对alluxio读写就可以。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号