
Python基础【第三篇】:变量与运算符
变量
变量的声明
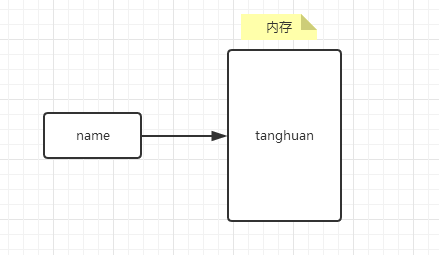
#!/usr/bin/env python # -*- coding: utf-8 -*- name = "tanghuan"
上述代码声明了一个变量,变量名为: name,变量name的值为:"tanghuan"
变量的作用:昵称,其代指内存里某个地址中保存的内容
变量定义的规则
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
变量的赋值
每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
等号(=)用来给变量赋值。
等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。例如:
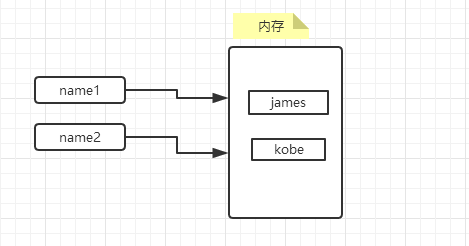
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "james" name2 = "kobe"
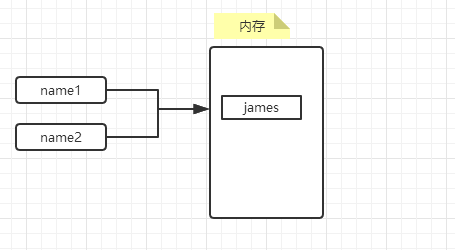
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "james" name1 = name2
Python 中的变量赋值不需要类型声明
#!/usr/bin/env python # -*- coding: utf-8 -*- name = "james" #字符串类型 age = 32 #int类型 point = 27.9 #浮点型 print(name,age,point)
C:\Users\dell>python.exe D:/first.py
james 32 27.9
python允许多个变量同时赋值
#!/usr/bin/env python # -*- coding: utf-8 -*- a = b = c = 2 print(id(a),id(b),id(c))
其中id(变量名),表示查看变量的内存地址。
输出:
C:\Users\dell>python.exe D:/first.py
1826292208 1826292208 1826292208
以上实例,创建一个整型对象,值为2,三个变量被分配到相同的内存空间上。
你也可以多个变量指定多个值。
#!/usr/bin/env python # -*- coding: utf-8 -*- a,b,c = 1,1.2,"james"
上述实例,我们将整型对象分配给变量a,将浮点对象1.2分配给变量b,将字符串对象"james"分配给变量c。
附:
变量定义的规范
文件名
全小写,可使用下划线
包
应该是简短的、小写的名字。如果下划线可以改善可读性可以加入。如mypackage。
模块
与包的规范同。如mymodule。
类
总是使用首字母大写单词串。如MyClass。内部类可以使用额外的前导下划线。
函数&方法
函数名应该为小写,可以用下划线风格单词以增加可读性。如:myfunction,my_example_function。
*注意*:混合大小写仅被允许用于这种风格已经占据优势的时候,以便保持向后兼容。
函数和方法的参数
总使用“self”作为实例方法的第一个参数。总使用“cls”作为类方法的第一个参数。
如果一个函数的参数名称和保留的关键字冲突,通常使用一个后缀下划线好于使用缩写或奇怪的拼写。
全局变量
对于from M import *导入语句,如果想阻止导入模块内的全局变量可以使用旧有的规范,在全局变量上加一个前导的下划线。
*注意*:应避免使用全局变量
变量
变量名全部小写,由下划线连接各个单词。如color = WHITE,this_is_a_variable = 1
*注意*:
1.不论是类成员变量还是全局变量,均不使用 m 或 g 前缀。
2.私有类成员使用单一下划线前缀标识,多定义公开成员,少定义私有成员。
3.变量名不应带有类型信息,因为Python是动态类型语言。如 iValue、names_list、dict_obj 等都是不好的命名。
常量
常量名所有字母大写,由下划线连接各个单词如MAX_OVERFLOW,TOTAL。
异常
以“Error”作为后缀。
缩写
命名应当尽量使用全拼写的单词,缩写的情况有如下两种:
1.常用的缩写,如XML、ID等,在命名时也应只大写首字母,如XmlParser。
2.命名中含有长单词,对某个单词进行缩写。这时应使用约定成俗的缩写方式。
例如:
function 缩写为 fn
text 缩写为 txt
object 缩写为 obj
count 缩写为 cnt
number 缩写为 num,等。
前导后缀下划线
一个前导下划线:表示非公有。
一个后缀下划线:避免关键字冲突。
两个前导下划线:当命名一个类属性引起名称冲突时使用。
两个前导和后缀下划线:“魔”(有特殊用图)对象或者属性,例如__init__或者__file__。绝对不要创造这样的名字,而只是使用它们。
*注意*:关于下划线的使用存在一些争议。
特定命名方式
主要是指 __xxx__ 形式的系统保留字命名法。项目中也可以使用这种命名,它的意义在于这种形式的变量是只读的,这种形式的类成员函数尽量不要重载。如
class Base(object):
def __init__(self, id, parent = None):
self.__id__ = id
self.__parent__ = parent
def __message__(self, msgid):
# …略
其中 __id__、__parent__ 和 __message__ 都采用了系统保留字命名法。
运算符
什么是运算符?
举个简单的例子:1 + 2 ,1和5叫做操作数,而“+”就是运算符。
Python支持下列运算符:
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 位运算符
- 成员运算符
- 身份运算符
接下来一一进行讲解
算数运算符
取变量a = 5,b = 2
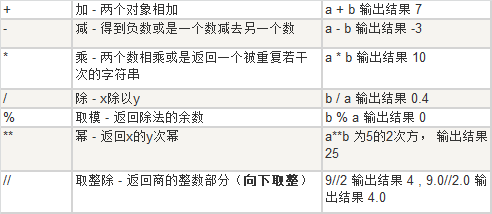
注意:在python2.X中,a/b返回的是整数,必须要将一个数改为浮点数。
#!/usr/bin/env python # -*- coding: utf-8 -*- a = 5.0 #改为浮点数 b = 2 print(a/b)
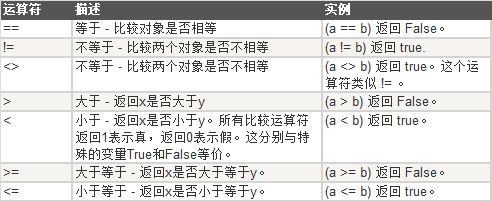
比较运算符
取变量a = 5,b = 10
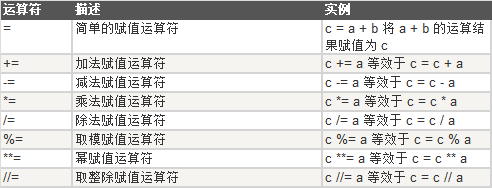
赋值运算符
位运算符使用不多,不作讲解。
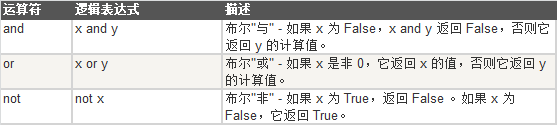
逻辑运算符
python的逻辑运算符与其他语言不太一样,java语言的逻辑运算符只返回True或者False,
且运算符||(或),&&(且),~(非)的两边必须是true或者false。
但是python的逻辑运算符两边可以是其他类型的变量,且返回值不只有true或者false。
取变量 a = 5 ,b = 10 。


1 a = 5 2 b = 10 3 print(a>b and a) #a>b的值为false,所以返回false 4 print(a>b and a<b) #a>b的值为false,所以返回false 5 print(a and a<b) #a的值不是false,返回a<b的值为true 6 print(a<b and b) #a<b的值不是false,返回b的值10 7 8 print(a<b or a<b) #a<b为true视为1非零,所以返回a>b的值true。 9 print(a or a<b ) #a的值为5非零,所以返回a的值5 10 print(a>b or b) #因为a>b为false视为0,则返回b的计算值10 11 print(a>b or b>5) #因为a>b为false视为0,所以返回b>5的计算值true
成员运算符
除了一些逻辑,算术运算符之外,python还包括一些实例对象的成员运算符,包括字符串,元祖。

1 a = 5 2 b = 10 3 Arr = [1, 2, 3, 4, 5] 4 name = "kobe_bryant" 5 name1 = "kobe" 6 name2 = "ebok" 7 if a in Arr: 8 print("a是list的成员") 9 else: 10 print("a不是list的成员") 11 if b in Arr: 12 print("b是list的成员") 13 else: 14 print("b不是list的成员") 15 if name1 in name: 16 print("name1是name的成员") 17 else: 18 print("name1不是name的成员") 19 if name2 in name: 20 print("name2是name的成员") 21 else: 22 print("name2不是name的成员")
以上实例输出结果:
1 C:\Python3.5.2\python.exe C:/Users/dell/PycharmProjects/Python_1/day10/firstPy.py 2 a是list的成员 3 b不是list的成员 4 name1是name的成员 5 name2不是name的成员
身份运算符
身份运算符用于查看两个对象是否属于同一个存储单元,就是比较两个对象的地址是否一样。

1 1 list = [1,2,3,4] 2 2 arr = list 3 3 if list is arr: 4 4 print("list和arr指向同一个内存单元") 5 5 print("list的地址为:",id(list)) 6 6 print("arr的地址为:",id(arr)) 7 7 else: 8 8 print("list 和 arr指向的不是同一个内存单元") 9 9 arr1 = list[:] 10 10 if arr1 is list: 11 11 print("list和arr1指向同一个内存单元") 12 12 else: 13 13 print("list和arr1不是指向同一个内存单元") 14 14 print("list的地址是:",id(list)) 15 15 print("arr1的地址是:",id(arr1))
此实例输出的结果为:
1 C:\Python3.5.2\python.exe C:/Users/dell/PycharmProjects/Python_1/day10/firstPy.py 2 list和arr指向同一个内存单元 3 list的地址为: 2313605031112 4 arr的地址为: 2313605031112 5 list和arr1不是指向同一个内存单元 6 list的地址是: 2313605031112 7 arr1的地址是: 2313605004040
对于上述实例,我们可以引申出运算符”==“和”is“的区别,在上述代码加入如下代码:
if arr1 == list: print("list和arr1中的内容是一样的") else: print("list和arr1中的内容是不一样的")
输出:
list和arr1中的内容是一样的
运算符“==”和“is”的区别
举一个例子:我家买了一辆奔驰,你家买了一辆奔驰,我家的奔驰和你家的一样吗?用“==”来判断的话两辆奔驰就是一样的,因为两辆奔驰没有任何不同,同一个地方买
的,相同的型号。但是用“is”来判断的话,两辆奔驰就不一样了,因为他们处在不一样的地方,地址不同。
记住这一点:两个变量对应的内存地址是一样的,那么他们的值在内存中只有一个;如果两个变量对应的内存地址不一样,但是两个变量对应的值完全一样,那么,这
个值是在地址里面存了两份的。
1 >>> a = "tanghuan" 2 >>> b = "tanghuan" 3 >>> id(a) 4 2423859864688 5 >>> id(b) 6 2423859864688 7 >>> c = 2.5 8 >>> d = 2.5 9 >>> id(c) 10 2423858045216 11 >>> id(d) 12 2423858045168 13 >>>
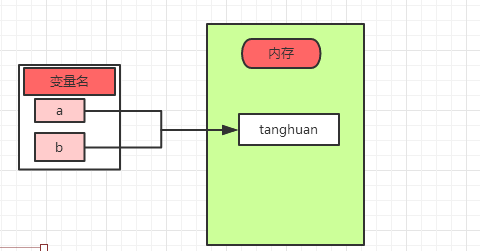
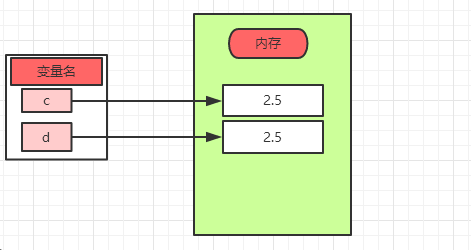
python中值相同的话,内存地址不一定一样
python中会为每个出现的对象分配内存,哪怕他们的值完全相等(注意是相等不是相同)。如执行a=1.4,b=1.4这两个语句时会先后为1.4这个Float类型对象分配内存,然后将a与b分别指向这两个对象。所以a与b指向的不是同一对像:
1 >>> a=1.4 2 >>> b=1.4 3 >>> id(a) 4 2423858045216 5 >>> id(b) 6 2423858045288
但是为了提高内存利用效率对于一些简单的对象,如一些数值较小的int对象,python采取重用对象内存的办法,如指向a=2,b=2时,由于2作为简单的int类型且数值小,python不会两次为其分配内存,而是只分配一次,然后将a与b同时指向已分配的对象,字符串类型也是如此:
1 >>> a=2 2 >>> b=2 3 >>> id(a) 4 1826292208 5 >>> id(b) 6 1826292208 7 >>> c="tanghuan" 8 >>> d="tanghuan" 9 >>> id(c) 10 2423859865392 11 >>> id(d) 12 2423859865392 13 >>>
如但果赋值的不是2而是较大的数值,情况就跟前面的不一样了:
1 >>> a = 256
2 >>> b = 256
3 >>> a is b
4 True
5 >>> a = 257
6 >>> b = 257
7 >>> a is b
8 False
每个电脑的内存分配不同,所以到底是哪个值使得内存要分配两次,不得而知,本人觉得这也是python的缺陷。
python没有自增(++)、自减(--)符号
因为在 Python 里的数值和字符串之类的都是不可变对象,对不可变对象操作的结果都会生成一个新的对象。
python不同于其他编程语言,比如C/Java。
在Java或者C中创造一个整形对象 int a=1,如果进行运算a = a + 1,那么a的内存地址不会变的,只不过内存中的数值由1变成了2。但是在python中就不一样了,他有另一套机制。
比如a = 1,a += 1,那么解释器会创造一个内存来存放2,然后变量a再指向2,而不是原来的地址。
1 >>> id(1) 2 1826292176 3 >>> a = 1 4 >>> id(a) #a的地址和1一样 5 1826292176 6 >>> id(2) 7 1826292208 8 >>> a += 1 #a的地址和2一样,a改变了地址 9 >>> id(a) 10 1826292208 11 >>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号