
Python基础【第七周】:文件和数据格式化(词云实例)
学习任务

文件的使用
什么叫文本文件?
由单一特定的编码(如utf-8)组成的文件叫文本文件。文本文件也被看做是存储着的长字符串。
什么是二进制文件?
直接由比特0与1组成,么有统一字符编码,一般存在二进制0和1的组织结构。适用于png文件,avi文件等。
总之有统一编码的叫文本文件,没有统一编码的叫二进制文件,但是任何文件均可以用二进制编码表示。用二进制方式打开文件,就可以将字符转化为最初的存储形式。


文件的使用流程
打开——操作——关闭
首先要使文件变成占用状态才可以对文件进行操作,也就是要打开文件。
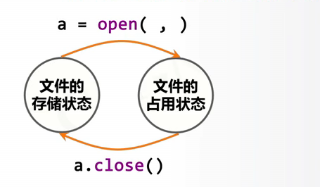

文件的打开

路径和名称可以是绝对也可以是相对
注意:windows下的“\”在python中时转义符,所以需要用‘“\\”
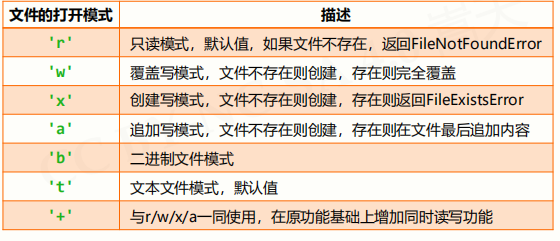
打开模式

文件读写的方法
读的方法:
文件内容为:Kobe作为世界上最伟大的球员,
他对很多人产生了影响
1 f = open("test.txt",'r') 2 print(f.read(4))#读入前4个字符,默认读出全部 3 print(f.readline(2))#读入第一行前两个字符,默认读一行 4 print(f.readlines())#以每行作为元素形成列表,默认读全部。 5 #注意:读方法,都是接着上面读,不重复读取 6 #所以上述输出为 7 # Kobe 8 # 作为 9 # ['世界上最伟大的篮球运动员\n', '他对很多人产生了影响']
有时候文件太大,一次读入不可取,可使用按数逐步处理

对于大文件,这个方法更可取
逐行遍历也是个不错的、常用的办法
一 . 一次读入,分行处理

二. 分行读入,逐行处理

fo其实是一个io流。
写的方法:
f = open("test.txt",'w') s = "kobe is the best basketball player" f.write(s)#将字符串直接写入 s = ["kobe","james","jordan"] f.writelines(s)#将列表元素不分行,直接链接写入 f.close() #写入文件:kobe is the best basketball playerkobejamesjordan
注意方法f.writelines(s),这并不是一个元素一行,而是直接拼接。
当我们想要改变读写的光标位置时,使用方法


这是因为在写完之后,指针(光标)已经到了文件尾部,再进行遍历的话,当然不会有其他内容。

实例:自动轨迹绘制

使用数据脚本,是自动化、模块化的第一步。也就是根据数据脚本,然后通过特定程序,将数据加以实现,变成可视。
问题分析:
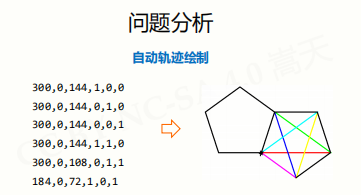
基本思路:
- 定义数据文件格式(接口),也就是数据文件和程序之间的规范。
- 编写程序,根据文件接口解析参数绘制图形。
- 编制数据文件。
数据接口定义是非常主观的,没有规范。下面每个数字就是接口,因为每个人对数字的解释即设定不一样,所以带有主观色彩。

代码:

代码解析:
map函数:map(parameter1,parameter2),其中parameter1是函数名字,parameter2是具有多个元素的迭代类型,一般是序列,map函数的作用是将parameter1的函数,作用到parameter2的每个元素,生成一个map数据类型
s = "KOBE,JAMES,JORDAN" m = map(str.lower,s.split(",")) #m是一个map对象,需要再次使用list将其转换 print(list(m)) #输出['kobe', 'james', 'jordan']
实例蕴含的思想:
自动化思维:数据和功能分离,数据驱动的自动运行
接口化设计:格式化设计接口,清晰明了。如本例中的数据间的逗号。
如果说我们要变换不同的图形,则只要更换数据文件即可,而不需要更换程序,这达到了程序复用的目的。
应用扩展:
可以扩展接口设计,增加更多的控制接口,比如说转向多少度、跳转到特定区域等等
扩展功能设计,增加弧形等更多功能
一维数据的格式化
数据的格式化
一维数据主要指:列表、数组、集合等
二维数据是由一维数据构成,是一维数据的组合形式

多维数据是一维或者二维数据在新维度上扩展形成,比如上述高校排名在时间维度上扩展。


二维数据的格式化
使用列表表达二维数据

csv格式与二维数据的存储
csv格式就是用逗号分割的值

举例:
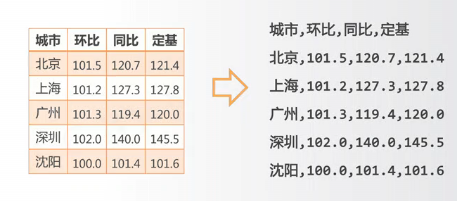

如果数据中包含逗号,那么在逗号两侧包含引号,从而识别此逗号不是用来分割值的。

二维数据的读入处理
从csv中读入数据

二维数据的写入处理

注意:使用join函数时,item中的每个元素都要是字符串,所以先要把二维列表中的数字都转化为字符串。
ls = [["kobe",81],["james",60],["jordan",70]] ls = [[str(j) for j in i] for i in ls ]
采用两层循环转化为字符串。
二维数据的逐一处理


词云实例wordcloud



词云文本为空格分割的大字符串。
词云对文本的自动处理:

词云的参数改变


文本中频数越大的词,字号越大。font_step表示随着频数增大,字号增大的步进间隔。

font_path指的是使用什么风格的字体,msyh.ttc指的是微软雅黑。

控制词云单词量。
如何制定词云形状?

实例:政府工作报告词云图
《决胜全面建成小康社会 夺取新时代中国特色社会主义伟大胜利》
文件来源:https://python123.io/resources/pye/新时代中国特色社会主义.txt
《中共中央 国务院关于实施乡村振兴战略的意见》
文件来源:https://python123.io/resources/pye/关于实施乡村振兴战略的意见.txt

代码:
1 import jieba 2 import wordcloud 3 import requests 4 import imageio#用于生成词云图片轮廓 5 #首先从网络获取字符串 6 #txt1为《决胜全面建成小康社会 夺取新时代中国特色社会主义伟大胜利》 7 #txt2为《中共中央 国务院关于实施乡村振兴战略的意见》 8 txt1 = requests.get("https://python123.io/resources/pye/新时代中国特色社会主义.txt").text 9 txt2 = requests.get("https://python123.io/resources/pye/关于实施乡村振兴战略的意见.txt").text 10 #再利用jieba库分词,且去除单个字符的词语。再使用空格连接成大字符串 11 words1 = " ".join([word for word in jieba.lcut(txt1) if len(word) != 1]) 12 words2 = " ".join([word for word in jieba.lcut(txt2) if len(word) != 1]) 13 14 #生成词云,设置参数 15 #首先先将图像轮廓设定出来 16 mk = imageio.imread("test.png") 17 w = wordcloud.WordCloud(width=600,height=600,#设定大小 18 background_color="white",#背景颜色 19 font_path="msyh.ttf",#字体风格 20 max_words = 200,#词数限制 21 stopwords=wordcloud.STOPWORDS.add("美国"),#屏蔽词语美国 22 mask = mk#设定图像轮廓 23 ) 24 #加载词云文本 25 w.generate(words1) 26 w.to_file("pywordcloud1.png") 27 w.generate(words2) 28 w.to_file("pywordcloud2.png")
结果:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号