


Python基础【第六周】:组合数据类型(包含实例词频统计)
组合数据类型为集合,序列(列表、元组),字典
具体可见https://www.cnblogs.com/dadahuan/p/9564737.html
jieba库的简介
jieba是优秀的中文分词的第三方库。
由于中文是连续书写的,我们就需要用一定的手段去获取文章中单个词语,这种手段就叫分词。
安装 (cmd命令行)pip install jieba 注:安装外在库,可能会因为网速等原因而失败,可以更换镜像,本人笔者使用的是豆瓣的镜像。具体可见笔者之前的文章。https://www.cnblogs.com/dadahuan/articles/12263880.html
简单来说,jieba库是通过中文分词库来识别分词

jieba库有三种模式

jieba的常用函数

默认就是精确模式。

将所有的可能的词语均分出来,会有冗余
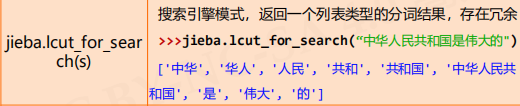
搜索引擎模式也会冗余。首先是在精确模式下分词出:中华人民共和国,再在其基础上将其分词。

实例:词频统计
hamlet实例
代码:


1 #词频统计 2 import requests 3 import wordcloud 4 hamlet_txt = requests.get('https://python123.io/resources/pye/hamlet.txt').text 5 #英文词频不能使用jieba库,但程序相对简单 6 def getword(txt): 7 txt = txt.lower() 8 for ch in '!,:#$%^&*?/:";<=>@()[]{}\|': 9 txt = txt.replace(ch," ") 10 txt_list = txt.split() 11 return txt_list 12 #txt_list 是单词列表 13 txt_list = getword(hamlet_txt) 14 dist_word = {} 15 for word in txt_list: 16 dist_word[word] = dist_word.get(word,0)+1 17 items = list(dist_word.items()) 18 #按照出现次数降排序 19 items.sort(key=lambda x:x[1],reverse=True) 20 #输出使用次数前十的单词 21 for i in range(10): 22 word , count = items[i] 23 print("{0:<10}{1:>5}".format(word,count))
上述代码,有几处值得一讲。
1. request库的使用
hamlet_txt = requests.get('https://python123.io/resources/pye/hamlet.txt').text
上述url是一个文档的直接链接,故可以直接使用.text来获取文档形成的字符串
2. 使用sort函数进行排序
1 d = {"kobe":1,"james":3,"jordan":2} 2 items = list(d.items()) 3 items.sort(key = lambda x:x[1],reverse = True) 4 #按照键值对第二个元素,降序排 5 print(items) 6 #第二种方法:先定义一个临时函数 7 def second(ele): 8 return ele[1] 9 items.sort(key = second) 10 ##按照键值对第二个元素,升序排 11 print(items) 12 #输出: 13 [('james', 3), ('jordan', 2), ('kobe', 1)] 14 [('kobe', 1), ('jordan', 2), ('james', 3)]
三国演义实例
代码:
1 #词频统计 2 import requests 3 import jieba 4 threekingdoms_txt = requests.get('https://python123.io/resources/pye/threekingdoms.txt').text 5 txt_list = jieba.lcut(threekingdoms_txt) 6 dist_word = {} 7 for word in txt_list: 8 if len(word) == 1:#如果词只有一个字符,则忽略 9 continue 10 else: 11 dist_word[word] = dist_word.get(word,0)+1 12 items = list(dist_word.items()) 13 #按照出现次数降排序 14 items.sort(key=lambda x:x[1],reverse=True) 15 #输出使用次数前十的单词 16 for i in range(15): 17 word , count = items[i] 18 print("{0:<10}{1:>5}".format(word,count))
输出结果:
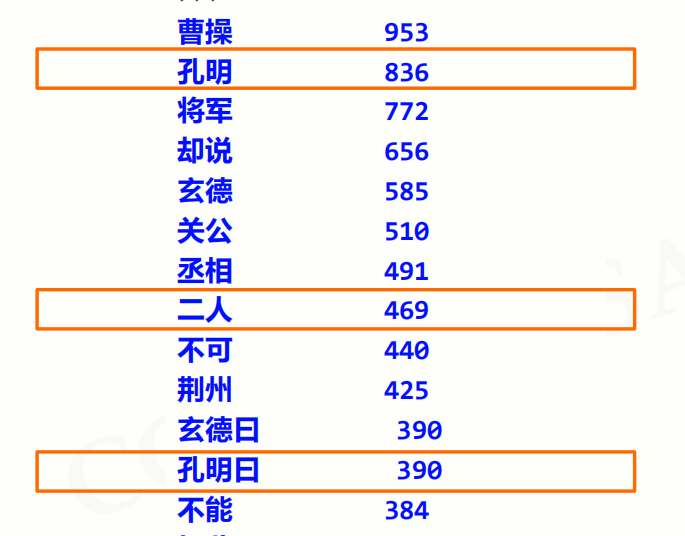
这明显不符合实际需求,并没能达到出场人物的次数统计。出现了大量了与人无关,而且出现了重复。
那么我们改造一下代码。
1 #词频统计 2 import requests 3 import jieba 4 threekingdoms_txt = requests.get('https://python123.io/resources/pye/threekingdoms.txt').text 5 txt_list = jieba.lcut(threekingdoms_txt) 6 excludes = {"将军","却说","荆州","二人","不可","不能","如此","\r\n"} 7 dist_word = {} 8 for word in txt_list: 9 if len(word) == 1:#如果词只有一个字符,则忽略 10 continue 11 #替换类似词语 12 elif word == "诸葛亮" or word == "孔明曰": 13 reword = "孔明" 14 elif word == "关公" or word == "云长": 15 reword = "关羽" 16 elif word == "玄德" or word == "玄德曰": 17 reword = "刘备" 18 elif word == "孟德" or word == "丞相": 19 reword = "曹操" 20 else: 21 reword = word 22 dist_word[reword] = dist_word.get(reword,0)+1 23 #删除不符合的词语 24 for word in excludes: 25 del dist_word[word] 26 items = list(dist_word.items()) 27 #按照出现次数降排序 28 items.sort(key=lambda x:x[1],reverse=True) 29 #输出出场次数前十五的人物 30 for i in range(15): 31 word , count = items[i] 32 print("{0:<10}{1:>5}".format(word,count))
上述无论是删除无关词语,还是替换相同含义的词语,都是通过不断运行程序得来的。
所以第一次置换的结果为:
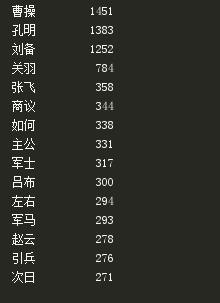
可见依旧不如意,只有在不断运行程序,不断修改,才可以到达预期效果

1. 指定元素排序,使用以下两种方法
d= {"kobe":1,"james":3,"jordan":2}
items = list(d.items())
items.sort(key = lambda x:x[1],reverse = True)
#按照键值对第二个元素,降序排
print(items)
#第二种方法:先定义一个临时函数
def second(ele):
return ele[1]
items.sort(key = second)
##按照键值对第二个元素,升序排
print(items)
#输出:
[('james', 3), ('jordan', 2), ('kobe', 1)]
[('kobe', 1), ('jordan', 2), ('james', 3)]

