4 - django-orm基本使用
1 数据库与ORM
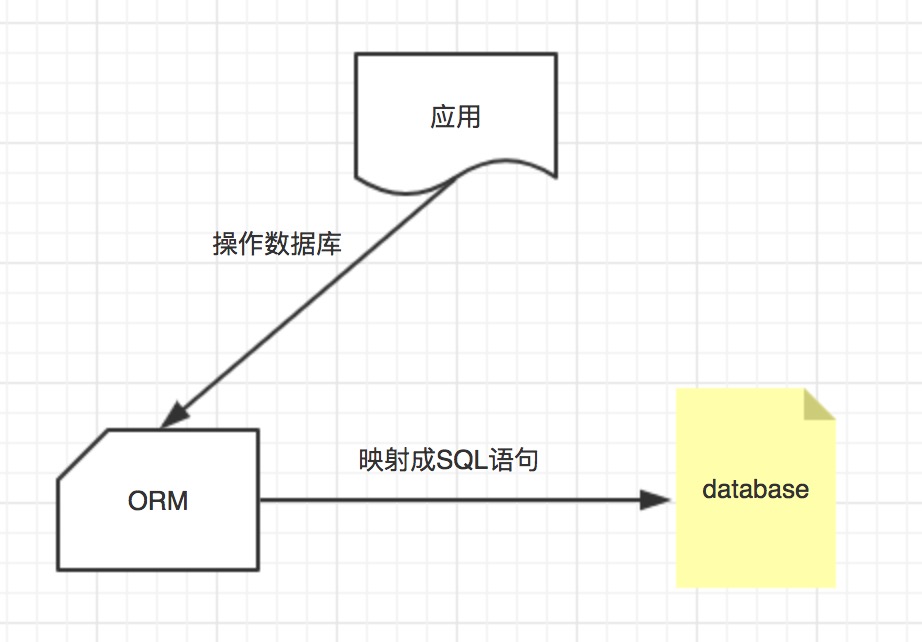
对象关系映射(英语:(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换 。从效果上说,它其实是创建了一个可在编程语言里使用的--“虚拟对象数据库”。
简单一句话来说:就是把数据库的表映射为一个个对象,对对象的操作会被映射成SQL语句,在数据库执行。
2 orm的配置
django默认支持sqlite,mysql, oracle,postgresql数据库。
- sqllit: django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
- mysql: 引擎名称:django.db.backends.mysql
2.1 引擎和配置
在django的项目中会默认使用sqlite数据库,在settings里有如下设置:
DATABASES = {
'default': {
- 'ENGINE': 'django.db.backends.sqlite3',
- 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
下面是MySQL的配置
DATABASES = {
'default': {
- 'ENGINE': 'django.db.backends.mysql',
- 'NAME': 'books', # 你的数据库名称
- 'USER': 'root', # 你的数据库用户名
- 'PASSWORD': '', # 你的数据库密码
- 'HOST': '',- # 你的数据库主机,留空默认为localhost
- 'PORT': '3306', # 你的数据库端口
}
}
参数如下:
- NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建
- USER和PASSWORD分别是数据库的用户名和密码。
2.2 mysql驱动程序
django可以使用如下mysql的驱动程序:
MySQLdb(不完美支持Python3)
mysqlclient (官方建议)
PyMySQL(纯python的mysql驱动程序)
建议使用:
- mysqlclient
- PyMySQL
django基础配置部分已经描述了mysqlclient的安装,这里介绍如何使用pymysql,首先需要安装
pip install pymysql
下一步只需要找到项目名文件下的__init__,在里面写入:
import pymysql
pymysql.install_as_MySQLdb()
即可完成配置
3 orm 表模型
我们所说的ORM主要分为两种:
DB First数据库里先创建数据库表结构,根据表结构生成类,根据类操作数据库Code First先写代码,执行代码创建数据库表结构
主流的orm都是code first。django 的orm也是code first,所以本质上分为两部分:
- 根据类自动创建数据库表
- 根据类对数据库表中的数据进行各种操作
3.1 创建表对象
现在有一张表,主要字段如下:

对应的models中的映射类为:
from django.db import models # 导入models,django提供的对象包含很多建表的方法
# Create your models here.
class UserInfo(models.Model): # 需要继承models.Model
class Meta:
db_table = 'userinfo' # 在数据库中生成的表明
id = models.AutoField(primary_key=True,null=False,verbose_name='ID')
name = models.CharField(max_length=4,null=False,verbose_name='用户名')
password = models.CharField(max_length=64,null=False,verbose_name='密码')
email = models.EmailField(null=False,verbose_name='邮箱')
# AutoField : 自增字段,类似于mysql的int字段加auto_increment属性
# CharField:可变长字段,类似于mysql的varchar类型,需要指定长度
# EmailField:邮件字段,仅仅提供给 django admin进行约束使用,映射到MySQL上,根本上也是字符串类型
# null:是否为空,通用参数,默认为否。
# verbose_name:django admin上对表操作时,显示的字段名称
# primary_key:主键
# max_length:针对于CharField字段,标示其长度
3.2 Django字段类型
部分字段类型及说明如下:
| 字段名称 | 含义 |
|---|---|
| AutoField(Field) | int自增列,必须填入参数 primary_key=True |
| BigAutoField(AutoField) | bigint自增列,必须填入参数 primary_key=True 注:当model中如果没有自增列,则自动会创建一个列名为id的列 |
| SmallIntegerField(IntegerField) | 小整数 -32768 ~ 32767 |
| PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) | 正小整数 0 ~ 32767 |
| IntegerField(Field) | 整数列(有符号的) -2147483648 ~ 2147483647 |
| PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) | 正整数 0 ~ 2147483647 |
| BigIntegerField(IntegerField) | 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807 |
| BooleanField(Field) | 布尔值类型 |
| NullBooleanField(Field) | 可以为空的布尔值 |
| CharField(Field) | 字符类型,必须提供max_length参数, max_length表示字符长度 |
| TextField(Field) | 文本类型 |
| EmailField(CharField) | 字符串类型,Django Admin以及ModelForm中提供验证机制 |
| IPAddressField(Field) | 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制 |
| GenericIPAddressField(Field) | 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6 |
| URLField(CharField) | 字符串类型,Django Admin以及ModelForm中提供验证 URL |
| SlugField(CharField) | 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号) |
| CommaSeparatedIntegerField(CharField) | 字符串类型,格式必须为逗号分割的数字 |
| UUIDField(Field) | 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证 |
| FilePathField(Field) | 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功 |
| FileField(Field) | 字符串,路径保存在数据库,文件上传到指定目录 |
| ImageField(FileField) | 字符串,路径保存在数据库,文件上传到指定目录 |
| DateTimeField(DateField) | 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] |
| DateField(DateTimeCheckMixin, Field) | 日期格式 YYYY-MM-DD |
| TimeField(DateTimeCheckMixin, Field) | 时间格式 HH:MM[:ss[.uuuuuu]] |
| DurationField(Field) | 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型 |
| FloatField(Field) | 浮点型 |
| DecimalField(Field) | 10进制小数 |
| BinaryField(Field) | 二进制类型 |
3.3 常用字段参数说明
django中提供了很多参数对字段进行控制
通用类:
| 属性 | 含义 |
|---|---|
| null | 是否可以为空 |
| default | 默认值 |
| primary_key | 主键 |
| db_column | 列名 |
| db_index | 索引(bool) |
| unique | 唯一索引 |
时间日期类:
| 属性 | 含义 |
|---|---|
| unique_for_date | 对日期字段来说,表示只对时间做索引 |
| unique_for_month | 对日期字段来说,表示只对月份做索引 |
| unique_for_year | 对日期字段来说,表示只对年做索引 |
| auto_now | 无论是你添加还是修改对象,时间为你添加或者修改的时间。 |
| auto_now_add | 为添加时的时间,更新对象时不会有变动。 |
django admin相关:
| 属性 | 含义 |
|---|---|
| choices | 在django admin中显示下拉框,避免连表查询(比如用户类型,可以在存在内存中) |
| blank | 在django admin中是否可以为空 |
| verbose_name | 字段在django admin中显示的名称 |
| editable | 在django admin中是否可以进行编辑,默认是true |
| error_message | 当在django admin中输入的信息不匹配时,字段的提示信息 |
| help_text | 在django admin中输入框旁边进行提示 |
| validators | 在django admin中自定义规则限制 |
django中提供了很多的字段类型,大部分都是提供给django admin 来做验证的,实际体现在数据库中的,大部分都是字符串类型。
3.4 特殊类型字段参数说明
GenericIPAddressField(Field):字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6
参数:
- protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6"
- unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启刺功能,需要protocol="both"
FilePathField(Field):字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能
参数:
- path:文件夹路径
- match=None:正则匹配
- recursive=False:递归下面的文件夹
- allow_files=True:允许文件
- allow_folders=False:允许文件夹
FileField(Field):字符串,路径保存在数据库,文件上传到指定目录
参数:
- upload_to = "":上传文件的保存路径
- storage = None:存储组件,默认django.core.files.storage.FileSystemStorage
ImageField(FileField):字符串,路径保存在数据库,文件上传到指定目录
参数:
- upload_to = "" 上传文件的保存路径
- storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
- width_field=None, 上传图片的高度保存的数据库字段名(字符串)
- height_field=None 上传图片的宽度保存的数据库字段名(字符串)
DecimalField(Field):10进制小数
参数:
- max_digits,小数总长度
- decimal_places,小数位长度
3.5 Meta信息
在类内部定义内部类Meta,由于设置映射的表的元数据信息,
class User(models.Model):
class Meta:
db_name = 'user'
id...
name...
这里的Meta的类属性db_name,表示生成的数据库表名称为'user',更多的参数有:
| 属性信息 | 含义 |
|---|---|
| db_tablespace | 有些数据库有数据库表空间,比如Oracle。你可以通过db_tablespace来指定这个模型对应的数据库表放在哪个数据库表空间。 |
| managed | 默认值为True,Django可以对数据库表进行 migrate或migrations、删除等操作,如果为False的时候,不会对数据库表进行创建、删除等操作。可以用于现有表、数据库视图等,其他操作是一样的。 |
| ordering | 告诉Django模型对象返回的记录结果集是按照哪个字段排序的 |
| unique_together | 设置两个字段保持唯一性时使用 |
| verbose_name | 给模型类起一个更可读的名字 |
常用的就是db_table,用于指定生成的表的名称
3.6 生成表
前面我们已经编写了对应数据库表的类,这里我们将进行实例化(创建数据库对应的表)。利用django提供的命令进行数据库的初始化工作.(以及其他对数据库表进行修改的动作,比如修改表结构,字段属性等,都需要执行如下步骤)
# 进入项目目录下执行
python manage.py makemigrations
# 大致含义是:把类转换成对应格式的sql语句。
# 创建表
python manage.py migrate
# 在数据库中执行生成的sql语句
注意:
- 执行makemigrations后生成的文件,存放在应用目录下的migrations目录下,一般以0001_initial.py为文件名并且依次递增。
- 0001_initial.py存放的是 django 根据我们写的 class 生成的相关代码,执行migrate后,会根据这些代码生成对应的数据库表。
- 如果我们执行migrate后没有生成我们创建的表格,那么需要确认在django配置文件中,是否加载了我们的应用(因为django会加载setting里面的install_app中查找对应的modules.py)
- 表名默认是:应用名_class类名,可以在映射类内部定义内部类Meta,设置db_table='表名',来修改在数据库中生存的表名
3.6.1 注册app
如果没有生成对应的表文件,那么需要在settings.py中,注册你的app
# settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config',
'你的app名称'
]
3.6.2 修改表结构遇到的问题
当我们对已生成的表添加新字段时,会出现如下情况
ou are trying to add a non-nullable field 'code' to business without a default; we can't do that (the database needs something to populate existing rows).
Please select a fix:
1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
2) Quit, and let me add a default in models.py
Select an option:
由于我们添加字段会影响之前的数据,所以这时django提醒我们,不能只是单纯的添加一个字段,还需要为该字段指定对应的值,当然有几种解决办法:
- 设置新增字段default属性,表示其默认值
- 设置新增字段null属性,表示其默认可以为空
- 根据上面的提示,选择1,手动输入默认值即可(注意默认值需要用引号引起来,不然django认为输入的数据是个变量)
4 利用orm完成数据库的增删改查
接下来就需要利用orm来对数据库的表数据进行增删改查等基本操作了。
4.1 orm之增加
根据django的MTV架构,业务的处理是在views中完成的,那么对数据库的查询逻辑也应该在views中编写,而我们定义的数据库对象在model.py中,那么在导入之后,才能进行表操作。
django提供了两种增加数据的方式:1、create,2、save
#------------------------------------- create -------------------------------------
from app01 import models # 从自己的应用中导入models模块
username = 'daxin'
password = 'abc.123'
email = 'daixin@qq.com'
models.UserInfo.objects.create(name=username,password=password,email=email)
# 表对象.objects.create() 用来新增数据
# name,password,email 表示表的字段
# 等号右边的表示数据
# 传递的key也可以是字典利用**dic进行传递,在后面利用form的时候会经常使用这种方式。
dict = {'usernane':'daxin','password':'abc.123',email='daxin@qq.com'}
models.UserInfo.objects.create(**dict)
#------------------------------------- save -------------------------------------
from app01 import models # 从自己的应用中导入models模块
username = 'daxin'
password = 'abc.123'
email = 'daixin@qq.com'
userobj = models.UserInfo(name=username,password=password,email=email)
userobj.save()
# save的方式是利用对象实例化的传递参数后,调用save方法进行保存的
# 利用对象,我们可以方便的进行数据修改后,再进行save
# 比如 userobj.name = 'dahuaidan'
# userobj.save()
注意:利用create新增数据时,会默认返回新增加的数据对象,我们可以接受该对象来进行其他的操作,比如添加多对多关系等
比较常用的方式是 利用create进行数据的增加
4.2 orm之删除
想要对数据进行删除,首先需要匹配到数据,然后执行删除操作,那么就涉及两部分:查找,删除
models.UserInfo.objects.filter(id=1).delete()
# 利用filter对数据唯一的字段进行过滤,匹配到删除的行,也可以用all()匹配所有数据,进行删除
# 利用delete方法进行删除操作
4.3 orm之修改
整体思路和删除是相同的,首先查找到数据,然后对字段进行修改
models.UserInfo.objects.filter(id=1).update(name='dachenzi')
# 利用filter过滤到要修改的数据,然后更新它的name字段的值
4.4 orm之查询
查询会返回结果的集,它是django.db.models.query.QuerySet类型。是惰性求值,和sqlalchemy一样。结果就是查询的集。同时它也是一个可迭代对象。
- 创建查询集不会带来任何数据库的访问,直到调用方法使用数据时,才会访问数据库。在迭代、序列化、if语句中
都会立即求值。 - 每一个查询集都包含一个缓存,来最小化对数据库的访问。
4.4.1 查询过滤方法
返回结果集的方法:
| 名称 | 说明 |
|---|---|
| all() | 获取所有 |
| filter() | 过滤,返回满足条件的数据 |
| exclude() | 排除,排除满足条件的数据 |
| order_by() | 以什么字段排序(在字段前面加减号,表示倒序) |
| values() | 返回一个对象字典的列表,列表的元素是字典,字典内是字段和值的键值对 |
| values_list() | 返回一个对象字典的列表,列表的元素是元组,字典内是字段和值的键值对 |
models.Userinfo.object.all().values('id','username')
# 表示只取指定的id和username列
# 结果依旧返回的是QuerySet,但是数据不同,体现的形式是一个字典
QuerySet({'id':1,'username':'daxin'},{'id':2,'username':'dachenzi'}......)
# 使用value_list('id','username'),体现的形式是一个元组
QuerySet((1,'daxin'),(2,'dachenzi')......)
关于filter:
- filter(k1=v1).filter(k2=v2) 等价于 filter(k1=v1, k2=v2)
- filter(pk=10) 这里pk指的就是主键, 不用关心主键字段名,当然也可以使用使用主键名filter(std_id=10)
获取结果集的方法通过适当的组合可以链式编写。
返回单个值的方法:
| 名称 | 说明 |
|---|---|
| get() | 仅返回单个满足条件的对象 如果未能返回对象则抛出DoesNotExist异常; 如果能返回多条抛出MultipleObjectsReturned异常 |
| count() | 返回当前查询的总条数 |
| first() | 返回第一个对象 |
| last() | 返回最后一个对象 |
| exist() | 判断查询集中是否有数据,如果有则返回True |
# 获取表里所有的对象
models.UserInfo.objects.all() # 结果为一个QuerySet对象(django提供的),可以理解为一个列表
# 获取id为1的对象
models.UserInfo.objects.filter(id=1) # 类似于sql中的 where查询条件,结果也是一个QuerySet
# 获取name字段包含da的记录
models.UserInfo.objects.filter(name__contains='da') # 这里涉及了万能的双下划线,在后续会进行说明
# get获取一条数据
models.UserInfo.objects.get(id=1) # 注意get不到数据,会直接抛出异常
# 除了id等于1的其他数据
models.UserInfo.objects.exclude(id=1)
注意:
- 查找到的不是想sql语句那样直接列出一行的各个字段及对应的值,而已把改行表示为一个行对象。匹配到一行,就表示1个表中的行对象。
- 每个对象内才包含了对应的字段和值。
- 通过 行对象.字段名,来获取对应的数据。
- filter中包含多个条件,那么它们是and的关系。
PS:由于filter、all取到的数据默认是 QuerySet 格式,在某些场景下我们只需要验证是否取到,我们可以直接获取结果中的第一个数据即可,即在最后添加.first()即可,表示取第一个数据,或者使用.count()来统计匹配到的数据的个数。
module.UserInfo.filter(username='daxin').first()
4.4.2 限制查询集(切片)
查询集对象可以直接使用索引下标的方式(不支持负索引),相当于SQL语句中的limit和offset子句。
注意使用索引返回的新的结果集,依然是惰性求值,不会立即查询。
qs = User.objects.all()[20:40]
# LIMIT 20 OFFSET 20
qs = User.objects.all()[20:30]
# LIMIT 10 OFFSET 20
4.4.2 字段查询(双下划线)
字段查询表达式可以作为filter()、exclude()、get()的参数,实现where子句。
语法:字段名称__比较运算符=值,属性名和运算符之间使用双下划线
比较运算符如下
| 名称 | 举例 | 说明 |
|---|---|---|
| exact filter(isdeleted=False) |
filter(isdeleted__exact=False) | 严格等于,可省略不写 |
| contains | exclude(title__contains='天') | 是否包含,大小写敏感,等价于like '%天%' |
| statswith endswith |
filter(title__startswith='天') | 以什么开头或结尾,大小写敏感 |
| isnull isnotnull |
filter(title__isnull=False) | 是否为null |
| iexact icontains istartswith iendswith |
i的意思是忽略大小写 | |
| in | filter(pk__in=[1,2,3,100]) | 是否在指定范围数据中 |
| gt、gte lt、lte |
filter(id__gt=3) filter(pk__lte=6) filter(pub_date__gt=date(2000,1,1)) |
|
| year、month、day week_day、hour minute、second |
filter(pub_date__year=2000) | 对日期类型属性处理 |
4.4.3 Q对象
虽然Django提供传入条件的方式,但是不方便,它还提供了Q对象来解决。Q对象是django.db.models.Q,可以使用&(and)、|(or)操作符来组成逻辑表达式。 ~ 表示not。
from django.db.models import Q
User.objects.filter(Q(pk__lt=6)) # 不如直接写User.objects.filter(pk<6)
User.objects.filter(pk__gt=6).filter(pk_lt=10) # 与
User.objects.filter(Q(pk_gt=6) & Q(pk_lt=10)) # 与
User.objects.filter(Q(pk=6) | Q(pk=10)) # 或
User.objects.filter(~Q(pk__lt=6)) # 非
可使用&|和Q对象来构造复杂的逻辑表达式
- 过滤器函数可以使用一个或多个Q对象
- 如果混用关键字参数和Q对象,那么Q对象必须位于关键字参数的前面。所有参数都将and在一起
5 表与表之间的关系
我们常说的表与表之间的关系有:一对一、一对多、多对多,下面分别说明
5.1 一对多
表示当前表的某个字段的值,来自于其他表,比如人员表和部门表,在人员表中利用一对多外键关系标明该员工属于哪个部门。
user_type = models.ForeignKey('表名',to_field='字段') # 默认会自动关联对方表的ID字段(主键),手动指定的话必须是唯一列才行。
注意:
- 默认情况下,外键字段在数据库中存储的名称为:字段名_id (上面的例子的话,在数据库中的字段名:user_type_id)
- 外键字段(user_type_id)存放的是所关连表的id信息
- 同时还存在一个字段名(上面的例子就是user_type)对象,这个对象指代的就是所关联的表中的数据对象
- 我们可以通过user_type,来跨表获取其关联的信息的某写字段的值(通过.字段名,即可访问)
5.1.1 正向查询
什么叫正向查询?还是拿人员表和部门表举例,外键关系存在人员表中,那么我们通过人员表利用表中的外键字段就可以查询到该人员的部门信息,我一般称之为正向查询。
一对多跨表查询例子:
# -------------------- models.py --------------------
from django.db import models
class Business(models.Model):
class Meta:
db_table='business'
caption = models.CharField(max_length=32)
code = models.CharField(max_length=16,default='SA')
class Host(models.Model):
class Meta:
db_table='host'
nid = models.AutoField(primary_key=True)
hostname = models.CharField(max_length=16)
ip = models.GenericIPAddressField(protocol='ipv4',db_index=True)
port = models.IntegerField()
b = models.ForeignKey(to='Business',to_field='id') # 外键关联Business表
# -------------------- views.py --------------------
def host(request):
v1 = models.Host.objects.all()
return render(request,'host.html',{'v1':v1})
# -------------------- host.html --------------------
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<p>主机信息</p>
{% for row in v1 %}
<p>{{ row.nid }} - {{ row.hostname }} - {{ row.ip }} - {{ row.port }} - {{ row.b_id }} - {{ row.b.caption }} - {{ row.b.code }}</p> # 通过b对象,进行跨表查询主机业务线相关信息
{% endfor %}
</div>
</body>
</html>
这里通过row.b_id 和通过b对象来获取 row.b.id 结果是相同的,区别在于使用b对象,会多一次sql查询
PS:当多个表进行及联跨表,那么都可以通过表的外键字段使用点来进行跨表访问(或者使用双下划线)
双下划线和点跨表的不同之处在于:
- 双下划线一般用于条件查询(values,values_list)
- 点则一般用于在结果中利用外键对象进行跨表查询
# -------------- 利用点进行跨表查询 --------------
# 如果我只想获取主机地址和所属业务线使用点跨表的话
v2 = models.Host.objects.all()
return render(request,'host.html',{'v2':v2})
# 前端代码
{% for row in v2 %}
<p>{{ row.hostname }} - {{ row.b.caption }}</p>
{% endfor %}
# 我们只用了两个字段,却取出了相关的所有数据。
# 是否可以在查询阶段只取出所需字段即可?使用双下划线__即可
# -------------- 利用双下划线跨表查询 --------------
v3 = models.Host.object.all().values('hostname','b__caption')
# 我们可以看到在作为value的条件语句,通过b对象配合双下划线就进行了一次跨表查询
# 前端代码
<div>
{% for row in v2 %}
<p>{{ row.hostname }} - {{ row.b__caption }}</p> # 只需要向字典一样即可。
{% endfor %}
</div>
在django内部,它之所以能识别__,是因为,它在处理values条件时,会使用__作为分隔符,分隔后再进行相关处理
5.1.2 反向查询
很多时候我们会有另一种需求,查询一个部门下的所有员工,这时部门表中没有外间字段关联人员表啊,该怎么查?其实是可以的,我把这个查询方式称之为反向查询。
在建立外键关系时,不仅会在外键所在表中产生外键所关联表的对象,在所关联表中也会产生一个关联表的对象(可能有点绕,没找到更好的表达方式),这个对象一般有两种体现方式:
- 关联我的表(小写):
一般用在values,values_list当作条件做字段过滤 - 关联我的表名(小写)_set:
一般当作对象,当作字段处理
def index(request):
users = models.User.objects.all()
departments = models.Department.objects.values('user__name') # 跨到管理本表的user表中,查找对应的user的名称,利用的是join 格式
for dep in departments:
print(dep)
# {'user__name': 'daxin'}
# {'user__name': 'dachenzi'}
# {'user__name': 'hello'}
# {'user__name': 'xiaoming'}
# {'user__name': 'xiaochen'}
return HttpResponse('ok')
对应的sql语句为:
- SELECT"user"."name"FROM"department"LEFTOUTERJOIN"user"ON("department"."dept_id" = "user"."dept_id");
def index(request):
departments = models.Department.objects.filter(pk=1)
for dep in departments:
for username in dep.user_set.values('name'): # user_set指代的是关联的user表对象
print(username)
# {'name': 'daxin'}
# {'name': 'dachenzi'}
# {'name': 'hello'}
return HttpResponse('ok')
对应的sql语句为:
- SELECT "department"."dept_id", "department"."dept_name" FROM "department" WHERE "department"."dept_id" = 1;
- SELECT "user"."name" FROM "user" WHERE "user"."dept_id" = 1;
5.2 多对多
前面说了一对多的情况,这里还有一种情况叫多对对,比如一个主机可以关联多个业务线,不同的业务线可以关联多个主机,所以这里,业务线和主机的关系为多对多,在多对多的情况下,有需要一张额外的表来表示对应关系,这里有两种情况来创建这张关系表。
5.2.1 手动创建
手动创建,故名思议,我们需要手动的创建一张关系表,然后创建两个ForeignKey字段(一对多),关联两张表即可。
# 业务线表
class Business(models.Model):
caption = models.CharField(max_length=32)
code = models.CharField(max_length=16,default='SA')
# 主机表
class Host(models.Model):
nid = models.AutoField(primary_key=True)
hostname = models.CharField(max_length=16)
ip = models.GenericIPAddressField(protocol='ipv4',db_index=True)
port = models.IntegerField()
# 多对多关系表
class Application(models.Model):
h = models.ForeignKey(to='Host',to_field='nid') # 关联主机id,字段名为h_id,同时存在对象h,存放对应的Host信息
b = models.ForeignKey(to='Business',to_field='id') # 关联业务线id,字段名为b_id,同时存在对象b,存放对应的Business信息
PS:一共手动创建三张表,可以利用创建的Application关系表来直接操作多对多关系。
5.2.2 自动创建
在Django中,还存在一种方式为自动创建, 通过django提供的ManyToMany关键字创建。
# 业务线表
class Business(models.Model):
caption = models.CharField(max_length=32)
code = models.CharField(max_length=16,default='SA')
# 主机表
class Host(models.Model):
nid = models.AutoField(primary_key=True)
hostname = models.CharField(max_length=16)
ip = models.GenericIPAddressField(protocol='ipv4',db_index=True)
port = models.IntegerField()
business = models.ManyToManyField('Business') # 通过manytomany字段创建多对多关系
注意:
- 虽然我们创建了两张表,但是由于我们使用了manytomany关键字创建多对对关系,django还会为我们创建一张表名为当前表名加当前字段名的表(上面的例子就是:app01_host_business),当作关系表,不会产生business字段。
- 由于我们没有关系表这个class类对象,所以我们不能直接操作关系表,需要通过Host对象间接通过business字段来操作关系表。
- 虽然利用manytomany关键字,能帮我们创建关系表,节省了很多代码,但是自动生成的表中只会生成两个字段(两张表的主键id字段),不能定制其他字段,相反手动生成的表可以定制,平时可以根据情况二者混用。
5.2.3 操作关系表
手动创建关系表的情况下,由于含有第三张表对应的class,那么我们可以直接使用这个class对关系表进行操作,但是多对多的情况下没有关系表的class,所以我们需要通过其他办法来操作。
| 方法 | 含义 |
|---|---|
| add() | 添加关系 |
| remove() | 删除关系 |
| clear() | 清除所有关系 |
| all() | 获取对应的所有关系对象(在查询时这里可以使用all,filter,get等,就像查找过滤其他数据一样) |
models.Host.objects.filter(nid=1).first().business.add(1,2) # 添加两条多对多关系 1(host) --> 1(business),1(host) --> 2(business)
models.Host.objects.filter(nid=1).first().business.remove(2) # 删除一条多对多关系 1 -x-> 2
models.Host.objects.filter(nid=1).first().business.clear() # 清除nid为1的所有的多对多关系
下面是一个小栗子:
# models.py
class Bussiness(models.Model):
class Meta:
db_table = 'bussiness'
bus_id = models.AutoField(primary_key=True)
bus_name = models.CharField(max_length=64, null=False)
class Host(models.Model):
class Meta:
db_table = 'host'
host_id = models.AutoField(primary_key=True)
host_name = models.CharField(max_length=64, null=False)
host_ip = models.GenericIPAddressField(protocol='both')
bus = models.ManyToManyField(Bussiness)
# views.py
def index(request):
hosts = models.Host.objects.all()
for host in hosts:
for bus in host.bus.all(): # 通过bus对象获取它关联的所有bussiness实例记录
print(host.host_name, host.host_ip, bus.bus_name)
return HttpResponse('ok')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号