【redis 布隆过滤器】
简述:
这个过滤器可以检索一个元素是否在一个集合中(优点是查询效率很高,缺点是有一定概率出现误判),可以理解为 利用高效的数据结构和算法快速判断出你这个 Key 是否在数据库中存在,不存在就 return ,存在就去查询 DB数据库 刷新 KV 再 return。
可以通过代码来看下效果:
先导入依赖:
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>20.0</version> </dependency>
测试demo:
private static int size = 1000000;//预计要插入多少数据,即布隆数组长度 private static double fpp = 0.01;//期望的误判率 // private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp); private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size); public static void main(String[] args) { //插入数据 for (int i = 0; i < 1000000; i++) { bloomFilter.put(i); } double count = 0; for (int i = 1000000; i < 2000000; i++) { if (bloomFilter.mightContain(i)) { count++; // System.out.println(i + "误判了"); } } System.out.println("100w条数据,其中总共的误判数:" + count + "误判率 :"+ (count/1000000L) * 100 + "%"); // 如果增加过滤器哈希数组长度为100 0000,则默认误判率会降低到 0.003% }
输出结果:
100w条数据,其中总共的误判数:30155.0误判率 :3.0155000000000003%
可以看到误判数为3%,源码里有create方法重载,可以看到 有一种方法(我代码里注释掉的)可以手动传入期望误判率,手动设置期望误差值的话输出如下:
100w条数据,其中总共的误判数:10314.0误判率 :1.0314%

如上图所示:其默认误判率在0.03左右。
为什么会有误判率?
从布隆过滤器的原理上来讲,其本身并不会存储真正的数据,只是在哈希数组中分配标记,例如:
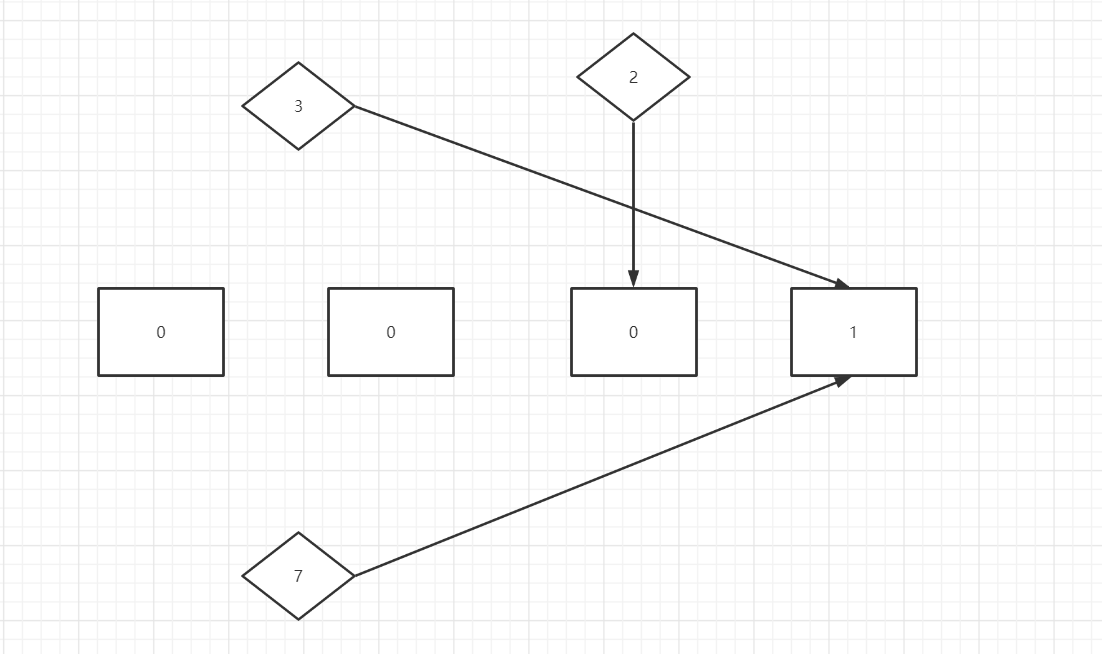
也就是说,其根据对应位置是否为1,判断数据是否存在,于是就会有个问题,当3和7都占据这个长度为4的数组下标【3】处,只会被记录一次,所以这个数据实际上可能并不存在(对应缓存中其实没有),也就是说,如果布隆返回不存在那就是不存在,而返回存在时可能存在误判。这个误判通过增加布隆过滤器哈希数组长度可以得到减轻,因为01重复存入的概率会变小。
总结:
布隆过滤器的查询速度很快,而且保密性强,因为只是存储二进制01(不存储原始数据,可以节省存储空间),而它的误判概率并不大,对于零星的漏网之鱼落在缓存上应该是可以接受的。
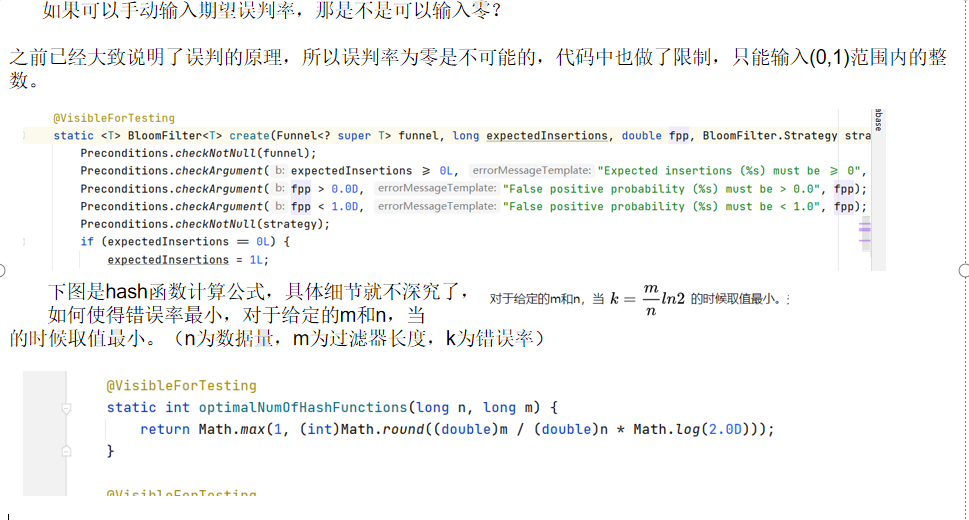
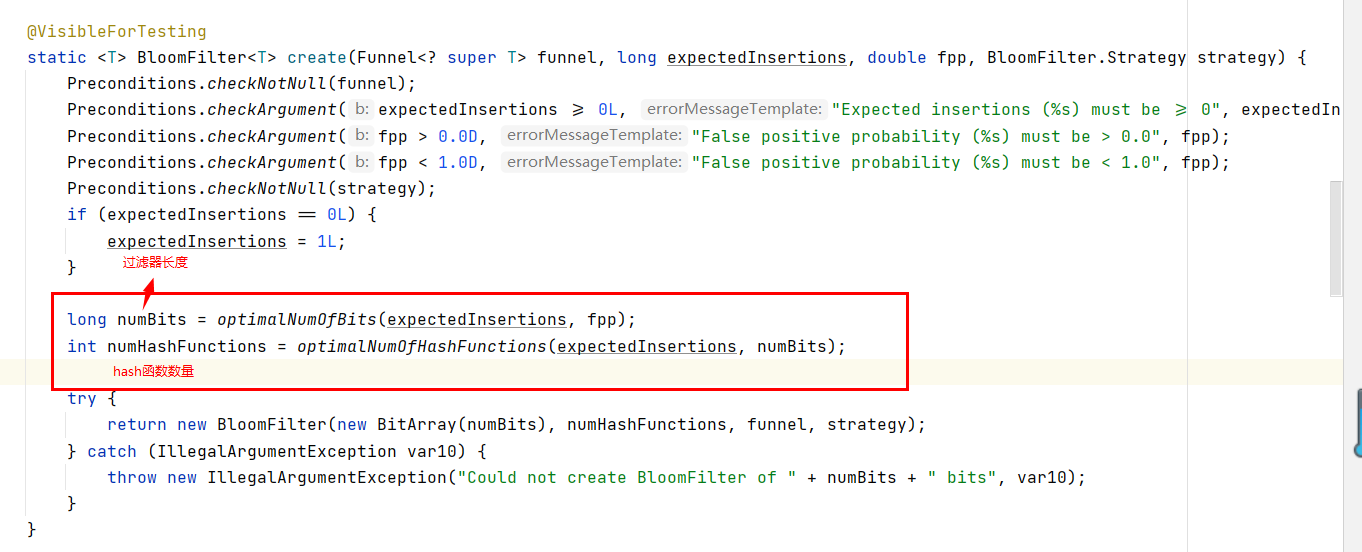
至于为什么可以设置期望误判率,是因为根据目前已知的公式,误判概率和这些因素有关: 已添加元素的数量(x),布隆过滤器长度(位数组大小 m),哈希函数数量(n)。
- 估算最佳布隆过滤器长度(位数组大小:m)。
- 估算最佳哈希函数数量(如上图例子一样,可以通过多个hash函数提高准确率 :n)。
所以我们可以输入数据量x的同时,输入过滤器长度m,这样调用内嵌好的公式就可以使用了;如果再加上期望误判率,那么期望误判率越低,hash函数的数量 n就要越多,运行时间也就越长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号