Python和RPA网页自动化-让非标准下拉框选择指定文本的方法
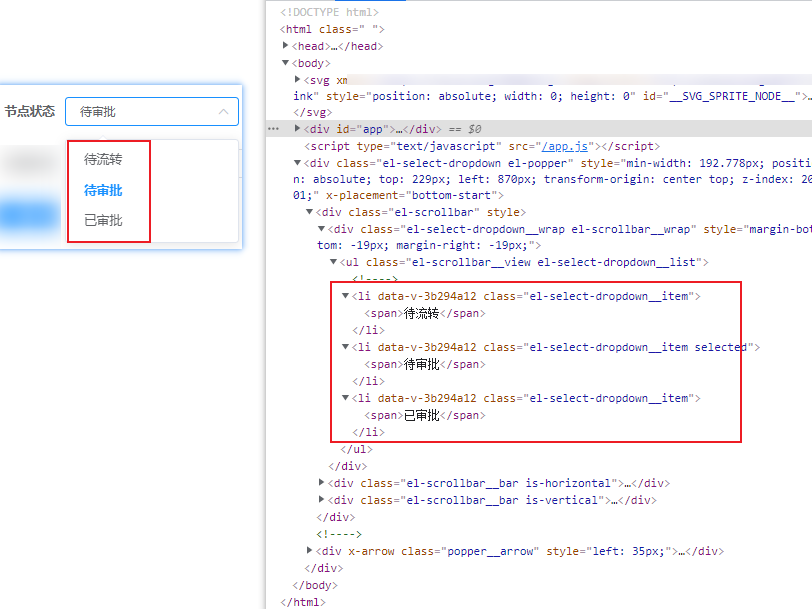
以下方“节点审批”下拉框为例
- 该下拉框没有<select>标签,而是<div><ul><li>标签。分别使用Python和RPA网页自动化让下拉框选择=“已审批”
1、Python代码如下
步骤:先点击下拉框获取所有下拉值,然后遍历每个下拉值找到指定文本内容再进行点击
from selenium import webdriver from time import sleep url="http://xxx.com" def dropDownBox(): browser = webdriver.Chrome() browser.get(url) #窗口最大化 browser.maximize_window() sleep(1)
#非标准下拉框。点击下拉框 browser.find_element_by_xpath('//*[@id="app"]/div/div[2]/section/div/div/div/form/div[6]/div/div/div/input').click() sleep(2) #获取所有选项值再进行for循环遍历内容,符合指定文本则点击选项 #看网页源代码层级关系,'/html/body/div[2]/div[1]/div[1]/ul/li[3]'是已审批状态的绝对路径,它的上一层'/html/body/div[2]/div[1]/div[1]/ul'即为所有选项 orderStatusStr=browser.find_element_by_xpath('/html/body/div[2]/div[1]/div[1]/ul').text print(type(orderStatusStr)) #将str类型转换为list类型,按换行符进行切片 orderStatusList = orderStatusStr.split("\n") print(type(orderStatusList),orderStatusList) approvedStatus = "已审批" for i in range(len(orderStatusList)) : statusXpath='/html/body/div[2]/div[1]/div[1]/ul/li['+str(i+1)+']' print(statusXpath) orderStatus = browser.find_element_by_xpath(statusXpath).text if orderStatus==approvedStatus: print(orderStatus+" 状态符合指定文本内容,点击此选项") browser.find_element_by_xpath(statusXpath).click() #如果下拉选项有独立的title,也可直接使用xpath定位而不用遍历所有选项 #browser.find_element_by_xpath('//*[@title="已审批"]').click() else: print(orderStatus + " 状态不符合指定文本内容") sleep(2) if __name__=="__main__": dropDownBox()
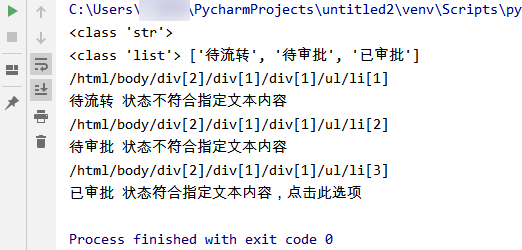
运行结果
2、RPA指令如下
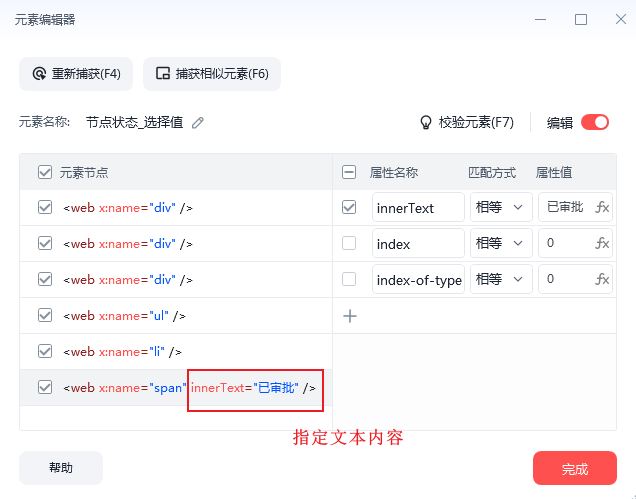
步骤:先点击下拉框,再根据文本内容点击下拉选项

其中“节点状态_选择值”元素指定了属性innerText=已审批

 浙公网安备 33010602011771号
浙公网安备 33010602011771号