

Sklearn到底是什么?
1.概念
Sklearn (全称 Scikit-Learn) 是机器学习中的常用python第三方模块。
里面对一些常用的机器学习方法进行了封装,在进行机器学习任务时,并不需要每个人都实现所有的算法,只需要简单的调用sklearn里的模块就可以实现大多数机器学习任务。,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。
2.方法
常用模块
sklearn中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)、 ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:k-Means、 spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
2.1有监督学习的分类任务(Classification)
分类算法:
from sklearn import SomeClassifier from sklearn.linear_model import SomeClassifier from sklearn.ensemble import SomeClassifier
2.2有监督学习的回归任务(Regression)
回归算法:
from sklearn import SomeRegressor from sklearn.linear_model import SomeRegressor from sklearn.ensemble import SomeRegressor
2.3无监督学习聚类任务(Clustering)
聚类算法:
from sklearn.cluster import SomeModel
2.4无监督学习的降维任务(Dimensionality Reduction)
from sklearn.decomposition import SomeModel
2.5模型选择任务(Model Selection)
from sklearn.model_selection import SomeModel
2.6数据的预处理任务(Preprocessing)
from sklearn.preprocessing import SomeModel
2.7引入某个数据集
from sklearn.datasets import SomeData
3.部分代码详细分析
3.1自带的数据集
例如导入乳腺癌数据集:
#导入乳腺癌数据集 from sklearn.datasets import load_breast_cancer
数据是以「字典」格式存储的,详细查看一下里面的键:
breast = load_breast_cancer() print(breast.keys())
结果:

键的名词解释:
-
data:特征值 (数组)
-
target:标签值 (数组)
-
target_names:标签 (列表)
-
DESCR:数据集描述
-
feature_names:特征 (列表)
-
filename:iris.csv 文件路径
详细查看一下数据集:
#定义两个分别为数据集的样例个数、特征个数 n_samples,n_features = breast.data.shape #输出数据集的样例个数和特征个数,类似数据集的规模 print(n_samples,n_features) #输出数据集的特征名称 print(breast.feature_names) #输出数据集的前5个特征示例 print(breast.data[0:5])
可以看到输出分别为——样例个数以及特征个数:
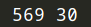
数据集中30个特征的名称为:

前五个示例为(每一个示例中都有30个数据,分别对应30个特征):
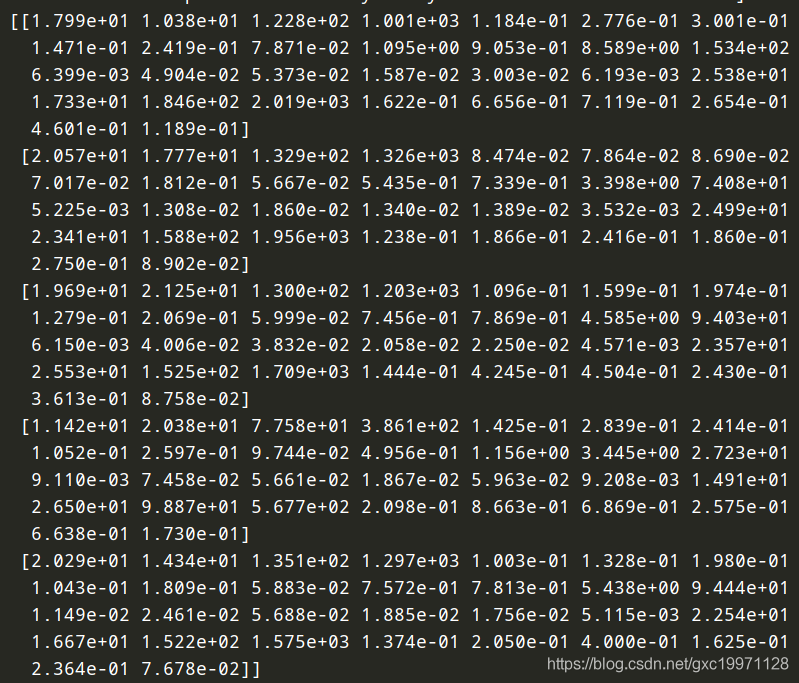
输出数据集的标签大小:
#输出数据集的标签数量(也就是最后的那个是乳腺癌良性还是恶性): print(breast.target.shape)
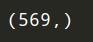
输出数据集标签名称看看:
#输出数据集标签名称: print(breast.target_names)

输出全部标签示例:
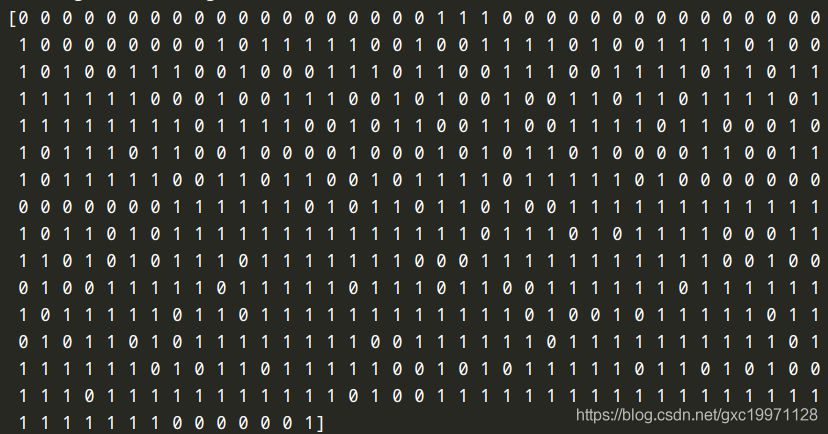
即数据集中有569个标签,2个类别(malignant恶性、benign良性),分别用0和1来表示。
使用pandas下的工具DataFrame来把数据集创建成表格来读取数据集中的详细数据
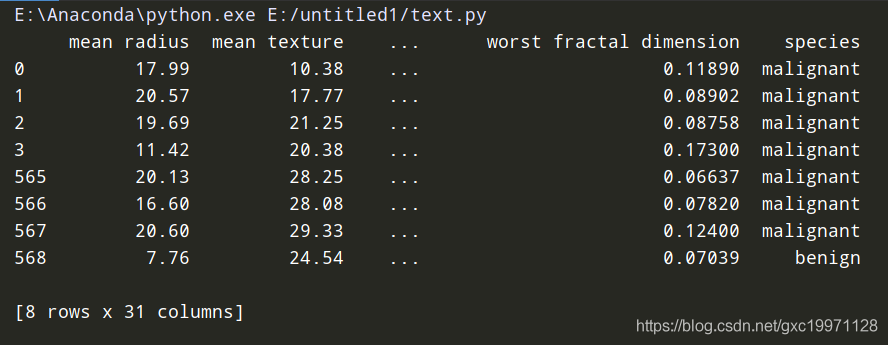
Seaborn 的 pairplot (看每个特征之间的关系)来用图来展示一下数据集的内容。
import seaborn as sns from matplotlib import pyplot as plt sns.pairplot(breast_data,hue='species',palette='husl'); plt.show()
3.安装SKlearn
如果你已经安装了numpy和scipy,那么安装scikit-learn的最简单方法就是使用 pip或者canda
pip install -U scikit-learn
conda install scikit-learn
升级scikit-learn:conda update scikit-learn
卸载scikit-learn:conda remove scikit-learn
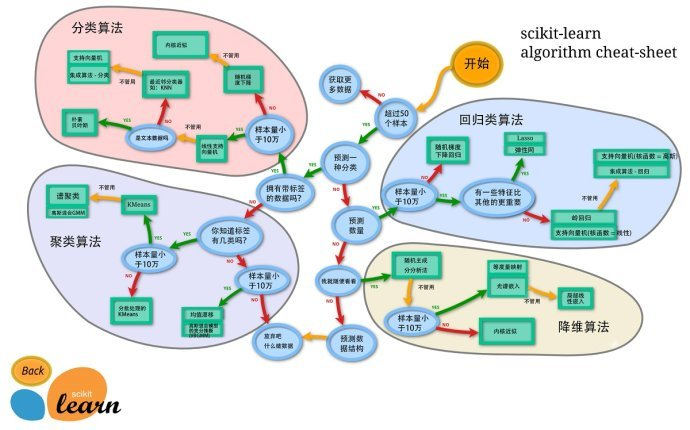
4.算法选择
相关阅读
Data Analyst:SKlearn中分类决策树的重要参数详解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号