
python课堂整理19----迭代器和生成器
一、概念
• 迭代器协议:
对象必须提供一个next方法,执行该方法要么返回迭代中的下一项,要么引起一个stopIteration异常,以终止迭代(只能往后走,不能往前退)
• 协议是一种约定,python中的 for sum min max map reduce 等,使用迭代器对象访问对象
• 迭代器就是可迭代对象
• 可迭代对象:实现了迭代器协议的对象(如何实现:对象内部定义一个__iter__(方法))
next()函数,next -------->iter_l.__next__(), 本质一样
二、for 循环访问方式
l = [1, 2, 3]
for i in l:
print(i)
for 循环做了两件事:①先调用 diedai_l = l.__iter__()方法,将列表变为可迭代对象,然后可迭代对象调用 __next__()方法或next()函数
②捕捉stopIteration异常
l = [1, 2, 3]
iter_l = l.__iter__()
print(iter_l.__next__())
print(iter_l.__next__())
print(iter_l.__next__())
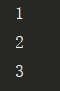
或者:
l = [1, 2, 3] iter_l = l.__iter__() print(next(iter_l)) print(next(iter_l)) print(next(iter_l))
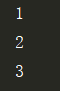
用while去模拟for 循环做的事
l = [1, 2, 3]
iter_l = l.__iter__()
while True:
try:
print(iter_l.__next__())
except StopIteration:
print('迭代完了嘻嘻')
break

为何要有for 循环:
再看一个例子:
l = [1, 2, 3]
index = 0
while index < len(l):
print(l[index])
index +=1
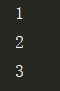
没错,序列类型字符串,列表,元组都有下标,你用上述的访问方式很好,但是,非序列类型像字典,集合,文件等就不适用了。
所以,for 循环就是基于迭代器协议提供了一个统一的可遍历所有迭代对象的方法,即在遍历前,先调用对象的__iter__方法将其转换成一个迭代器,
然后使用迭代器协议去实现循环访问
###############################
§生成器
一、什么是生成器?
可以理解为一种数据类型,这种数据类型自动实现了迭代器协议(其他的数据类型需要调用自己内置的__iter__方法)
所以生成器是可迭代对象
二、生成器分类在python中的表现形式:
①生成器函数:常规函数定义,但是使用yield语句而不是return语句返回结果。
yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
②生成器表达式:类似于列表推导,但是生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
三、实例
生成器函数:
def test():
yield 1
yield 2
yield 3
g = test()
print(g)
print(g.__next__())
print(g.__next__())
print(g.__next__())
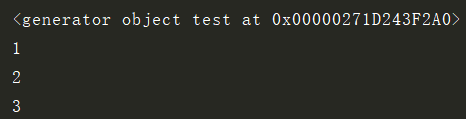
使用生成器的优点:①占用空间小
②效率高
def pro_baozi():
for i in range(100):
print('正在生产包子')
yield '一屉%s' %i
print('正在卖包子')
pro_g = pro_baozi()
baozi = pro_g.__next__()
print(baozi) #加代码,得到一个值就可以立刻开始处理,而不用等后面的数值
baozi = pro_g.__next__()
print(baozi)

三元表达式:
name = 'alex' res = 'sb' if name =='alex' else '帅哥' print(res)

列表解析:
egg_list = []
for i in range(10):
egg_list.append('鸡蛋%s'%i)
print(egg_list)

就相当于:
l = ['鸡蛋%s'% i for i in range(10)] print(l)

使用生成器表达式:
就是把上述列表解释式的中括号换成小括号,就形成了一个生成器
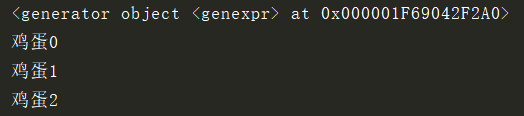
l = ('鸡蛋%s'% i for i in range(10))
print(l)
print(l.__next__())
print(l.__next__())
print(l.__next__())
这样求和,虽然也慢,但机器不会卡死
print(sum(i for i in range(1000000000)))
总结:
优点一:生成器的好处是延迟运算,一次返回一个结果,也就是说,他不会一次生成所有的结果,这对于大数据量的处理,将会非常有用。
优点二:生成器还能有效提高代码的可读性
实例:人口普查统计(算总人口)
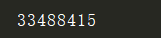
{'name': '河南','population': 10000000}
{'name': '山东','population': 9000000}
{'name': '北京','population': 10000}
{'name': '广东','population': 1023000}
{'name': '重庆','population': 1012000}
{'name': '河北','population': 12443415}
def get_population():
with open('人口普查', 'r', encoding = 'utf-8') as f:
for i in f:
yield i
g = get_population()
print(sum(eval(i)['population'] for i in g))
自己改进:
{'name': '河南','population': 20}
{'name': '山东','population': 20}
{'name': '北京','population': 20}
{'name': '广东','population': 20}
{'name': '重庆','population': 20}
{'name': '河北','population': 20}
res = []
def get_population():
with open('人口普查', 'r', encoding = 'utf-8') as f:
for i in f:
yield i
g = get_population()
henan = g.__next__()
res.append(eval(henan)['population'])
shandong = g.__next__()
res.append(eval(shandong)['population'])
beijing = g.__next__()
res.append(eval(beijing)['population'])
chongqing = g.__next__()
res.append(eval(chongqing)['population'])
guangdong = g.__next__()
res.append(eval(guangdong)['population'])
hebei = g.__next__()
res.append(eval(hebei)['population'])
sum1 = sum(res)
print('总人口%s'%sum1)
print('河南人口占总人口的%.2f%%'%((eval(henan)['population']/sum1)*100))
print('北京人口占总人口的%.2f%%'%((eval(beijing)['population']/sum1)*100))

一个奋斗中的产品小白

 浙公网安备 33010602011771号
浙公网安备 33010602011771号