
[Paddle学习笔记][03][数字识别]
说明:
深度学习的入门教程,一般都是 MNIST 数据库上的手写识别问题。原因是手写识别属于典型的图像分类问题,比较简单,同时MNIST数据集也很完备。MNIST数据集作为一个简单的计算机视觉数据集,包含一系列如图1所示的手写数字图片和对应的标签。图片是28x28的像素矩阵,标签则对应着0~9的10个数字。每张图片都经过了大小归一化和居中处理。
实验代码:

1 import paddle 2 import paddle.fluid as fluid 3 from paddle.utils.plot import Ploter 4 5 import numpy 6 import os 7 from PIL import Image 8 import matplotlib.pyplot as plt 9 10 %matplotlib inline 11 12 # 全局变量 13 epochs = 5 # 训练迭代周期 14 save_dirname = "./model/Recognize_Digits.model" # 模型保存路径 15 infer_dirname = "./data/mnist/test/4/116.png" # 预测图像路径 16 17 # 测试模型 18 def test(executor, program, reader, feeder, fetch_list): 19 avg_loss_set = [] # 平均损失值集 20 acc_set = [] # 分类准确率集 21 for test_data in reader(): # 将测试数据输出的每一个数据传入网络进行训练 22 metrics = executor.run( 23 program=program, 24 feed=feeder.feed(test_data), 25 fetch_list=fetch_list) 26 avg_loss_set.append(float(metrics[0])) 27 acc_set.append(float(metrics[1])) 28 avg_loss_val_mean = numpy.array(avg_loss_set).mean() # 计算平均损失值 29 acc_val_mean = numpy.array(acc_set).mean() # 计算平均准确率 30 return avg_loss_val_mean, acc_val_mean # 返回平均损失值和平均准确率 31 32 # 训练模型 33 def train(): 34 # 读取数据 35 batch_size = 64 # 每批64张图像 36 train_reader = paddle.batch( 37 paddle.reader.shuffle(paddle.dataset.mnist.train(), buf_size=500), # 每次读取500条数据,并随机打乱 38 batch_size=batch_size) 39 test_reader = paddle.batch( 40 paddle.dataset.mnist.test(), 41 batch_size=batch_size) 42 43 # 配置训练网络 44 img = fluid.data(name='img', shape=[None, 1, 28, 28], dtype='float32') # 数据层: 输出n*1*28*28 45 label = fluid.data(name='label', shape=[None, 1], dtype='int64') # 数据层: 输出n*1 46 47 # softmax_regression 48 # prediction = fluid.layers.fc(input=img, size=10, act='softmax') # 全连接层: 输出n*10 49 50 # multilayer_perceptron 51 # hidden = fluid.layers.fc(input=img, size=200, act='relu') # 全连接层: 输出n*200 52 # hidden = fluid.layers.fc(input=hidden, size=200, act='relu') # 全连接层: 输出n*200 53 # prediction = fluid.layers.fc(input=hidden, size=10, act='softmax') # 全连接层: 输出n*10 54 55 # convolutional_neural_network 56 # 卷积层: 输出n*20*24*24, c=k, w/h=(w/h-f+2*p)/s+1 57 conv_1 = fluid.layers.conv2d(input=img , num_filters=20, filter_size=5, act='relu') 58 # 池化层: 输出n*20*12*12, c=c, w/h=(w/h-f+2*p)/s+1 59 pool_1 = fluid.layers.pool2d(input=conv_1, pool_size=2, pool_stride=2) 60 # 归一化层: 输出n*20*12*12 61 norm_1 = fluid.layers.batch_norm(pool_1) 62 # 卷积层: 输出n*50*8*8 63 conv_2 = fluid.layers.conv2d(input=norm_1, num_filters=50, filter_size=5, act='relu') 64 # 池化层: 输出n*50*4*4 65 pool_2 = fluid.layers.pool2d(input=conv_2, pool_size=2, pool_stride=2) 66 # 全连接层: 输出n*10 67 prediction = fluid.layers.fc(input=pool_2, size=10, act='softmax') 68 69 loss = fluid.layers.cross_entropy(input=prediction, label=label) # 损失值层: 输出n*10, 交叉熵损失 70 avg_loss = fluid.layers.mean(loss) # 损失值层: 输出n*1, 平均损失值 71 acc = fluid.layers.accuracy(input=prediction, label=label) # 准确率层: 输出n*10,分类准确率 72 73 # 获取网络 74 startup_program = fluid.default_startup_program() # 获取默认启动程序 75 main_program = fluid.default_main_program() # 获取默认主程序 76 test_program = main_program.clone(for_test=True) # 克隆测试主程序 77 78 # 配置优化方法 79 optimizer = fluid.optimizer.Adam(learning_rate=0.001) #Adam算法 80 optimizer.minimize(avg_loss) # 最小化平均损失 81 82 # 运行启动程序 83 place = fluid.CUDAPlace(0) # 获取GPU设备 84 exe = fluid.Executor(place) # 获取训练执行器 85 exe.run(startup_program) # 运行启动程序 86 87 # 开始训练模型 88 step = 0 # 周期计数 89 lists = [] # 测试结果 90 feeder = fluid.DataFeeder(feed_list=[img, label], place=place) # 获取数据读取器 91 exe_test = fluid.Executor(place) # 获取测试执行器 92 93 train_prompt = "Train loss" 94 test_prompt = "Test loss" 95 loss_ploter = Ploter(train_prompt, test_prompt) # 绘制训练损失值图 96 97 for epoch_id in range(epochs): 98 # 训练模型 99 for train_data in train_reader(): 100 train_metrics = exe.run( 101 program=main_program, 102 feed=feeder.feed(train_data), 103 fetch_list=[avg_loss, acc]) 104 105 if step % 100 == 0: # 每100个批次记录并输出一下训练损失值 106 loss_ploter.append(train_prompt, step, train_metrics[0]) 107 loss_ploter.plot() 108 print("Pass %4d, Epoch %d, Loss %f" % (step, epoch_id, train_metrics[0])) 109 110 step += 1 # 增加计数 111 112 # 测试模型 113 test_metrics = test( 114 executor=exe_test, 115 program=test_program, 116 reader=test_reader, 117 feeder=feeder, 118 fetch_list=[avg_loss, acc]) 119 120 loss_ploter.append(test_prompt, step, test_metrics[0]) 121 loss_ploter.plot() 122 print("Test with Epoch %d, avg_loss: %f, acc: %f" % (epoch_id, test_metrics[0], test_metrics[1])) 123 lists.append((epoch_id, test_metrics[0], test_metrics[1])) # 保存测试结果 124 125 # 保存模型 126 if save_dirname is not None: 127 fluid.io.save_inference_model(save_dirname, ['img'], [prediction], exe) 128 129 # 输出最好结果 130 best = sorted(lists, key=lambda list: float(list[1]))[0] 131 print("Best pass is %d, testing avg_loss is %f" % (best[0], best[1])) 132 print("The classification accuracy is %.2f%%" % (float(best[2]) * 100)) 133 134 # 加载图像 135 def load_image(file): 136 im = Image.open(file).convert('L') # 读取图像文件,并转成灰度图 137 im = im.resize((28, 28), Image.ANTIALIAS) # 调整为28*28,高质量图 138 im = numpy.array(im).reshape(1, 1, 28, 28).astype(numpy.float32) # 转换为numpy类型 139 im = im / 255.0 * 2.0 - 1.0 # 对数据归一化处理(-1,1) 140 return im 141 142 # 数据推断 143 def infer(): 144 # 是否存在推断模型 145 if save_dirname is None: 146 return 147 148 # 加载图像 149 tensor_img = load_image(infer_dirname) 150 151 # 数据推断 152 place = fluid.CUDAPlace(0) # 获取GPU设备 153 infer_exe = fluid.Executor(place) # 获取推断执行器 154 inference_scope = fluid.core.Scope() # 获取推断作用域 155 156 with fluid.scope_guard(inference_scope): 157 # 加载推断模型 158 [inference_program, feed_target_names, fetch_targets 159 ] = fluid.io.load_inference_model(save_dirname, infer_exe) 160 161 # 进行数据推断 162 results = infer_exe.run( 163 program=inference_program, 164 feed={feed_target_names[0]: tensor_img}, 165 fetch_list=fetch_targets) 166 167 # 输出推断结果 168 label = numpy.argsort(results[0][0]) # 对10类概率值位置从小到大排序 169 print(results[0][0]) # 10类概率值 170 print(label) # 10类概率从大到小对应标签 171 print("Inference result is: %d" % label[-1]) # 输出概最大率值标签 172 img = Image.open(infer_dirname) # 打开推断图像 173 plt.imshow(img) # 显示推断图像 174 175 176 # 主函数 177 def main(): 178 # 训练模型 179 train() 180 181 # 数据推断 182 infer() 183 184 # 主函数 185 if __name__ == '__main__': 186 main()
实验结果:
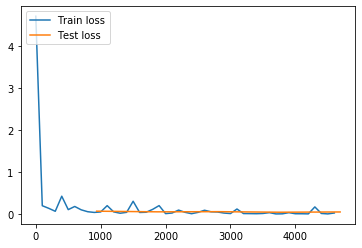
Test with Epoch 4, avg_loss: 0.047326, acc: 0.987361
Best pass is 3, testing avg_loss is 0.041124
The classification accuracy is 98.72%
[1.8291370e-14 1.3467998e-08 2.3033226e-11 1.5657427e-08 9.9999630e-01
1.2488571e-08 3.6087099e-11 1.4171575e-09 2.1537630e-06 1.5523912e-06]
[0 2 6 7 5 1 3 9 8 4]
Inference result is: 4
参考资料:
https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/train.py




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术