
[Paddle学习笔记][01][线性回归]
说明:
使用从UCI Housing Data Set获得的波士顿房价数据集进行模型的训练和预测。
实验代码:
静态图

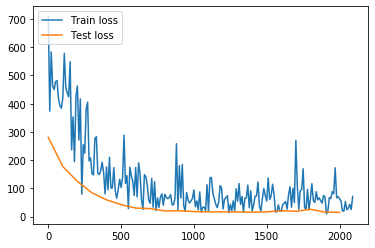
1 import paddle 2 import paddle.fluid as fluid 3 from paddle.utils.plot import Ploter 4 import math 5 import numpy 6 %matplotlib inline 7 8 # 全局变量 9 filename = "./data/housing.data" # 数据文件路径 10 num_epochs = 100 # 训练迭代周期 11 params_dirname = "./model/Linear_Regression.model" # 模型保存路径 12 13 # 计算测试损失 14 def train_test(executor, program, reader, feeder, fetch_list): 15 accumulated = 1 * [0] 16 count = 0 17 for data_test in reader(): 18 outs = executor.run( 19 program=program, 20 feed=feeder.feed(data_test), 21 fetch_list=fetch_list) 22 accumulated = [ x_c[0] + x_c[1][0] for x_c in zip(accumulated, outs) ] # 累加测试过程中的损失 23 count += 1 # 累加测试集中个的样本数量 24 return [x_d / count for x_d in accumulated] # 计算平均损失值 25 26 # 保存推断结果 27 def save_result(points1, points2): 28 import matplotlib 29 # matplotlib.use('Agg') # 显示图像 30 import matplotlib.pyplot as plt 31 32 x1 = [idx for idx in range(len(points1))] 33 y1 = points1 34 y2 = points2 35 l1 = plt.plot(x1, y1, 'r--', label='Predictions') 36 l2 = plt.plot(x1, y2, 'g--', label='GT') 37 38 plt.plot(x1, y1, 'ro-', x1, y2, 'g+-') 39 plt.title('Predictions VS GT') 40 plt.legend() 41 plt.savefig('./image/prediction_gt.png') 42 43 # 主函数 44 def main(): 45 # 读取数据 46 feature_names = [ 47 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 48 'PTRATIO', 'B', 'LSTAT', 'convert' 49 ] 50 feature_num = len(feature_names) 51 data = numpy.fromfile(filename, sep=' ') # 从文件中读取原始数据 52 data = data.reshape(data.shape[0] // feature_num, feature_num) 53 54 # 归一化处理 55 maximums, minimums, avgs = data.max(axis=0), data.min(axis=0), data.sum(axis=0) / data.shape[0] # 获取每列的最大,最小和平均值 56 for i in range(feature_num - 1): # 对506条数据进行归一化处理(-0.5,0.5) 57 data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] -minimums[i]) 58 59 ratio = 0.8 # 训练集和测试集的划分比例 60 offset = int(data.shape[0]*ratio) 61 train_data = data[:offset] 62 test_data = data[offset:] 63 64 def reader_creator(data): 65 def reader(): 66 for d in data: 67 yield d[:-1], d[-1:] 68 return reader 69 70 batch_size = 20 # 每批20条数据 71 train_reader = fluid.io.batch( 72 fluid.io.shuffle(reader_creator(train_data), buf_size=500), 73 batch_size=batch_size) 74 test_reader = fluid.io.batch( 75 fluid.io.shuffle(reader_creator(test_data), buf_size=500), 76 batch_size=batch_size) 77 78 # 读取数据 79 # batch_size = 20 # 每批20条数据 80 # train_reader = fluid.io.batch( 81 # fluid.io.shuffle(paddle.dataset.uci_housing.train(), buf_size=500), 82 # batch_size=batch_size) 83 # test_reader = fluid.io.batch( 84 # fluid.io.shuffle(paddle.dataset.uci_housing.test(), buf_size=500), 85 # batch_size=batch_size) 86 87 # 配置训练网络 88 x = fluid.data(name='x', shape=[None, 13], dtype='float32') # 数据层1: 输出n*13 89 y = fluid.data(name='y', shape=[None, 1], dtype='float32') # 数据层1: 输出n*1 90 y_predict = fluid.layers.fc(input=x, size=1, act=None) # 全连层2: 输出n*1 91 92 loss = fluid.layers.square_error_cost(input=y_predict, label=y) # 损失值层: 输出n*1, 均方误差损失 93 avg_loss = fluid.layers.mean(loss) # 损失值层: 输出1*1, 平均损失 94 95 # 获取网络 96 main_program = fluid.default_main_program() # 获取全局主程序 97 startup_program = fluid.default_startup_program() # 获取全局启动程序 98 test_program = main_program.clone(for_test=True) # 克隆测试主程序 99 100 # 配置优化方式 101 sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001) # 随机梯度下降算法 102 sgd_optimizer.minimize(avg_loss) # 最小化网络损失值 103 104 # 运行启动程序 105 place = fluid.CUDAPlace(0) # 获取运行设备 106 exe = fluid.Executor(place) # 获取训练执行器 107 exe.run(startup_program) # 运行启动程序 108 109 # 开始训练模型 110 train_prompt = "Train loss" 111 test_prompt = "Test loss" 112 step = 0 113 114 exe_test = fluid.Executor(place) # 获取测试执行器 115 feeder = fluid.DataFeeder(place=place, feed_list=[x, y]) # 获取数据读取器 116 plot_prompt = Ploter(train_prompt, test_prompt) # 配置损失值图 117 118 for pass_id in range(num_epochs): 119 # 训练一个周期 120 for data_train in train_reader(): 121 # 训练模型 122 avg_loss_value = exe.run( 123 main_program, 124 feed=feeder.feed(data_train), 125 fetch_list=[avg_loss]) 126 if step % 10 == 0: # 每10个批次记录并输出一下训练损失 127 plot_prompt.append(train_prompt, step, avg_loss_value[0]) 128 plot_prompt.plot() 129 print("%s, Step %d, Loss %f" % (train_prompt, step, avg_loss_value[0])) 130 131 # 测试模型 132 if step % 100 == 0: # 每100批次记录并输出一下测试损失 133 test_metics = train_test( 134 executor=exe_test, 135 program=test_program, 136 reader=test_reader, 137 feeder=feeder, 138 fetch_list=[avg_loss]) 139 plot_prompt.append(test_prompt, step, test_metics[0]) 140 plot_prompt.plot() 141 print("%s, Step %d, Loss %f" % (test_prompt, step, test_metics[0])) 142 143 if test_metics[0] < 10.0: # 如果准确率达到要求,停住训练 144 break 145 146 # 增加计数 147 step += 1 148 if math.isnan(float(avg_loss_value[0])): # 如果训练发散,退出程序 149 sys.exit("got NaN loss, training failed.") 150 151 # 保存训练模型 152 if params_dirname is not None: # 保存训练参数到给定的路径中 153 fluid.io.save_inference_model(params_dirname, ['x'], [y_predict], exe) 154 155 # 进行数据推断 156 infer_exe = fluid.Executor(place) # 配置推断执行器 157 inference_scope = fluid.core.Scope() # 配置推断作用域 158 159 with fluid.scope_guard(inference_scope): 160 # 加载推断模型 161 [inference_program, feed_target_names, fetch_targets 162 ] = fluid.io.load_inference_model(params_dirname, infer_exe) 163 164 # 读取推断数据 165 batch_size = 10 #每批10条数据 166 infer_reader = fluid.io.batch( 167 paddle.dataset.uci_housing.test(), batch_size=batch_size) 168 169 # 提取一条数据 170 infer_data = next(infer_reader()) 171 infer_feat = numpy.array([data[0] for data in infer_data]).astype('float32') 172 infer_label = numpy.array([data[1] for data in infer_data]).astype('float32') 173 174 # 进行预测 175 assert feed_target_names[0] == 'x' 176 results = infer_exe.run( 177 inference_program, 178 feed={feed_target_names[0]: numpy.array(infer_feat)}, 179 fetch_list=fetch_targets) 180 181 # 输出预测结果 182 print("Infer results: (House Price)") 183 for idx, val in enumerate(results[0]): 184 print("%d: %.2f" % (idx, val)) #输出预测结果 185 186 print("\nGround truth:") 187 for idx, val in enumerate(infer_label): 188 print("%d: %.2f" % (idx, val)) # 输出真实标签 189 190 # 保存预测结果 191 save_result(results[0], infer_label) 192 193 # 主函数 194 if __name__ == '__main__': 195 main()
动态图
1 # 相关类库 2 import paddle 3 import paddle.fluid as fluid 4 import paddle.fluid.dygraph as dygraph 5 from paddle.fluid.dygraph import Linear 6 import numpy as np 7 8 # 全局变量 9 batch_size = 10 # 每批读取数据 10 epoch_num = 10 # 训练迭代周期 11 data_path = './data/housing.data' # 数据路径 12 model_path = './model/LR_model' # 模型路径 13 gpu = fluid.CUDAPlace(0) # 计算设备 14 15 # 数据处理 16 def load_data(): 17 # 读取数据文件 18 data = np.fromfile(data_path, sep=' ') 19 20 # 变化数据形状 21 feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \ 22 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ] 23 feature_num = len(feature_names) 24 25 data = data.reshape([data.shape[0] // feature_num, feature_num]) 26 27 # 计算数据每列的最大值,最小值和平均值 28 maxs, mins, avgs = data.max(axis=0), data.min(axis=0), data.sum(axis=0) / data.shape[0] 29 30 global max_values, min_values, avg_values 31 max_values = maxs 32 min_values = mins 33 avg_values = avgs 34 35 # 进行数据归一化处理 36 for i in range(feature_num): 37 data[:, i] = (data[:, i] - avgs[i]) / (maxs[i] - mins[i]) 38 39 # 划分训练集和测试集 40 ratio = 0.8 41 offset = int(data.shape[0] * ratio) 42 train_data = data[:offset] 43 test_data = data[offset:] 44 45 return train_data, test_data 46 47 def load_one_example(): 48 # 读取数据 49 file = open(data_path, 'r') 50 data = file.readlines() 51 52 temp = data[-10] # 读取倒数第十行数据 53 temp = temp.strip().split() # 按空格分割数据 54 one_data = [float(x) for x in temp] # 构成一条数据 55 56 # 对数据归一化处理 57 for i in range(len(one_data) - 1): 58 one_data[i] = (one_data[i] - avg_values[i]) / (max_values[i] - min_values[i]) 59 60 # 改变数据形状 61 data = np.reshape( np.array(one_data[:-1]), [1,-1] ).astype(np.float32) 62 label = one_data[-1] 63 64 return data, label 65 66 # 模型设计 67 class Regressor(fluid.dygraph.Layer): 68 def __init__(self): 69 super(Regressor, self).__init__() 70 self.fc = Linear(input_dim=13, output_dim=1, act=None) 71 72 def forward(self, inputs): 73 x = self.fc(inputs) 74 return x 75 76 # 训练配置 77 with fluid.dygraph.guard(gpu): 78 # 声明模型 79 model = Regressor() 80 model.train() 81 82 # 加载数据 83 train_data, test_data = load_data() 84 85 # 优化算法 86 opt = fluid.optimizer.SGD(learning_rate=0.01, parameter_list=model.parameters()) 87 88 # 训练过程 89 with fluid.dygraph.guard(gpu): 90 for epoch_id in range(epoch_num): 91 np.random.shuffle(train_data) # 打乱训练数据 92 mini_batches = [train_data[k: k+batch_size] for k in range(0, len(train_data), batch_size)] 93 for iter_id, mini_batch in enumerate(mini_batches): 94 # 准备数据 95 x = np.array(mini_batch[:, :-1]).astype('float32') # 获取当前批次训练数据 96 y = np.array(mini_batch[:, -1:]).astype('float32') # 获取当前批次训练标签 97 98 house_features = dygraph.to_variable(x) 99 prices = dygraph.to_variable(y) 100 101 # 前向计算 102 predicts = model(house_features) 103 104 # 计算损失 105 loss = fluid.layers.square_error_cost(input=predicts, label=prices) 106 avg_loss = fluid.layers.mean(loss) 107 108 if iter_id % 20 == 0: 109 print("epoch: {}, iter: {}, loss: {}".format(epoch_id, iter_id, avg_loss.numpy())) 110 111 # 反向传播 112 avg_loss.backward() 113 opt.minimize(avg_loss) # 更新参数 114 model.clear_gradients() # 清除梯度 115 116 # 保存模型 117 with fluid.dygraph.guard(gpu): 118 fluid.save_dygraph(model.state_dict(), model_path) 119 120 # 测试模型 121 with fluid.dygraph.guard(gpu): 122 # 加载模型 123 model_dict, _ = fluid.load_dygraph(model_path) 124 model.load_dict(model_dict) 125 model.eval() 126 127 # 加载数据 128 test_data, label = load_one_example() 129 test_data = dygraph.to_variable(test_data) 130 131 # 前向计算 132 results = model(test_data) 133 134 # 显示结果 135 results = results * (max_values[-1] - min_values[-1]) + avg_values[-1] 136 print("Inference result is {}, the corresponding label is {}".format(results.numpy(), label))
实验结果:
静态图
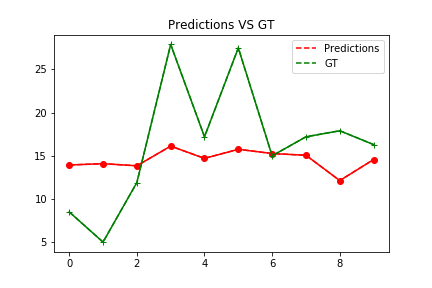
Infer results: (House Price)
0: 13.93
1: 14.09
2: 13.84
3: 16.12
4: 14.70
5: 15.75
6: 15.26
7: 15.06
8: 12.13
9: 14.56
Ground truth:
0: 8.50
1: 5.00
2: 11.90
3: 27.90
4: 17.20
5: 27.50
6: 15.00
7: 17.20
8: 17.90
9: 16.30
动态图
epoch: 0, iter: 0, loss: [0.07497297]
epoch: 0, iter: 20, loss: [0.3525038]
epoch: 0, iter: 40, loss: [0.04666689]
epoch: 1, iter: 0, loss: [0.38827196]
epoch: 1, iter: 20, loss: [0.13481286]
epoch: 1, iter: 40, loss: [0.06001815]
epoch: 2, iter: 0, loss: [0.10629095]
epoch: 2, iter: 20, loss: [0.03465366]
epoch: 2, iter: 40, loss: [0.05638801]
epoch: 3, iter: 0, loss: [0.02082269]
epoch: 3, iter: 20, loss: [0.04387076]
epoch: 3, iter: 40, loss: [0.09744592]
epoch: 4, iter: 0, loss: [0.10036241]
epoch: 4, iter: 20, loss: [0.1272443]
epoch: 4, iter: 40, loss: [0.11150322]
epoch: 5, iter: 0, loss: [0.03789455]
epoch: 5, iter: 20, loss: [0.09937193]
epoch: 5, iter: 40, loss: [0.00952427]
epoch: 6, iter: 0, loss: [0.16564386]
epoch: 6, iter: 20, loss: [0.13072248]
epoch: 6, iter: 40, loss: [0.04984929]
epoch: 7, iter: 0, loss: [0.08494945]
epoch: 7, iter: 20, loss: [0.05231998]
epoch: 7, iter: 40, loss: [0.2188043]
epoch: 8, iter: 0, loss: [0.09792896]
epoch: 8, iter: 20, loss: [0.04418667]
epoch: 8, iter: 40, loss: [0.02227205]
epoch: 9, iter: 0, loss: [0.06652302]
epoch: 9, iter: 20, loss: [0.0659591]
epoch: 9, iter: 40, loss: [0.02393019]
Inference result is [[24.21373]], the corresponding label is 19.7
参考资料:
https://www.paddlepaddle.org.cn/documentation/docs/zh/user_guides/simple_case/fit_a_line/README.cn.html




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术