网络爬虫-DeepNet爬虫
Deep Net爬虫
Deep Web是相对于Surface Web和Dark Web而言的,是互联网页面的几种形态。
DeepWeb指存储在网络数据库里,不能通过超链接访问而需要动态网页技术访问的资源集合。网络数据库包括搜索引擎数据库、在线专业数据库及站内搜索数据库,统称为可搜索数据库(Searchable Database)。
Deep Web资源容量约为Surface Web的500倍,而且包含更多更有价值的资源。
以下是三种网页形态的介绍:
Surface Web
上面的网络是所有人都知道的通用网络,所有使用互联网的用户都可以看到。网络上的网站大多被搜索引擎收录或推广。谷歌,必应,雅虎等。所有这些搜索引擎,当用户根据他的需要来搜索内容时。用户可以打开网站并收集数据。但好消息是,网络上只有 4% 的内容仅对网络上的公众开放。互联网是海量信息,但很多人不知道。他们认为只有他们看到的是互联网,没有别的。

Deep Web
深度网络是一种私有网络,只有具有访问权限的普通用户才能看到它,并且授权人员可以访问和使用这些信息。一组许多不同的网站或许多页面,但未被搜索引擎识别。它用于存储许多详细信息,例如云存储、任何个人组织数据和军事数据等。

Dark Web
Dark Web,也称为暗网,是互联网的加密部分,不会被谷歌、必应、雅虎等搜索引擎显示出来。它不是出现在搜索引擎结果上的黑网或深网页面页面,但任何使用知道 URL 的浏览器的人都可以访问或访问深层网页。黑色网页除了获得权限和了解内容的位置外,还需要具有适当加密密钥的 Tor 浏览器等特殊软件。
Black Web 建立在网络之上,只能通过特殊软件(基于要连接的网络,以及使用 TOR 代理和代理的 TOR 网络)访问并直接配置网络设置,这意味着应该整洁且匿名连接到网络。
股票信息爬取
我们爬取网易财经个股行情接口,接口示例如下:
http://quotes.money.163.com/trade/lsjysj_600000.html?year=2022&season=4
接口参数为/lsjysj_{xxxxxx(6位股票代码)}.html?year={xxxx(4位数字年份)}&season={x(季度)}
通过开发者查看页面对应的源码,股票信息所在table为<table class="table_bg001"...>,
<thead>
<tr class="dbrow">
<th>日期</th>
<th>开盘价</th>
<th>最高价</th>
<th>最低价</th>
<th>收盘价</th>
<th>涨跌额</th>
<th>涨跌幅(%)</th>
<th>成交量(手)</th>
<th>成交金额(万元)</th>
<th>振幅(%)</th>
<th>换手率(%)</th>
</tr>
</thead>
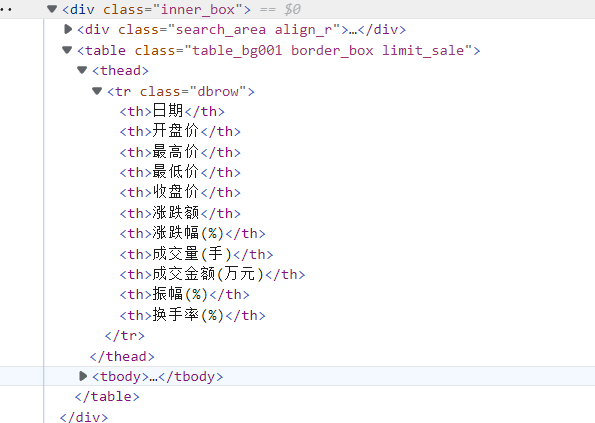
首先我们获取A股的股票列表,然后爬取所有股票2022年1-4季度的历史数据。
获取沪深A股所有股票信息的页面URL如下:
http://quotes.money.163.com/old/#query=EQA&DataType=HS_RANK&sort=PERCENT&order=desc&count=6000&page=0
设置count>=5031即可获取所有5031支A股股票的信息概览。
通过开发者工具观察网页记录,发现对应的后端接入如下:
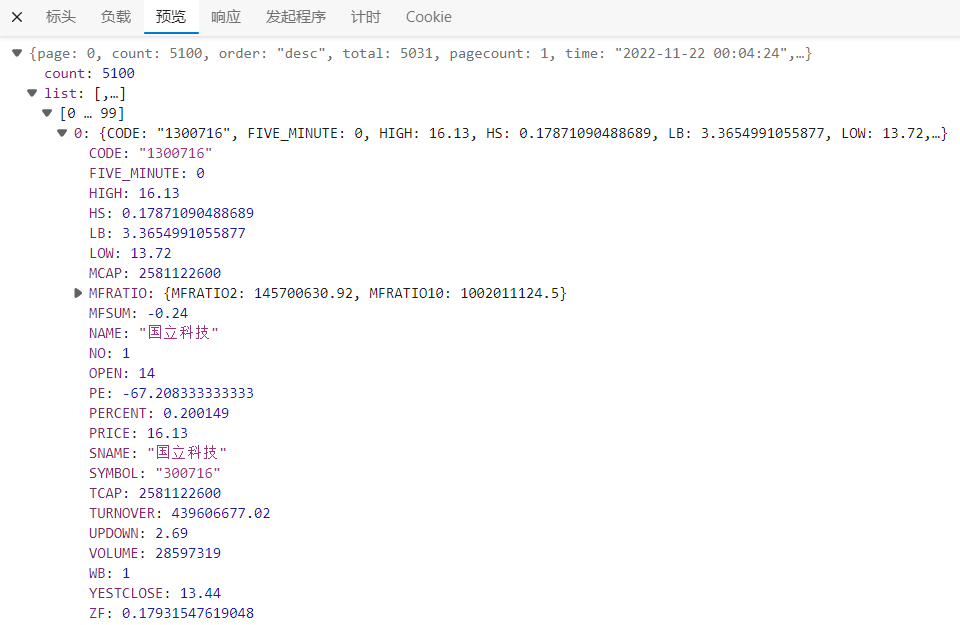
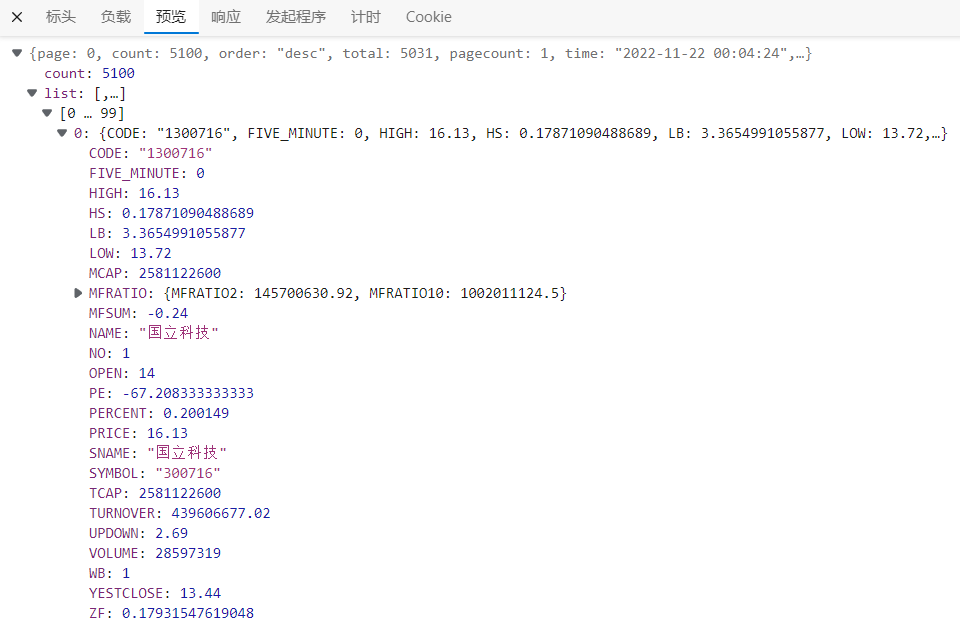
http://quotes.money.163.com/hs/service/diyrank.php?host=http://quotes.money.163.com/hs/service/diyrank.php&page=0&query=STYPE:EQA&fields=NO,SYMBOL,NAME,PRICE,PERCENT,UPDOWN,FIVE_MINUTE,OPEN,YESTCLOSE,HIGH,LOW,VOLUME,TURNOVER,HS,LB,WB,ZF,PE,MCAP,TCAP,MFSUM,MFRATIO.MFRATIO2,MFRATIO.MFRATIO10,SNAME,CODE,ANNOUNMT,UVSNEWS&sort=PERCENT&order=desc&count=5100&type=query
其中DataType代表数据类型,sort代表以哪一列排序,order为排序顺序,count为单页返回数据数量,page代表页数,从0开始递增。
观察Response,可以看到数据在list列表中,包含了5031支股票的数据。其中股票代码和股票名称字段为SYMBOL和SNAME。
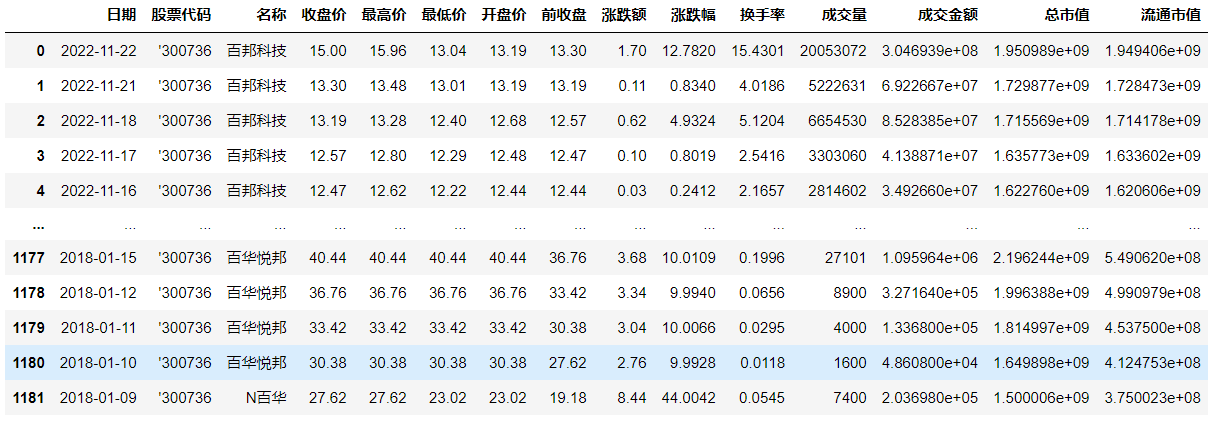
同时也发现了该网站批量爬取数据的接口,能够将输入的股票代码参数和时间范围内的数据一次性返回:
由于爬取数量较多,将会采取多线程加快爬取速度。
代码实现
以threading.Thread为基类实现多线程爬虫,分别对股票数据网站的接口进行爬取,获得股票信息,包括5038条股票的代码、名称等。再根据获取的股票代码,爬取股票的历史数据。
import requests
import io
from bs4 import BeautifulSoup
import pandas as pd
import time,random
import queue,threading
class DeepCrawler(threading.Thread):
#参数初始化
def __init__(self,q,out_q,year):
threading.Thread.__init__(self)
self.q=q
self.out_q=out_q
self.year=year
self.start_date='19901201'
#历史交易数据URL
self.query_url='http://quotes.money.163.com/trade/lsjysj_{}.html?year={}&season={}'
self.all_data_url = str('http://quotes.money.163.com/service/chddata.html?code={}&start={}&end={}&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP')
self.header={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42"}
self.stock_list=pd.DataFrame
def do_req(self,url):
try:
ret=requests.get(url,headers=self.header)
if not ret.ok:
print('request error:',ret.status_code)
return None
ret.encoding='utf-8'
return ret
except Exception as e:
print('request error:',e)
return None
#获取股票信息列表
def get_stock_list(self):
stock_list_url='http://quotes.money.163.com/hs/service/diyrank.php?host=http://quotes.money.163.com/hs/service/diyrank.php&page=0&query=STYPE:EQA&fields=NO,SYMBOL,NAME,PRICE,PERCENT,UPDOWN,FIVE_MINUTE,OPEN,YESTCLOSE,HIGH,LOW,VOLUME,TURNOVER,HS,LB,WB,ZF,PE,MCAP,TCAP,MFSUM,MFRATIO.MFRATIO2,MFRATIO.MFRATIO10,SNAME,CODE,ANNOUNMT,UVSNEWS&sort=PERCENT&order=desc&count=5100&type=query'
ret = self.do_req(stock_list_url)
if ret==None:
print('request error')
stock_list=dict(r.json())['list']
data=pd.DataFrame(stock_list)
data.index.name='index'
self.stock_list=data
data.to_csv('stock_list.csv')
#爬取股票信息
def crawl_stock_info(self,SYMBOL,Y,Q):
try:
#获取股票名称和代码
ret = self.do_req(self.query_url.format(SYMBOL,Y,Q))
soup = BeautifulSoup(ret.text)
data = list()
index= list()
for item in soup.select('body > div.area > div.inner_box > table > thead > tr > th'):
index.append(item.text)
for item in soup.select('body > div.area > div.inner_box > table > tr'):
tmp=list()
for td in item.children:
tmp.append(td.text)
data.append(tmp)
return index,data
except Exception as e:
print('crwal error:',e)
#下载某一股票的所有历史数据
def download_stock_data(self,CODE,SYMBOL,SNAME,start,end):
try:
#请求网页数据
r = self.do_req(self.all_data_url.format(CODE,start,end))
if r==None :
return
filename = f'result1/{SNAME}_{CODE}_{SYMBOL}_{start}_{end}.csv'.replace('*','-')
#写入文件中
data=pd.read_csv(io.StringIO(r.text))
data.to_csv(filename,index=0,encoding='utf-8')
# print(f'{filename} download complete: length {len(r.text)/(2**10)}KB')
time.sleep(5)
except Exception as e:
print('download error:',e)
#Thread.run()
def run(self):
try:
while not exit:
#从队列获取股票代码和名称
CODE,SYMBOL,SNAME =self.q.get(timeout=2)
#下载该股票的所有历史数据
self.download_stock_data(CODE,SYMBOL,SNAME,self.start_date,time.strftime("%Y%m%d",time.localtime()))
except Exception as e:
print(e)
#多线程爬取
def multi_thread_crawler():
try:
global exit
exit=False
#读取股票列表
data=pd.read_csv('stock_list.csv',index_col='index')
q_len=len(data)
# 填充队列
workQueue = queue.Queue(q_len)
out_q = queue.Queue(q_len)
for i in range(q_len):
workQueue.put(list((data.loc[i,['CODE','SYMBOL','SNAME']])))
threads = []
for i in range(10):
# 创建线程
thread = DeepCrawler(q=workQueue,out_q=out_q,year='2022')
# 开启新线程
thread.start()
# 添加新线程到线程列表
threads.append(thread)
while not workQueue.empty():
pass
# 等待所有线程完成
exit=True
for thread in threads:
thread.join()
except Exception as e:
print(e)
multi_thread_crawler()
本文来自博客园,作者:d42z,转载请注明原文链接:https://www.cnblogs.com/d42z/p/16916792.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号