Java 集合框架主要包括两种类型的容器,一种是Collection,存储一个元素集合,另一种是Map,存储键/值对映射。
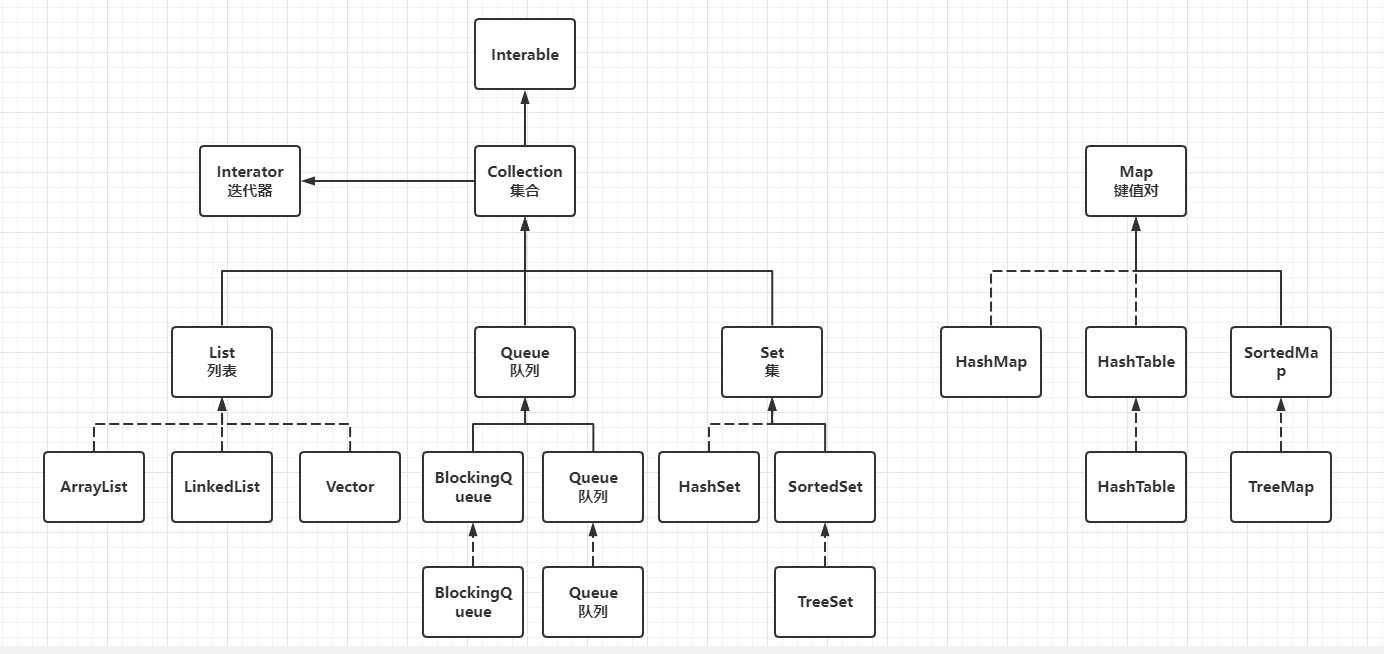
一、Collection集合
List集合
特点:有序可重复
ArrayList集合(内部使用数组来存储数据,可为null,查询性能好,线程不安全)
ArrayList底层用Object数组实现,初始化会指向一个空数组,第一次调用add()方法会给list一个初始容量10,如果list容量不够,调用grow方法扩容,每次扩容原数组的1/2。
ArrayList删除方法踩坑
List<String> strList = new ArrayList<>();
strList.add("aaa");
strList.add("bbb");
strList.add("ccc");
strList.add("ddd");
for (String s : strList) {
if ("ccc".equals(s)) {
strList.remove(s);
}
}
System.out.println(strList);
为什么对倒数第二个元素进行删除不会报异常,输出[aaa, bbb, ddd]。而对其他位置的删除会报异常?
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:907)
at java.util.ArrayList$Itr.next(ArrayList.java:857)
at collections.list.ArrayListRemove01.main(ArrayListRemove01.java:13)
原因: forEach 循环其实是走 list 的迭代器进行遍历的,在 ArrayList 中有一个内部类 Itr 实现了 Iterator ,这个类初始化的时候会将 ArrayList 对象的 modCount 属性的值赋值给 expectedModCount。在 ArrayList 的所有涉及结构变化的方法中都增加 modCount 的值,包括:add()、remove()、addAll()、removeRange() 及 clear() 方法。这些方法每调用一次,modCount 的值就加 1。而变量 expectedModCount 在迭代开始时便会被赋值成 modCount 的值。所以在循环遍历中,list 每次获取下一个对象前都要去检查一下光标是否越界,而 expectedModCount 却不会变化。
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
ArrayList遍历删除一般采用 Iterator 迭代遍历删除
Iterator<String> iterator = strList.iterator();
while (iterator.hasNext()) {
if ("ccc".equals(iterator.next())) {
iterator.remove();
}
}
LinkedList (内部使用双向链表来存储数据,增加和删除数据性能更好,线程不安全)
为什么linkList增删比ArrayList快, ArrayList查询快?
1、数组在内存中的地址是连续相邻的。而链表在内存中是散列存放的。数组的中间插入(或删除)一个元素,那么这个元素后的所有元素的内存地址都要往后(前)移动,对最后一个元素插入(或删除)时才比较快,而链表不需要改变内存的地址,只需要修改节点的信息即可(包括指针指向,节点值)
2、ArrayList,当我get(index)的时候,我可以根据数组的(首地址+偏移量),直接计算出我想访问的第index个元素在内存中的位置
Set集合
特点:无顺序,不可重复
HashSet类(基于HashMap实现)
-
- HashSet内部通过使用HashMap的键来存储集合中的元素,而且内部的HashMap的所有值都是null。
-
- 方便用于数据的查询,加入的元素特别要注意hashCode()方法的实现,不是同步的,多线程访问同一个hashSet对象时,需要手工同步
-
- HashSet存储对象的效率相对要低些,因为向HashSet集合中添加对象的时候,首先要计算出来对象的哈希码和根据这个哈希码来确定对象在集合中的存放位置。
-
- HashSet不是同步的,如果多个线程同时访问一个Set集合,如果多个线程同时访问一个HashSet集合,如果有2条或者2条以上线程同时修改了HashSet集合时,必须通过代码来保证其同步。
-
- HashSet集合元素可以是null。
HashSet还有一个子类 LinkedHashSet,LinkedHashSet 是LinkedHashMap 键的封装。
- LinkedHashSet 和 LinkedHashMap等集合有序是因为 LinkedHashSet与 LinkedHashMap底层是通过双向链表来实现排序的。
- LinkedHashSet集合也是根据元素hashCode值来决定元素存储位置,但它同时使用链表维护元素的次序。也就是说当遍历LinkedHashSet集合里的元素时,HashSet将会按元素的添加顺序来访问集合里的元素。
- LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但是在迭代访问Set里的全部元素时,将有很好的性能,因为它以列表来维护内部顺序。
SortedSet接口的实现类TreeSet
- TreeSet是通过TreeMap实现的一个有序的、不可重复的集合,底层维护的是红黑树结构。
- 当TreeSet的泛型对象不是java的基本类型的包装类时(String 除外),对象需要重写Comparable#compareTo()方法
TreeSet中有两种排序,一个是自然排序,一个是重写compareTo()方法自定义排序。
自然排序可以参考Integer,String等类中的实现。其顺序也是我们常见的“1,2,3,4”,“a,b,c,d”。假如我们想让Student对象中String类型的字段倒序输出呢
@Data
public class Student implements Comparable<Student>{
String name;
/**
* 这里的参数o,其实是TreeMap中维护的根节点
* @param o
* @return
*/
@Override
public int compareTo(Student o) {
System.out.println("name:"+name+",参数:"+o.getName());
int i = this.name.compareTo(o.getName());
return i==0?0:-i;
}
}
public static void main(String[] args) {
Set<Student> set = new TreeSet<>();
Student a = new Student();
a.setName("a");
Student b = new Student();
b.setName("b");
Student c = new Student();
c.setName("c");
Student d = new Student();
d.setName("d");
Student e = new Student();
e.setName("e");
Student f = new Student();
f.setName("f");
set.add(a);
set.add(c);
set.add(e);
set.add(b);
set.add(d);
set.add(f);
for (Student str: set) {
System.out.print(str.getName());
}
}
================================================================
输出结果:
name:a,参数:a
name:c,参数:a
name:e,参数:a
name:e,参数:c
name:b,参数:c
name:b,参数:a
name:d,参数:c
name:d,参数:e
name:f,参数:c
name:f,参数:e
fedcba
Map集合
HashMap
HashMap基于Map接口实现,元素以键值对的方式存储,并且允许使用null建和null值,因为key不允许重复,因此只能有一个键为null,另外HashMap不能保证放入元素的顺序,它是无序的,和放入的顺序并不能相同。HashMap是线程不安全的。
在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成(1.7版本是数组+链表)
- HashMap采用Entry数组来存储key-value对,每一个键值对组成了一个Entry实体,Entry类实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Entry实体,依次来解决Hash冲突的问题,因为HashMap是按照Key的hash值来计算Entry在HashMap中存储的位置的,如果hash值相同,而key内容不相等,那么就用链表的形式存储,当链表过长的话,HashMap会把这个链表转换成红黑树来存储。
1、散列表
通过数组和链表结合在一起使用,就叫做链表散列
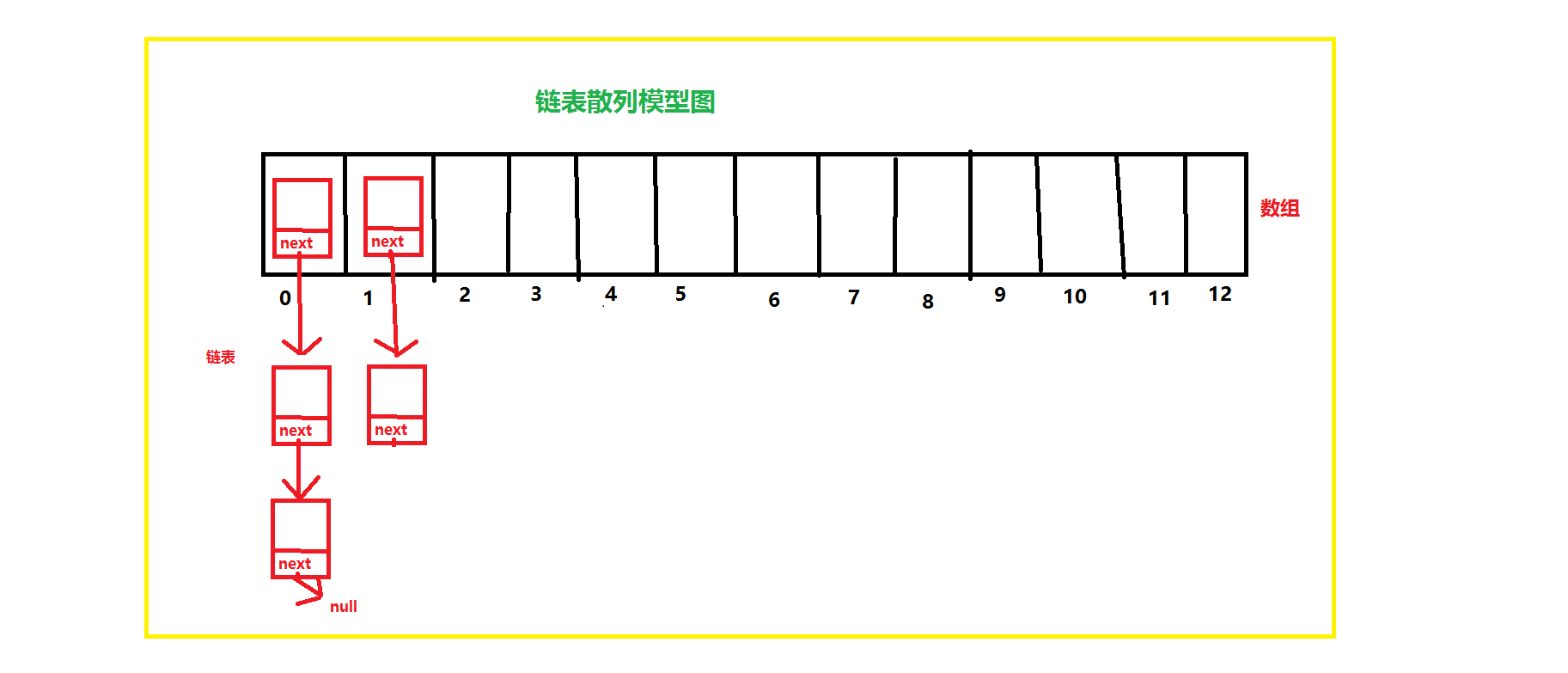
2、hashMap的数据结构和存储原理
HashMap的数据结构就是用的链表散列,大概是怎么存储的呢?分两步
- 1、HashMap将hash,key,value,next已经封装到一个静态内部类Node上。它实现了
Map.Entry<K,V>接口。我们要存储一个值,则需要一个key和一个value,存到map中就会先将key和value保存在这个Entry类创建的对象中。
//这里只看这一小部分,其他重点的在下面详细解释
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; //就是我们说的map的key
V value; //value值,这两个都不陌生
Entry<K,V> next;//指向下一个entry对象
int hash;//通过key算过来的你hashcode值。
- 2、构造好了entry对象,然后将该对象放入数组中,如何存放就是这hashMap的精华所在了。
- 大概的一个存放过程是:通过key、value封装成一个entry对象,然后通过key的值来计算该entry的hash值,通过entry的hash值和数组的长度length来计算出entry放在数组中的哪个位置上面,每次存放都是将entry放在第一个位置。在这个过程中,就是通过hash
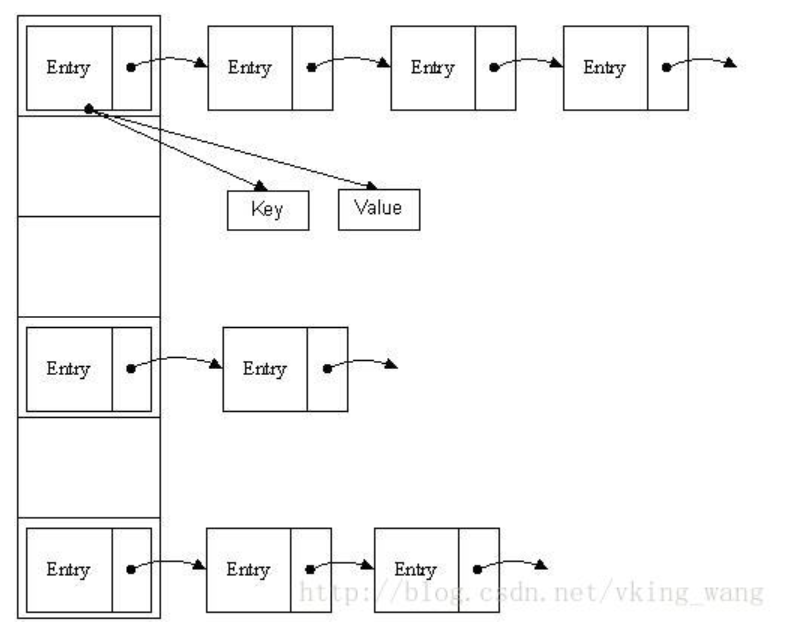
- 大概的一个存放过程是:通过key、value封装成一个entry对象,然后通过key的值来计算该entry的hash值,通过entry的hash值和数组的长度length来计算出entry放在数组中的哪个位置上面,每次存放都是将entry放在第一个位置。在这个过程中,就是通过hash
HashMap的一些概念
-
1、loadFactor加载因子
- loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加。如果 loadFactor 太大,我们在通过key拿到我们的value时,是先通过key的hashcode值,找到对应数组中的位置,如果该位置中有很多元素,则需要通过equals来依次比较链表中的元素,拿到我们的value值,这样花费的性能就很高,如果能让数组上的每个位置尽量只有一个元素最好,我们就能直接得到value值了,所以有人又会说,那把loadFactor变得很小不就好了,但是如果变得太小,在数组中的位置就会太稀,也就是分散的太开,浪费很多空间,这样也不好,所以在hashMap中loadFactor的初始值就是0.75
-
桶
- 根据前面画的HashMap存储的数据结构图,你这样想,数组中每一个位置上都放有一个桶,每个桶里就是装一个链表,链表中可以有很多个元素(entry),这就是桶的意思。也就相当于把元素都放在桶中。
-
capacity
- 代表的数组的容量,也就是数组的长度,同时也是HashMap中桶的个数。默认值是16.
-
HashCode
- 首先一个对象肯定有物理地址,hashcode代表对象的地址说的是对象在hash表中的位置,物理地址说的对象存放在内存中的地址,把对象的物理地址转换成一个整数,然后该整数通过hash函数的算法就得到了hashcode,所以,hashcode是什么呢?就是在hash表中对应的位置。HashCode的存在主要是为了查找的快捷性
- 1、.若两个对象equals相等,则hashCode一定相等。
- 2、若两个对象equals不等,则hashCode有可能相等。
- 3、若两个对象hashCode相等,则equals不一定返回相等。
- 4、若两个对象hashCode不等,则equals一定返回不等。
LinkedHashMap
1、LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于散列结构。该结构由数组和链表或红黑树组成,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序
2、JDK1.8之前采用的是拉链法。拉链法 :将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
3、LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号