
使用几种常见分类器预测海难幸存者(二分类)
1 预备知识
1.1 XGBoost
Boosting分类器属于集成学习模型,它基本思想是把成百上千个分类准确率较低的树模型组合起来,成为一个准确率很高的模型。这个模型会不断地迭代,每次迭代就生成一颗新的树。在合理的参数设置下,我们往往要生成一定数量的树才能达到令人满意的准确率。在数据集较大较复杂的时候,我们可能需要几千次迭代运算。XGBoost(eXtreme Gradient Boosting)更好地解决了这个问题。gboost最大的特点在于,它能够自动利用CPU的多线程进行并行,同时在算法上加以改进,提高分类预测的精度。下面会用这种分类器和随机森林做一个比较。github链接:XGBoost
1.2 交叉验证
讲交叉验证之前一定要清楚,仅仅使用默认配置的模型在大多数任务下无法取得最佳的性能表现。因此在预测之前,我们希望尽可能地利用手头现有的数据对模型进行调优。通常的做法就是对现有数据进行采样分割:一部分用于模型参数训练,这部分叫训练集(Training Set);另一部分用于调优模型配置和特征选择,并且对未知的测试性能做出估计,叫做验证集(Validation Set)或者开发集(Development Set)。也就是说,首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。
保持(hold-out)方法是这种思想的最简单体现,通常把2/3(也有说70%)的数据分配到训练集,其余1/3(30%)分配到验证集。使用训练集导出模型,其准确率用验证集估计。估计是悲观的,因为是分割是随机的,所以最后验证集分类准确率的高低与分割的结果有很大的关系,所以这种方法得到的结果其实并不具有说服性。

随机二次抽样(random subsampling)是hold-out方法的一种变形,它将保持方法重复k次,总准确率估计取每次迭代准确率的平均值。
由于hold-out方法的不确定性,在我们拥有了足够的算力之后,这一验证方法进化出了更高级的版本,也就是我们下面马上要说的——交叉验证。
交叉验证(k-fold cross-validation,CV)中,初始数据被随机划分为k个互不相交的子集或者叫“折”,每个折的大小大致相等。训练和验证进行k次。在第i次迭代,分区Di作为验证集,其余的折一起用作训练集。如此迭代下去,每个样本用于训练的次数相同,并且有一次是用于验证的,这是与前面的hold-out方法和随机二次抽样方法不同的地方。对于分类,准确率估计是k次迭代正确分类的实例总数初一初始数据中的实例总数。下面的图展示了4折交叉验证的迭代过程。
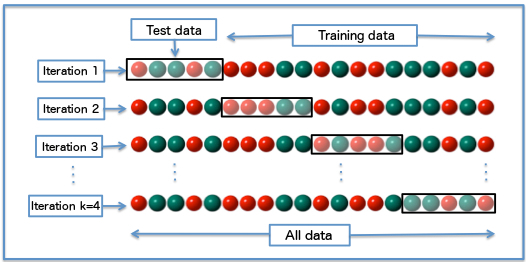
全部可用的数据被随机分割为平均数量的5组,每次迭代都选取其中的1组数据作为验证集,其余4组作为训练集。
交叉验证的好处在于,可以保证所有数据都有被训练和验证的机会,也尽最大可能让优化的模型性能表现得更加可信。
留一(leave-one-out,LOO-CV)是k折交叉验证的特殊情况。如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标.相比于前面的K-CV,LOO-CV有两个明显的优点:
- 每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
- 实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但LOO-CV的缺点则是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间.
2 数据准备
在Kaggle上,有许多数据可以为我们练习使用。比如这个“铁达尼号”的项目。这个项目是一个二分类的问题,通过给出的乘客信息来预测最终幸存与否。
- survival 幸存与否 :0 = 挂了, 1 = 得救
- pclass 舱位等级: 1 = 头等舱, 2 = 二等舱, 3 = 三等舱
- sex 性别
- Age 年龄
- sibsp 同船的配偶或兄弟姐妹的人数
- parch 同船的父母或儿女的人数
- ticket 票号
- fare 路费
- cabin 客舱号
- embarked 登船口岸: C = Cherbourg, Q = Queenstown, S = Southampton
数据下载链接:https://www.kaggle.com/c/titanic/data
3 数据清洗
第一步:在下载的原始数据中有一些属性是和分类结果没有什么关系的,这些属性是我们不需要的,我们把这些属性忽略掉,仅保留如下9个属性。同时,我们发现有许多实例缺失属性值,我们要做相应的填充处理。比如年龄属性我们用平均值填充缺失的属性值,用众数来填充Embarked的缺失值。我们要保证我们的数据中没有缺失任何属性,否则会报错。如果有这种实例,且缺失的属性和分类的关联不大,我们把这些实例拿掉。
- PassengerId
- Pclass
- Sex
- Age
- SibSp
- Parch
- Fare
- Embarked
填充缺失值,我们可以使用一个代码块来遍历一下我们的数据,看看哪个实例的哪个属性缺失值。例如:
import numpy as npy
for i in range(len(train_x)):
dataline=train_x[i]
for j in range(len(dataline)):
if npy.isnan(dataline[j]):
print("行:",i+2,"列:",j+2)
或者,使用一种更简便直接的方法info()来查看非空属性的实例个数,然后使用fillna()来填充。下面代码用的就是这种方法。
4 预处理
#! /usr/bin/env python3
# -*-coding:utf-8-*-
import pandas as pds
trainfile="/home/d0main/LL/Python35/Datasets/Titanic/train.csv"#注意这两个文件的编码采用utf-8
testfile="/home/d0main/LL/Python35/Datasets/Titanic/test.csv"
trainset=pds.read_csv(trainfile)
testset=pds.read_csv(testfile)
#查看数据集信息
#print(trainset.info())
#print(testset.info())
#选择训练数据和验证数据的相关属性(列)
selected_features=['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']#Cabin缺失了太多数据,所以也忽略掉
train_x=trainset[selected_features]
test_x=testset[selected_features]
#获取对应的类标号
train_y=trainset["Survived"]
#补充缺失值
train_x["Age"].fillna(train_x["Age"].mean(),inplace=True)
test_x["Age"].fillna(test_x["Age"].mean(),inplace=True)
test_x["Fare"].fillna(test_x["Fare"].mean(),inplace=True)
train_x["Embarked"].fillna('S',inplace=True)
#print(test_x.info())
#print(train_x.info())
5 训练与验证
#特征抽取
from sklearn.feature_extraction import DictVectorizer
dict_vec=DictVectorizer(sparse=False)
train_x=dict_vec.fit_transform(train_x.to_dict(orient='record'))
print(dict_vec.feature_names_)
test_x=dict_vec.transform(test_x.to_dict(orient="record"))
#随机森林
from sklearn.ensemble import RandomForestClassifier
rfc_model=RandomForestClassifier()
rfc_model.fit(train_x,train_y)
#XGBoost
from xgboost import XGBClassifier
xgbc_model=XGBClassifier()
xgbc_model.fit(train_x,train_y)
#ET
from sklearn.ensemble import ExtraTreesClassifier
et_model=ExtraTreesClassifier()
et_model.fit(train_x,train_y)
#朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
gnb_model=GaussianNB()
gnb_model.fit(train_x,train_y)
#性能评价(交叉验证)
from sklearn.cross_validation import cross_val_score
print("\n 使用5折交叉验证方法得随机森林模型的准确率(每次迭代的准确率的均值):")
print("\t 随机森林模型:",cross_val_score(rfc_model,train_x,train_y,cv=5).mean())
print("\t XGBoost模型:",cross_val_score(xgbc_model,train_x,train_y,cv=5).mean())
print("\t ET模型:",cross_val_score(et_model,train_x,train_y,cv=5).mean())
print("\t 高斯朴素贝叶斯模型:",cross_val_score(gnb_model,train_x,train_y,cv=5).mean())
6 测试与输出
#预测test.csv中的数据
rfc_predicted_y=rfc_model.predict(test_x)
#结果输出到csv
rfc_submission=pds.DataFrame({"PassengerId":testset["PassengerId"],"Survived":rfc_predicted_y})
rfc_submission.to_csv("rfc_submission.csv",index=False)
xgbc_predicted_y=xgbc_model.predict(test_x)
xgbc_submission=pds.DataFrame({"PassengerId":testset["PassengerId"],"Survived":xgbc_predicted_y})
xgbc_submission.to_csv("xgbc_submission",index=False)
et_predicted_y=et_model.predict(test_x)
et_submission=pds.DataFrame({"PassengerId":testset["PassengerId"],"Survived":et_predicted_y})
et_submission.to_csv("et_submission",index=False)
gnb_predicted_y=gnb_model.predict(test_x)
gnb_submission=pds.DataFrame({"PassengerId":testset["PassengerId"],"Survived":gnb_predicted_y})
gnb_submission.to_csv("gnb_submission",index=False)
7 hold-out方法进行评价
由于数据选择的不确定性,这种简单的保持方法在实际评价模型时不予采用。这里只做是为了体现几种不同分类器、混淆矩阵和分类器评价报表的的使用。
'''
#性能评估(HOLD OUT)
from sklearn import metrics
from sklearn.cross_validation import train_test_split
subtrain_x,validation_x,subtrain_y,validation_y=train_test_split(train_x,train_y,test_size=0.3,random_state=8)
#subtrain_x表示训练集的几个特征属性,validation_x表示验证集的特征属性,subtrain_y和validation_y分前两者的类标签。test_size=0.3表示验证样本的占比为30%,random_state=8表示随机数种子为8。
#K最近邻
from sklearn.neighbors import KNeighborsClassifier
knn_model=KNeighborsClassifier()
knn_model.fit(subtrain_x,subtrain_y)
knn_predicted_y=knn_model.predict(validation_x)
#逻辑回归
from sklearn.linear_model import LogisticRegression
lr_model=LogisticRegression()
lr_model.fit(subtrain_x,subtrain_y)
lr_predicted_y=lr_model.predict(validation_x)
#决策树
from sklearn.tree import DecisionTreeClassifier
dt_model=DecisionTreeClassifier()
dt_model.fit(subtrain_x,subtrain_y)
dt_predicted_y=dt_model.predict(validation_x)
#支持向量机
from sklearn.svm import SVC
svc_model=SVC()
svc_model.fit(subtrain_x,subtrain_y)
svc_predicted_y=svc_model.predict(validation_x)
print("\n 使用保持(hold-out)方法得模型的平均准确率(mean accuracy = (TP+TN)/(P+N) )")
print("\t 最近邻模型:",knn_model.score(validation_x,validation_y))
print("\t Logistic回归模型:",lr_model.score(validation_x,validation_y))
print("\t 决策树模型:",dt_model.score(validation_x,validation_y))
print("\t 支持向量机模型:",svc_model.score(validation_x,validation_y))
print("\n K近邻模型性能评价:")
print("\t 预测结果评价报表:\n", metrics.classification_report(validation_y,knn_predicted_y))
print("\t 混淆矩阵:\n", metrics.confusion_matrix(validation_y,knn_predicted_y))
print("\n 逻辑回归模型性能评价:")
print("\t 预测结果评价报表:\n", metrics.classification_report(validation_y,lr_predicted_y))
print("\t 混淆矩阵:\n", metrics.confusion_matrix(validation_y,lr_predicted_y))
print("\n 决策树模型性能评价:")
print("\t 预测结果评价报表:\n", metrics.classification_report(validation_y,dt_predicted_y))
print("\t 混淆矩阵:\n", metrics.confusion_matrix(validation_y,dt_predicted_y))
print("\n 支持向量机模型性能评价:")
print("\t 预测结果评价报表:\n", metrics.classification_report(validation_y,svc_predicted_y))
print("\t 混淆矩阵:\n", metrics.confusion_matrix(validation_y,svc_predicted_y))
'''
8 模型评价
在各个分类器的报表中,我们看到了precision、recall、f1-score这几个概念。这些概念是用来给分析人员评估分类效果好与坏的。具体含义可以参考Wikipedia。
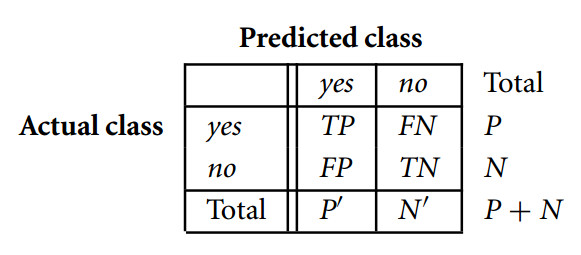
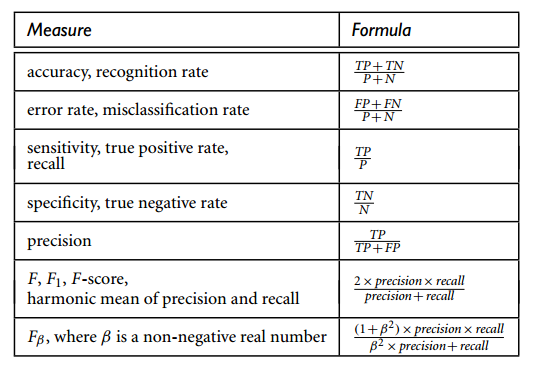
在二分类中,通常我们去f1-score最高的模型进行预测即可。
9 参考文献
-
拾毅者. 机器学习-CrossValidation交叉验证Python实现[EB/OL]. http://blog.csdn.net/dream_angel_z/article/details/47110077, 2015-07-28
-
Henrik, Brink, Joseph, W, Richards, and, Mark, Fetherolf. Real-World Machine Learning: Model Evaluation and Optimization[EB/OL]. http://www.developer.com/mgmt/real-world-machine-learning-model-evaluation-and-optimization.html, 2016-02-04
-
雪伦_. xgboost原理[EB/OL]. http://blog.csdn.net/a819825294/article/details/51206410, 2016-04-21
-
AARSHAY, JAIN. Complete Guide to Parameter Tuning in XGBoost (with codes in Python)[EB/OL]. https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-Python/, 2016-03-01

 浙公网安备 33010602011771号
浙公网安备 33010602011771号