
【译】为什么BERT有3个嵌入层,它们都是如何实现的
本文翻译自Why BERT has 3 Embedding Layers and Their Implementation Details
引言
本文将阐述BERT中嵌入层的实现细节,包括token embeddings、segment embeddings, 和position embeddings.
概览
下面这幅来自原论文的图清晰地展示了BERT中每一个嵌入层的作用:
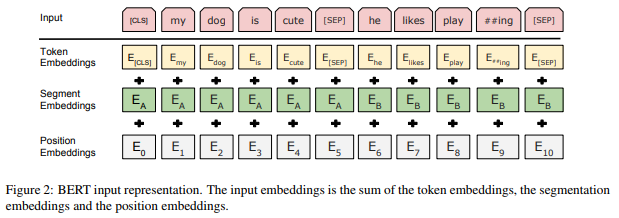
和大多数NLP深度学习模型一样,BERT将输入文本中的每一个词(token)送入token embedding层从而将每一个词转换成向量形式。但不同于其他模型的是,BERT又多了两个嵌入层,即segment embeddings和 position embeddings。在阅读完本文之后,你就会明白为何要多加这两个嵌入层了。
Token Embeddings
作用
正如前面提到的,token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示。
实现
假设输入文本是 “I like strawberries”。下面这个图展示了 Token Embeddings 层的实现过程:

输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。它们视为后面的分类任务和划分句子对服务的。
tokenization使用的方法是WordPiece tokenization. 这是一个数据驱动式的tokenization方法,旨在权衡词典大小和oov词的个数。这种方法把例子中的“strawberries”切分成了“straw” 和“berries”。这种方法的详细内容不在本文的范围内。有兴趣的读者可以参阅 Wu et al. (2016) 和 Schuster & Nakajima (2012)。使用WordPiece tokenization让BERT在处理英文文本的时候仅需要存储30,522 个词,而且很少遇到oov的词。
Token Embeddings 层会将每一个wordpiece token转换成768维的向量。这样,例子中的6个token就被转换成了一个(6, 768) 的矩阵或者是(1, 6, 768)的张量(如果考虑batch_size的话)。
Segment Embeddings
作用
BERT 能够处理对输入句子对的分类任务。这类任务就像判断两个文本是否是语义相似的。句子对中的两个句子被简单的拼接在一起后送入到模型中。那BERT如何去区分一个句子对中的两个句子呢?答案就是segment embeddings.
实现
假设有这样一对句子 (“I like cats”, “I like dogs”)。下面的图成仙了segment embeddings如何帮助BERT区分两个句子:
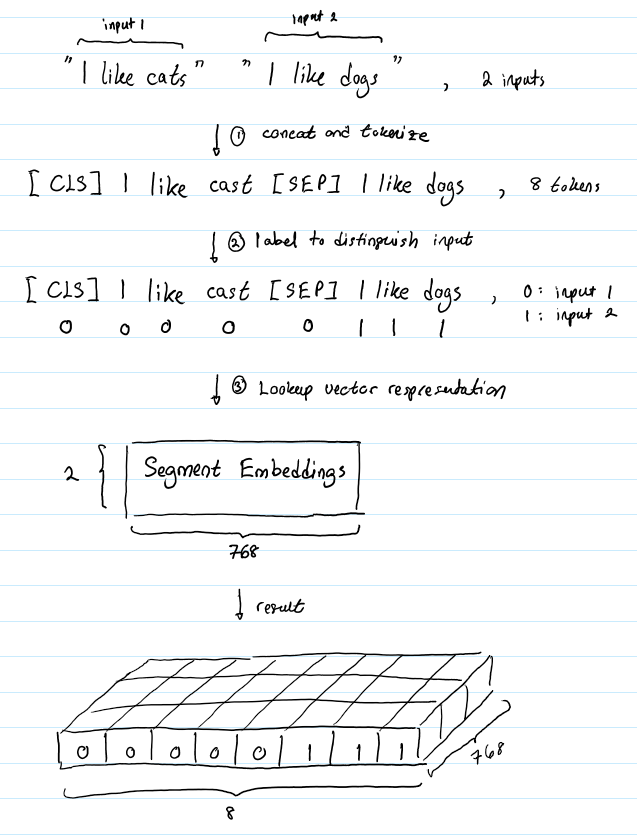
Segment Embeddings 层只有两种向量表示。前一个向量是把0赋给第一个句子中的各个token, 后一个向量是把1赋给第二个句子中的各个token。如果输入仅仅只有一个句子,那么它的segment embedding就是全0。
Position Embeddings
作用
BERT包含这一串Transformers (Vaswani et al. 2017),而且一般认为,Transformers无法编码输入的序列的顺序性。 博客更加详细的解释了这一问题。总的来说,加入position embeddings会让BERT理解下面下面这种情况:
I think, therefore I am
第一个 “I” 和第二个 “I”应该有着不同的向量表示。
实现
BERT能够处理最长512个token的输入序列。论文作者通过让BERT在各个位置上学习一个向量表示来讲序列顺序的信息编码进来。这意味着Position Embeddings layer 实际上就是一个大小为 (512, 768) 的lookup表,表的第一行是代表第一个序列的第一个位置,第二行代表序列的第二个位置,以此类推。因此,如果有这样两个句子“Hello world” 和“Hi there”, “Hello” 和“Hi”会由完全相同的position embeddings,因为他们都是句子的第一个词。同理,“world” 和“there”也会有相同的position embedding。
合成表示
我们已经介绍了长度为n的输入序列将获得的三种不同的向量表示,分别是:
- Token Embeddings, (1, n, 768) ,词的向量表示
- Segment Embeddings, (1, n, 768),辅助BERT区别句子对中的两个句子的向量表示
- Position Embeddings ,(1, n, 768) ,让BERT学习到输入的顺序属性
这些表示会被按元素相加,得到一个大小为(1, n, 768)的合成表示。这一表示就是BERT编码层的输入了。
结论
在本文中,笔者介绍了BERT几个嵌入层的作用以及实现。
参考文献
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding; Devlin et al. 2018.
-
Google’s Neural Machine Translation System: Briding the Gap between Human and Machine Translation; Wu et al. 2016
-
Japanese and Korean Voice Search; Schuster and Nakajima. 2012.
-
Attention Is All You Need; Vaswani et al. 2017.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号