
【译】深度双向Transformer预训练【BERT第一作者分享】
翻译自Jacob Devlin分享的slides
目录
NLP中的预训练
-
词嵌入是利用深度学习解决自然语言处理问题的基础。
![]()
-
词嵌入(例如word2vec,GloVe)通常是在一个较大的语料库上利用词共现统计预训练得到的。例如下面两个句子中,由于king和queen附近的上下文时常相同或相似,那么在向量空间中,这两个词的距离较为接近。
![]()


语境表示
-
问题:通常的词嵌入算法无法表现一个词在不同语境(上下文)中不同的语义。例如bank一词在下列两个句子中有着不同的语义,但是却只能使用相同的向量来表示。
![]()
-
解决方案:在大语料上训练语境表示,从而得到不同上下文情况下的不同向量表示。


语境表示相关研究
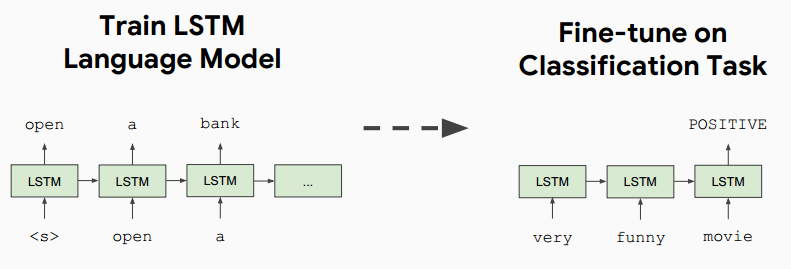
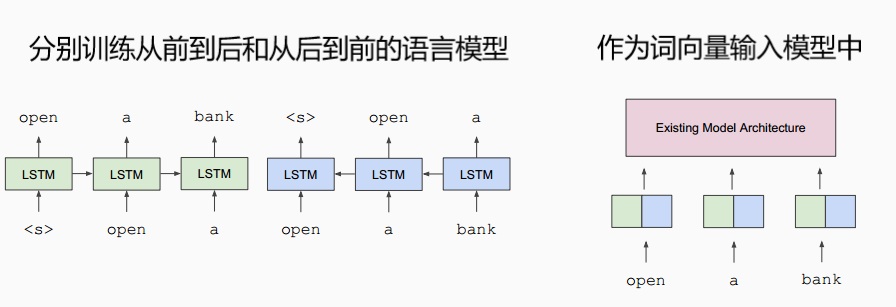
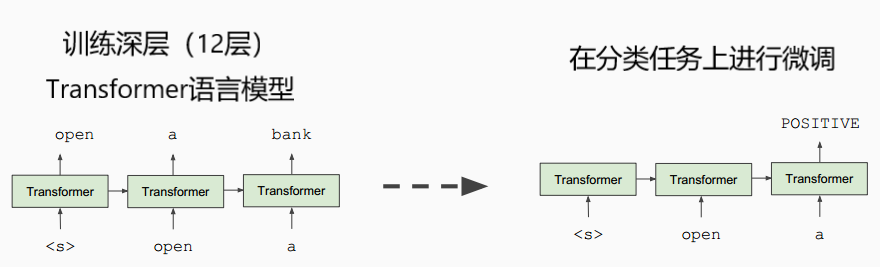
- 译者注:比较著名的还有2018年初fast.ai提出的ULMFiT
存在的问题
- 问题:语言模型的训练,要么仅适用上文,要么仅适用下文;而人类理解语言则是同时考虑上下文的。
- 为什么说语言模型是单向的
- 理由1:为了生成适合模型计算的概率分布
- 理由2:如果使用双向的编码器,因为这会产生一些循环,在这些循环中,单词会间接地“窥见”自己
![]()

BERT的解决方案
任务一:Masked LM
把输入序列中的k%(一般为15%)的词掩盖住,然后通过上下文预测这些被掩盖住的词。

- k%的设置
- k太小:计算代价过大
- k太大:剩下的上下文不足以准确预测
- 遇到的问题:在预训练过程中所使用的这个特殊符号,在后续的任务中是不会出现的。
- 由于15%的词被遮住,那么就有15%的词要被语言模型预测,但是BERT并不是一词就将所有这些词都用[MASK]替换掉,而是

任务二:预测下一句
学习句子间的关系,预测句子B是否句子A的下一句话(译者注:二元分类任务)。

BERT
输入表示

- 使用30,000 WordPiece 词表(BERT 用 WordPiece工具来进行分词,并插入特殊的分离符([CLS],用来分隔样本)和分隔符([SEP],用来分隔样本内的不同句子))
- 每一个token由三种向量加和而成
- 单一序列更高效
模型结构——Transformer编码器
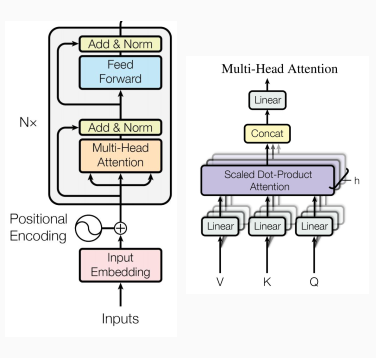
- 多头注意力机制
- 上下文建模
- 前向层
- 计算非线性层次特征
- 正则化与残差
- 让深层网络更有效
- 位置向量
- 让模型学习相对位置的特征
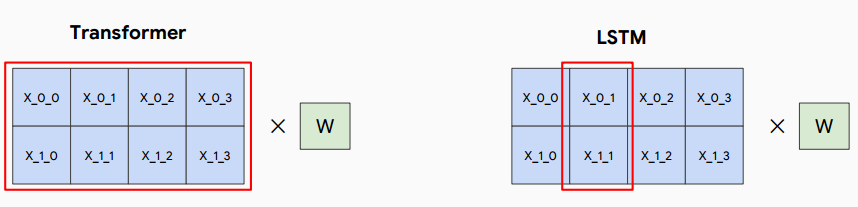
Transformer vs. LSTM
- 自注意力机制不管词间距离长短而直接计算其依赖关系
- 每一层进行乘法运算在TPU上更高效
- 有效的batch_size是词数而不是序列数
模型细节
- 语料: Wikipedia (2.5B words) + BookCorpus (800M words)
- Batch Size: 131,072 个词 (1024 个序列* 每个序列128个词或者256个序列 *每个序列512个词)
- 训练时间: 1M steps (~40 epochs)
- Optimizer: AdamW, 1e-4 learning rate, linear decay
- BERT-Base: 12-layer, 768-hidden, 12-head
- BERT-Large: 24-layer, 1024-hidden, 16-head
- 在4x4 或 8x8 的TPU slice上训练了4天
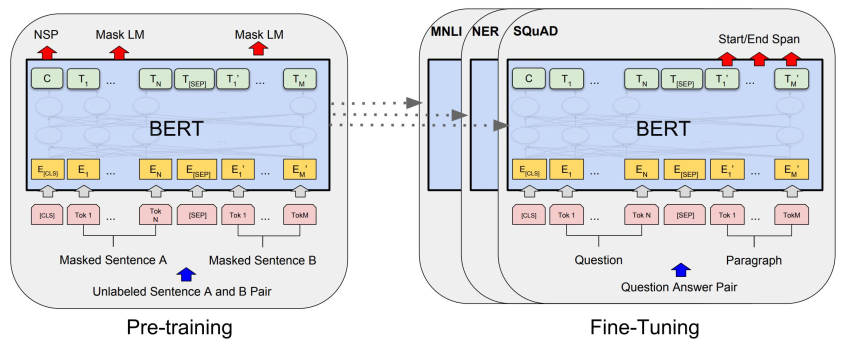
在不同任务上进行微调
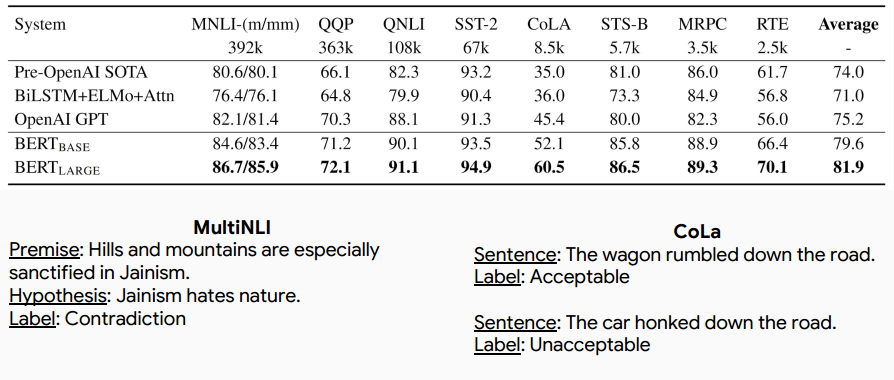
GLUE
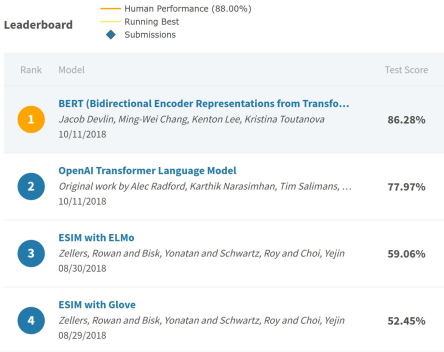
SQuAD 1.1

*注:榜单已经被很多基于BERT的模型刷新了
SQuAD 2.0

SWAG
分析
预训练的影响
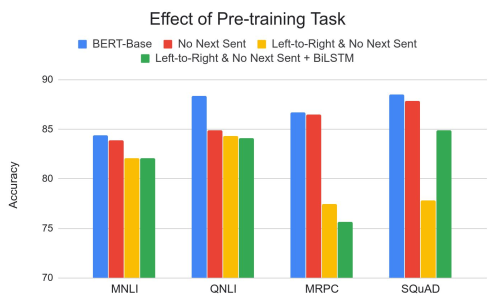
- 相较于从前到后(从左到右)语言模型,在一些任务中,Masked LM更重要,还有一些任务中,预测下一句这一策略很重要。
- 从前到后的模型在词级别的任务(如SQuAD)上表现平平,加上BiLSTM后效果也一般。
方向与训练时间的影响
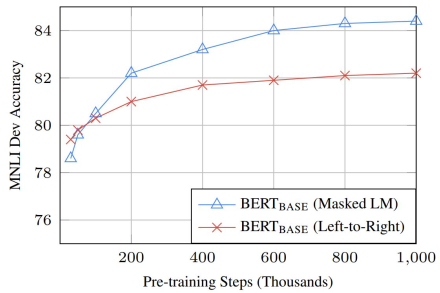
- 由于仅仅预测15%的词,因此Masked LM收敛速度仅仅慢了一点点
- Masked LM的绝对结果显然更好
模型规模的影响
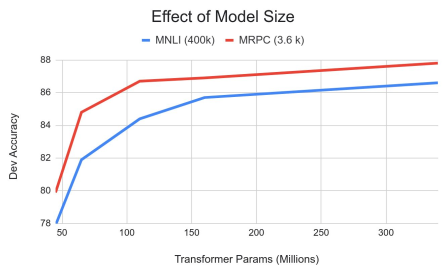
- 大模型更有效
- 即使在仅有3,600个标注样本的数据集上,把参数从110M调整到340M也带来了性能提升
- 性能提升并不是渐进的
遮罩策略的影响

- 一次遮住100%的词让基于特征的方法在性能上有所下降
- 而100%使用随机替换的方式让基于特征的方法在性能上下降幅度较小
多语言BERT(机器翻译)
- 在104种语言的维基百科数据上训练不同的语言模型,共享110k的WordPiece 词表
- XNLI是由MultiNLI翻译为多种语言得到的
- 在人工翻译测试集上进行性能评估
- 机器翻译-训练:将英文翻译为其他语言,然后进行微调
- 机器翻译-测试:将其他语言翻译为英文,使用英文模型
- 零样本:在英文模型上使用其他语言进行测试
生成训练数据(机器阅读理解)
-
使用seq2seq模型从context+answer中生成正例问题
-
启发式地将正例问题转换为负例(如“no answer”/impossible )
-
在维基百科数据上预训练seq2seq模型
- 用BERT作为编码器,训练解码器解码下一个句子
-
在SQuAD 进行微调——Context+Answer →Question
- Ceratosaurus was a theropod dinosaur in the Late Jurassic, around 150 million years ago. -> When did the Ceratosaurus live ?
-
训练模型,预测答案,不使用问题描述
- Ceratosaurus was a theropod dinosaur in the Late Jurassic, around 150 million years ago. ->
-
使用第三步的模型从大量维基百科数据中生成答案
-
使用第四步的输出作为seq2seq模型的输入,生成问题描述
- Roxy Ann Peak is a 3,576-foot-tall mountain in the Western Cascade Range in the U.S. state of Oregon. → What state is Roxy Ann Peak in?
-
利用基线SQuAD2.0 系统过滤不好的问题
- ○ Roxy Ann Peak is a 3,576-foot-tall mountain in the Western Cascade Range in the U.S. state of Oregon. → What state is Roxy Ann Peak in? ( 好问题)
○ Roxy Ann Peak is a 3,576-foot-tall mountain in the Western Cascade Range in the U.S. state of Oregon. → Where is Oregon? (坏问题)
- ○ Roxy Ann Peak is a 3,576-foot-tall mountain in the Western Cascade Range in the U.S. state of Oregon. → What state is Roxy Ann Peak in? ( 好问题)
-
启发式地生成强负例
- 从同一文档的其他段落中获得正例问题
- What state is Roxy Ann Peak in? → When was Roxy Ann Peak first summited?
- 将一些词替换为段落内相同 POS标识类型的词
- What state is Roxy Ann Peak in? → What state is Oregon in?
- What state is Roxy Ann Peak in? → What mountain is Roxy Ann Peak in?
- 从同一文档的其他段落中获得正例问题
-
可选步骤: Two-pass训练,
常见问题
- 深度双向性是必要的吗?在更大的模型上像ELMo这种类型的浅层双向性怎么样?
- 深度双向性的优点:训练耗时稍短
- ELMo这种类型的浅层双向模型的缺点:
- 需要在上面增加非预训练的双向模型
- 从后到前的SQuAD模型看不到问题描述
- 需要训练两个模型
- 错位:从前到后(LTR)预测下一个词,从后到前(RTL)预测前一个词
- 增加预训练任务并不是没有用
- 为什么之前没有人想到这一点?或者说,为什么在ELMo之前语境预训练没有流行起来?
- 比起有监督训练,计算开销更大
- 在2013年,从零训练2层的512维的LSTM情感分析模型,需要花费约8小时进行训练,正确率达到80%;而预训练的语言模型在同样的结构上需要消耗一周的时间,而正确率也就能达到80.5%。(谁会为了这么一点点提升却消耗这么大的计算代价?)
- 靠这一个模型能解决NLP中的所有问题吗?
- 就目前而言,在大部分任务上是可以由这一模型解决的
结论
- 使用预训练,更大的模型意味着更好的性能,目前没有证明其界限
- 研究者或企业在BERT上建立模型,会带来更好的模型性能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号