Scrapy(三) - Spider Middlerware 使用
介绍
处于Spider 和 Engine 之间的处理模块。当Downloader 生成Response之后,Response会被发送给Spider,在发送
给Spider之前,Response 会首先经过Spider Middleware的处理,当Spider处理生成Item和 Request 之后,Item
和Request 还会经过Spider Middlerware 的处理
主要有以下三个作用:
-
Downloader 生成Response 之后,Engine 会将其发送给Spider 进行解析,在Response 发送给Spider之前,
可以借助Spider Middlerware 对Response 进行处理 -
Spider 生成Request 之后会被发送至Engine,然后Request 会被转发到Scheduler,在Request被发送给Engine之前,
可以借助Spider Middlerware 对 Request进行处理 -
Spider 生成Item之后会被发送至Engine,然后Item 会被转发到Item pipeline,在Item 被发送给Engine之前,可以借助
Spider Middlerware 对Item进行处理
框架默认提供的Scrapy Middler:
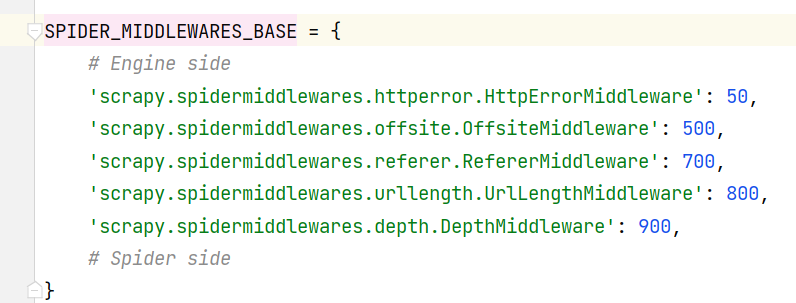
数字越小的Spiddler Middlewre 越靠近Engine,数字越大的越靠近Spider,优先级和 Downloader Middleware一致
每个Spider Middlerware 都定义了以下一个或多个方法的类,核心方法有如下4个
- process_spider_input(response,spider)
- process_spider_output(response,result,spider)
- process_spider_exception(response,exception,spider)
- process_start_requests(start_requests,spider)
只需要实现其中一个方法就可以定义一个Spider Middlerware。
核心方法介绍
- process_spider_input(response,spider)
当Response 通过 Spider Middleware 时,process_spider_input方法被调用,处理该Response。
应该返回None,或者抛出一个异常
-
如果返回None,Scrapy会继续处理该Response,调用其他的Spider Middleware 知道Spider 处理该
Response -
如果它抛出一个异常,Scrapy不会调用任何其他Spider Middleware 的process_spider_input方法,并调用
Request 的errback方法。errback的输出将会以另一个方向被重新输入中间件,使用process_spider_output方法来处理,当
其抛出异常时则调用process_spider_exception来处理
实战
process_start_requests
spider:
import scrapy
from scrapy import Request
from scrapyspidermiddlerwaredemo.items import DemoItem
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['www.httpbin.org']
start_url = 'https://www.httpbin.org/get'
def start_requests(self):
for i in range(5):
url = f'{self.start_url}?query={i}'
yield Request(url, callback=self.parse)
def parse(self, response):
print(response.text)
process_start_requests: 请求spider的初始请求
class CustomizeMiddlerware(object):
def process_start_requests(self, start_requests, spider):
'''
处理start_url
:param start_requests:
:param spider:
:return:
'''
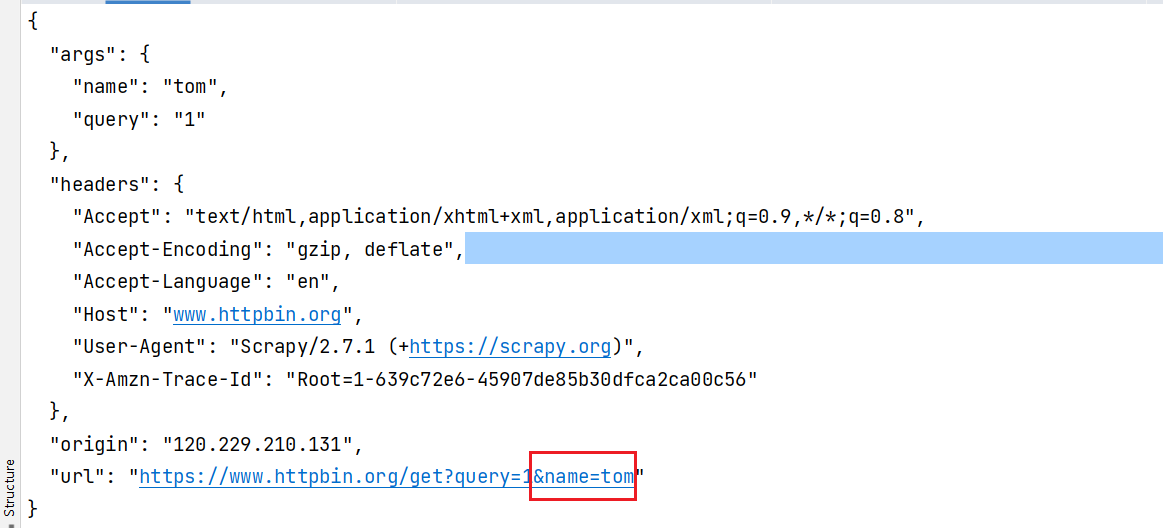
for request in start_requests:
url = request.url
url += '&name=tom'
request = request.replace(url=url)
yield request
输出结果:可以看到请求的url 已被修改
process_spider_input
HttpbinSpider - parse() 方法:
def parse(self, response):
print(f'response status:{response.status}')
print(response.text)
CustomizeMiddlerware - process_start_requests
class CustomizeMiddlerware(object):
def process_start_requests(self, start_requests, spider):
'''
处理spider 开始时的request
:param start_requests:
:param spider:
:return:
'''
for request in start_requests:
url = request.url
url += '&name=tom'
request = request.replace(url=url)
yield request
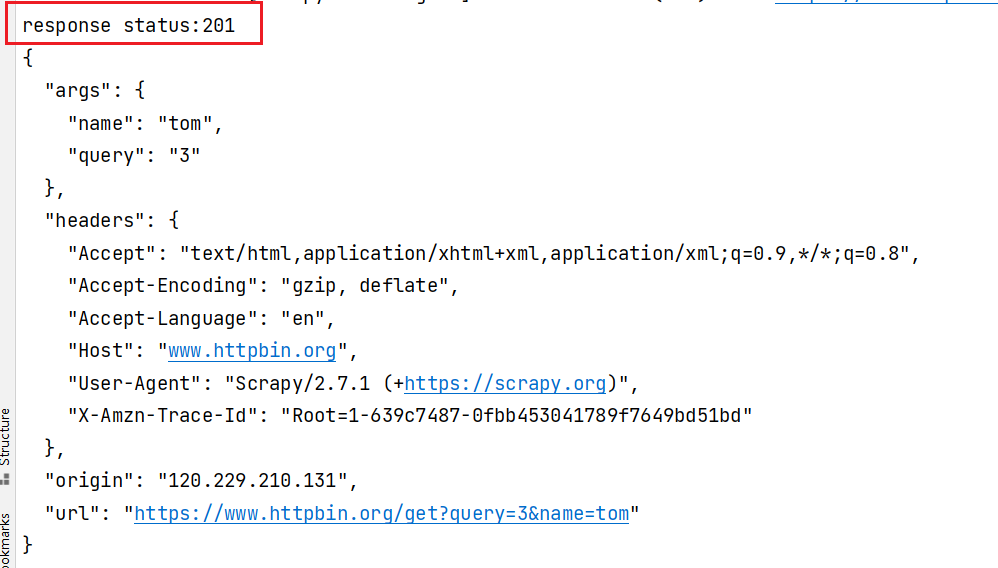
def process_spider_input(self, response, spider):
'''
处理 Response,修改响应码
:return:
'''
response.status = 201
输出结果:可以看到响应状态码已被修改
process_spider_output
parse:
def parse(self, response):
print(f'response status:{response.status}')
item = DemoItem(**response.json())
yield item
CustomizeMiddlerware - process_spider_output:
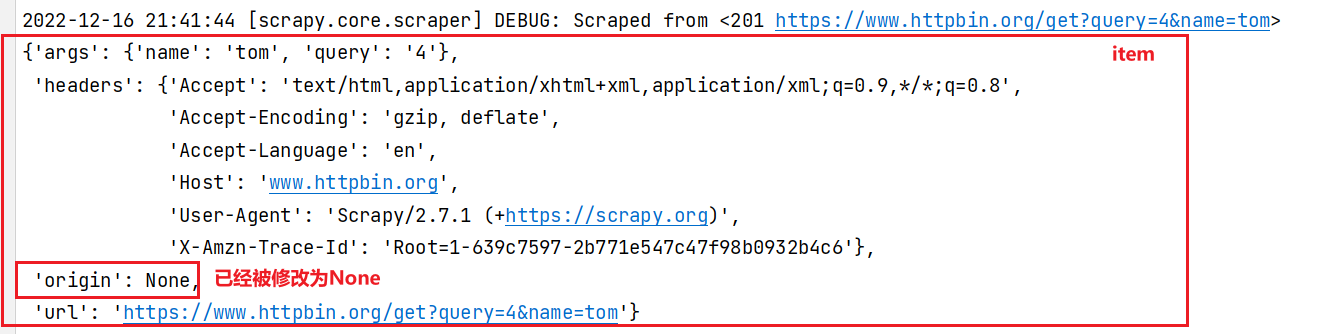
class CustomizeMiddlerware(object):
def process_spider_output(self, response, result, spider):
'''
处理Item对象
:param response:
:param result:
:param spider:
:return:
'''
for i in result:
if isinstance(i, DemoItem):
i['origin'] = None
yield i
输出结果:
本文来自博客园,作者:chuangzhou,转载请注明原文链接:https://www.cnblogs.com/czzz/p/16988344.html

