Elastic Stack (一)
Elastic Stack 简介
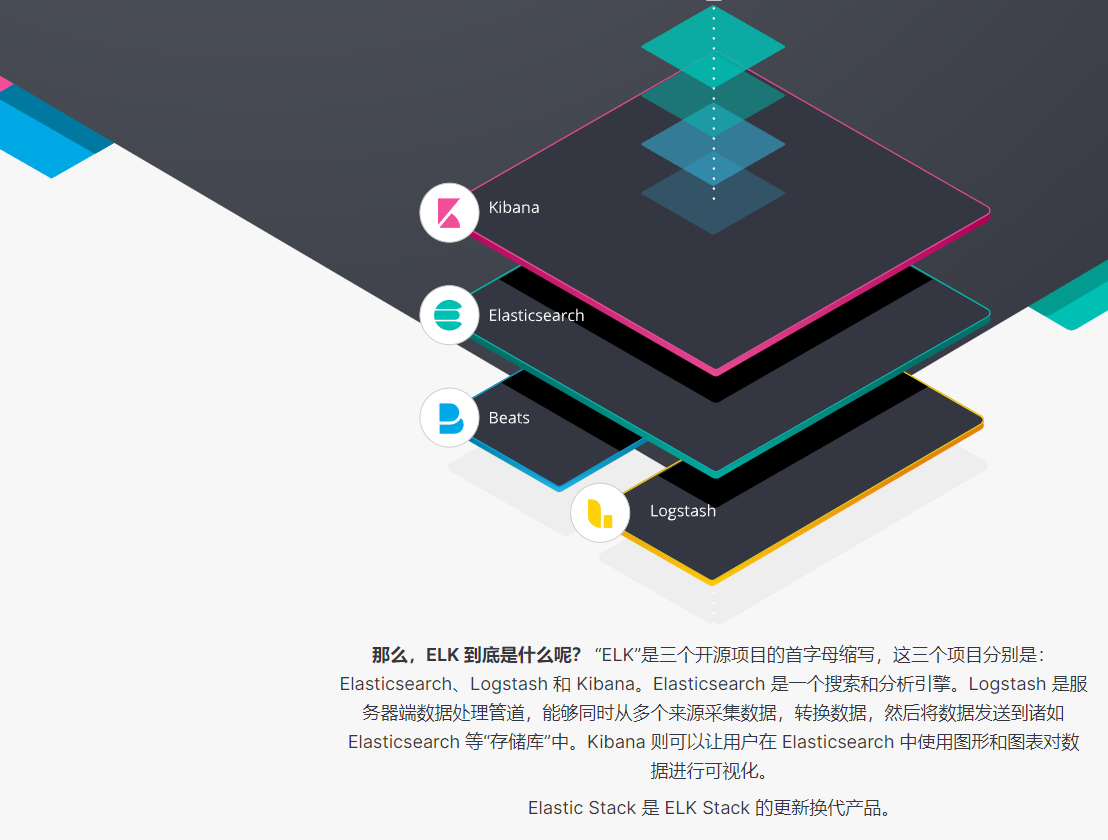
ELK是一个免费开源的日志分析架构技术栈总称,官网https://www.elastic.co/cn。ELK包含但不限于Elasticsearch(简称es)、Logstash、Kibana 三个开源软件的组成的一个整体。是用于数据抽取(Logstash)、搜索分析(Elasticsearch)、数据展现(Kibana)的一整套解决方案,所以也称作ELK stack。
但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据搜索、分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。下面是ELK架构:
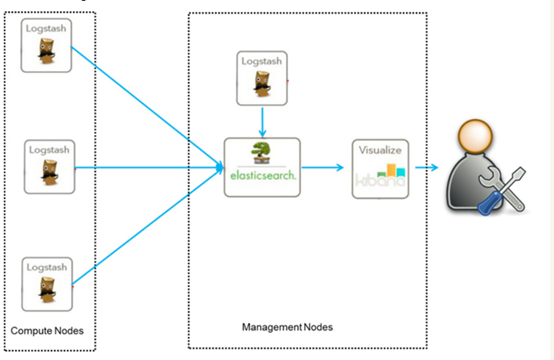
随着elk的发展,又有新成员Beats、elastic cloud的加入,所以就形成了Elastic Stack。所以说,ELK是旧的称呼,Elastic Stack是新的名字。

特色
-
处理方式灵活:elasticsearch是目前最流行的准实时全文检索引擎,具有高速检索大数据的能力。
-
配置简单:安装elk的每个组件,仅需配置每个组件的一个配置文件即可。修改处不多,因为大量参数已经默认配在系统中,修改想要修改的选项即可。
-
接口简单:采用json形式RESTFUL API接受数据并响应,无关语言。
-
性能高效:elasticsearch基于优秀的全文搜索技术Lucene,采用倒排索引,可以轻易地在百亿级别数据量下,搜索出想要的内容,并且是秒级响应。
-
灵活扩展:elasticsearch和logstash都可以根据集群规模线性拓展,elasticsearch内部自动实现集群协作。
-
数据展现华丽:kibana作为前端展现工具,图表华丽,配置简单。
组件介绍
Elasticsearch
Elasticsearch 是使用java开发,基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash
Logstash 基于java开发,是一个数据抽取转化工具。一般工作方式为c/s架构,client端安装在需要收集信息的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch或其他组件上去。
Kibana
Kibana 基于nodejs,也是一个开源和免费的可视化工具。Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以汇总、分析和搜索重要数据日志。
Beats
Beats 平台集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
Elasticsearch和Lucene 的关系
Lucene:最先进、功能最强大的搜索库,直接基于lucene开发,非常复杂,api复杂
Elasticsearch:基于lucene,封装了许多lucene底层功能,提供简单易用的restful api接口和许多语言的客户端,如java的高级客户端(Java High Level REST Client)和底层客户端(Java Low Level REST Client)
Elasticsearch 的 核心概念
倒排索引
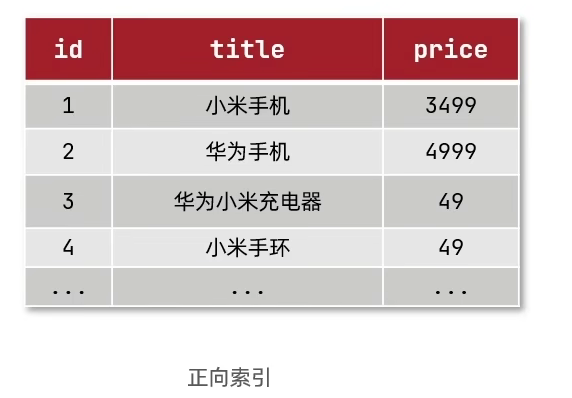
正向索引:
传统数据库(如MySQL)采用正向索引,例如给下表(tb_goods) 中的id创建索引:
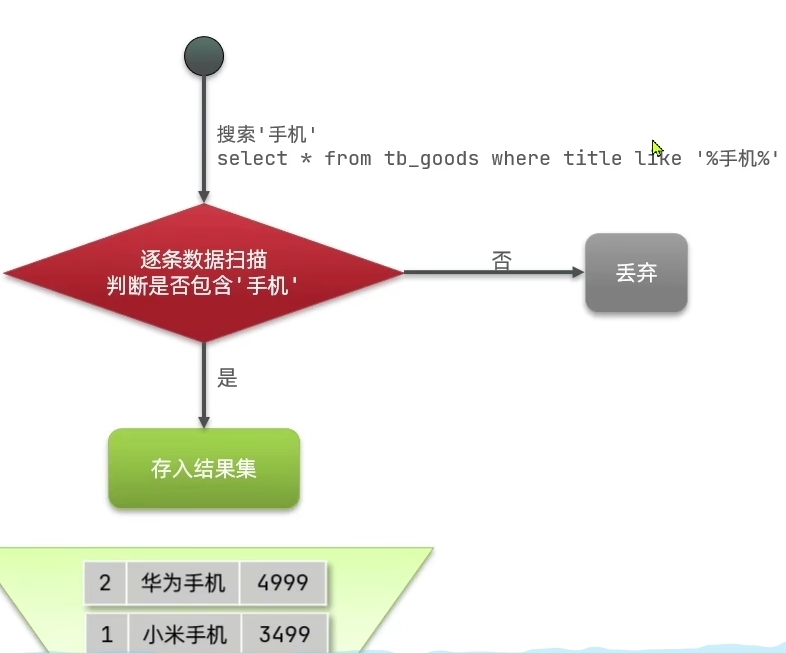
根据字段局部内容做检索的时候效率比较差:
倒排索引:
elasticsearch 采用倒排索引:
- 文档(document):每条数据就是个文档
- 词条(tearm):文档按照语义分成的词语

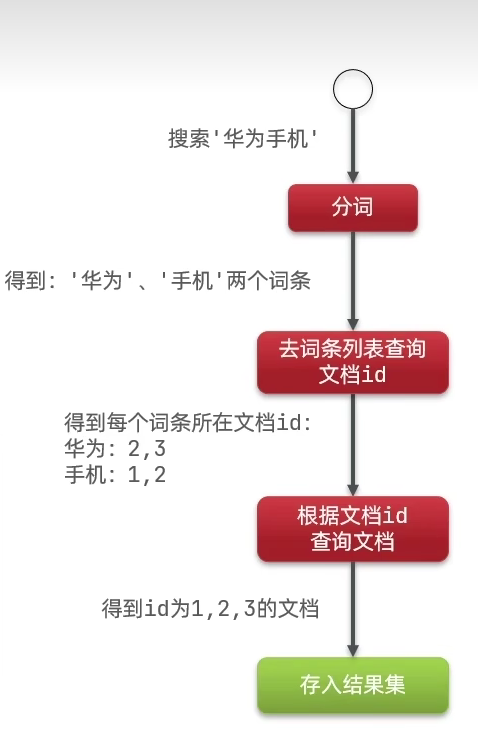
查找过程:
根据词条查找到对应的id
NRT(Near Realtime):近实时
两方面:
-
写入数据时,过1秒才会被搜索到,因为内部在分词、录入索引。
-
es搜索时:搜索和分析数据需要秒级出结果。
Cluster:集群
包含一个或多个启动着es实例的机器群。通常一台机器起一个es实例。同一网络下,集名一样的多个es实例自动组成集群,自动均衡分片等行为。默认集群名为“elasticsearch”。
Node:节点
每个es实例称为一个节点。节点名自动分配,也可以手动配置。
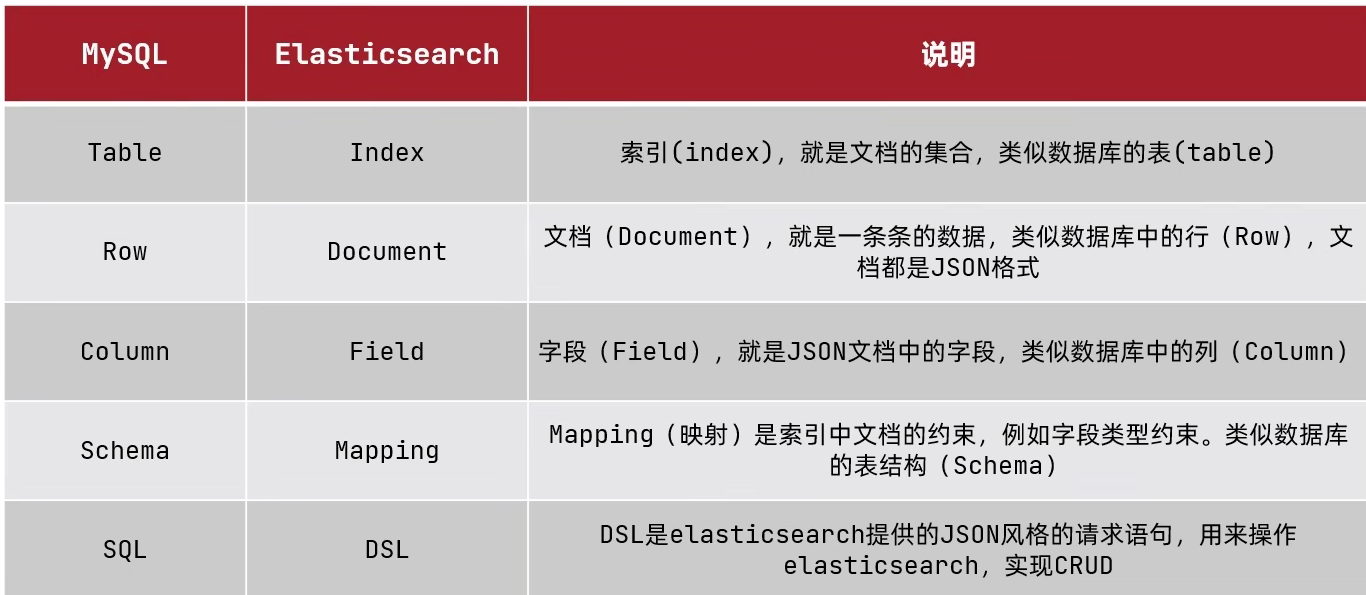
Index:索引
包含一堆有相似结构的文档数据。
索引创建规则:
-
仅限小写字母
-
不能包含\、/、 *、?、"、<、>、|、#以及空格符等特殊符号
-
从7.0版本开始不再包含冒号
-
不能以-、_或+开头
-
不能超过255个字节(注意它是字节,因此多字节字符将计入255个限制)
Document:文档
es中的最小数据单元。一个document就像数据库中的一条记录。通常以json格式显示。多个document存储于一个索引(Index)中。
book document
{
"book_id": "1",
"book_name": "java编程思想",
"book_desc": "从Java的基础语法到最高级特性(深入的[面向对象](https://baike.baidu.com/item/面向对象)概念、多线程、自动项目构建、单元测试和调试等),本书都能逐步指导你轻松掌握。",
"category_id": "2",
"category_name": "java"
}
Field:字段
就像数据库中的列(Columns),定义每个document应该有的字段。
Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field。
注意:6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES官方将在ES9.0版本中彻底删除type。本教程typy都为_doc。
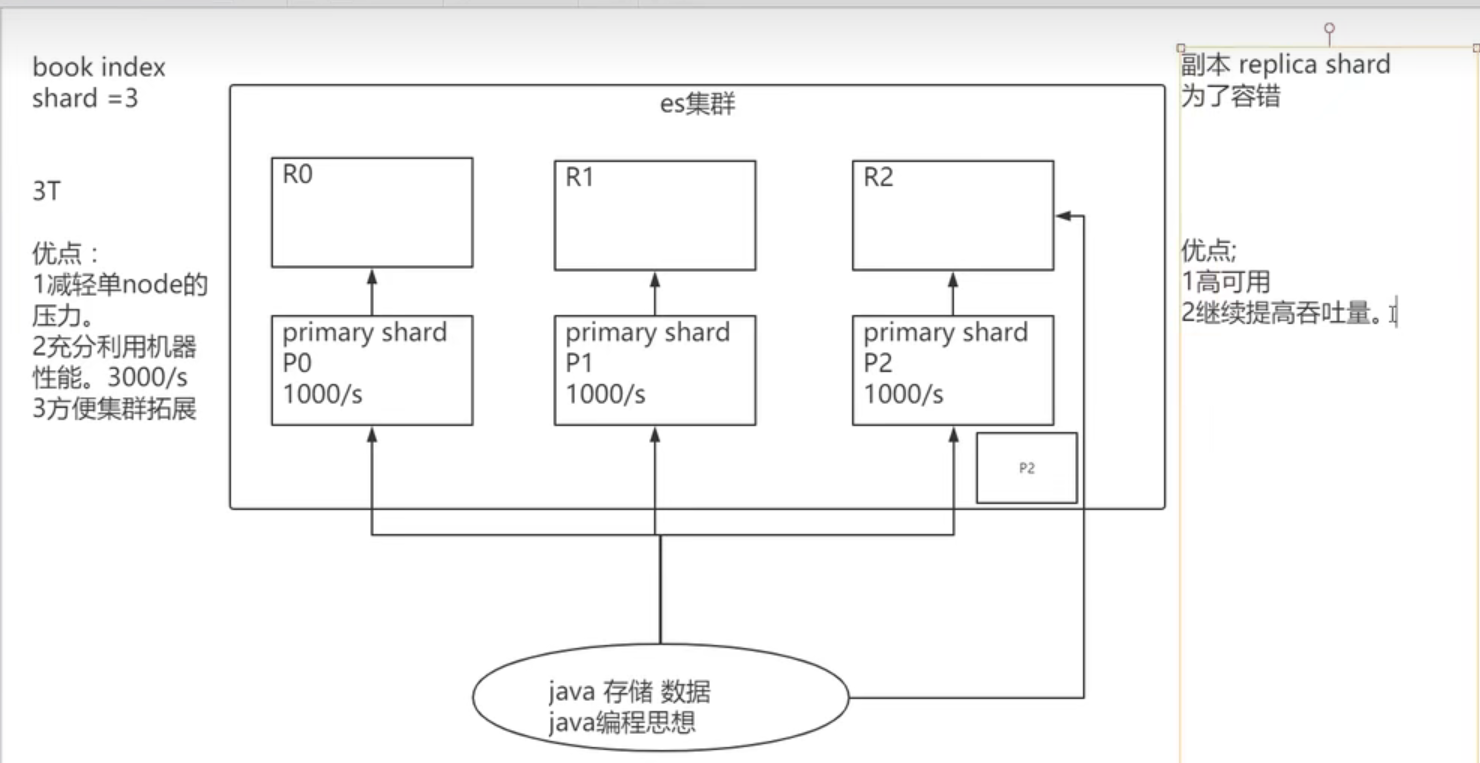
shard:分片
index数据过大时,将index里面的数据,分为多个shard,分布式的存储在各个服务器上面。可以支持海量数据和高并发,提升性能和吞吐量,充分利用多台机器的cpu。
replica:副本
在分布式环境下,任何一台机器都会随时宕机,如果宕机,index的一个分片没有,导致此index不能搜索。所以,为了保证数据的安全,我们会将每个index的分片经行备份,存储在另外的机器上。保证少数机器宕机es集群仍可以搜索。
能正常提供查询和插入的分片我们叫做主分片(primary shard),其余的我们就管他们叫做备份的分片(replica shard)。
Elasticsearch vs. MYSQL
核心概念:
架构:
Mysql: 擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
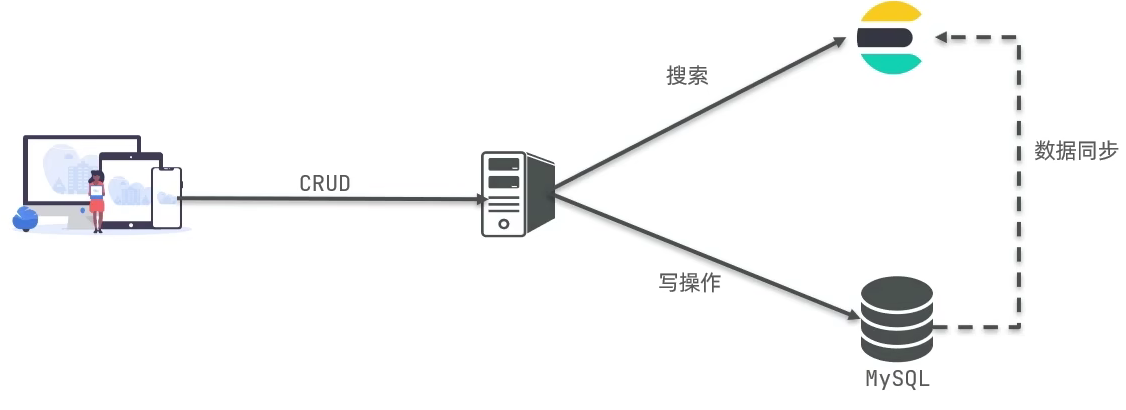
Elasticsearch 快速入门
Windows 搭建环境 - Elasticsearch
运行elasticsearch.bat 出现以下问题:
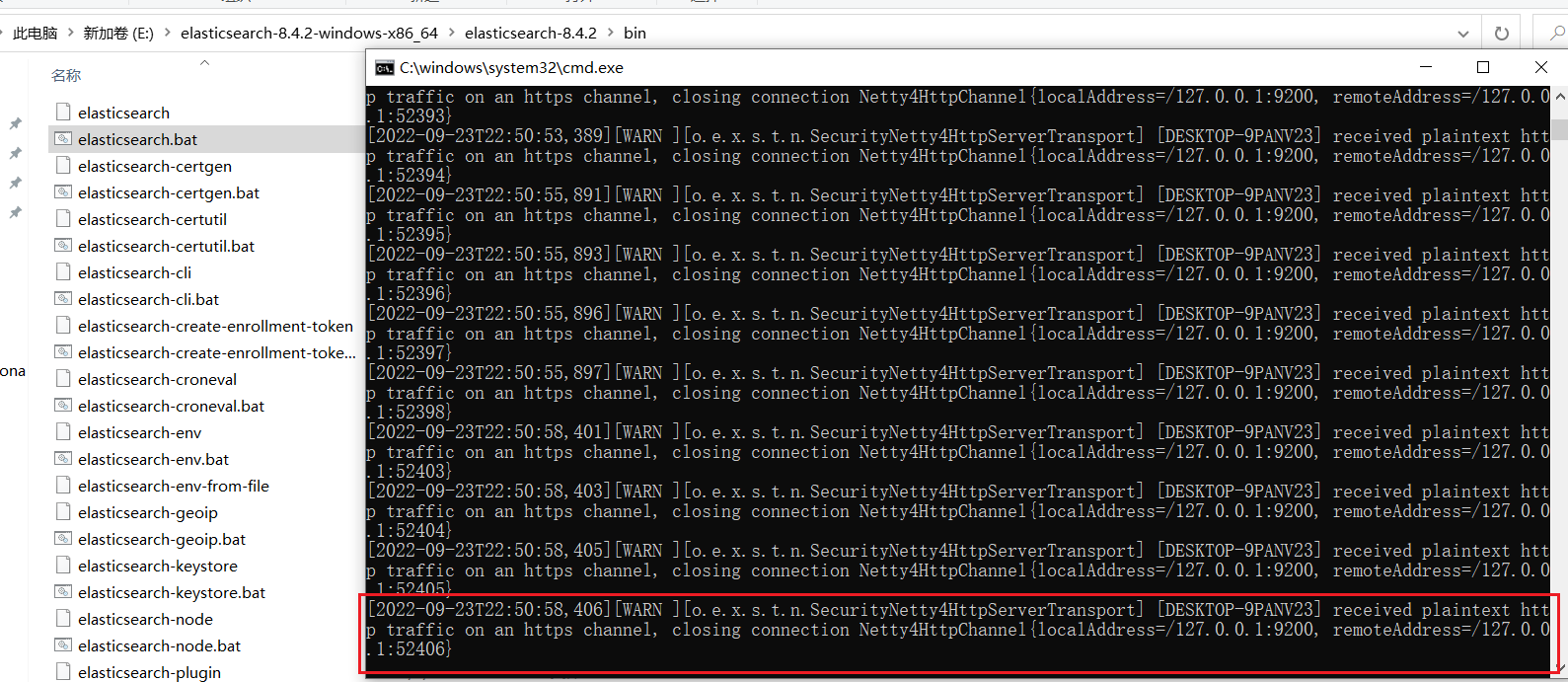
解决:
讲一下配置改为false,默认是true
# Enable security features
xpack.security.enabled: false
地址栏访问:http://localhost:9200/,返回以下信息代表启动成功:
{
"name" : "DESKTOP-9PANV23",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "yoCqdOBGS2SppfEwPXgbMg",
"version" : {
"number" : "8.4.2",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "89f8c6d8429db93b816403ee75e5c270b43a940a",
"build_date" : "2022-09-14T16:26:04.382547801Z",
"build_snapshot" : false,
"lucene_version" : "9.3.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
Windows 搭建环境 - Kibanan
-
下载解压直接运行kibana.bat ,访问
-
访问http://localhost:5601/
文档(document)的数据格式
(1)应用系统的数据结构都是面向对象的,具有复杂的数据结构
(2)对象存储到数据库,需要将关联的复杂对象属性插到另一张表,查询时再拼接起来。
(3)es面向文档,文档中存储的数据结构,与对象一致。所以一个对象可以直接存成一个文档。
(4)es的document用json数据格式来表达。
例如:班级和学生关系
public class Student {
private String id;
private String name;
private String classInfoId;
}
private class ClassInfo {
private String id;
private String className;
。。。。。
}
数据库中要设计所谓的一对多,多对一的两张表,外键等。查询出来时,还要关联,mybatis写映射文件,很繁琐。
而在es中,一个学生存成文档如下:
{
"id":"1",
"name": "张三",
"last_name": "zhang",
"classInfo": {
"id": "1",
"className": "三年二班",
}
}
RESTful API
在Elasticsearch中,提供了功能丰富的RESTful API的操作,包括基本的CRUD、创建索引、删除索引等操作。
快速检查集群的健康状况
GET _cat/health?v

如何快速了解集群的健康状况?
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
创建空索引
POST /book
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "book"
}
删除索引
DELETE /book
{
"acknowledged": true
}
插入数据
URL规则: POST /{索引}/{类型}/
PUT/POST /book/_doc/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price":38.6,
"timestamp":"2019-08-25 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "bootstrap", "dev"]
}
返回:
{
"_index": "book",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
查询索引
语法:GET /{索引}/{类型}/
GET /book/_doc/1
返回:
{
"_index": "book",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "Bootstrap开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price": 38.6,
"timestamp": "2019-08-25 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"bootstrap",
"dev"
]
}
}
局部更新数据
在Elasticsearch中,文档数据是不为修改的,但是可以通过覆盖的方式进行更新。
语法:POST /{index}/_update/
POST /book/_update/1/
{
"doc": {
"name": " Bootstrap开发教程高级"
}
}
返回:
{
"_index": "book",
"_id": "1",
"_version": 2, => 版本加1
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
Kibanan 中查看索引
在Discover 面板中创建一个 data view
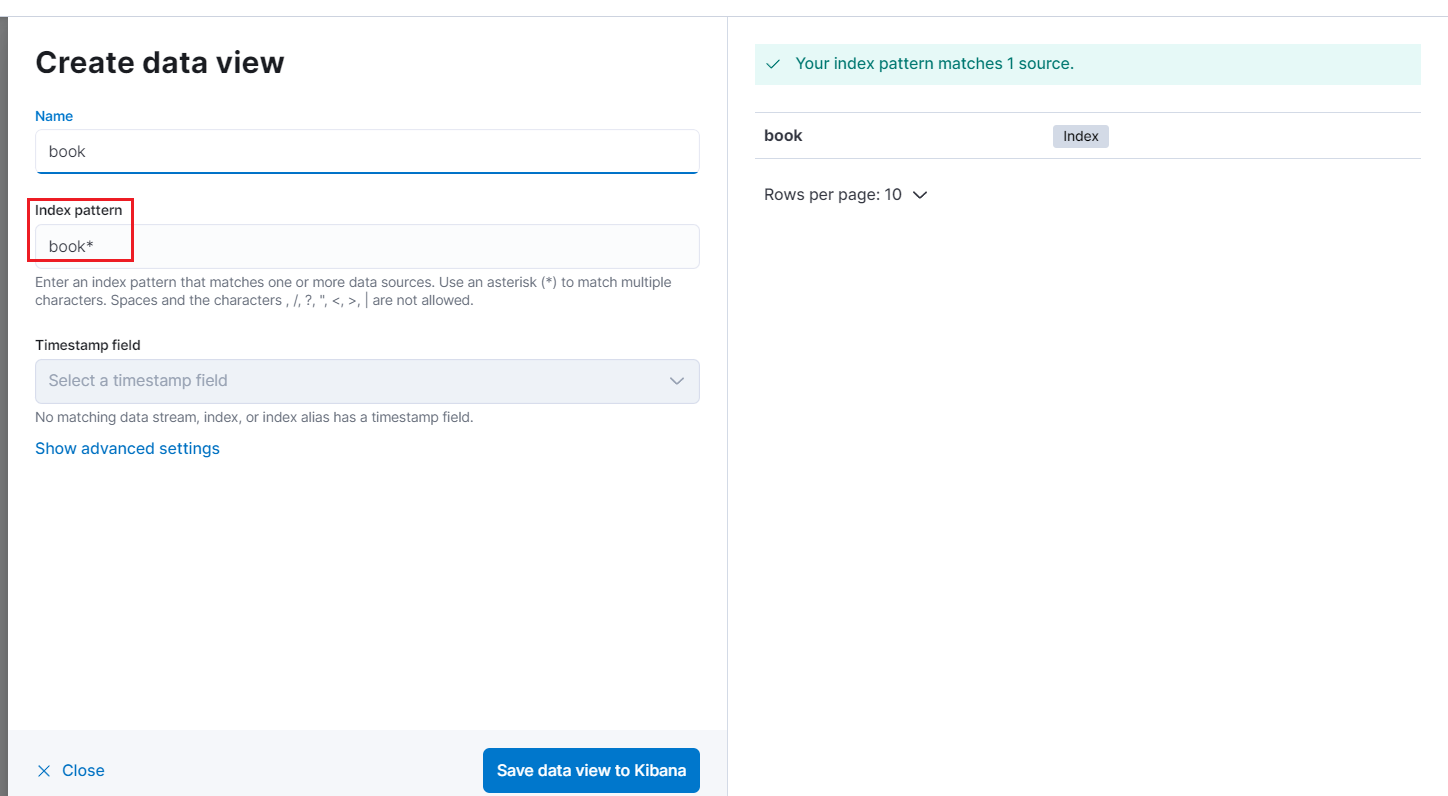
创建完毕后便可以看到匹配到所有book开头的索引的document
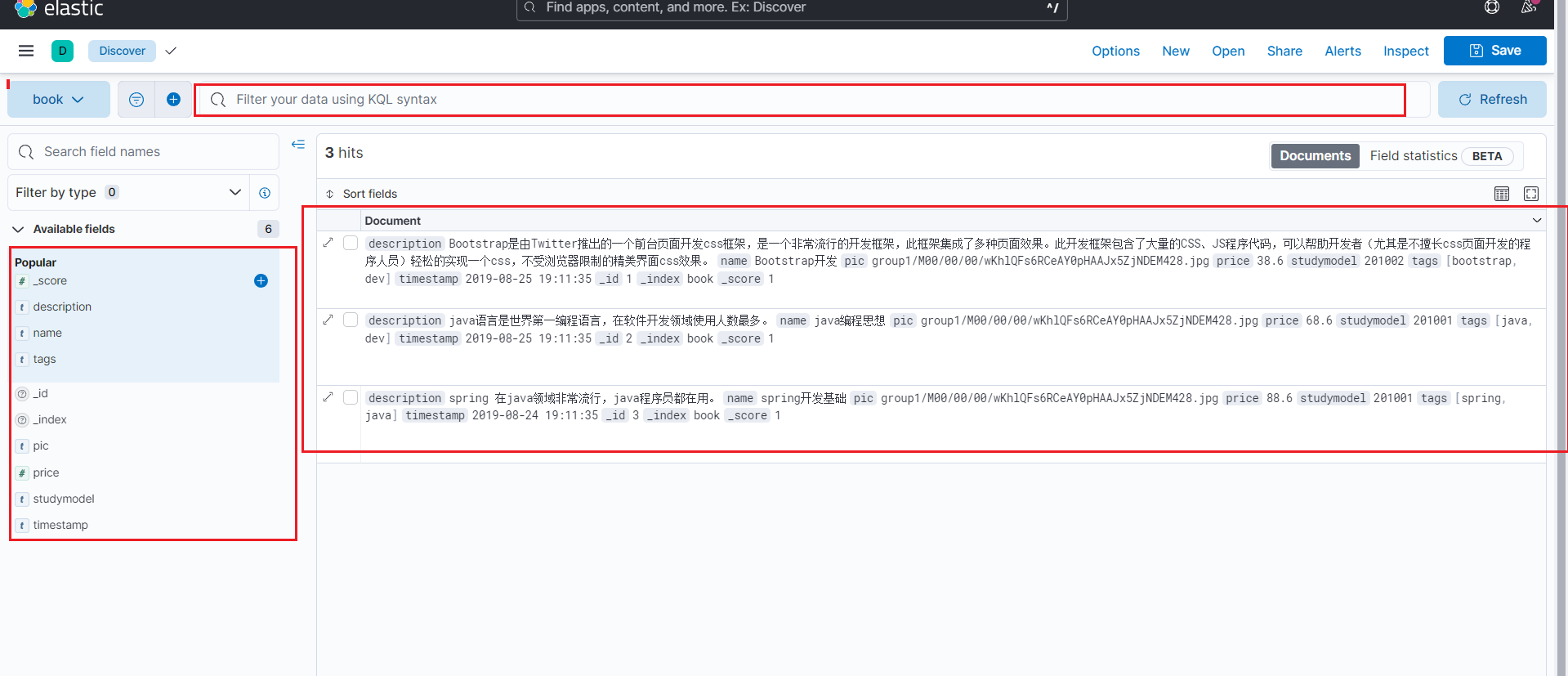
Document 入门
_index
- 含义:此文档属于哪个索引
- 原则:类似数据放在一个索引中。数据库中表的定义规则。如图书信息放在book索引中,员工信息放在employee索引中。各个索引存储和搜索时互不影响。
- 定义规则:英文小写。尽量不要使用特殊字符。order user
_type
- 含义:类别。book java node
- 注意:以后的es9将彻底删除此字段,所以当前版本在不断弱化type。不需要关注。见到_type都为doc。
_id
-
含义:文档的唯一标识。就像表的id主键。结合索引可以标识和定义一个文档。
-
生成:手动(put /index/_doc/id)、自动
生成文档id 的两种方式
- 手动
场景:数据从其他系统导入时,本身有唯一主键。如数据库中的图书、员工信息等。
用法:put /{index}/_doc/{id}
PUT /test_index/_doc/1
{
"test_field": "test"
}
- 自动
用法: POST /{index}/_doc
自动id特点:长度为20个字符,URL安全,base64编码,GUID,分布式生成不冲突
POST /test_index/_doc
{
"test_filed":"abc"
}
返回:
{
"_index": "test_index",
"_id": "eEZtbYMBoa2T73yXVPlu",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
_source
GET 请求返回的JSON数据中都包含有一个_source字段,该字段有什么用?
含义:储存插入数据时的所有字段和值。在get获取数据时,在_source字段中原样返回。
也可以定制返回字段,就像sql不要select *,而要select name,price from book …一样。
GET /book/_doc/1?_source_includes=name,price
观察_source的返回,只有name和price的返回
{
"_index": "book",
"_id": "1",
"_version": 3,
"_seq_no": 4,
"_primary_term": 1,
"found": true,
"_source": {
"name": " Bootstrap开发教程高级22222",
"price": 38.6
}
}
全量替换
执行两次,返回结果中版本号(_version)在不断上升,result 由create变为update 的过程为全量替换。
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。
执行第一次:
PUT /test_index/_doc/1
{
"test_filed":"aaaa"
}
返回:
{
"_index": "test_index",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1
}
执行第二次返回:
{
"_index": "test_index",
"_id": "1",
"_version": 2,
"result": "updated", <= 变为update
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1
}
强制创建
为防止覆盖原有数据,我们在新增时,设置为强制创建,则在之后再次创建时会报错,不会创建成功
语法:PUT /{index}/_doc/{id}/_create
PUT /test_index/_doc/1/_create
{
"test_field": "test"
}
返回:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[2]: version conflict, document already exists (current version [1])",
"index_uuid": "lqzVqxZLQuCnd6LYtZsMkg",
"shard": "0",
"index": "test_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[2]: version conflict, document already exists (current version [1])",
"index_uuid": "lqzVqxZLQuCnd6LYtZsMkg",
"shard": "0",
"index": "test_index"
},
"status": 409
}
删除文档
语法:DELETE /{index}/_doc/
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。lazy delete
全量更新和局部更新的区别
局部更新即: POST /{index}/_update/{id}/
内部与全量替换是一样的,旧文档标记为删除,新建一个文档。
优点:
- 大大减少网络传输次数和流量,提升性能
- 减少并发冲突发生的概率。
ES内部机制
shard & replica 机制
(1)每个index包含一个或多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是1,replica默认是1,默认共有2个shard,1个primary shard,1个replica shard
注意:es7以前primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
单节点创建index
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index1
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
数据路由
一个文档,最终会落在主分片的一个分片上,到底应该在哪一个分片?这就是数据路由。
路由算法:
哈希值对主分片数取模: shard = hash(routing) % number_of_primary_shards
举例:
对一个文档经行crud时,都会带一个路由值 routing number。默认为文档_id(可能是手动指定,也可能是自动生成)。
存储1号文档,经过哈希计算,哈希值为2,此索引有3个主分片,那么计算2%3=2,就算出此文档在P2分片上。
决定一个document在哪个shard上,最重要的一个值就是routing值,默认是_id,也可以手动指定,相同的routing值,每次过来,从hash函数中,产出的hash值一定是相同的
无论hash值是几,无论是什么数字,对number_of_primary_shards求余数,结果一定是在0~number_of_primary_shards-1之间这个范围内的。0,1,2。
涉及到以往数据的查询搜索,所以一旦建立索引,主分片数不可变。
文档增删改的内部流程
增删改可以看做update,都是对数据的改动。一个改动请求发送到es集群,经历以下四个步骤:
(1)客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
(2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
(3)实际的node上的primary shard处理请求,然后将数据同步到replica node。
(4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端。
文档查询的内部机制
1、客户端发送请求到任意一个node,成为coordinate node
2、coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
3、接收请求的node返回document给coordinate node
4、coordinate node返回document给客户端
5、特殊情况:document如果还在建立索引过程中,可能只有primary shard有,任何一个replica shard都没有,此时可能会导致无法读取到document,但是document完成索引建立之后,primary shard和replica shard就都有了。
本文来自博客园,作者:chuangzhou,转载请注明原文链接:https://www.cnblogs.com/czzz/p/16724381.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号