第一次个人编程作业
1、Github地址:
2、PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 70 | 60 |
| Estimate | 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | 450 | 300 |
| Analysis | 需求分析 (包括学习新技术) | 600 | 750 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 60 | 30 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 60 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 350 | 350 |
| Reporting | 报告 | -- | -- |
| Test Report | 测试报告 | -- | -- |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 1840 | 1780 |
3、计算模块接口的设计与实现过程
-
(1)解题思路:
- 第一步:将文本通过命令行参数读入;
- 第二步:将文本内容转化为字符串存下(可以在这里把标点,空格去掉);
- 第三步:关键的来了,百度求 相似度算法;通过合适的来求解;我刚刚开始采用余弦定理,计算两个句子向量 如:
句子A:我喜欢晚上吃面条,喜欢中午吃米饭;
句子B:我不喜欢晚上吃面条,我们不合适;
我们可以提取每个字的出现次数(可以用map来存下)句子A:(1,2,2,1,1,2,1,1,1,1,1,1);句子B:(2,2,1,1,1,1,1,1,1,1,1,1)通过它们的向量余弦值来确定两个句子的相似度,但文本长的时候准确率不够(后面我才知道可以用词频来优化)。 - 最终我选择最小编辑距离算法,点这里;是指利用字符操作,把字符串A转换成字符串B所需要的最少操作数。其中,字符操作包括:删除一个字符,插入一个字符,修改一个字符。我们只要求出最小编辑距离,最后得相似度就是1-最小编辑距离/两句中更长的长度。
- 第四步:将答案输出到文本。
-
(2)我的内心:
- 刚看到题目就蒙了,论文查重算法,这是啥呀!脑子里想到的是NLP(自然语言处理);天哪,这么怎么做,
杀了我吧!。不知所措后再慢慢看要求,顿时感觉要当场去世。后面认真的思考下,NLP我是不知道从哪入手,但是论文查重不就 == 字符串相似度吗。至于那些要求慢慢一步步来,去年学了一些java,用上了。百度搜了一下求相似度算法,首选余弦定理,以前学过比较好理解,后面长文本时准确度低放弃了,又百度到了最小编辑距离算法,还不错,就它了。命令行参数输入,文本输出,文本内容装换字符串,单元测试,性能分析,全部不会。。。统统百度学习。面向百度的编程。 -
(3)流程图:
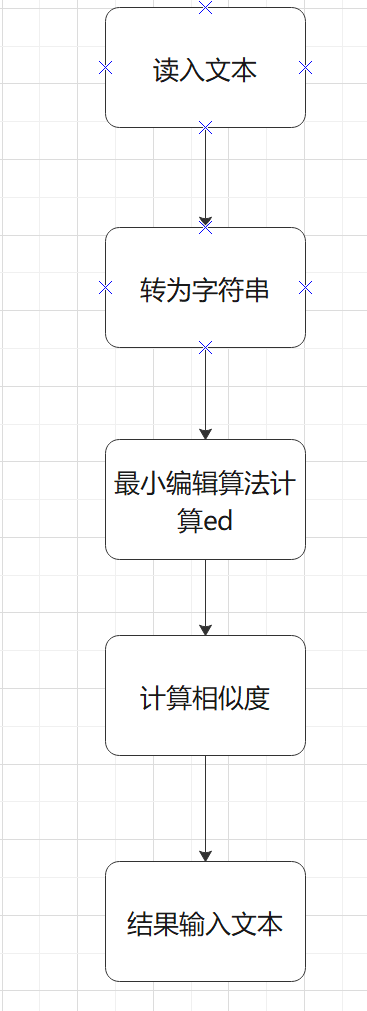
-
(4)核心代码实现:
可以在短文本时使用余弦定理
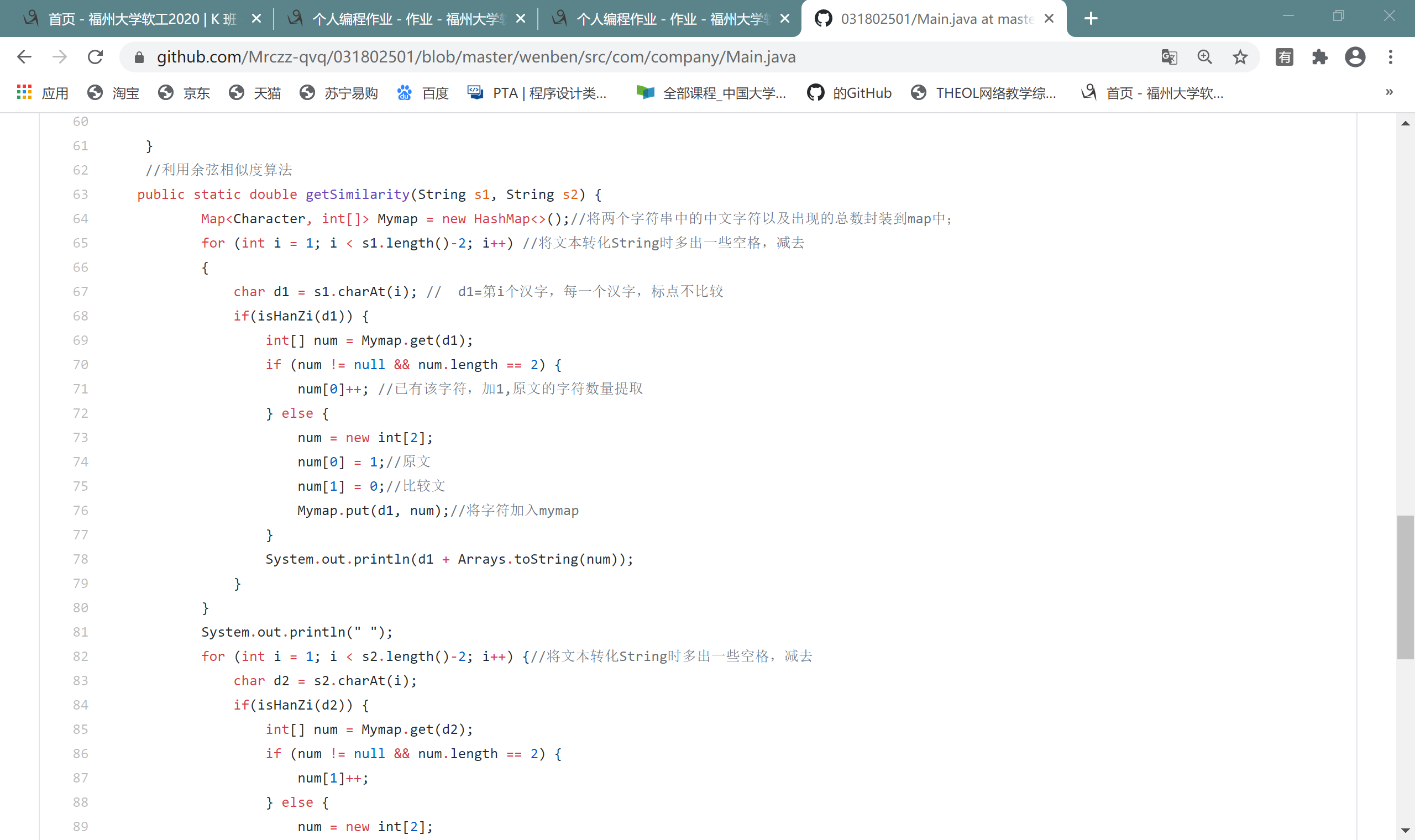
长文本时,我是先用递归实现最小编辑距离,堆栈溢出了。。。

后面改用动态规划的方法。
public static int getEd(String str1, String str2, int l1, int l2) {//动态规划求最小编辑距离
int Distance = 0;
int ed = 0;
if (l1 != 0 && l2 != 0) {
int[][] Distance_shuzu = new int[l1 + 1][l2 + 1];
//编号
int Bianhao = 0;
for (int i = 0; i <= l1; i++) {//初始化,给每个字符编号
Distance_shuzu[i][0] = Bianhao;
Bianhao++;
}
Bianhao = 0;
for (int i = 0; i <= l2; i++) {
Distance_shuzu[0][i] = Bianhao;
Bianhao++;
}
char[] Str1_CharArray = str1.toCharArray();
char[] Str2_CharArray = str2.toCharArray();
for (int i = 1; i <= l1; i++) {
for (int j = 1; j <= l2; j++) {
if (Str1_CharArray[i - 1] == Str2_CharArray[j - 1]) {//相同不变
Distance = 0;
} else {
Distance = 1;
}
int Temp1 = Distance_shuzu[i - 1][j] + 1;//增
int Temp2 = Distance_shuzu[i][j - 1] + 1;//减
int Temp3 = Distance_shuzu[i - 1][j - 1] + Distance;//改
Distance_shuzu[i][j] = Math.min(Temp1, Temp2);//找最小的一步
Distance_shuzu[i][j] = Math.min(Temp3, Distance_shuzu[i][j]);
}
}
ed = Distance_shuzu[l1][l2];
}
return ed;
}
-
(5)所用的类

4、 计算模块接口部分的性能改进:
-
内存消耗
int数组消耗了大量的空间
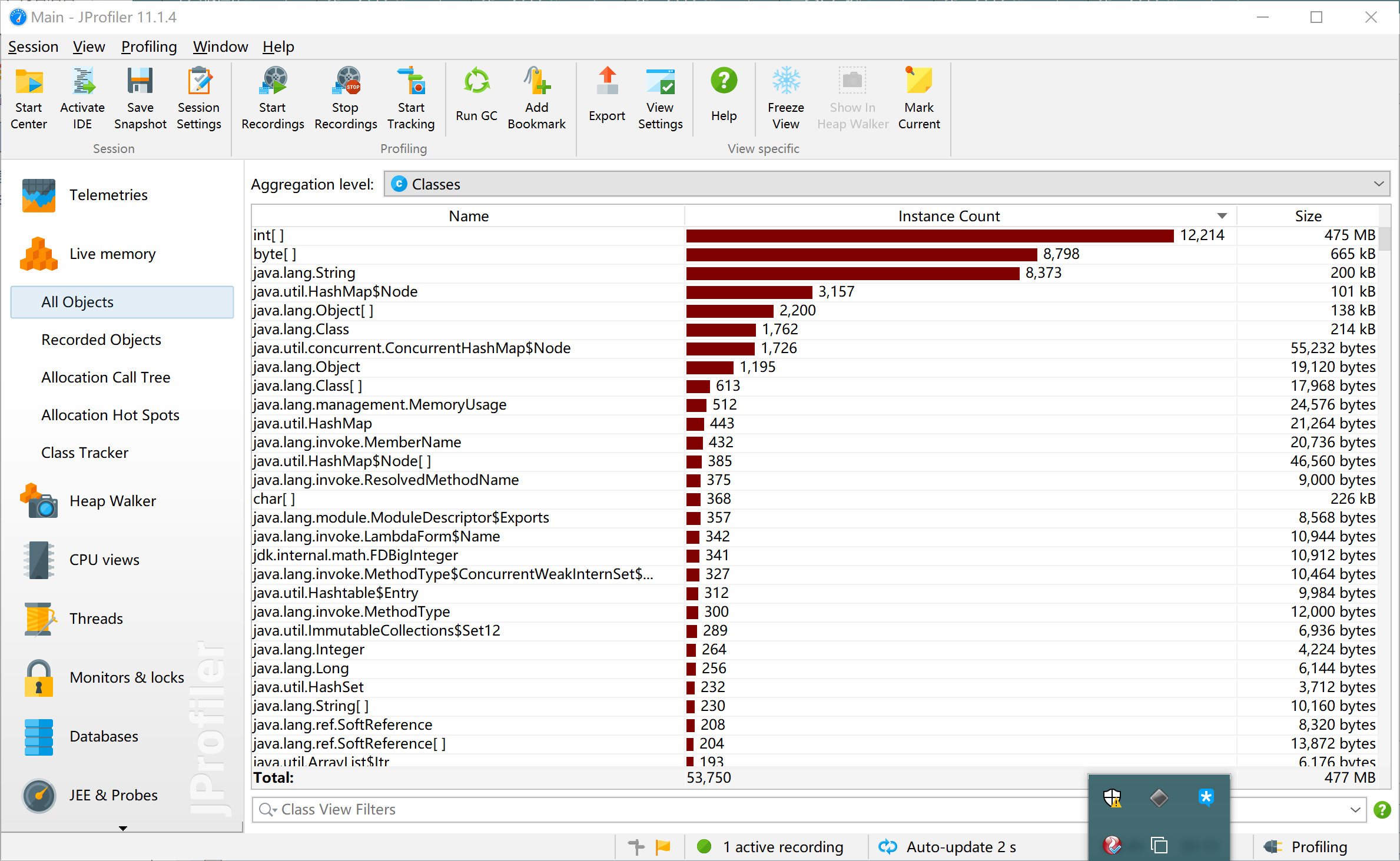
-
overview
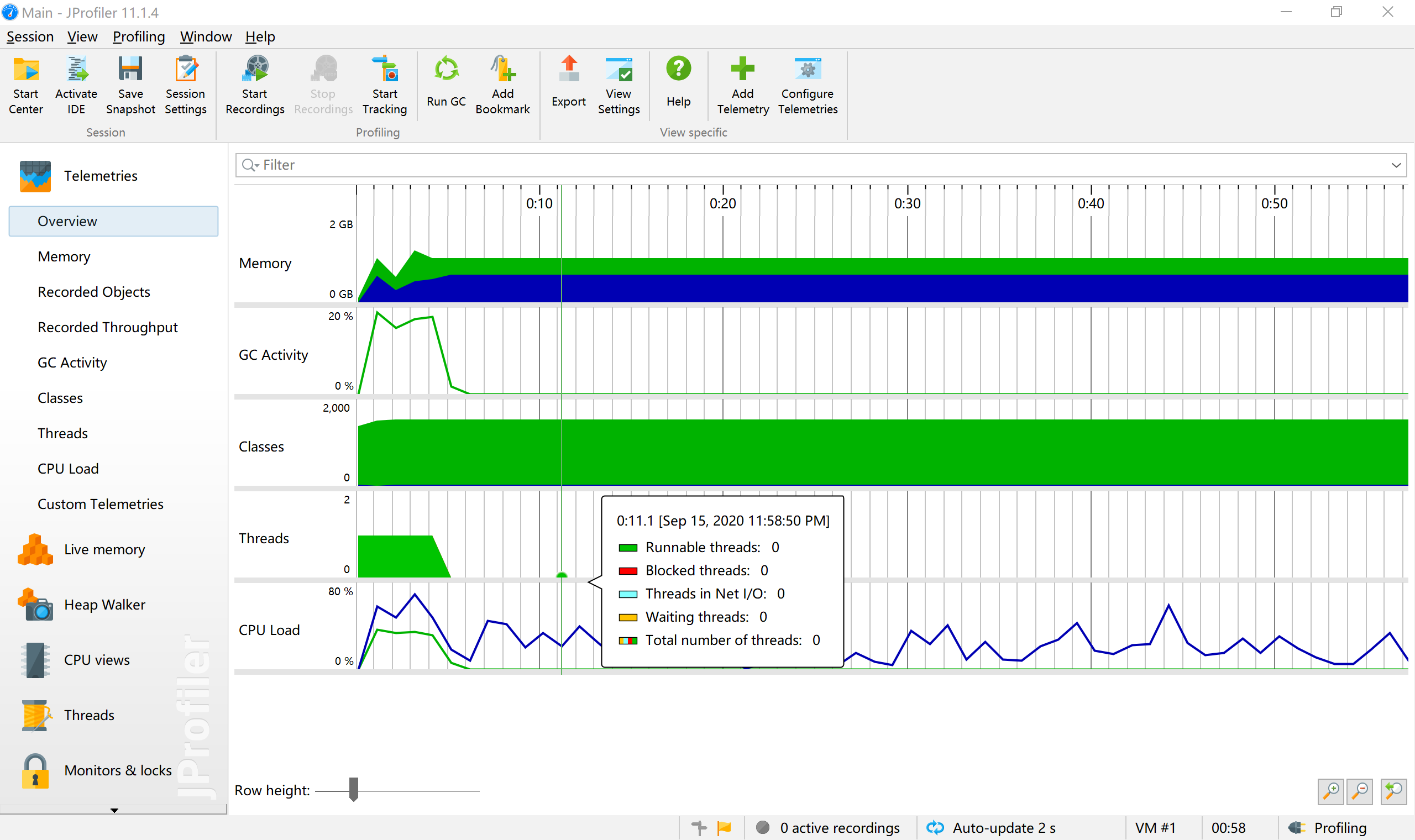
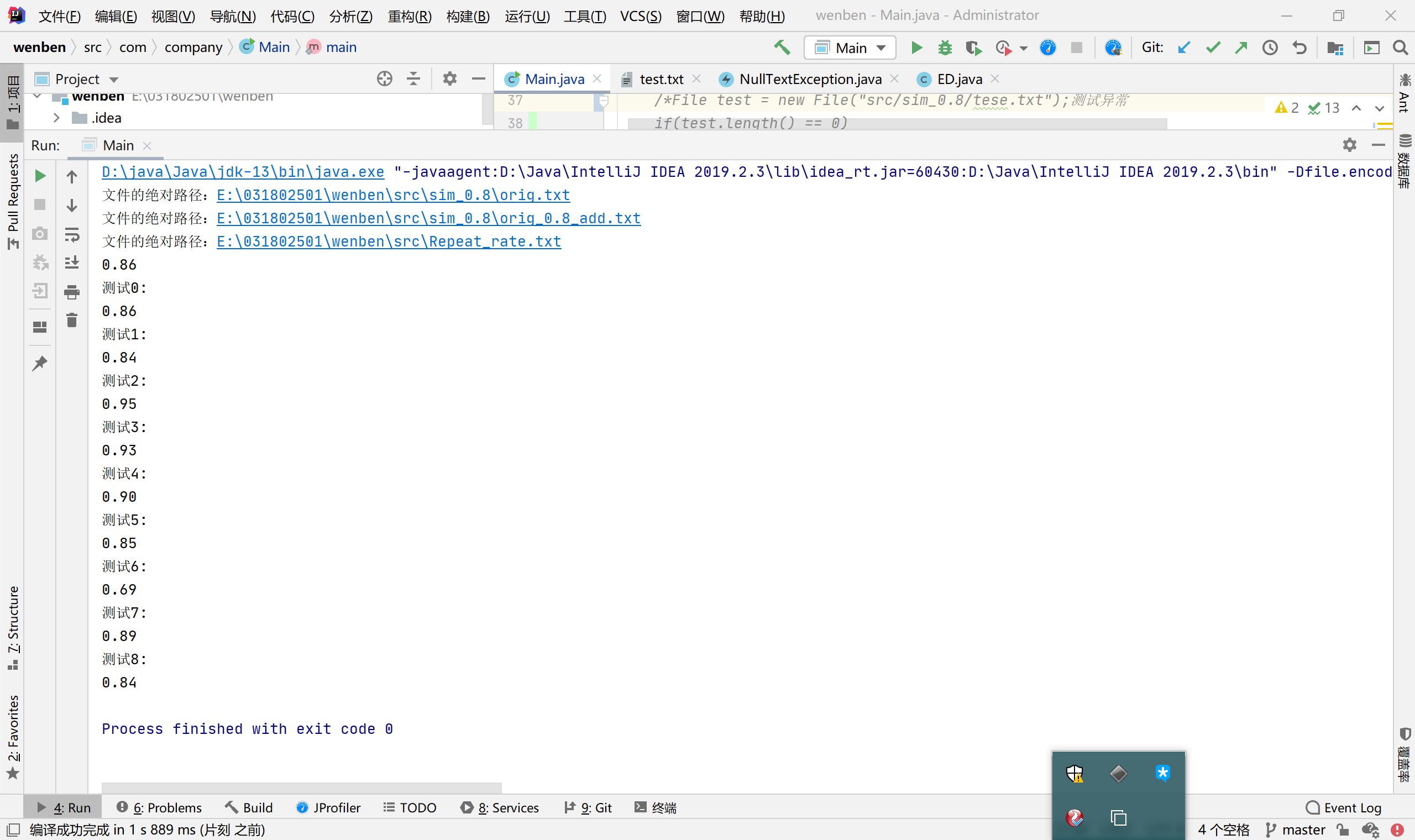
5、计算模块部分单元测试展示。
- 测试代码
@org.junit.Test
public static void testEd(){
String [] testNames = new String[]{
"src/sim_0.8/orig_0.8_add.txt",
"src/sim_0.8/orig_0.8_del.txt",
"src/sim_0.8/orig_0.8_dis_1.txt",
"src/sim_0.8/orig_0.8_dis_3.txt",
"src/sim_0.8/orig_0.8_dis_7.txt",
"src/sim_0.8/orig_0.8_dis_10.txt",
"src/sim_0.8/orig_0.8_dis_15.txt",
"src/sim_0.8/orig_0.8_mix.txt",
"src/sim_0.8/orig_0.8_rep.txt"
};
for (int i=0;i<testNames.length;i++) {
System.out.println("测试"+i+':');
double ans = Test.test(testNames[i]);
Assert.assertEquals(0.8,ans,0.2);
}
}
-
测试结果
-
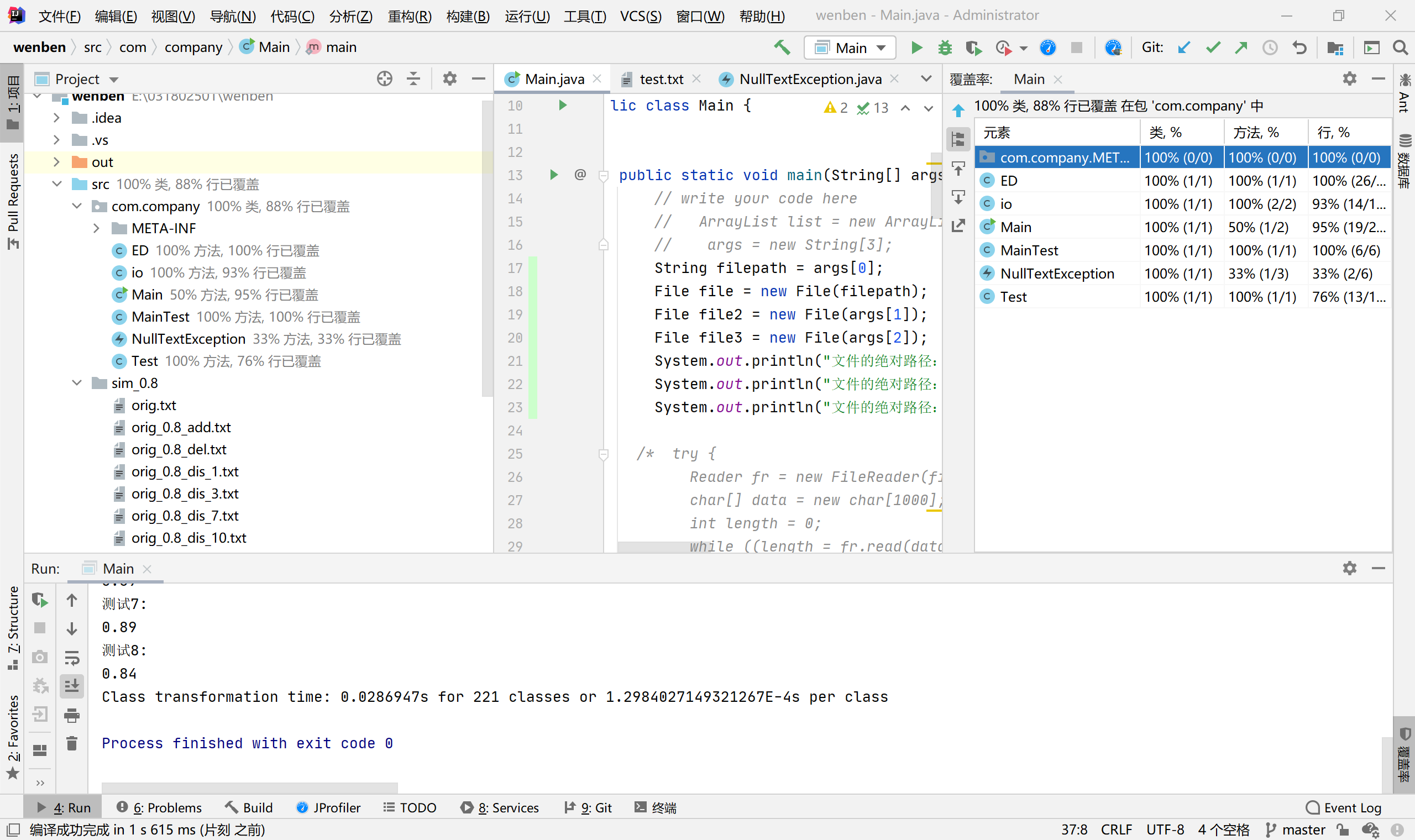
覆盖率
100%覆盖
6、计算模块部分异常处理说明
设计了一个空文本异常类
public class NullTextException extends IOException {
public NullTextException(String message){
super(message);
}
public NullTextException(String message,Throwable cause){
super(message,cause);
}
public NullTextException(Throwable cause){
super(cause);
}
}
测试一下
File test = new File("src/sim_0.8/tese.txt");测试异常
if(test.length() == 0)
try {
throw new NullTextException("null text");
}catch (NullTextException e){
e.printStackTrace();
}

7、总结
天啊,终于完了!!!第一次编程作业让我充分的感受到了学习的痛并快乐着。但缺少学到了很多,从刚开始的一脸懵逼到一步步深入学习,寻找算法,安装jprofile查看性能,Junit单元测试,命令行参数导入,文本转化,都是学习的成果。感谢百度。不枉费我浏览器的几十个窗口。但还是有很多东西不会,优化性能不懂,jprofile也有问题,单元测试也没搞太懂。
要学的东西还很多,但还是希望下一次作业能放过我,头发都要掉光了 😢
“道阻且长,行则将至”
