
编译原理-垃圾回收
一、垃圾回收的几种方式
1、手动delete内存的方式回收垃圾
2、通过引用计数的方式,常见的有:ARC、智能指针
3、通过可达性的方式
二、编译原理主要讲述的是通过可达性的方式
这里有几种算法来进行垃圾回收
1、标记 清扫的垃圾回收方式
思想是:通过根集遍历所有能够 达到的空间进行标记,其他未被标记的空间则被标记为不可达(不可达则为free的空间)
这个算法有个特点是 :1、遍历的过程中如果增变者在节点A已经扫描完之后再增加A的子节点B,那么就会出现B被额外删除的情况;2、在清扫阶段都要遍历所有的堆区,导致时间消耗会很长
如上是标记清扫的算法,从根集出发标记能访问到的所有对象然后遍历所有的内存对象将无标记的对象设置为free;
假设A已经被设为可达并且已经从Unscanned列表中删除,此时增变者创建了一个对象B被A引用那么在清扫阶段则会被删除从而造成误删的情况
2、对标记清扫的优化
思想是:在创建对象的时候将该对象设为unreashed, 在标记阶段把扫描到的对象都从unreached中移除,在清扫 阶段则 Free=Free U unreached; 然后将扫描到的对象复制给unreached
这个算法优化了第一点中的清扫阶段消耗时间长的问题

一共有3个容器:scanned、unscanned、unreached
初始化的时候,将所有的元素均放入unreached中,然后将根集的集合从unreached移到unscanned中
一直循环遍历unscanned容器中的元素,被遍历到的元素则从unscanned移到scanned中
假设当前遍历到的元素为o,将引用该元素o并且在unreached中的元素移到unscanned中,然后继续遍历下一个unscanned容器中的元素
如上是标记清扫的优化,假设当前已经申请的对象已经都记录在了unreached, 那么最终标记完之后剩余的unreached对应一定是垃圾
第九行把扫描到的赋值给unreached使之能够用在在下一轮的清扫中
3、标记压缩的垃圾回收器
如上的算法上面在进行多次标记清扫之后可能会产生很多的碎片,为了减少碎片我们需要将可达的对象尽可能的放在一起
思想是:先对可达的对象进行标记,然后假设整个堆是空的,从低到高顺序遍历每个可达的对象并使用一个表记录这些可达对象所在的堆区位置并将即将分配给该可达对象的新的地址位置,在记录表完成之后;再次从低端开始拷贝每个对象到新的地址

如上8~12行所示是为了建立一张表用来记录从旧的位置到新的位置的映射,这一步只是建表无实际的拷贝操作
如上13~17行所示,先将对象中的引用设置为映射表中新的位置,然后将旧的对象全部拷贝到新的位置;这里是按顺序从低端开始遍历并且新的堆区在映射表中也是从低端开始分配,所以不会出现还未拷贝的对象被覆盖的现象
因为根集没有参与重新映射,所以只需要把根集中的每个引用设置一下即可
4、拷贝垃圾回收
拷贝垃圾回收跟标记压缩的垃圾回收思路差不多,都是为了集簇内存并减少内存碎片
思想:将存储空间分为from和to两个堆区其中to这个空间是全部空闲的堆区;垃圾回收的时候将from标记的堆区拷贝到t堆区。然后将from和to进行互换则在下一轮的回收中to依旧是全部空闲
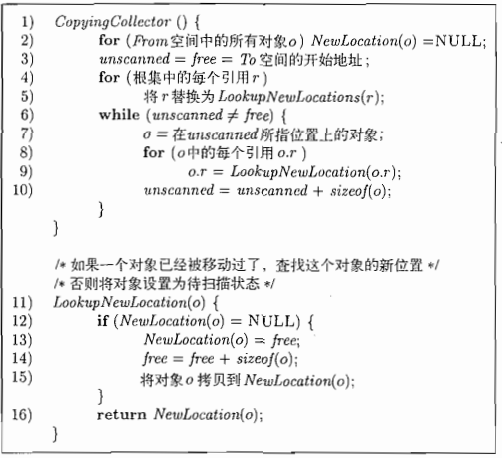
先介绍LookupNewLocation这个函数,这个函数是为了映射from中的对象在to中的分配位置,如果当前的对象还未在to中有对应的位置则分配一个从当前free开始的对象大小的区域给该对象
CopyingCollecter函数是为了将from中的可达对象复制到to中
第二行的初始化操作是因为所有的对象映射位置都保存在一个类似哈希表中,如果不进行清空则会出现在LookupNewLocation中总是能找到该对象的映射而无需对该对象重新分配to的堆区
4~5行类似于标记压缩的垃圾回收的第18~19行,将根集的引用重定位并将根集引用的对象复制到to区域中(此时free的所指的位置会比unscanned的大否则无需再扫描,from和to均为free)
6~10行跟标记压缩的垃圾回收的13~17行是差不多的思路,这里就不再做具体的描述
LookupNewLocation算法:该函数是返回对象o在to中的指针。如果对象o不在to中,则从free中申请内存然后将o拷贝到申请的内存中,再返回o在to中的指针
三、增量式垃圾回收
如果如第二节所描述的那些算法进行回收的话则会出现一个问题:在进行垃圾回收的时候需要暂时所有的增量者的操作知道本轮的垃圾回收结束。那么当该工程比较大的时候则会出现整个界面无响应的情况
所以需要使用增量式的垃圾回收机制,这里有两种的垃圾回收技术:1、世代垃圾回收;2、列车算法
1、世代垃圾回收
该算法的思想是:新创建的对象大部分的生命周期都很短,那么对新创建的对象进行垃圾回收则可以减少因为垃圾回收而暂停的时间。
回收的算法使用了第二节说的拷贝垃圾回收的方式进行垃圾回收:1、先确认每个区域的大小为n,并为每个区域编号从小到大;2、当第0号区域填满之后使用拷贝垃圾回收的方式将0区域中的可达对象拷贝到1号区域,如果1号区域也填满了则继续使用拷贝的方式将1号区域中的可达对象拷贝到2号区域以此类推
如上的世代垃圾回收的算法有个问题是:有可能在某次的垃圾回收中退化为全局的垃圾回收,为此则引入了列车算法进行垃圾回收
2、列车算法
列车算法的存在是为了对成熟的对象进行垃圾回收
该算法使用多趟列车并且每趟列车内有多节车厢,列车和车厢均是从小到大进行标号。每趟列车有一个记忆集用来记录较高序号的列车对该趟列车的引用,每节车厢有记录该趟列车比他高的车厢对他的引用
每次只处理第一趟列车的第一节车厢
如果该趟列车没有来自高序号列车的引用则整趟列车全部删除
如果车厢中有来自高序号列车的引用则将该对象拷贝到高序列的列车中
如果车厢中有来自其他车厢的引用则该对象拷贝到对应的车厢中
如果目标车厢的对象已经满了则在该趟列车的末尾新建车厢并将对象拷贝到该车厢中
四、并发的垃圾回收
当我们进行垃圾回收的时候总是会出现增变者暂停等待垃圾回收完的情况
那么此时我们可以使用并发的形式进行垃圾回收
但是并发会出现一个情况是: A已经扫描但是A引用新创建的B,那么在该趟的垃圾回收之后B则会被当做垃圾回收。那么此种情况该如何处理呢? 我们可以在新建对象的时候进行监听如果引用的对象A是已经扫描的情况则再次将A标记为未扫描的状态使之重新扫描。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号