

CSAPP阅读笔记-异常,进程,进程控制-来自第八章8.1-8.4的笔记-P501-P526
异常的概念,类别与处理
异常:当处理器在处理一条指令时,若系统状态发生了某些特定的变化(又称发生了某个“事件”),就会跳转到所谓的“异常处理程序”,处理完后返回。
这里有几点要注意:
1.异常的发生和当前指令是否执行完成无必然联系,可能发生在当前指令执行完之后,比如执行完这条指令后发现某个I/O请求完成了。也可能发生在执行某条指令时,比如虚拟内存缺页。
2.异常在跳转到“异常处理程序”时,是通过一张“异常表”来跳转的,每一种异常都有一个异常号(非负整数),异常表会把不同的异常号关联到不同的异常处理程序,异常表在系统启动时由操作系统初始化。
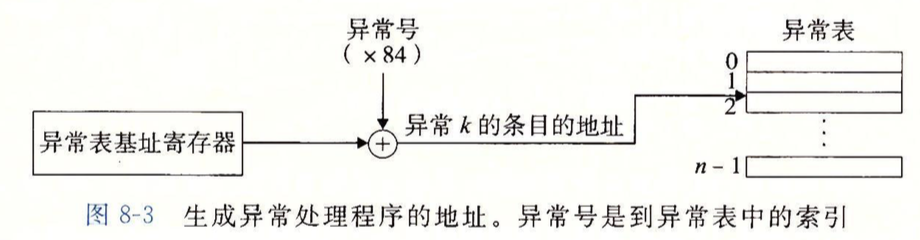
上图是根据异常表跳转到对应异常处理程序的流程:
异常表基址寄存器(一个特殊的CPU寄存器)存放异常表的起始地址,处理器根据异常号在异常表中找到对应的地址,与基址寄存器存的地址相加得到最终的异常处理程序地址。
异常处理程序处理完异常后有三种可能情况:1.将控制返回给当前正在执行的指令。2.将控制返回给下一条即将执行的指令。3.程序终止
因此,处理器在跳转到异常处理程序前,需要先根据异常类型,将不同的返回地址(当前指令还是下一条指令的)压栈,还要将处理器的一些状态也压栈。
注意,这里的压栈不是压到用户栈,由于异常处理程序运行在内核模式下,因此会压到内核栈。
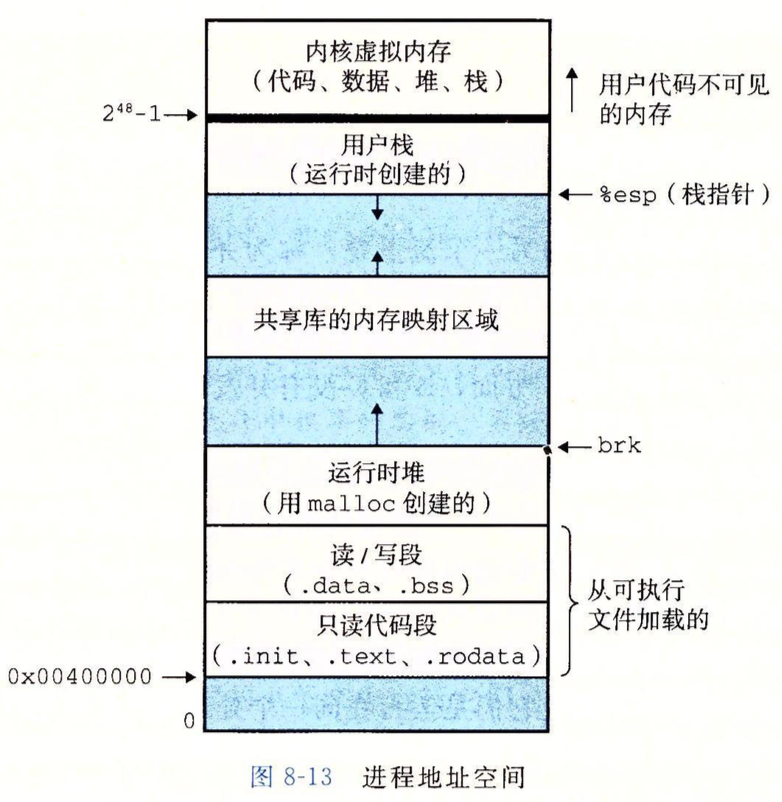
上图描述的是进程运行时的地址空间,它可以帮助理解内核栈,每个进程在运行时有自己的私有地址空间,它一般不能被其他进程访问,顶部空间留给内核(操作系统常驻内存的部分),内核有自己的代码段,数据段和堆栈。
异常的中断类型分4种:中断、陷阱、故障和终止
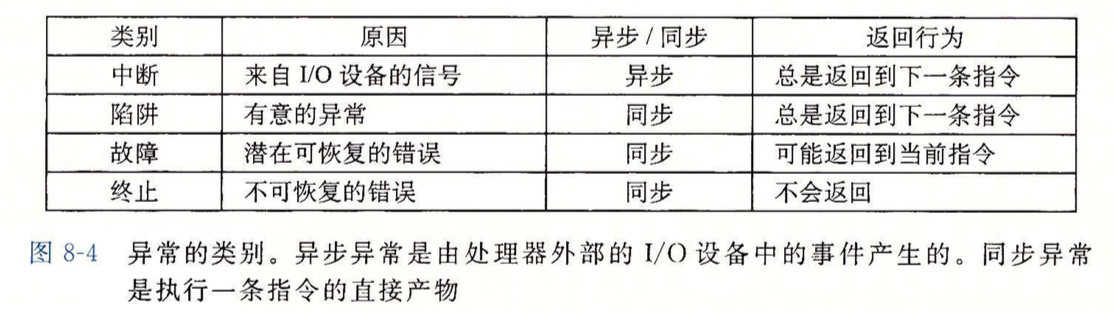
如上图所示,看书即可,不做详细阐述。
故障,比如缺页异常,是有可能被修复的,若修复了,会返回当当前指令,修复不了,返回到内核中的abort例程,abort例程会终止程序。
陷阱,最重要的用途是提供系统调用的接口,用户程序平时运行于用户模式,一些系统服务,比如读取文件(read),创建新进程(fork),加载程序(execve)等是无法使用的,而且也不能访问内核栈,当要用到这些服务时,只能“故意”触发异常,进入内核中的异常处理程序,来使用这些系统服务。
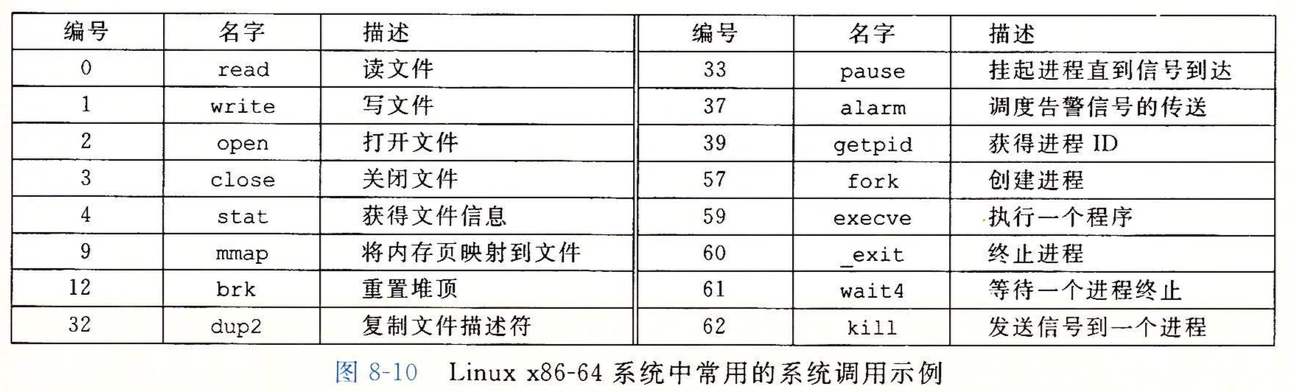
上图是一些常见的系统服务调用,这些调用基本都封装在标准C库中,当然它们的底层调用是通过一条syscall指令来实现的,对应调用时的参数传递由第三章讲的6个传参寄存器来完成,调用号存在%rax里,返回值也存在%rax中。
举例如下:


第一张图是对应的C语言程序,调用了write和_exit系统函数,具体的参数就不介绍了,直接查一下就知道了。注意,我在测试中发现,在MAC的Xcode下直接运行会报错,因为write函数包含于unistd.h头文件中,需要include一下。第二张图是对应的汇编版本,可以看到这两个命令的底层都是用syscall实现的,比如调用_exit,对应表中的编号,即调用号为60,存在%rax中,参数只有1个,值为0,存在第一个传参寄存器%rdi中。
进程与进程控制
进程可以理解为程序的一次运行,在我的理解中,进程这个概念的提出完全是为了让你更好地理解并发。
初学者会有这样的想法:我现在开始运行自己写的程序,因此当前CPU就在一条条顺序执行我程序中的指令,直到程序执行完,程序结束。
但其实不是这样的,可以这么理解:CPU就是一个超人,我们写的代码可以在很短的时间被它运行完,但现在有个问题,就是当代码中需要调用与外部交互时,比如从磁盘读取数据,由于从磁盘取数据需要花费较长一段时间(相对CPU运行速度而言),这个取数据是不需要CPU参与的,CPU只需发送请求即可,因此人们想到,这段时间完全可以让CPU去做其他的事,当数据读取完毕,再让CPU回来继续执行下一条指令即可,显然这将大大提高效率。这里所谓的做其他的事,就是去运行其他的程序,也就是所谓的并发。
但问题来了,要实现并发就相当于要让当前程序“暂停”,转而去运行其他程序,且返回时能让当前程序从之前没完成的步骤开始继续运行下去。因此,之前对程序的认知,从概念上就不大合适了,毕竟之前的认知就是,系统中只有一个程序,CPU在执行该程序,而且程序也不存在“暂停”的概念。
于是人们发明了“进程”这个概念来更加科学地描述这个并发的过程,可以把进程理解为程序的一次运行,如果学过前几章我们就能明白,程序的运行并不是一个整体的概念,它实质上就是CPU在一条条地取代码段的指令并执行,一个程序的运行是由许许多多分立指令的运行组成的,因此它完全可以被“暂停”,只需要保存暂停时的状态即可,所谓的恢复执行,也就是跳转回程序的下一条指令继续执行而已。而程序运行时是会被加载器加载到内存里的,除了当前运行的程序,内存里同时存在其他的程序,当要暂停当前程序并让其他程序运行时,只需跳转到其他程序的入口地址即可,但这么多程序在一起,如果互相干扰怎么办?比如同时用了某个寄存器。进程这个概念其实就是把这些分立的程序进行了模块化封装,上面有一张进程地址空间的结构图,进程把所有程序都描述成上面的样子,不同的程序区别就在于其代码段有不同,但相同的是它们都有自己的堆,栈等私有空间,这是一种抽象,因为这些程序其实都在内存中,挤在一起,但有了进程这个概念,我们可以对不同的程序对应的内存地址分割,营造出它们都在某个独立空间的假象,这有助于我们分析程序, 毕竟,有了这个概念,以后我们分析并发的时候就可以说,进程A运行了多久,然后切换到了进程B,而不是“先跳转到内存的xxx处,执行xxx条指令后,跳转到内存的xxx处”。
总而言之,进程这个概念可以帮助我们更好地理解程序的“暂停”,从而更好地理解“并发”。
之前提到的触发异常导致切换到异常处理程序其实就是一种进程切换,以磁盘读取导致的“陷阱”异常为例:
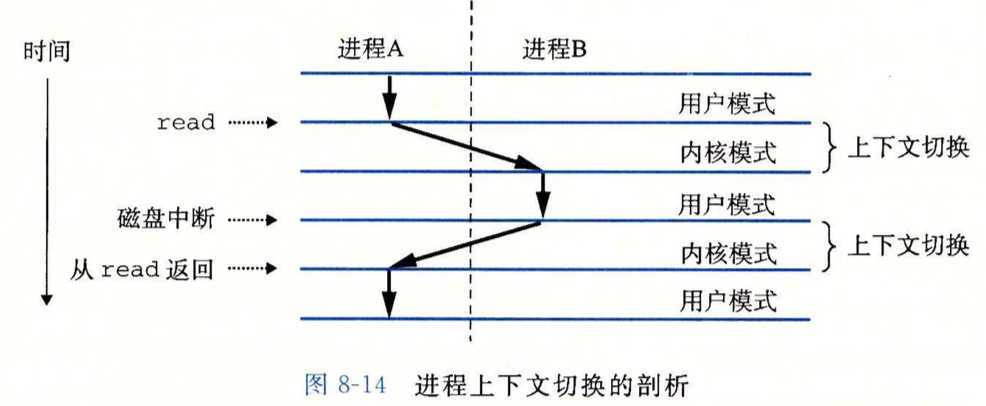
进程A运行在用户模式下,需要执行系统调用read,触发异常并转入内核模式,内核模式下运行处理磁盘读取的陷阱异常处理程序,在等待读取数据时,内核主导完成进程切换,注意这里进程A到B用了斜箭头,这是因为从A到B的进程切换是在内核模式下执行的,内核模式先花了一部分时间执行A的系统调用,又花了一部分时间来切换到进程B,这里的上下文切换就是切换进程时恢复进程之前的状态。进程B在用户模式运行一段时间后由于磁盘数据读取完毕,磁盘的中断信号导致进程B进入内核模式,内核模式下完成进程B到进程A的切换,返回后进程A继续运行在用户模式,执行下一条指令。
介绍几个进程操作的函数:
fork函数,可以创建一个子进程,它有独立的,但与父进程相同的虚拟地址空间,有与父进程相同的打开文件描述符(可以理解为句柄),即它可以修改父进程打开的文件,它与父进程的区别在于PID不同。此函数,无参数,返回值为子进程的PID。
看一个案例:

注意,这里创建子进程用的是Fork函数,这不是说fork函数不区分大小写,而是csapp里对fork函数做了包装,可以理解为Fork函数是一个具有校验功能的fork函数。这个案例是为了说明这样一个事实:fork函数会在为当前进程创建一个子进程,但由于子进程与父进程有相同的虚拟地址空间,这意味着在子进程中代码也是运行到了第6行,那么接下来处理器该把控制返回给谁呢?答案是随机的,此时这两个进程已经处于并发运行状态了,交叉运行,谁先谁后都不一定。注意fork函数返回子进程的PID,在父进程中肯定返回的是创建的子进程的PID,在子进程中返回的就是0。因此若此时是子进程在运行,会进入到7-10行,并由exit系统调用来退出进程。而若父进程在运行,则会进入13-14行的代码。同样,由于子进程和父进程有相同的虚拟地址空间,临时变量x显然也会被复制,此时子进程中的x与父进程中的x不再关联,因此修改后父进程输出parent:x=0,子进程输出child:x=2。同理,由于子进程和父进程共享相同的打开文件,因此printf都显示在父进程打开的stdout上,且指向屏幕。
进程终止时并不会被直接清除,而是等待父进程回收,父进程回收后内核会把子进程的“退出状态”传给父进程,此时子进程会被清除。已终止但尚未被回收的进程就是所谓的“僵尸进程”,注意,僵尸进程虽然已终止,但仍占用内存资源。那么假如父进程终止了,子进程怎么办?内核会安排一个init进程(PID为1,所有进程的祖先,在系统启动时由内核创建,不会终止)去收养它们,当子进程终止时,由init进程去回收子进程。
下面简略介绍waitpid函数,由于它比较复杂,直接看书,不作详细介绍,简要描述下其功能:进程可以通过调用它来等待子进程终止,返回值是已终止子进程的PID,另外,此函数还附带回收终止子进程的功能。通过调整其参数,可以指定等待某个子进程终止,还可以设置成非阻塞的,即调用时不再等待子进程终止,而是直接“看一下”当前是否有终止的子进程并立刻返回结果。还可以返回子进程退出的退出码(即exit的参数)。
waidpid函数有一个简化版本,wait函数,等价于waitpid(-1,&status,0),效果是正常的阻塞等待功能,针对目标是集合中所有子进程(而不是单一指定子进程)。
execve函数可以加载并运行一个指定名字的可执行目标文件,原型如下:
int execve(const char *filename,const char *argv[],const char *envp[]);
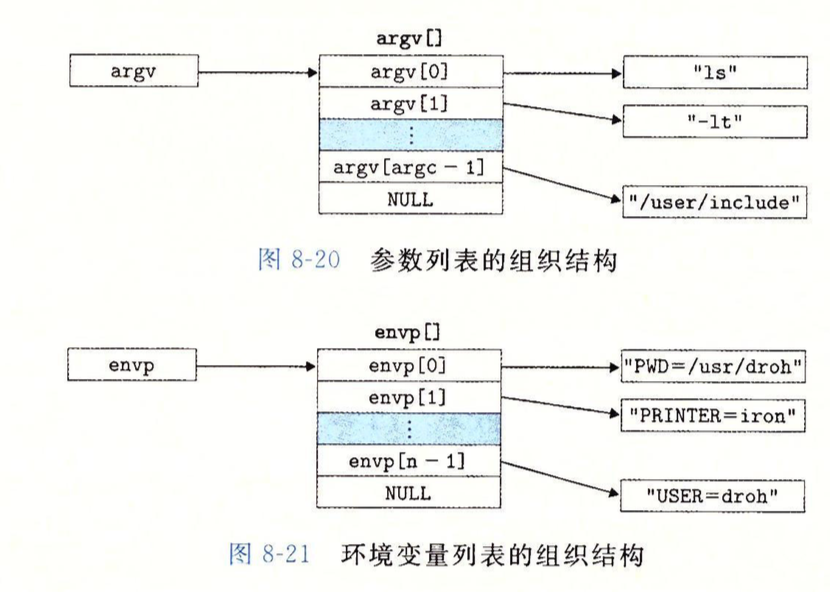
argv是参数列表,envp是环境变量列表。
注意,除非出现错误,否则execve加载并运行可执行目标文件后不会返回,它是在当前进程的上下文中加载并运行的新程序,会覆盖当前进程的地址空间,并没有创建新进程,因此新加载的程序的PID不变,且继承了调用execve时已经打开的文件。
argv和envp对应的其实就是主函数里的参数int main(int argc,char *argv[],char *envp[]),如下图所示:
同理,对应的栈组织结构如下:
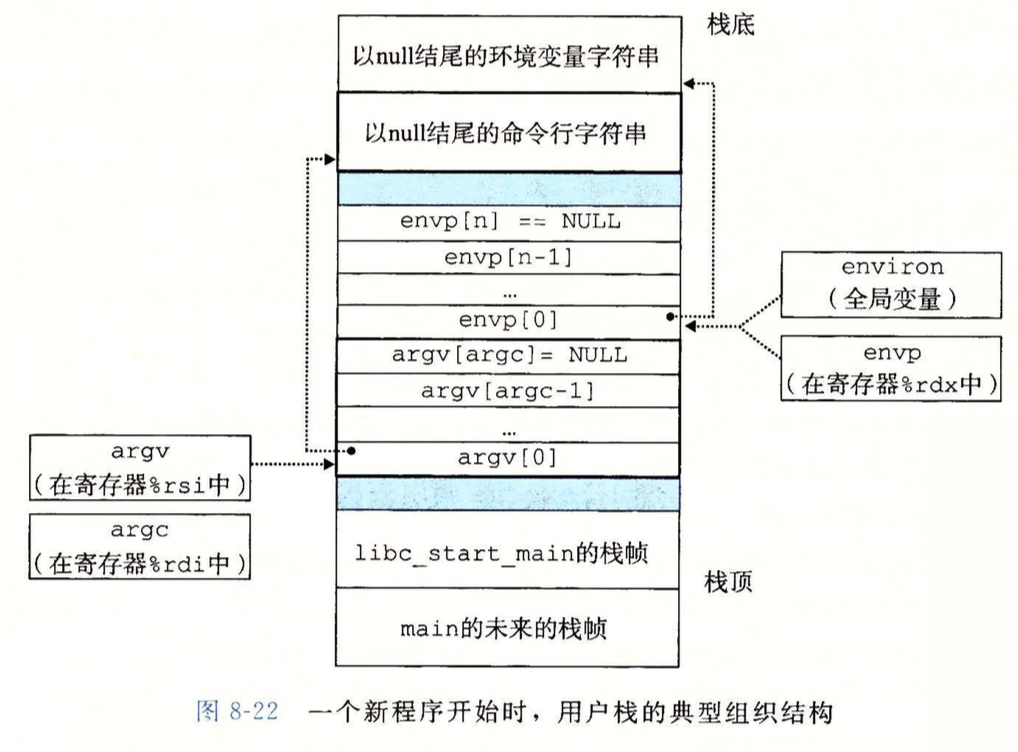
还记得第三章中描述的参数压栈顺序吗?从后往前,这里先压入envp最终指向的所有字符串内容,即"PWD=/usr/droh"等所有字符串,再压入argv里面的所有字符串,随后压入envp[]和argv[]指针数组,即压入的是之前字符串的地址,它们都以null结尾,最后是libc_start_main这个系统启动函数(注意不是main函数)的栈帧。
一个很有意思的案例:



上面是一个简易的shell程序,功能是打印命令提示符后等待用户输入命令行,并根据命令行的内容执行相应的系统调用。
其中,parseline函数用于将输入的命令(存于buf中)以空格为分隔符分割到argv数组中,argv中的每一项对应一个字符串地址,以null结尾。里面有一些细节的处理值得一看,如第9行对命令行前面的空格的处理,如第16行,把分割出的字符串中的空格以'\0'代替,如第18行,针对处理出现连续空格的情况,第21行,为分隔出的字符串数组尾部添加null,以满足execve加载时参数的要求,23行针对无输入的情况做了处理。
eval函数中先对分隔的字符串数组检测,看是否是内置命令(目前只有quit),是的话直接退出,不是的话创建子进程并在子进程中用execve加载对应的命令。可以看到16行,execve的可执行文件名参数用的是argv[0],说明程序名存放在argv[0]中,这点从图8-20也能看出,也说明我们平时命令行中用的那些如ls,open之类的命令其实是单独的可执行文件。第三个参数是envp,这里对应的是全局变量environ,由图8-22可知,environ是指向envp[0]的,所以没问题。
突然有点奇怪,因为之前我们看到,C语言中可以进行对应的系统调用,比如直接调用write函数,是否可以认为其实它在底层上是用了类似上面的fork+execve的方法来实现的呢?
查了一些资料,目前理解是这样,可能不对,暂时记录一下:
我们平时在shell中用命令行来交互,其本质就是上面的那种架构的程序,对系统的调用通过fork+execve来实现,当然底层仍然是汇编的syscall指令。但按照上面的思路来尝试,我们在命令行打入ls,是成功运行的,能显示当前目录下的文件,但打入fork的时候,却提示command not found,这是怎么回事?难道ls被包装成了可执行程序,可以被fork+execve加载,而fork却没有吗?
这是因为我的理解完全错了,fork是系统调用,不存在它的可执行文件。而ls这种指令,是shell自己封装的指令,而且根据这种指令是否存在可执行文件,这些shell 自己封装的指令可被分为内建指令和外部指令,它们不是直接的系统调用指令!!如果这是个外部指令,如pwd,就用类似fork+execve加载某种系统指令的方式实现,如果是内建指令,就对应上面代码的builtin_command函数中定义的指令,只不过我们的程序中只有一个quit的内建指令罢了。
从https://blog.csdn.net/cooling88/article/details/52302544
参考得知,内建指令由shell直接执行,不需要派生新的进程,这也和我们代码中的builtin_command函数对应上了,里面直接做了系统调用,并没有用fork+execve加载到新的进程中运行。

shell的外部指令对应的可执行文件一般在/bin下,如上图所示,可以看到,此目录下存在ls与pwd的可执行目标文件,它们都是外部指令。而如cd这样的指令则显然是shell的内建指令。
这个程序还有个选择前台后台实现的功能,前台实现实质就是让父进程阻塞在那,等待子进程加载的命令实现完毕再继续,用waidpid实现,后台就是并发运行。
注意,这个shell仍有缺陷,后台运行的情况下,也就是第28行的情况,只做了简单的输出,并没有对子进程进行回收。

