

CSAPP阅读笔记-存储器层次结构-第六章-P400-P462
6.1 存储技术
1.随机访问存储器(RAM),是易失性存储器,掉电存储信息会丢失,与之相对的是非易失性存储器(ROM),它掉电后存储信息不丢失,但前者访问速度较快,但容量有限,通常只有几百或几千兆字节。
2.它分为静态RAM(SRAM)和动态RAM(DRAM),前者更快,价格也更高,密集度更低。
3.磁盘由盘片构成,一个盘片两个面,盘片中央有旋转轴以固定速率旋转,多个盘片组合并封装形成了一个磁盘,也就是所谓的机械硬盘。盘片可以被划分为许多同心圆,这些被称为磁道。每个磁道被分为许多扇区,每个扇区拥有相等数量的数据位,因此扇区的数量是由最靠内的磁道能记录的扇区数决定的,越靠外的磁道扇区隔得越开。扇区之间有间隙,不存储数据位,用于存储用来标识扇区的格式化位。如下图所示:

给个案例:假设有一个磁盘,有5个盘片,每个扇区512字节,每个面20000条磁道,每条磁道平均300个扇区,则其容量是多少?
答:容量为 5*2*20000*300*512 = 3.072*1010字节=30.72GB
4.对扇区的访问时间主要由以下3个部分组成:寻道时间(移动传动臂到对应磁道),旋转时间(定位到该磁道上的某个扇区)和传送时间(传送该扇区内容)
注意,由于并不知道扇区位于磁道中的那个地方,因此旋转时间通常用平均旋转时间来计算,即最大旋转时间/2。
给个案例:

解答:首先寻道时间是Tavg seek=5ms, 旋转速率是10000RPM,即10000转/分钟,那么最大旋转时间为(1/10000)*60*1000=6ms,平均旋转时间为3ms,1MB的文件约有2000个扇区,首先定位到第一个扇区,用了5+3=8ms,最优情况下直接顺序读两圈磁道即可,因此无额外的寻道和旋转时间,最终时间为8+2*6=20ms。而B对应的随机情况,每个扇区都要重新寻道和旋转定位,因此有2000*8 = 16s,差别巨大。这就是为什么需要清理磁盘碎片的原因。
6.2 局部性 略
6.3 存储器层次结构
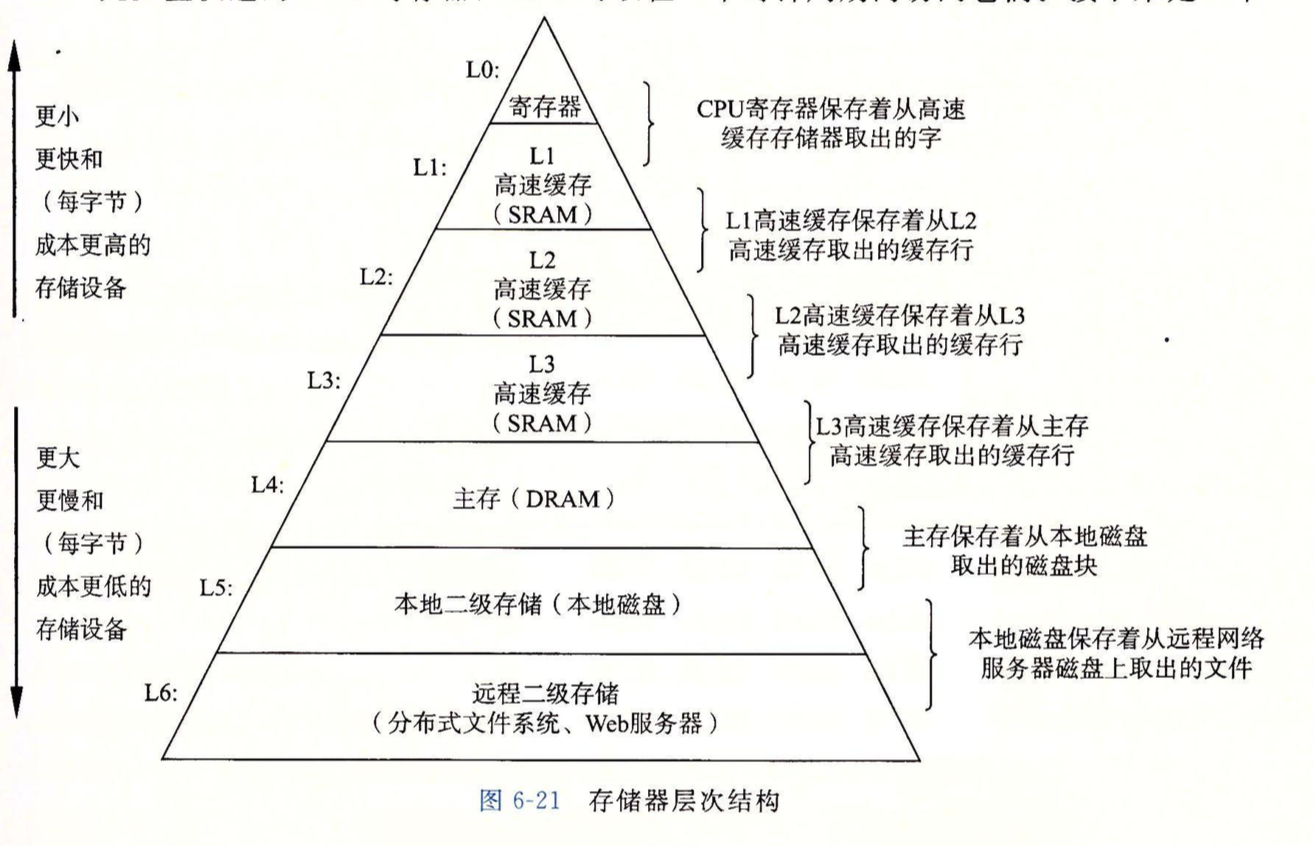
如上图所示,是典型的存储器层次结构,从上往下越来越慢,越来越便宜和大。数据以块的形式在其中传输,每一级都可作为下一级的缓存,比如k+1级有序号为0-15的块,则k级可能会有0,2,7,9几个块作为缓存。块的大小不是固定的,较低层由于访问时间长,为了补偿这些较长的访问时间,倾向于使用较大的块。
如果要访问的内容在缓存中,则被称为缓存命中,若不在,则称为缓存不命中,要从下一层取出包含内容的块,若缓存满了,则要替换缓存中的某个块,替换策略有很多种,比如LRU(最近最少被使用)等。还有一种不命中叫冲突不命中,原因是由于下一层的某些块在映射到上一层的缓存时,使用了严格的映射策略,比如规定只能映射到i mod 4的块中,这样,块0,块4和块8都会映射到缓存中的同一个块,当程序先请求块0,再请求块4,块8时,即使缓存可以容纳多个块,每次访问也都会不命中。
6.4 高速缓存存储器
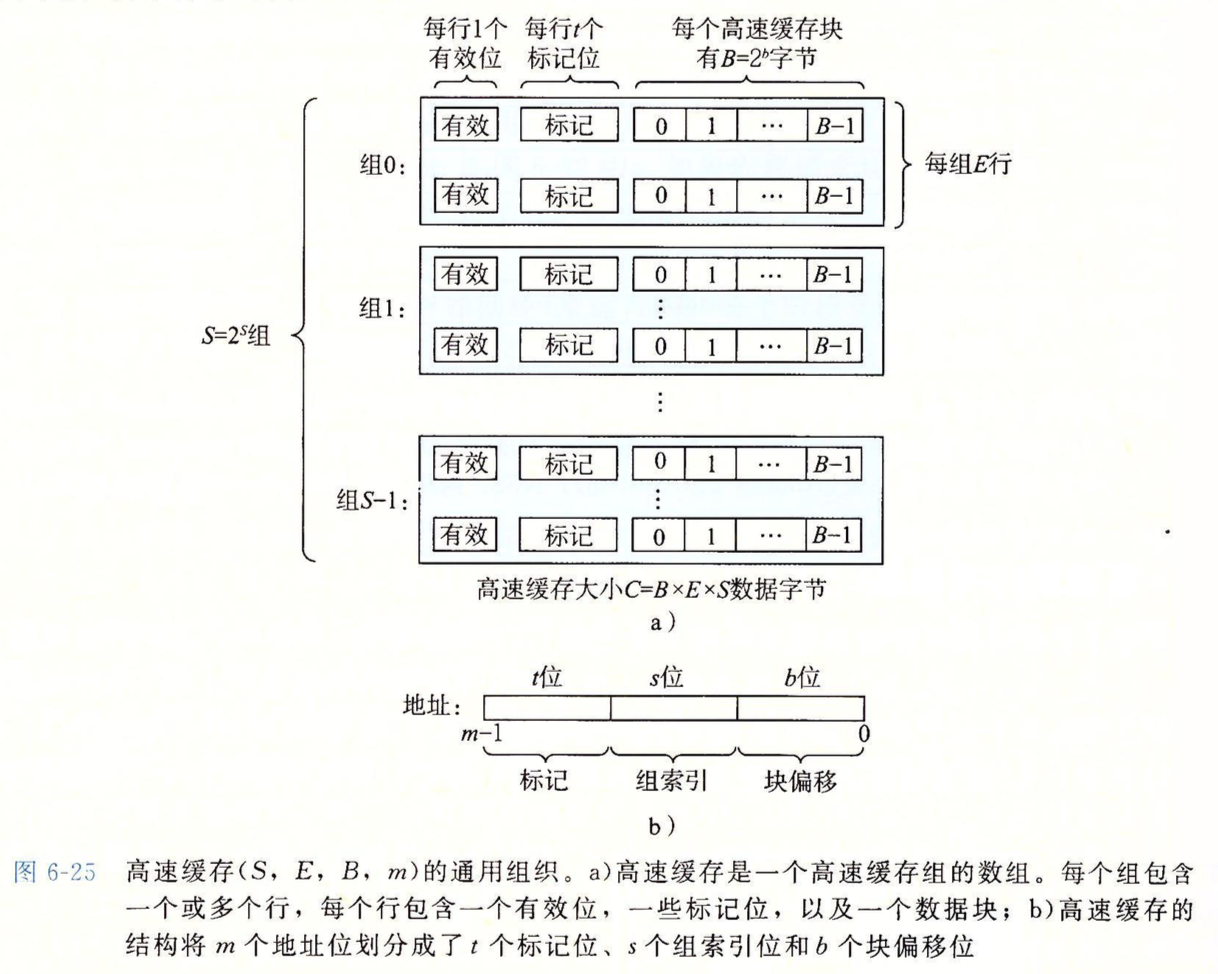
通过上图了解一下高速缓存中的几个重要参数:
每个存储器地址有m位,被分割为t位的标记位,s位的组索引位和b位的块偏移位。其中s位的组索引位把高速缓存分割成了2s个组,每个组有E行的高速缓存行,每行包含一个块,块的大小为2b个字节,b位的块偏移位可以指定选中的字节是从该块中的哪个字节开始计算。每一行还有个有效位,用于标记此行是否有效。
当每个组的行数E为1时,高速缓存被称为直接映射高速缓存。
考虑这样一个函数:

假设一个块是16个字节,高速缓存由两个组组成,且是直接映射高速缓存(因此整个大小为32字节),此时x[0]-x[7]存放在地址0-31,分别映射到组0和组1,y[0]-y[7]存放在地址32-63,也分别映射到组0和组1。如下图所示:
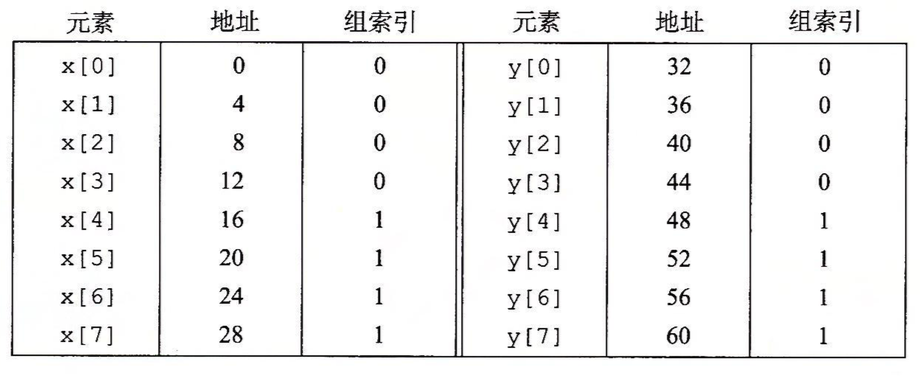
当访问x[0]时,由于缓存不命中导致x[0]-x[3]被加载到组0,访问y[0]时又会出现未命中,导致y[0]-y[3]被加载到组0,出现覆盖。同理,以后每次对x和y的访问都会由于覆盖出现未命中,这种现象被称为“抖动”。解决的方法是在数组后面加一定字节的填充,比如对以上情况,可以定义为float x[12],此时映射如下:
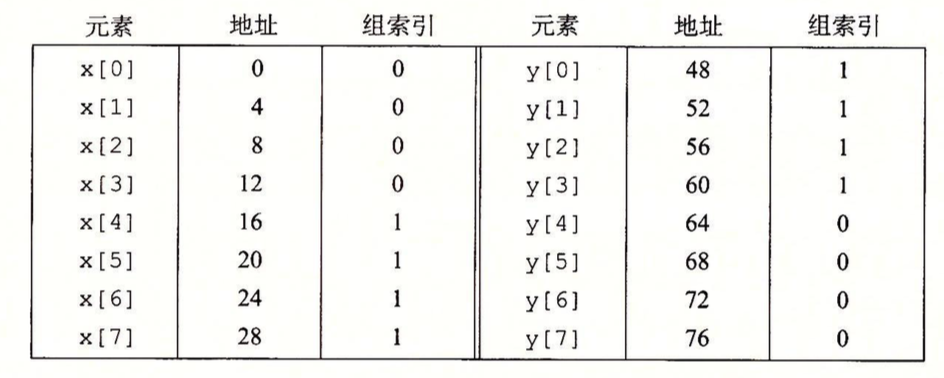
具体情况就不解释了。
考虑一个问题:为什么要用中间的位做索引位,而不是用高位?
答:当用高位做索引位时,相邻地址的内存块会映射到高速缓存的同一组,此时若顺序访问某个数组,那任何时刻高速缓存都只保存一个块的大小。使用效率很低。
给个例子:

对于A:假设有t位标记位,则每个组有2t个块。
对于B:由于S=512,所以索引位有9位,块大小为32字节,因此偏移位有5位,因此t=32-9-5=18位,因此每218个块会映射到同一组,而数组一共有4096*4/32=512个块,因此全部会映射到组0,因此任何时候,高速缓存最多只能保存一个块,效率很低。
当E>1时,高速缓存中的一个组可以包含很多行,每行存储一个块,它被称为组相联高速缓存,定位时找到组后要根据标识位进一步判断在哪一行。
当此高速缓存有很多行,但只有一个组时,它被称为全相联高速缓存。
对于高速缓存的写,有两个问题:
一个是对已经缓存了字的高速缓存,如何更新下一层的副本?
两种方法,一种是“直写”,即立刻把更新的高速缓存块写回到低一层中。第二种是“写回”,即尽可能推迟更新,只有当替换算法要驱逐这个更新的块时,才把它写到低一层中。
第二个问题是如何处理写不命中?
两种方法,一种是“写分配”,即加载相应的低一层的块到高速缓存,然后更新此高速缓存块。另一种是“非写分配”,即直接把这个字写到低一层。
给一些典型题:

答:对于A,由于块大小为8个字节,高速缓存总大小为16个字节,因此,一组可以存2个int,高速缓存总共可以存4个int,映射关系如下:
| src | [0][0] | [0][1] | 块1 |
| [1][0] | [1][1] | 块2 | |
| dst | [0][0] | [0][1] | 块1 |
| [1][0] | [1][1] | 块2 |
访问src[0][0]时,不命中,于是读取src[0][0]和src[0][1]到块1中,此时块1是src[0][0]和src[0][1],块2为空。
随后访问dst[0][0],不命中,读取dst[0][0]和dst[0][1]到块1中,发生了覆盖,此时块1是dst[0][0]和dst[0][1],块2为空。
随后访问src[0][1], 由于之前发生了覆盖,所以不命中,读取src[0][0]和src[0][1]到块1中,又发生了覆盖, 此时块1是src[0][0]和src[0][1],块2为空。
随后访问dst[1][0],不命中,读取dst[1][0]和dst[1][1]到块2中,此时块1是src[0][0]和src[0][1],块2是dst[1][0]和dst[1][1]。
随后访问src[1][0],不命中,读取src[1][0]和src[1][1]到块2中,发生了覆盖,此时块1是src[0][0]和src[0][1],块2是src[1][0]和src[1][1]。
随后访问dst[0][1], 不命中,读取dst[0][0]和dst[0][1]到块1中,发生了覆盖, 此时块1是dst[0][0]和dst[0][1],块2是src[1][0]和src[1][1]。
随后访问src[1][1],命中。
随后访问dst[1][1],不命中,读取dst[1][0]和dst[1][1]到块2中,发生了覆盖,此时块1是dst[0][0]和dst[0][1],块2是dst[1][0]和dst[1][1]。
对于B:
当高速缓存为32字节时,可以存放4个块,则映射关系如下:
| src | [0][0] | [0][1] | 块1 |
| [1][0] | [1][1] | 块2 | |
| dst | [0][0] | [0][1] | 块3 |
| [1][0] | [1][1] | 块4 |
显然此时只会在第一次访问块时才会有不命中,即一共只有4个不命中。


答:A:读总数=16*16*2=512
B:整个缓存可以存1024/16=64个块,一个块可存两个结构体,grid共占用16*16/2= 128个块,因此grid的前8行正好全部映射到高速缓存中,后8行会
进行覆盖映射。这里由于是顺序访问,每2个数据有1个不命中,不命中数=512*50%=256次
C:50%
变种:

答:A:读总数仍为16*16*2=512
B:由于这里是列访问,当访问前8个元素(即grid[0][0]-grid[7][0])时,都不命中,此时命中率50%,访问grid[8][0]-grid[15][0]时,会覆盖掉高速缓存,导致后面访问grid[0][1]-grid[7][1]时再次发生不命中,因此命中率一直维持在50%,因此不命中读总数为256。
C:50%
D:高速缓存两倍大时,访问grid[8][0]-grid[15][0]不会覆盖掉高速缓存,又因为一个块可存两个结构体,因此后面访问grid[0][1]-grid[15][1]时会 命中,因此只存在冷不命中,不命中率只有25%。
再次变种:

答:A:512
B:此时顺序访问,只有冷不命中,128。
C:25%
D:此时限制不命中率的不再是高速缓存大小,而是块大小,因为每个块只能存两个数据,因此此时不命中率仍是25%。
一道比较有意思的题:

答:
A:高速缓存能存放512/16=32个块,数组一共包含2*128*4/16=64个块,因此高速缓存最多存放数组的一行,然而数组是列访问的,访问x[0][0]时发生不命中并把x[0][0]-x[0][3]对应的块加载进来,随后访问x[1][0]时,发生不命中并把x[1][0]-x[1][3]对应的块加载进来,由于x[1][0]-x[1][3]映射的块刚好和x[0][0]-x[0][3]的相同,发生冲突不命中,会导致覆盖,导致随后访问x[0][1]时又会发生不命中,循环往复,不命中率100%。
B:翻倍后,高速缓存最多能把数组全部存放,因此x[1][0]-x[1][3]映射的块与x[0][0]-x[0][3]不同,不会发生覆盖,因此只会发生冷不命中,即每个块刚加载进来时对应的那次不命中,不命中率25%。
C:两路组相联时,一组有两行,即两个块,高速缓存最多存512/16/2=16组。此时x[0][0]-x[0][63]对应映射到组0-组15,首先访问x[0][0],将对应的块x[0][0]-x[0][3]加载到组0,随后访问x[1][0],此时x[1][0]-x[1][3]对应的块也会映射到组0,但由于每个组有两行,这个块会被加载到组0的第2行,循环往复,到访问完x[1][63]时,正好将高速缓存全部映射完,此时不命中率为25%,随后访问x[0][64]时,它对应的块也会映射到组0,根据LRU策略,会覆盖掉组0中对应x[0][0]-x[0][3]对应的那一行,即行1,同理,访问x[1][64]时,对应的块也会映射到组0,根据LRU策略,此时覆盖掉行2,因此按这种顺序访问不会发生立刻覆盖的情况,不命中率一直保持为25%。
D:不会,这种情况下,不命中已经是冷不命中了,增大高速缓存只能增加容纳的组的数量,但加载进来的每个块都只能容纳4个int,只能保证后面3个int能命中,命中率无法改善。
E:会,不解释了,看D就明白了。
再来一道:


首先,高速缓存可以存4*1024/16=256个块。
N=64时,数组的一行有64*4/16=16个块。对于sumA,由于顺序访问,只有冷不命中,25%。对于sumB,列访问,访问a[0][0]时,映射的块是块1,访问a[1][0]时,映射的块是块17,循环往复,到访问a[16][0]时,又会映射到块1,此时发生覆盖,如此继续,访问完a[63][0]时,对于任意一个块,发生了3次覆盖,因此,此时访问a[0][1]时,仍会发生不命中,同理,后面的情况也是如此,因此100%不命中。对于sumC,因为是按正方形的顺序访问的,在访问a[0][0]和a[1][0]时,要分别加载进来块1和块17,而访问a[1][0]和a[1][1]时,都会发生命中,因此最终不命中率50%,注意sumC中i是以2的速度递增的,不用担心有重复访问的问题。
N=60时,数组的一行有60*4/16=15个块。对于sumA,一样只有冷不命中,25%。对于sumB,列访问,对于第一列,从a[0][0]到a[59][0],此时映射的块分别为
1 16 31 46 61 76 91 106 121 136 151 166 181 196 211 226 241 256
15 30 45 60 75 90 105 120 135 150 165 180 195 210 225 240 255
14 29 44 59 74 89 104 119 134 149 164 179 194 209 224 239 254
13 28 43 58 73 88 103 118
无一重复,都不命中,而且此时不会发生覆盖,因此在继续访问a[0][1]到a[59][1]时,不会因为覆盖发生不命中,同理,后面也是这样,因此其行为类似于冷不命中,不命中率25%。
对于sumC,分析类似于sumB,也是25%。

