

CSAPP阅读笔记-汇编语言初探(数据传送类指令)-来自第三章3.2-3.3的笔记-P115-P128
1.如何由机器代码生成汇编代码?
objdump -d再加上文件名即可直接在终端看到由反汇编器恢复的汇编代码。注意,文件名并不一定得是.o文件,任何可执行文件都可以。
结果如下:
![]()

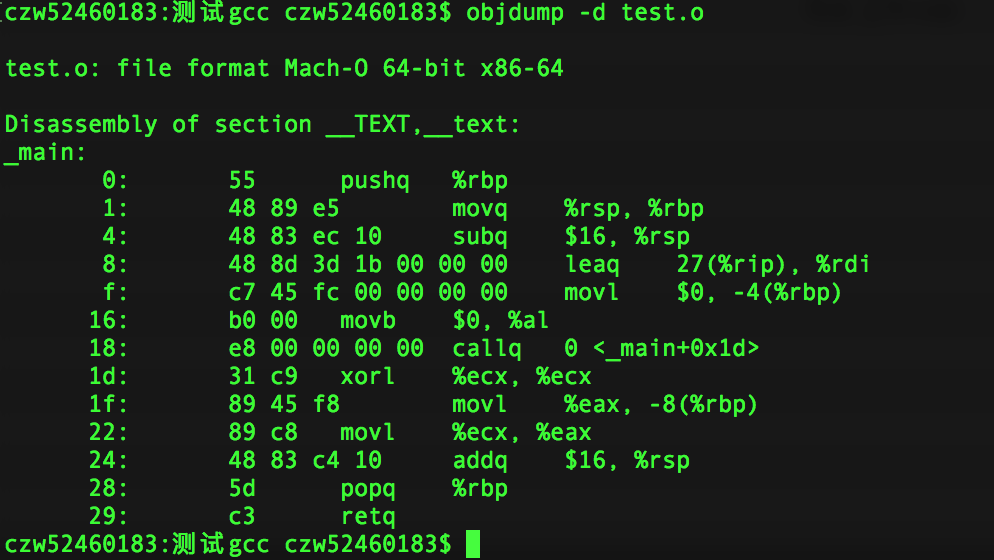
仅列举了反汇编test.o的结果,其它的也测试过,不放图了。
2. 32位和64位的基本数据类型大小对比:
32位:
char:1字节,char*:4字节,short int:2字节,int:4字节,unsigned int:4字节,float:4字节,double:8字节,long:4字节,long long:8字节,unsigned long:4字节
64位:
char:1字节,char*:8字节,short int:2字节,int:4字节,unsigned int:4字节,float:4字节,double:8字节,long:8字节,long long:8字节,unsigned long:8字节
红字标识的是有变化的数据类型。
3.几个术语:
字节:8位,后缀:b
字:16位,后缀:w
双字:32位,后缀:l
四字:64位,后缀:q
MOV类指令也有movb,movw,movl,movq,分别对应这几种大小的操作数。
4.x86-64的寄存器:
看下面这张图:

x86-64有16个64位通用寄存器,如最左侧所示,可以对每个寄存器的低字节操作,比如要访问%rax的低8位,则可以访问%al。
同理,也有%ax对应16位,%eax对应32位,%rax对应64位。
有一条特殊规则:当对某个寄存器的低4字节操作时,如%eax,会自动把高4个字节全置为0。
5.寻址方式:
1: $+立即数,则取得的操作数就是立即数
2:立即数,则取得的操作数就是以立即数为地址,对应取出的操作数
3:寄存器,则取得的操作数就是以寄存器的值
4:(寄存器),则取得的操作数就是以寄存器的值为地址,对应取出的操作数
5:立即数1(寄存器1,寄存器2,立即数2),则取得的操作数就是以立即数1的值+寄存器1的值+寄存器2的值*立即数2为地址,对应取出的操作数
6.有了最通用的第5条,其他变种都能写出,比如(,寄存器2,立即数2),则取得的操作数就是以寄存器2的值*立即数2为地址,对应取出的操作数
习题练一下:

答案:
%rax对应0x100, 0x104对应0xAB, $0x108对应0x108, (%rax)对应0xFF, 4(%rax)对应0xAB, 9(%rax,%rdx)对应0x11
260(%rcx,%rdx)对应0x13, 0xFC(,%rcx,4)对应0xFF, (%rax,%rdx,4)对应0x11
讲解一下260(%rcx,%rdx),因为260=0x104,所以操作数是0x104+0x1+0x3=0x108地址对应的值,是0x13
6.mov指令
1.mov指令的顺序是从左到右,如mov a,b,则把a的值复制给b
2.除了之前提到的movb,movw,movl,movq,还有movabsq,代表传送绝对的四字,movq虽可传四字,但一旦要传立即数,则只能传32位补码表示的立即数,随后把它符号拓展到64位。而movabsq可以直接传64位的立即数,但是它只能以寄存器作为目的地。
3.所有mov指令都不支持从一个内存地址直接传到另一个内存地址,如movw (%rax),4(%rsp)是不行的。
4.决定mov使用哪个后缀的是寄存器的大小,当两边操作的都是寄存器时,若大小不同,必须用第5条中的小数据复制到大目的地的类型的mov指令,当两边操作的是立即数和内存时,可以以立即数大小为准,
例子:movl $0x4050,%eax 0x4050虽然是2字节,但%eax是4字节,所以movl
movw %bp,%sp
movb (%rdi,%rcx),%al
movb $17,(%rsp) 立即数->内存
movq %rax,-12(%rbp)
5.当想将小的数据复制到大的目的地时,可以用movz或movs,前者代表用0填充高字节,后者代表用符号填充高字节,后面还要加上两种转换数据的大小,
比如movzbw(字节->字,0填充),movswq(字->四字,符号填充),还有一种cltq指令,特指%eax->%rax的符号拓展转换,等价于movslq %eax,%rax
注意movs和movz都是以寄存器为目的地的。
根据以上信息,可以知道,之前的第4点中的特殊规则其实相当于是说movl可以实现movzlq的功能
6.当作强制类型转换时,若既涉及大小的变化又涉及符号变化,则操作时应先改变大小。
例子:有两个指针,sp和dp,分别保存在%rdi和%rsi中,指向的数据类型分别是src_t和dest_t,中间寄存器为%rax,可用其任意子部分
当src_t为long,dest_t为long时,写出转换的指令:
movq (%rdi),%rax
movq %rax,(%rsi)
当src_t为char,dest_t为int时,写出转换的指令:
movsbl (%rdi),%eax //因为char是有符号的,先用movsbl转成4字节
movl %eax,(%rsi) //以寄存器大小决定后缀用l
当src_t为char,dest_t为unsigned时,写出转换的指令:
movsbl (%rdi),%eax
movl %eax,(%rsi) //转换后两者大小相等,无需作零拓展
当src_t为unsigned char,dest_t为long时,写出转换的指令:
movzbq (%rdi),%rax //答案是movzbl (%rdi),%eax,答案疑似错了
movq %rax,(%rsi)
当src_t为int,dest_t为char时,写出转换的指令:
movl (%rdi),%eax //先改变大小指的是源比目的小时先改变大小
movb %al,(%rsi)
当src_t为unsigned,dest_t为unsigned char时,写出转换的指令:
movl (%rdi),%ax
movb %al,(%rsi)
当src_t为char,dest_t为short时,写出转换的指令:
movsbw (%rdi),%ax
movw %ax,(%rsi)
7.push与pop指令
1.栈是向下增长的,因此栈顶元素的地址是所有栈中元素地址中最低的。
2.%rsp保存着栈顶元素的地址。
3.push和pop同样有pushq,pushl,pushw,pushb等操作,以下都以pushq为例来讨论。
4.pushq时,先将栈顶指针减8,再将值写到新栈顶地址,如:
pushq %rbp
等价于:
subq $8,%rsp (下一章讲述这个指令)
movq %rbp,(%rsp)
这两种操作的区别是机器代码中pushq指令编码占1字节,而上面两条指令加起来需要8字节。
验证:随便找个.c文件,先生成.s汇编代码,然后在.s里面改成需要的汇编指令,生成.o文件,再用objdump -d反汇编查看,结果如下:
![]()
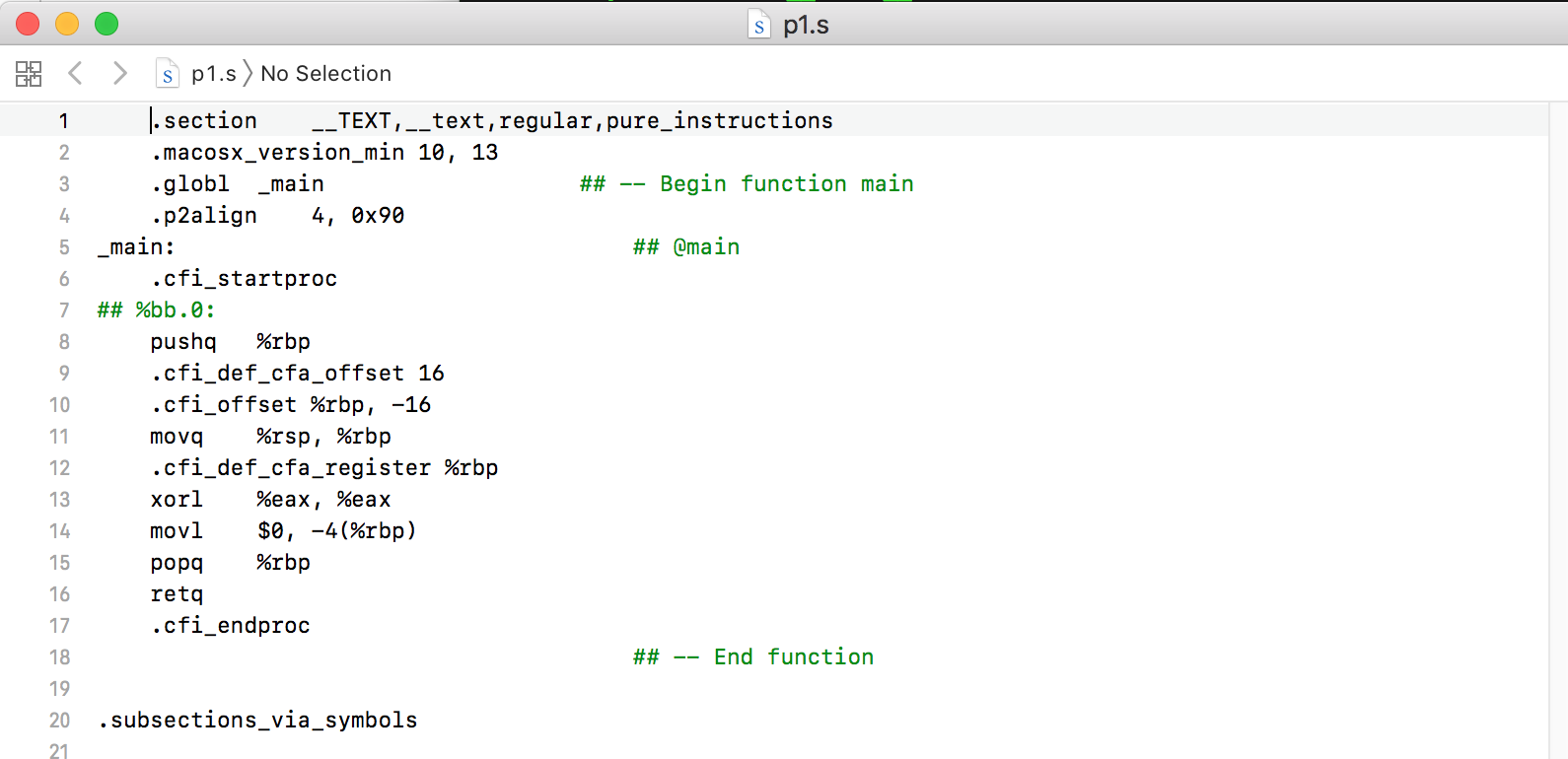

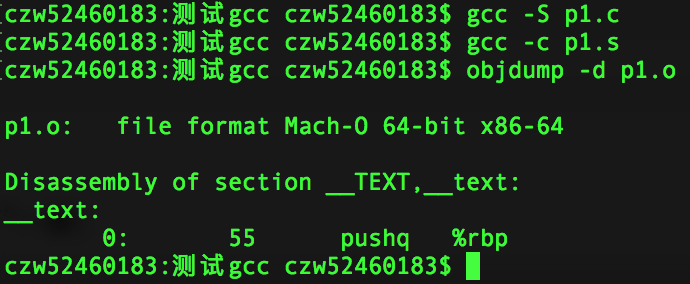
此时可以看到pushq占1个字节,再改成等价的指令来看下:

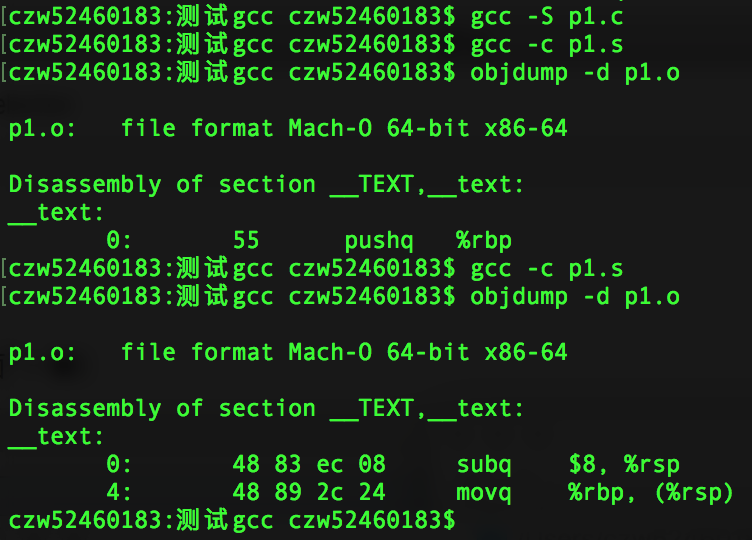
可以看到,变成了8个字节,验证完毕。
对了,有个小知识点,如果汇编语言中想注释怎么办?
答案是和c,c++等一样,//和#都可以实现,可以加上注释再反汇编一下看有没有反汇编到注释的句子来验证,具体就不演示了。
5.类似地,popq会把栈顶的值读出数据,然后再将栈指针+8,注意此时原先栈顶的内容是不变的(虽然栈顶指针已经不指向它了)。
结束!

