
Python基础
Python的语法比较简单,采用缩进方式,写出来的代码就像下面的样子:
a = int(input())
if a >= 0 :
print(a)
else :
print(-a)
以#开头的语句是注释,注释是给人看的,可以是任意内容,解释器会忽略掉注释。其他每一行都是一个语句,当语句以冒号:结尾时,缩进的语句视为代码块。
缩进有利有弊。好处是强迫你写出格式化的代码,但没有规定缩进是几个空格还是Tab。按照约定俗成的管理,应该始终坚持使用4个空格的缩进。
缩进的另一个好处是强迫你写出缩进较少的代码,你会倾向于把一段很长的代码拆分成若干函数,从而得到缩进较少的代码。
缩进的坏处就是“复制-粘贴”功能失效了,这是最坑爹的地方。当你重构代码时,粘贴过去的代码必须重新检查缩进是否正确。此外,IDE很难像格式化Java代码那样格式化Python代码。
最后,请务必注意,Python程序是大小写敏感的,如果写错了大小写,程序会报错。
小结
Python使用缩进来组织代码块,请务必遵守约定俗成的习惯,坚持使用4个空格的缩进。
在文本编辑器中,需要设置把Tab自动转换为4个空格,确保不混用Tab和空格。
数据类型
- 整数 有时候用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2
a = 0xa
print(a)
- 浮点数 科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的,而浮点数运算则可能会有四舍五入的误差
- 字符串 字符串是以单引号'或双引号"括起来的任意文本,如果'本身也是一个字符,那就可以用""括起来
>>>print('\'') # 如果字符串内部既包含'又包含,可以用转义字符\来标识,转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\
'
>>>print('\\\n\\')
\
\
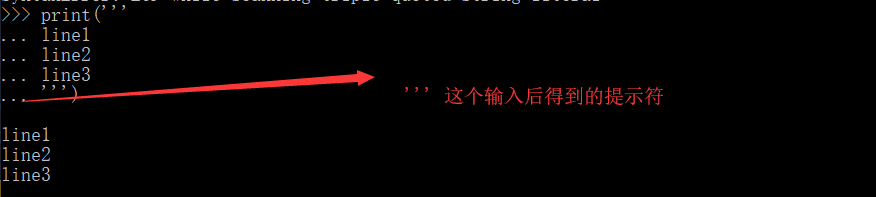
>>>print('''line1 #多行编辑 ’‘’-----‘’‘
line2
line3''')
line1
line2
line3
- 布尔值 布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值 and、or和not运算
- 空值 空值是Python里一个特殊的值,用None表示
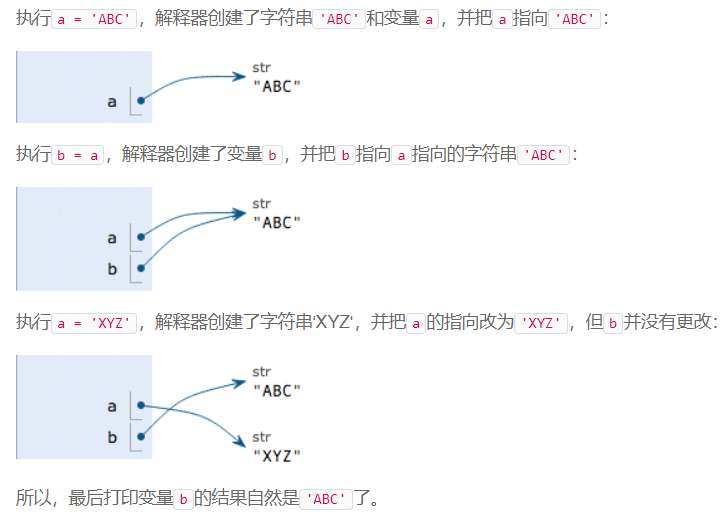
- 变量
a = 123 # a是整数 跟java有所不同 java变量一旦确定 即不可变
print(a)
a = 'ABC' # a变为字符串
print(a)
- 常量
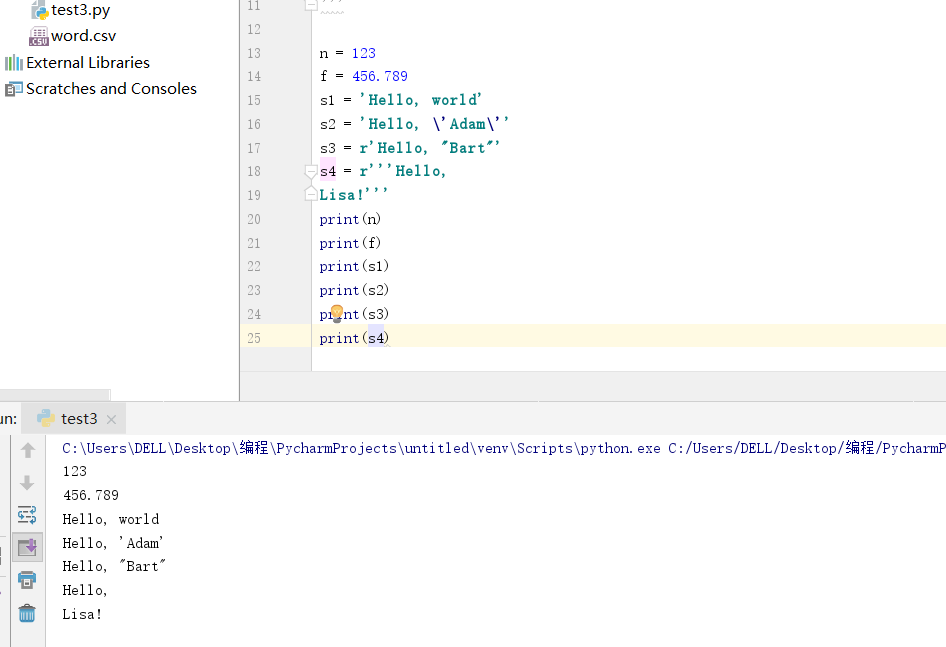
print('''n = 123\n
f = 456.789\n
s1 = \'Hello, world\'\n
s2 = \'Hello, \\'Adam\\'\'\n
s3 = r\'Hello, \"Bart\"\'\n
s4 = r\'\'\'Hello,\n
Lisa!\'\'\'''')
小结
Python支持多种数据类型,在计算机内部,可以把任何数据都看成一个“对象”,而变量就是在程序中用来指向这些数据对象的,对变量赋值就是把数据和变量给关联起来。
对变量赋值x = y是把变量x指向真正的对象,该对象是变量y所指向的。随后对变量y的赋值不影响变量x的指向。
注意:Python的整数没有大小限制,而某些语言的整数根据其存储长度是有大小限制的,例如Java对32位整数的范围限制在-2147483648-2147483647。
Python的浮点数也没有大小限制,但是超出一定范围就直接表示为inf(无限大)。
字符编码
计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:

Python的字符串
- ord()
- chr()
十六进制这么写str
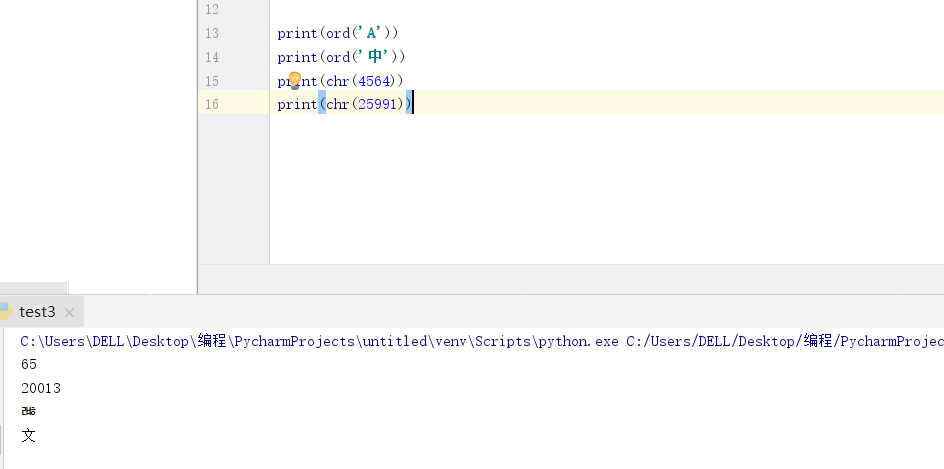
>>>print('\u4e2d\u6587')
中文
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:x = b'ABC' <- 这个是一个bytes类型
- 要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
#纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
>>>print('ABC'.encode('ascii'))
b'ABC'
>>>print('ABC'.encode('utf-8'))
b'ABC'
>>>print('中文'.encode('utf-8'))
b'\xe4\xb8\xad\xe6\x96\x87'
>>>print('中文'.encode('ascii'))
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
# 反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
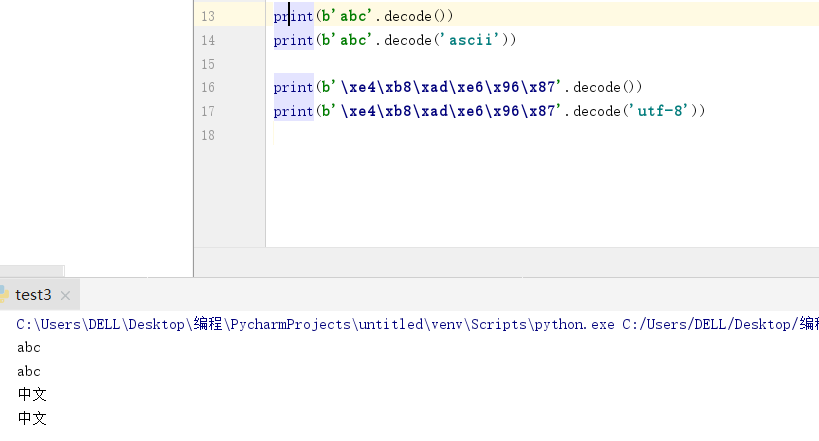
如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
print(b'\xe4\xb8\xad\xff'.decode('utf-8' ,errors ='ignore')) # decode(' ' , errors =' ')
要计算str包含多少个字符,可以用len()函数:
print(len('abafb'))
5
print(len('中文'))
2
len()函数就计算字节数
print(len(b'abc'))
3
print('中文'.encode('utf-8'))
print(len('中文'.encode('utf-8')))
b'\xe4\xb8\xad\xe6\x96\x87'
6
# 1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3 #第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
# -*- coding: utf-8 -*- # 第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。

格式化
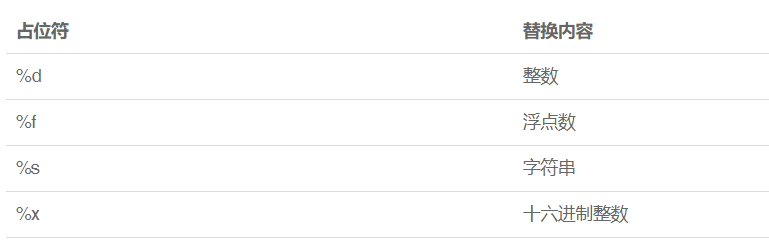
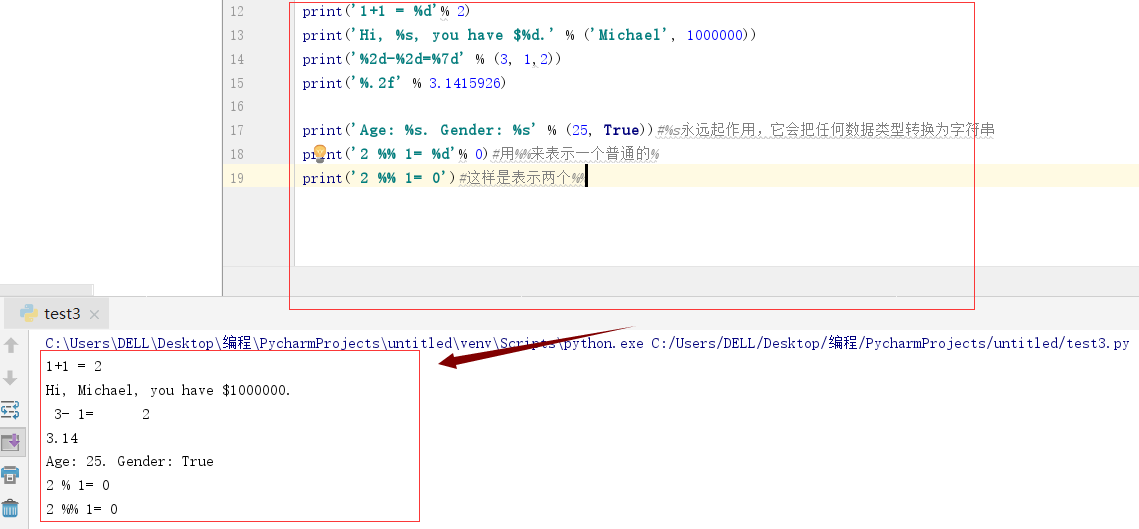
format()
小结
Python 3的字符串使用Unicode,直接支持多语言。
当str和bytes互相转换时,需要指定编码。最常用的编码是UTF-8。Python当然也支持其他编码方式,比如把Unicode编码成GB2312,不支持 容易错

 浙公网安备 33010602011771号
浙公网安备 33010602011771号