
Python爬虫学习
网络爬虫一般分为两个过程:
1.通过网络连接获取网页内容,即以HTML语言写成的网页源代码;(主要是掌握requests库)
2.对获得的网页内容进行处理,可通过re(正则表达式)、beautifulsoup4等函数库来处理。
requests库:
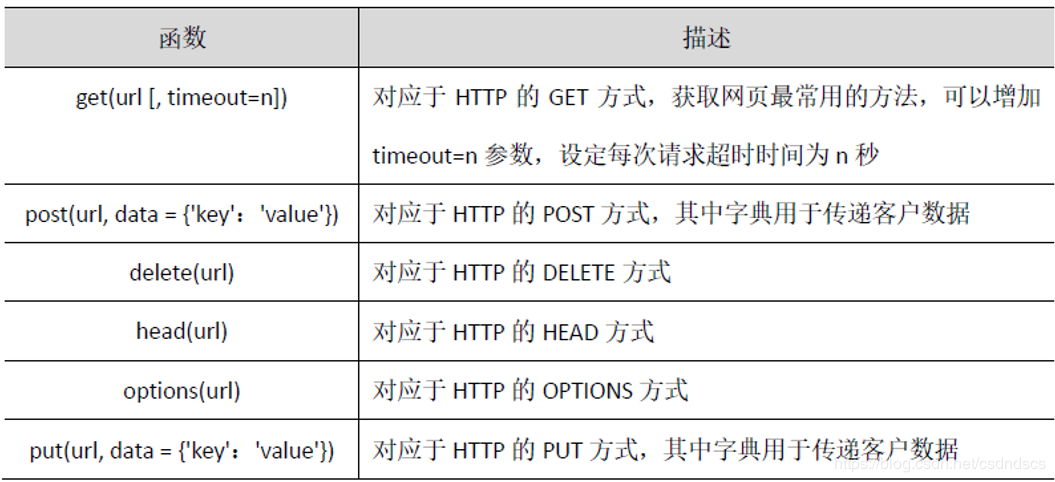
get()是获取网页最常用的方式,在调用requests.get()函数后,返回的网页内容会保存为一个Response对象。其中,get()函数的参数url链接必须采用HTTP或HTTS方式访问。
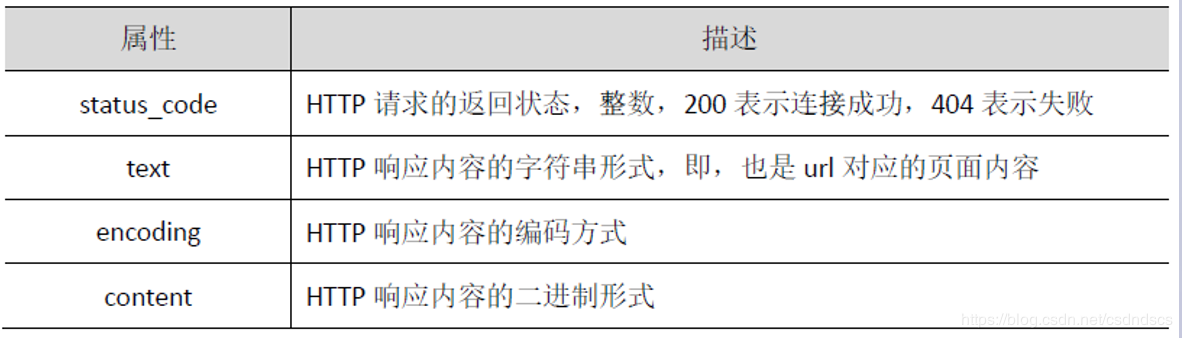
requests.get()代表请求过程,返回的Response对象代表响应。返回内容作为一个对象便于操作,Response对象的属性如下,需要采用<a>.<b>的形式。
beautifulsoup4库:
beautifulsoup4库也称Beautiful Soup或bs4库,采用面向对象思想实现,库中最主要的是BeautifulSoup类。采用from-import导入库中的Beautifulsoup类后,使用BeautifulSoup()创建一个BeautifulSoup对象。
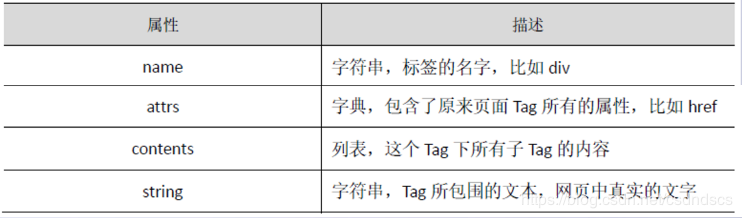
创建的BeautifulSoup对象是一个树形结构,它包含HTML页面中的每一个Tag(标签)元素,如<head>、<body>等。具体来说,HTML中的主要结构都变成了Beautiful对象的一个属性,直接用<a>.<b>形式获得,其中<b>的名字采用HTML中标签的名字,下表为BeautifulSoup对象的常用属性。
由于HTML语法可以在标签中嵌套其他标签,所以,string属性的返回值遵循如下原则:
如果标签内部没有其他标签,string属性返回其中的内容。
如果标签内部还有其他标签,但只有一个标签,string属性返回最里面标签的内容。
如果标签内部有超过1层嵌套的标签,string属性返回None(空字符串)。
HTML语法中同一个标签会有很多内容,例如<a>标签,百度首页一共有多处,直接调用soup.a只能返回第一个。当需要列出标签对应的所有内容或者需要找到非第一个标签时,需要用到BeautifulSoup的find()和find_all()方法。这两个方法会便利整个HTML文档,按照条件返回标签内容。
BeautifulSoup.find_all(name,attrs,recursive,string,limit)
作用:根据参数找到对应标签,返回列表类型。
参数如下。
name:按照Tag标签名字检索,名字用字符串形式表示,如idv、li。
attrs:按照Tag标签属性值检索,需要列出属性名称和值,采用JSON表示。
recursive:设置查找层次,只查找当前标签下一层时使用recursive=False。
string:按照关键字检索string属性内容,采用string=开始。
limit:返回结果的个数,默认返回全部结果。
————————————————
原文链接:https://blog.csdn.net/csdndscs/article/details/94432032

 浙公网安备 33010602011771号
浙公网安备 33010602011771号