flink整理知识点
基本介绍:
介绍:
Spark的技术理念是基于批来模拟流的计算。而Flink则完全相反,它采用的是基于流计算来模拟批计算。
Flink提供高吞吐量、低延迟的流数据引擎以及对事件-时间处理和状态管理的支持。
Spark 虽然支持各种场见场景,但并不是每一种都同样好用。数据流的实时处理就是其中相对较弱的一环。
Flink 凭借更优的流处理引擎,同时也支持各种处理场景,成为 Spark 的有力挑战者。
Spark与Flink对比:
1.数据模型
Spark 的数据模型是弹性分布式数据集 RDD(Resilient Distributed Datasets)。
比起 MapReduce 的文件模型,RDD 是一个更抽象的模型,RDD 靠血缘(lineage) 等方式来保证可恢复性。
很多时候 RDD 可以实现为分布式共享内存或者完全虚拟化(即有的中间结果 RDD 当下游处理完全在本地时可以直接优化省略掉)。
这样可以省掉很多不必要的 I/O,是早期 Spark 性能优势的主要原因。
Spark 用 RDD 上的变换(算子)来描述数据处理。每个算子(如 map,filter,join)生成一个新的 RDD。所有的算子组成一个有向无环图(DAG)。
Spark 比较简单地把边分为宽依赖和窄依赖。上下游数据不需要 shuffle 的即为窄依赖,可以把上下游的算子放在一个阶段(stage) 里在本地连续处理,
这时上游的结果 RDD 可以 省略。
Flink 的基本数据模型是数据流,及事件(Event) 的序列。数据流作为数据的基本模型可能没有表或者数据块直观熟悉,但是可以证明是完全等效的。
流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,这样就是批处理。
Flink 用数据流上的变换(算子)来描述数据处理。每个算子生成一个新的数据流。在算子,DAG,和上下游算子链接(chaining) 这些方面,
和 Spark 大致等价。Flink 的节点(vertex)大致相当于 Spark 的阶段(stage),划分也会和上图的 Spark DAG 基本一样。
2.批流关系
spark底层是批处理,微批处理基于批处理。
flink底层是流处理,批基于流。
区别是:
1.flink的流是每个window内的新到来数据会实时处理(不用window),而spark的微批处理则等待一批数据(设定的interval)到来后,再进行map、reduce
2.flink的流能基于process_time、event_time,而spark的只能process_time,不能和flink一样保证有序(同时间段的数据在同一个window)。
核心组成:
Deploy层:
可以启动单个JVM,让Flink以Local模式运行
Flink也可以以Standalone 集群模式运行,同时也支持Flink ON YARN,Flink应用直接提交到YARN上面运行
Flink还可以运行在GCE(谷歌云服务)和EC2(亚马逊云服务)
Core层(Runtime):
在Runtime之上提供了两套核心的API,DataStream API(流处理)和 DataSet API(批处理)
APIs & Libraries层:核心API之上又扩展了一些高阶的库和API
CEP流处理
Table API和SQL
Flink ML机器学习库
Gelly图计
输入与输出:
source:
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队列)、NIFI(数据管道)、Twitter(API)
批处理方式:包含HDFS(分布式文件系统)、HBase(分布式列式数据库)、Amazon S3(文件系统)、MapR FS(文件系统)、ALLuxio(基于内存分布式文件系统)
sink:
流处理方式:包含Kafka(消息队列)、AWS kinesis(实时数据流服务)、RabbitMQ(消息队列)、NIFI(数据管道)、Cassandra(NOSQL数据库)、ElasticSearch(全文检索)、HDFS rolling file(滚动文件)
批处理方式:包含HBase(分布式列式数据库)、HDFS(分布式文件系统)
架构:
JobManager处理器(StandaloneSessionClusterEntrypoint)
协调分布式执行,它们用来调度task,协调检查点(CheckPoint),协调失败时恢复等
Flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。
JobManager接收的应用包括jar和JobGraph
组成:
ResourceManager
ResourceManager 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位(请参考TaskManagers)。
Flink 为不同的环境和资源提供者(例如 YARN、Mesos、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。
在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
Dispatcher
Dispatcher 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
注意:某些应用的提交执行的方式,有可能用不到Dispat
JobMaster
JobMaster 负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
TaskManager处理器(Slave)也称之为Worker,主要职责是从JobManager处接收任务, 并部署和启动任务, 接收上游的数据并处理
Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点
TaskManager在启动的时候会向ResourceManager注册自己的资源信息(Slot的数量等)
术语:
Task:
一个阶段多个功能相同 SubTask 的集合,类似于 Spark 中的 TaskSet。
SubTask:
SubTask 是 Flink 中任务最小执行单元,是一个 Java 类的实例,这个 Java 类中有属性和方法,完成具体的计算逻辑
比如一个执行操作map,分布式的场景下会在多个线程中同时执行,每个线程中执行的都叫做一个SubTask
Operator chain(操作器链):
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain
实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行
减小了线程之间的切换,减小消息的序列化和反序列化,减小数据在缓冲区的交换,提高了整体的吞吐量
条件:
上下游的并行度相同,入度为1
同在一个slot group中
chain策略,没有禁用
数据传输:
在运行过程中,应用中的任务会持续进行数据交换。为了有效利用网络资源和提高吞吐量,Flink在处理任务间的数据传输过程中,采用了缓冲区机制。
任务槽:
每个TaskManager是一个JVM的进程, 可以在不同的线程中执行一个或多个子任务。
为了控制一个TaskManager能接收多少个task。worker的TaskManager通过task slot来进行控制(一个worker至少有一个task slot)
每个task slot表示TaskManager拥有资源的一个固定大小的子集。 一般来说:我们分配槽的个数都是和CPU的核数相等,比如6核,那么就分配6个槽.
槽共享:
默认情况下,Flink允许子任务subtast(map[1] map[2] keyby[1] keyby[2] 共享插槽,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个槽可以保存作业的整个管道。
安装和部署:
下载:
wget http://apache.01link.hk/flink/flink-1.8.0/flink-1.8.1-bin-scala_2.11.tgz
tar zxf flink-1.8.1-bin-scala_2.11.tgz
standalone部署:
cd flink-1.8.1/
修改配置flink-conf.yaml
jobmanager.rpc.address: hdp-1
taskmanager.numberOfTaskSlots: 2
修改masters和workers文件
添加环境变量
启动:
./bin/start-cluster.sh 运行集群,访问web url:HTTP://localhost:8081
运行示例:
./flink run ../examples/streaming/WordCount.jar
停止:
./bin/stop-cluster.sh
Yarn模式部署:
共享YARN session:
环境变量:
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
启动:
yarn-session.sh -s 2 -tm 1024 -jm 1024 -d
提交作业:
flink run -yid xxxxx
每个作业单独的session:
提交:
flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -c mainClass path/to/jar
注意1.10后新版本yn参数不再支持,而是动态根据并行度来设置。
-p 10
作业failed问题定位:
flink日志路径: 对应运行节点上的/data/emr/flink/logs/flink.log
容器日志路径:/data/emr/yarn/logs/yarn-hadoop-nodemanager-{对应的节点ip,如10.0.0.8}.log
Web UI:
点击yarn集群上的链接
删除:
yarn application -kill application_1527077715040_0003
client启动异常日志:
${FLINK_HOME}/log/flink-${USER}-client-<HOSTNAME>.log
History Server:
概述:
History Server允许查询由JobManager归档的已完成作业的状态和统计信息。已完成作业的归档在JobManager上进行,JobManager会将归档的作业信息upload到文件系统目录,这个文件系统可以是本地文件系统、HDFS、H3等,这个目录是可以在配置文件中指定的。然后还需要配置History Server去扫描这个目录,并且可以配置扫描的间隔时间。
配置:
jobmanager.archive.fs.dir: hdfs://hadoop01:8020/completed-jobs/ 指定由JobManager归档的作业信息所存放的目录,这里使用的是HDFS
historyserver.archive.fs.dir: hdfs://hadoop01:8020/completed-jobs/ 指定History Server扫描哪些归档目录,多个目录使用逗号分隔
historyserver.archive.fs.refresh-interval: 10000 指定History Server间隔多少毫秒扫描一次归档目录
historyserver.web.address: 0.0.0.0 History Server所绑定的ip,0.0.0.0代表允许所有ip访问
historyserver.web.port: 8082 指定History Server所监听的端口号
启动:
./bin/historyserver.sh start
作业提交流程:
flink集群模式流程:
1、在Flink Client中,通过反射启动jar中的main函数,生成Flink StreamGraph和JobGraph。将JobGraph和libraries提交给JobManager。
2、JobManager收到JobGraph后,将JobGraph翻译成ExecutionGraph,然后开始调度执行,启动成功之后开始消费数据
yarn模式流程:
1.Client 端提交任务,yarn的Resource Manager接收请求后,启动Application Master,作为JobManager
2.Jobmanager向 Resource Manager 申请TaskManager的资源,并调度任务ExecutionGraph给TaskManager执行。
3.taskManager执行任务,反馈进度。
DAG:
StreamGraph -> JobGraph -> ExecutionGraph -> TaskGraph
DataSet Api:
输入:
基于集合
fromCollection(Collection),主要是为了方便测试使用
基于文件
readTextFile(path),基于HDFS中的数据进行计算分析
Transformation操作:
map、flatmap等
输出:
writeAsText():将元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取
writeAsCsv():将元组以逗号分隔写入文件中,行及字段之间的分隔是可配置的,每个字段的值来自对象的toString()方法
print()/pringToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中
自定义输出addSink
DataStream API:
概述:
Flink中的DataStream程序是实现数据流转换的常规程序(例如,Filter,更新状态,定义窗口,聚合)。
最初从各种源(例如,消息队列,套接字流,文件)创建数据流。结果通过接收器返回,接收器可以例如将数据写入文件或标准输出(例如命令行终端)
输入:
1、基于文件
readTextFile(path)读取文本文件,文件遵循TextInputFormat逐行读取规则并返回
2、基于Socket
socketTextStream从Socket中读取数据,元素可以通过一个分隔符分开
3、基于集合
fromCollection(Collection)通过Java的Collection集合创建一个数据流,集合中的所有元素必须是相同类型的
如果满足以下条件,Flink将数据类型识别为POJO类型(并允许“按名称”字段引用):
该类是共有且独立的(没有非静态内部类)
该类有共有的无参构造方法
类(及父类)中所有的不被static、transient修饰的属性要么有公有的(且不被final修饰),要么是包含共有的getter和setter方法,这些方法遵循java bean命名规范。
4、自定义输入
可以使用StreamExecutionEnvironment.addSource(sourceFunction)将一个流式数据源加到程序中。
Flink提供了许多预先实现的源函数,但是也可以编写自己的自定义源,方法是为非并行源implements SourceFunction,或者为并行源 implements ParallelSourceFunction接口,
或者extends RichParallelSourceFunction。
内置的Connector:
连接器 是否提供Source支持 是否提供Sink支持
Apache Kafka 是 是
ElasticSearch 否 是
HDFS 否 是
Twitter Streaming PI 是 否
kafka Consumer:
依赖:
flink-connector-kafka_2.11
实例化:
构造函数接受以下参数:
Topic 名称或者名称列表
用于反序列化 Kafka 数据的 DeserializationSchema 或者 KafkaDeserializationSchema
Kafka 消费者的属性。需要以下属性:
“bootstrap.servers”(以逗号分隔的 Kafka broker 列表)
“group.id” 消费组 ID
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer<>("topic", new SimpleStringSchema(), properties));
DeserializationSchema:
概述:
Flink Kafka Consumer 需要知道如何将 Kafka 中的二进制数据转换为 Java 或者 Scala 对象。KafkaDeserializationSchema 允许用户指定这样的 schema,每条 Kafka 中的消息会调用 T deserialize(ConsumerRecord<byte[], byte[]> record) 反序列化。
分类:
1.TypeInformationSerializationSchema(和 TypeInformationKeyValueSerializationSchema) 基于 Flink 的 TypeInformation 创建 schema。
如果该数据的读和写都发生在 Flink 中,那么这将是非常有用的。此 schema 是其他通用序列化方法的高性能 Flink 替代方案。
2.JsonDeserializationSchema(和 JSONKeyValueDeserializationSchema)将序列化的 JSON 转化为 ObjectNode 对象,可以使用 objectNode.get("field").as(Int/String/...)() 来访问某个字段。
KeyValue objectNode 包含一个含所有字段的 key 和 values 字段,以及一个可选的"metadata"字段,可以访问到消息的 offset、partition、topic 等信息。
已在Flink 1.8中删除。
3.AvroDeserializationSchema 使用静态提供的 schema 读取 Avro 格式的序列化数据。 它能够从 Avro 生成的类(AvroDeserializationSchema.forSpecific(...))中推断出 schema,或者可以与 GenericRecords 一起使用手动提供的 schema(用 AvroDeserializationSchema.forGeneric(...))。此反序列化 schema 要求序列化记录不能包含嵌入式架构!
4.SimpleStringSchema 解析为字符串,再自己通过Gson.fromJson转化为json对象。
初始Offset位置:
setStartFromGroupOffsets(默认方法):从 Kafka brokers 中的 consumer 组(consumer 属性中的 group.id 设置)提交的偏移量中开始读取分区。 如果找不到分区的偏移量,那么将会使用配置中的 auto.offset.reset 设置。
setStartFromEarliest() 或者 setStartFromLatest():从最早或者最新的记录开始消费,在这些模式下,Kafka 中的 committed offset 将被忽略,不会用作起始位置。
setStartFromTimestamp(long):从指定的时间戳开始。对于每个分区,其时间戳大于或等于指定时间戳的记录将用作起始位置。
如果一个分区的最新记录早于指定的时间戳,则只从最新记录读取该分区数据。在这种模式下,Kafka 中的已提交 offset 将被忽略,不会用作起始位置。
容错恢复:
概述:
伴随着启用 Flink 的 checkpointing 后,Flink Kafka Consumer 将使用 topic 中的记录,并以一致的方式定期检查其所有 Kafka offset 和其他算子的状态。如果 Job 失败,Flink 会将流式程序恢复到最新 checkpoint 的状态,并从存储在 checkpoint 中的 offset 开始重新消费 Kafka 中的消息。
条件:
为了使 Kafka Consumer 支持容错,需要在 执行环境 中启用拓扑的 checkpointing。
如果未启用 checkpoint,那么 Kafka consumer 将定期向 kafka broker 提交 offset。
提交offset:
概述:
Flink Kafka Consumer 允许有配置如何将 offset 提交回 Kafka broker 的行为。请注意:Flink Kafka Consumer 不依赖于提交的 offset 来实现容错保证。提交的 offset 只是一种方法,用于公开 consumer 的进度以便进行监控。
启用:
配置 offset 提交行为的方法是否相同,取决于是否为 job 启用了 checkpointing。
禁用 Checkpointing: 如果禁用了 checkpointing,则 Flink Kafka Consumer 依赖于内部使用的 Kafka client 自动定期 offset 提交功能。
因此,要禁用或启用 offset 的提交,只需将 enable.auto.commit 或者 auto.commit.interval.ms 的Key 值设置为提供的 Properties 配置中的适当值。
启用 Checkpointing: 如果启用了 checkpointing,那么当 checkpointing 完成时,Flink Kafka Consumer 将提交的 offset 存储在 checkpoint 状态中。
这确保 Kafka broker 中提交的 offset 与 checkpoint 状态中的 offset 一致。 用户可以通过调用 consumer 上的 setCommitOffsetsOnCheckpoints(boolean) 方法来禁用或启用 offset 的提交(默认情况下,这个值是 true )。 注意,在这个场景中,Properties 中的自动定期 offset 提交设置会被完全忽略。
watermark:
定期:
myConsumer.assignTimestampsAndWatermarks(
WatermarkStrategy.
.forBoundedOutOfOrderness(Duration.ofSeconds(20)));
输出:
writeAsText():讲元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取
print()/printToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中
自定义输出:addSink可以实现把数据输出到第三方存储介质中
如redis
Transformation操作:
=========DataStream操作,无状态===========
Map
FlatMap
Filter
KeyBy输出KeyedStream
Union
join
coGroup
connect输出ConnectedStreams
Split输出SplitStream
Select
Iterate
=========KeyedStream操作===========
keyBy 从DataStream转化为KeyedStream。
Reduce
Fold
Aggregations类操作,如sum\max\min,默认永久有状态,除非加上window后才会清空之前状态(一般自己写keyed state,自己clear或者设置ttl)
IntervalJoin
=========window操作===========
Window 转换为windowStream,有countWindow和timeWindow之分。
WindowAll 适合非keyby stream
Window Apply 传入WindowFunction,已过时。旧版的 ProcessWindowFunction,只能提供更少的环境信息且缺少一些高级的功能,比如 per-window state。 这个接口会在未来被弃用。
不与state合用。window本身带有窗口内的数据。
Window Reduce 传入ReduceFunction
Window Fold
Window Aggregate 传入Aggregation接口,有如下几个方法: 把每一条元素加进累加器、创建初始累加器、合并两个累加器、从累加器中提取输出(OUT 类型)。
Window Process 传入ProcessWindowFunction接口能获取包含窗口内所有元素的 Iterable, 以及用来获取时间和状态信息的 Context 对象,比其他窗口函数更加灵活。
增量聚合的 ProcessWindowFunction ProcessWindowFunction可以与 ReduceFunction 或 AggregateFunction 搭配使用, 使其能够在数据到达窗口的时候进行增量聚合。
=========ConnectedStreams操作===========
CoMap
CoFlatMap
Window窗口机制:
概述:
Flink要操作窗口,先得将StreamSource 转成WindowedStream
不一定keyed stream,注意非keyed stream不能并行处理。
keyedStream对应timewindow,非keyedStream对应timewindowAll
分类:
翻滚窗口 (Tumbling Window, 无重叠),可以按照固定时间或者固定数量
滑动窗口 (Sliding Window, 有重叠)
会话窗口 (Session Window, 活动间隙)
全局窗口 (略)
滚动窗口(Tumbling Window):
概述:
将数据依据固定的窗口长度对数据进行切分
特点:
窗口长度固定,没有重叠
示例:
基于时间驱动
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> timeWindow = keyedStream.timeWindow(Time.seconds(10));
timeWindow.apply(new MyTimeWindowFunction()).print(); // MyTimeWindowFunction类需要继承自WindowFunction
等价于
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
基于事件驱动
WindowedStream<Tuple2<String, Integer>, Tuple, GlobalWindow> countWindow = keyedStream.countWindow(3);
countWindow.apply(new MyCountWindowFunction()).print()
滑动窗口(Sliding Window):
概述:
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
特点:
窗口长度固定,可以有重叠
示例:
基于时间驱动
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> timeWindow = keyedStream.timeWindow(Time.seconds(10), Time.seconds(5));
timeWindow.apply(new MyTimeWindowFunction()).print(); // MyTimeWindowFunction类需要继承自WindowFunction
等价于:
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
基于事件驱动
WindowedStream<Tuple2<String, Integer>, Tuple, GlobalWindow> countWindow = keyedStream.countWindow(3, 2);
countWindow.apply(new MyCountWindowFunction()).print()
会话窗口(Session Window):
概述:
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据后,之前的窗口才会关闭,生成新的窗口。
特点
会话窗口不重叠,没有固定的开始和结束时间
session窗口在一个固定的时间周期内不再收到元素,即非活动间隔产生,那么这个窗口就会关闭。
后续的元素将会被分配给新的会话窗口
示例:
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> window = keyedStream.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)));
window.apply(new MyTimeWindowFunction()).print();
固定间隔的会话窗口:
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
动态间隔的会话窗口:
session gap extractor 函数
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隔
}))
Time概念:
分类:
1.EventTime[事件时间]
事件发生的时间,例如:点击网站上的某个链接的时间,每一条日志都会记录自己的生成时间
如果以EventTime为基准来定义时间窗口那将形成EventTimeWindow,要求消息本身就应该携带EventTime
设定:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //设置使用事件时间
2.IngestionTime[摄入时间]
数据进入Flink的时间,如某个Flink节点的source operator接收到数据的时间,例如:某个source消费到kafka中的数据
如果以IngesingtTime为基准来定义时间窗口那将形成IngestingTimeWindow,以source的systemTime为准
3.ProcessingTime[处理时间](默认)
某个Flink节点执行某个operation的时间,例如:timeWindow处理数据时的系统时间,默认的时间属性就是Processing Time
如果以ProcessingTime基准来定义时间窗口那将形成ProcessingTimeWindow,以operator的systemTime为准
水印watermark:
概述:
防止 数据乱序(一般的window不能明确数据是否全部到位,又不能无限期的等下去)
防止 指定时间内获取不到全部数据。
与调大window窗口的区别:
窗口并不变大,而是允许在读取window_end_time的数据后,还允许window_end_time+延迟时间的数据(比如事件时间)到来前,继续接收更小的数据放入该窗口。
(按照数据的事件时间来更新watermark,更大事件时间的数据将会放入下一个窗口,但当前窗口仍未触发。)
总结:
[window_end_time,window_end_time+延迟时间)内的数据会流入下一个窗口,当前窗口仍在接收数据。
作用:
当数据流添加水印后,作为数据流的一部分随数据流流动。(触发后才放入数据流)
只有水位线越过窗口对应的结束时间,窗口才会关闭和进行计算。
如何生成水印:
每个消息到来后,获取该event time,比较该event time-允许延迟时间和当前水印的最大值存到全局变量,每间隔指定时间(默认200ms),获取最大值作为当前流的新水印。
窗口划分规则:
当使用EventTimeWindow时,按照设置的time window数值,事先在EventTime的时间轴上进行划分。
比如
window大小为4,那么每一分钟都被划分为了[00:00:00,00:00:04),[00:00:04,00:00:08)....
窗口是左闭右开的,形式为:[window_start_time,window_end_time)。
Window会一直按照指定的时间间隔进行划分,不论这个Window中有没有数据,EventTime在这个Window期间的数据会进入这个Window。
Window会不断产生,属于这个Window范围的数据会被不断加入到Window中,所有未被触发的Window都会等待触发。
只要Window还没触发,属于这个Window范围的数据就会一直被加入到Window中,直到Window被触发才会停止数据的追加,而当Window触发之后才接受到的属于被触发Window的数据会被丢弃。
如果水印时间超过了窗口的end_time,而且一直没有数据,也会关闭,后续的数据不能再加入。(已测试)
触发窗口计算的规则:
(1)在[window_start_time,window_end_time)窗口中有数据存在
(2)watermark时间 >= window_end_time;
此后,放置一个watermark进入运算符。
生成方式:
1.assignAscendingTimestamps(element => sdf.parse(element.createTime).getTime)系统通过跟踪上升时间戳自动且完美地生成水印。
2.assignTimestampsAndWatermarks(assigner: AssignerWithPeriodicWatermarks[T])周期性,更加灵活
2.assignTimestampsAndWatermarks(assigner: WatermarkStrategy[T])周期性,新版1.11的接口
生成示例:
SingleOutputStreamOperator<Tuple2<String, Long>> watermarks = maped.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple2<String, Long>>() {
Long currentMaxTimestamp = 0l; //保存当前最大值水印
final Long maxOutOfOrderness = 3000l; //允许延迟时间
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
@Override
public long extractTimestamp(Tuple2<String, Long> element, long previousElementTimestamp) {
long timestamp = element.f1;
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
return timestamp;
}
}); //不用lambda表达式的原因: 需要序列化
watermarks.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(4))).apply()//注意watermark本身没有设置窗口的大小,只负责延迟时间
空闲Sources:
目前,对于纯事件时间水印生成器,如果没有要处理的数据元,则水印不会更新。这意味着在输入数据存在间隙的情况下,事件时间将不会更新,
导致窗口算子将不会被触发,因此现有窗口将不能产生任何输出数据。
为了避免这种情况,可以使用周期水印分配器,它不仅基于数据元的时间戳进行分配。
一个示例解决方案可以是在不观察新事件一段时间之后切换到使用当前处理时间作为时间基础的分配器。
源通过SourceFunction.SourceContext#markAsTemporarilyIdle可以标记为空闲。有关详细信息,请参阅此方法的Javadoc以及StreamStatus。
allowLateNess:
将窗口关闭时间再延迟一段时间。
sideOutPut:
最后兜底把延迟数据导出到其他地方。
状态state:
概览:
用来保存计算结果或缓存数据。
状态种类:
原生状态(Raw State):
开发者自己管理的,需要自己序列化。
只支持字节,任何上层数据结构需要序列化为字节数组。
托管状态(Managed State):
由Flink管理的,Flink帮忙存储、恢复和优化。
支持了一系列常见的数据结构,如ValueState、ListState、MapState等。
按照是否有key划分状态种类:
Keyed State:
概述:
KeyedStream流上的每一个Key都对应一个State,各自访问。
状态分类:
ValueState:即类型为T的单值状态。这个状态与对应的key绑定,是最简单的状态了。它可以通过update 方法更新状态值,通过value() 方法获取状态值。
ListState:即key上的状态值为一个列表。可以通过add 方法往列表中附加值;也可以通过get()方法返回一个Iterable<T> 来遍历状态值。
ReducingState:这种状态通过用户传入的reduceFunction,每次调用add 方法添加值的时候,会调用reduceFunction,最后合并到一个单一的状态值。
FoldingState:跟ReducingState有点类似,不过它的状态值类型可以与add 方法中传入的元素类型不同(这种状态将会在Flink未来版本中被删除)。
MapState:即状态值为一个map。用户通过put 或putAll 方法添加元素
如何使用:
1.KeyedState需要重写RichFunction类,如flatMap要重写RichFlatMapFunction类
2.定义Descriptor状态描述符(ValueStateDescriptor,ListStateDescriptor, AggregatingStateDescriptor, ReducingStateDescriptor 或 MapStateDescriptor。)
3.使用getRuntimeContext.getState(…Descriptor)管理state(状态通过 RuntimeContext 进行访问,因此只能在 rich functions 中使用。)
过期时间TTL:
TTL时间更新机制:
StateTtlConfig.UpdateType.OnCreateAndWrite: 只在一个 key 的 state 创建和写入时更新。TTL(默认)
StateTtlConfig.UpdateType.OnReadAndWrite: 读取 state 时仍然更新 TTL
数据可见性:
数据在过期但还未被清理时的可见性配置如下(默认为 NeverReturnExpired):
StateTtlConfig.StateVisibility.NeverReturnExpired - 不返回过期数据
StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp - 会返回过期但未清理的数据
注意事项:
状态上次的修改时间会和数据一起保存在 state backend 中,因此开启该特性会增加状态数据的存储。 Heap state backend 会额外存储一个包括用户状态以及时间戳的 Java 对象,RocksDB state backend 会在每个状态值(list 或者 map 的每个元素)序列化后增加 8 个字节。
暂时只支持基于 processing time 的 TTL。
尝试从 checkpoint/savepoint 进行恢复时,TTL 的状态(是否开启)必须和之前保持一致,否则会遇到 “StateMigrationException”。
TTL 的配置并不会保存在 checkpoint/savepoint 中,仅对当前 Job 有效。
当前开启 TTL 的 map state 仅在用户值序列化器支持 null 的情况下,才支持用户值为 null。如果用户值序列化器不支持 null, 可以用 NullableSerializer 包装一层。
State TTL 当前在 PyFlink DataStream API 中还不支持。
过期数据的清理:
默认情况下,过期数据会在读取的时候被删除,例如 ValueState#value,同时会有后台线程定期清理(如果 StateBackend 支持的话)。可以通过 StateTtlConfig 配置关闭后台清理:
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.disableCleanupInBackground()
.build();
全量快照时进行清理:
另外,你可以启用全量快照时进行清理的策略,这可以减少整个快照的大小。当前实现中不会清理本地的状态,但从上次快照恢复时,不会恢复那些已经删除的过期数据。
该策略可以通过 StateTtlConfig 配置进行配置:
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build();
这种策略在 RocksDBStateBackend 的增量 checkpoint 模式下无效。
增量数据清理:
另外可以选择增量式清理状态数据,在状态访问或/和处理时进行。如果某个状态开启了该清理策略,则会在存储后端保留一个所有状态的惰性全局迭代器。 每次触发增量清理时,从迭代器中选择已经过期的数进行清理。
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(10, true)
.build();
示例:
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)) // 状态存活时间
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // TTL 何时被更新,这里配置的 state 创建和写入时
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();// 设置过期的 state 不被读取
stateDescriptor.enableTimeToLive(ttlConfig);
示例:
keyed.flatMap(new RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>>()
{
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long,Long>> out) throws Exception {
Tuple2<Long, Long> currentSum = sum.value();
currentSum.f0 += 1;
currentSum.f1 += value.f1;
sum.update(currentSum);
if(currentSum.f0 >= 5) {
out.collect(new Tuple2<>(value.f0,currentSum.f1 / currentSum.f0)); //可以自己决定什么时候输出
sum.clear();
}
}
@Override
public void open(Configuration parameters) throws Exception { //open方法一般用于初始化,一般的FlatMapFunction没有open方法,只有flatMap方法。
ValueStateDescriptor<Tuple2<Long, Long>> descriptor = new ValueStateDescriptor<>(
"average",
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>(){}),
Tuple2.of(0L, 0L)
);
sum = getRuntimeContext().getState(descriptor);
}
});
Operator State:
概述:
每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
相对于KeyedState,OperatorState可以使用在非key by的算子中。
应用场景:
OpeartorState不常用,主要用于source/sink节点,比如bufferSink。
存储形式:
当前 operator state 以 list 的形式存在。这些状态是一个 可序列化 对象的集合 List,彼此独立,方便在改变并发后进行状态的重新分派。
换句话说,这些对象是重新分配 non-keyed state 的最细粒度。
状态分类与分配模式:
ListState + Even-split redistribution
当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配。
比如说,算子 A 的并发读为 1,包含两个元素 element1 和 element2,当并发读增加为 2 时,element1 会被分到并发 0 上,element2 则会被分到并发 1 上。
UnionListState
如果并行度发生改变,会将上游的state合并,然后通过广播的方式全部发送给下游每一个节点。
当作业恢复或重新分配时,每个算子都将获得所有的状态数据。慎用,如果状态太多,会出现RPC报太大,或者OOM的情况。
广播状态:
概述:
BroadcastState是一种特殊的OperatorState。它主要用于将一些小数据量的A流以广播的形式发送到B流的每一个Operator中,B流在计算的时候就可以使用A流的数据。
广播流是k-v的形式保存的,就类似于Map,可以同时保存很多广播流,以Key值来区分。
应用:
大小流的join,小流可以使用广播的形式。
可以用于动态参数管理。大流计算的时候依赖动态参数做适当的逻辑,可以在广播流中获取更新。
CEP。将模式广播,然后分区的输入流和模式进行匹配,筛选出与模式匹配的数据。
示例:
MapStateDescriptor<Void, MyPattern> bcStateDescriptor = new MapStateDescriptor<>("patterns", Types.VOID, Types.POJO(MyPattern.class));
BroadcastStream<MyPattern> broadcastPatterns = patterns.broadcast(bcStateDescriptor);
SingleOutputStreamOperator<Tuple2<Long, MyPattern>> process = keyed.connect(broadcastPatterns).process(new PatternEvaluator()) //connect操作将两个流连接
其中PatternEvaluator定义open、processElement、processBroadcastElement方法。
通过ctx.getBroadcastState(new MapStateDescriptor<>("patterns", Types.VOID, Types.POJO(MyPattern.class)))来获取广播状态。
如何实现:
实现CheckpointedFunction或简化版的ListCheckpointed接口(只支持ListState)
this.bufferedElements = new ArrayList<Tuple2<Long,Long>>();
public void snapshotState(FunctionSnapshotContext context) throws Exception
{
System.out.println("...snapshotState");
checkpointedState.clear(); // 清空 ListState,我们要放入最新的数据啦
for (Tuple2<Long,Long> element : bufferedElements) {
checkpointedState.add(element); // 把当前局部变量中的所有元素写入到 checkpoint 中,保存状态
}
}
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<Long, Long>> descriptor =
new ListStateDescriptor<>("buffered-elements", TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
if(context.isRestored()) { // 需要处理从 checkpoint/savepoint 恢复的情况
for(Tuple2<Long,Long> element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
// 实现invoke方法,每来一条数据进行触发一次。
public void invoke(Tuple2<Long, Long> value, Context context) throws Exception {
bufferedElements.add(value);
if(bufferedElements.size() == threshold) {
for (Tuple2<Long,Long> element : bufferedElements) {
}
bufferedElements.clear();
}
}
flatMaped.addSink(new BufferingSink(1));
应用:
Kafka连接器是Flink在使用Operator State的一个很好例子。
每个并行的 kafka consumer 实例维护了每个 kafka topic 分区和该分区 offset 的映射关系,并将这个映射关系保存为 Operator state。
在算子并行度改变时,Operator State 也会重新分配。
状态存储后端:
概述:
Flink 的一个重要特性就是有状态计算(stateful processing)。Flink 提供了简单易用的 API 来存储和获取状态。但是,我们还是要理解 API 背后的原理,才能更好的使用。
分类:
MemoryStateBackend:
MemoryStateBackend 将工作状态数据保存在 taskmanager 的 java 内存中。key/value 状态和window 算子使用哈希表存储数值和触发器。
进行快照时(checkpointing),生成的快照数据将和checkpoint ACK 消息一起发送给 jobmanager,jobmanager 将收到的所有快照保存在 java 内存中。
MemoryStateBackend 现在被默认配置成异步的,这样避免阻塞主线程的 pipline 处理。
适合的场景:
本地开发和调试
状态很小的作业,这种方式显然不能存储过大的状态数据,否则将抛出OutOfMemoryError异常。因此,这种方式只适合调试或者实验,不建议在生产环境下使用。
env.setStateBackend(new MemoryStateBackend(MAX_MEM_STATE_SIZE))
FsStateBackend(1.13已经过时):
概述:
FsStateBackend 需要配置一个 checkpoint 路径,一般配置为 hdfs 目录
Flink的本地状态仍然在TaskManager的内存堆区上,直到执行快照时状态数据会写到所配置的文件系统上。因此,这种方式能够享受本地内存的快速读写访问,也能保证大容量状态作业的故障恢复能力。
支持同步和异步快照。
不支持增量快照。
适合场景:
大状态、长窗口、大键值(键或者值很大)状态的作业
适合高可用方案
配置:
代码:
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
配置文件:
state.backend、state.checkpoints.dir
命令行参数:
-yD state.backend=filesystem \
-yD state.checkpoints.dir=hdfs://HDFS14992/flink-checkpoints/zgstat_kafka_to_redis
作业重启:
点击页面cancel jon,作业停止时,会保存checkpoint一次。
作业停止后,目录并不会删除。
作业再次启动后,如果逻辑没有改变,会自动读取最新checkpoint。
RocksDBStateBackend:
概述:
RocksDB 是一种可嵌入的持久型的 key-value 存储引擎,提供 ACID 支持。由 Facebook 基于 levelDB开发,使用 LSM 存储引擎,是内存和磁盘混合存储(类似Hbase)。
RocksDB 本地状态存储在本地内嵌的RocksDB上,先保存到内存(写请求效率高),再flush到配置好的文件路径state.backend.rocksdb.localdir,当触发checkpoint时,将全部数据库的内容会被保存到state.checkpoints.dir上。
元数据保存到jobmanager的内存中,或者高可用模式下保存到metadata的checkpoint路径。
比起FsStateBackend的本地状态存储在内存(即托管内存的部分内存)中,RocksDB利用了磁盘空间,所以可存储的本地状态更大。
然而,每次从RocksDB中读写数据都需要进行序列化和反序列化,因此读写本地状态的成本更高。
架构:
 image-20220203141632192
image-20220203141632192写入流程:
writeOp先写入Active MemTable,当ActiveMemTable满了后,切换为ReadOnlyMemTable,flush到localDisk,存为sst文件。
多个sst文件会后台merge,compaction
读取流程:
ReadOp会读取ActiveMemTable,ReadOnlyMemTable和ReadOnly BlockCache,当ReadOnly BlockCache没有时,会读取LocalDisk。
适用场景:
状态非常大、窗口非常长、key/value 状态非常大的 Job。
适合高可用
增量checkpoint
开启State访问性能监控:
概述:
Flink 1.13中引入了 State 访问的性能监控,即 latency trackig state 。 此功能不局限于 State Backend 的类型,自定义实现的 State Backend 也可以复用此功能。
State访问的性能监控会产生一定的性能影响,所以,默认每 100 次做一次取样( 对不同的 State Backend 性能损失影响不同):
对于RocksDB State Backend ,性能损失大概在 1% 左右
对于Heap State Backend ,性能损失最多可达 10%
配置:
state.backend.latency-track.keyed-state-enabled true 启用访问状态的性能监控
state.backend.latency-track.sample-interval : 100 # 采样间隔
state.backend.latency-track.history-size : 128 保留的采样数据个数,越大越精确
state.backend.latency-track.state-name-as-variable : true 将状态名作为变量
常见监控指标(单位ns):
读取延迟最大值/中间值/P75/P99
写入延迟
增量检查点:
概述:
RocksDB是目前唯一可用于支持有状态流处理应用程序增量检查点的状态后端
开启:
提交参数
state.backend.incremental=true # 默认 false ,改为 true 。
或代码中指定
new EmbeddedRocksDBStateBackend(true)
开启本地恢复:
概述:
当Flink 任务失败时,可以基于本地的状态信息进行恢复任务,可能不需要从hdfs拉取数据。
本地恢复目前仅涵盖 键控类型的状态 后端 RocksDB MemoryStateBackend不支持本地恢复并忽略此选项。
配置:
state.backend.local-recovery: true
设置多目录:
概述:
如果有多块磁盘,也可以考虑指定本地多目录。
不要配置单块磁盘的多个目录,务必将目录配置到多块 不同的磁盘 上,让多块磁盘来分担压力。
配置:
state.backend.rocksdb.localdir: /data1/flink/rocksdb,/data2/flink/rocksdb,/data3/flink/rocksdb
调整预定义选项:
概述:
Flink针对不同的设置为 RocksDB 提供了一些预定义的选项集合 其中包含了后续提到的一些参数,如果调整预定义选项后还达不到预期,再去调整后面的 block 、 writebuffer等 参数。
可选:
DEFAULT
SPINNING_DISK_OPTIMIZED
SPINNING_DISK_OPTIMIZED_HIGH_MEM
FLASH_SSD_OPTIMIZED
配置:
state.backend.rocksdb.predefined-options=SPINNING_DISK_OPTIMIZED_HIGH_MEM 设置为机械硬盘+内存模式
增大block cache大小:
概述:
整个RocksDB 共享一个 block cache ,读数据时内存的 cache 大小,该参数越大读数据时缓存命中率越高,默认大小为 8 MB 建议设置到 64 ~ 256 MB 。
配置:
state.backend.rocksdb.block.cache-size: 64m 默认 8m
增大 write buffer 和 level 阈值 大小:
概述:
RocksDB中,每个 State 使用一个 Column Family ,每个 Column Family 使用独占的 write buffer(MemTable,无论Active还是ReadOnly),默认64MB,建议调大。
调整这个参数通常要适当增加 L1 层的大小阈值 max size level base ,默认256m。
该值太小会造成能存放的SST 文件过少,层级变多造成查找困难,太大会造成文件过多,合并困难。
建议设为 target_file_size_base (默认 64MB 的倍数,且不能太小,例如 5~10倍,即 320~640MB 。
配置:
state.backend.rocksdb.writebuffer.size: 128m
state.backend.rocksdb.compaction.level.max-size-level-base: 320m
增大 write buffer 数量:
概述:
每个Column Family 对应的 writebuffer 最大数量,这实际上是内存中ReadOnlyMemTable的最大数量,默认值是2。 对于机械磁盘来说,如果内存 足 够大,可以调大到 5 左右
配置:
state.backend.rocksdb.writebuffer.count: 5
增大后台线程数:
概述:
用于后台flush 和合并 sst 文件的线程数,默认为 1 ,建议调大。机械硬盘用户可以改为 4 等更大的值
配置:
state.backend.rocksdb.thread.num: 4
增大write buffer合并数:
概述:
将数据从writebuffer 中 flush 到磁盘时,需要合并的 writebuffer 最小数量,默认值为 1 ,可以调成3。
配置:
state.backend.rocksdb.writebuffer.number-to-merge: 3
开启分区索引功能:
概述:
Flink 1.13中对 RocksDB 增加了分区索引功能 复用了 RocksDB 的 partitioned Index & filter 功能,简单来说就是对 RocksDB 的 partitioned Index 做了多级索引。也就是将内存中的最上层常驻,下层根据需要再load 回来,这样就大大降低了数据 Swap竞争。
线上测试中,相对于 内存比较小 的场景中,性能提升 10 倍 左右。如果在内存管控下 Rocksdb 性能不如预期的话,这也能成为一个性能优化点。
配置:
state.backend.rocksdb.memory.partitioned-index-filters: true # 默认 false
配置方式:
job配置:
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
全局配置:
flink-conf.yaml的state.backend,可选
jobmanager (代表 MemoryStateBackend)
filesystem (代表 FsStateBackend)
rocksdb (代表 RocksDBStateBackend)
checkpoint:
概述:
开启 checkpoint 后,state backend 管理的 taskmanager 上的状态数据才会被定期备份到jobmanager 或 外部存储,这些状态数据在作业失败恢复时会用到
开启:
env.enableCheckpointing(30000);
checkpoint间隔:
概述:
Checkpoint是一种负载较重的任务,如果状态比较大,同时n值又比较小,那可能一次Checkpoint还没完成,下次Checkpoint已经被触发,占用太多本该用于正常数据处理的资源。
增大n值意味着一个作业的Checkpoint次数更少,整个作业用于进行Checkpoint的资源更小,可以将更多的资源用于正常的流数据处理。同时,更大的n值意味着重启后,整个作业需要从更长的Offset开始重新处理数据。
时效性的影响:
在exactly-once的语义下,checkpoint涉及到2PC,正式提交依赖于checkpoint的完成,假设间隔为5分钟,那么5分钟后才真正提交事务,数据才能被读取到。
如果时效性要求高,结合end to end 时长,设置秒级或毫秒级。
如何确定:
1.一般需求,Checkpoint 时间间隔可以设置为 分钟级别 15 分钟。对于状态很大的任务每次 Checkpoint 访问HDFS比 较耗时,可以设置为 5 ~10 分钟一次Checkpoint并且调大两次 Checkpoint之间的暂停间隔,例如设置两次 Checkpoint 之间 至少暂停4或8分钟。
2.考虑时效性。
3.如果 Checkpoint语义配置为EXACTLY_ONCE,那么在 Checkpoint 过程中还会存在 barrier 对齐 的过程,可以通过 Flink Web UI 的 Checkpoint 选项卡来查看 Checkpoint 过程中各阶段的耗时情况,从而确定到底是哪个阶段导致 Checkpoint 时间过 长 然后针对性的解决问题。
保留checkpoint:
Checkpoint 在默认的情况下仅用于恢复失败的作业,并不保留,当程序取消时 checkpoint 就会被删除。当然,你可以通过配置来保留 checkpoint,这些被保留的 checkpoint 在作业失败或取消时不会被清除。这样,你就可以使用该 checkpoint 来恢复失败的作业。
配置:
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
作业恢复:
类似savepoint,指定-s参数。
修改算子:
相关配置:
语义:
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE)
默认的Checkpoint配置是支持Exactly-Once投递的,这样能保证在重启恢复时,所有算子的状态对任一条数据只处理一次。(如果回滚,那么状态函数也会回滚,保证一次)
Checkpoint Barrier对齐,因此会有一定的延迟。如果作业延迟小,那么应该使用At-Least-Once投递,不进行对齐,但某些数据会被处理多次。
超时时间:
env.getCheckpointConfig.setCheckpointTimeout(3600*1000)
如果一次Checkpoint超过一定时间仍未完成,直接将其终止,以免其占用太多资源:
结合UI面板上的Checkpoints面板-History/Summury看板中的end_to_end时长来看。
最小间隔:
checkpointConf.setMinPauseBetweenCheckpoints(TimeUnit.MINUTES.toMillis(4))
并发数量:
默认情况下一个作业只允许1个Checkpoint执行,如果某个Checkpoint正在进行,另外一个Checkpoint被启动,新的Checkpoint需要挂起等待。
env.getCheckpointConfig.setMaxConcurrentCheckpoints(3)
作业取消后仍然保存Checkpoint:
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
RETAIN_ON_CANCELLATION模式下,用户需要自己手动删除远程存储上的Checkpoint数据。
失败相关:
默认情况下,如果Checkpoint过程失败,会导致整个应用重启,我们可以关闭这个功能,这样Checkpoint失败不影响作业的运行。
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)
checkpointConfig.setTolerableCheckpointFailureNumber(5);
savepoint:
概述:
依据 Flink checkpointing 机制所创建的流作业执行状态的一致镜像。 你可以使用 Savepoint 进行 Flink 作业的停止与重启、fork 或者更新。
组成:
Savepoint 由两部分组成:稳定存储(列入 HDFS,S3,…) 上包含二进制文件的目录(通常很大),和元数据文件(相对较小)。
与Checkpoint的区别:
Flink 的 Savepoint 与 Checkpoint 的不同之处类似于传统数据库中的备份与恢复日志之间的差异。
Checkpoint 的主要目的是为意外失败的作业提供恢复机制。 Checkpoint 的生命周期由 Flink 管理,即 Flink 创建,管理和删除 Checkpoint - 无需用户交互。
Savepoint 由用户创建,拥有和删除。 他们的用例是计划的,手动备份和恢复。 例如,升级 Flink 版本,调整用户逻辑,改变并行度,以及进行红蓝部署等。 当然,Savepoint 必须在作业停止后继续存在。
分配算子ID:
.uid("source-id")
可以让 Flink 有效地将算子的状态从 savepoint 映射到作业修改后(拓扑图可能也有改变)的正确的算子上 。 比如替换原来的 Operator 实现、增加新的 Operator 、删除 Operator 等等。
触发方式:
直接触发:
bin/flink savepoint jobId [targetDirectory] -yid yarnAppId
cancel触发:
flink cancel s [targetDirectory] jobId yid yarnAppId] on yarn 模式需要指定 yid 参数
从Savepoint恢复:
flink run -s,--fromSavepoint <savepointPath> 格式:hdfs:///checkpoint dir/job id/chk-xx,可以通过路径:/checkpoint dir/Jobid/chk-xxx来确定最新的chk
注意:
有状态算子:
新状态算子时,它将在没有任何状态的情况下进行初始化
删除状态运算符,可以通过 --allowNonRestoredState(short:-n)选项跳过无法映射到新程序的状态。
无状态算子:
不影响。
删除 Savepoint:
bin/flink savepoint -d :savepointPath
配置:
state.savepoints.dir: hdfs:///flink/savepoints 如果既未配置缺省值也未指定自定义目标目录,则触发 Savepoint 将失败。
双流Join:
概述:
大体分类只有两种:Window Join和Interval Join
Interval Join:
interval join也是利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清理;
在某些情况下,两条流的数据步调未必一致。例如,订单流的数据有可能在点击流的购买动作发生之后很久才被写入,如果用窗口来圈定,很容易 join 不上。
所以 Flink 又提供了"Interval join"的语义,按照指定字段以及右流相对左流偏移的时间区间进行关联
示例:
clickStream.intervalJoin(browseStream)
.between(Time.minutes(-10),Time.seconds(0)) //表示10分钟之前,0之后的数据包含在内
.process(new IntervalJoinFunc) //处理left和right的数据
.print()
Window Join:
概述:
可以根据Window的类型细分出3种:Tumbling Window Join、Sliding Window Join、Session Widnow Join。
Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join操作;
示例:
input1Stream.join(input2Stream)
.where(k=>k._1)
.equalTo(k=>k._1)
.window(TumblingEventTimeWindows.of(Time.seconds(2))) //指定window类型
.apply { (e1,e2) => e1 + "...." + e2}
.print()
connect函数:
示例:
orderStream.connect(payStream).process(new MyConFunc) //其中MyConFunc需要分别实现函数processElement1和processElement2、onTimer,处理空值、超时情况。
coGroup实现left/right outer join :
双流join其中一条流延迟的问题:
1.上游监听kafka,存到hbase,同一个rowkey,当所有的消息都到了之后,再综合起来发一条消息到下游kafka。
2.window join
一致性语义:
at-most-once:
——故障发生之后,计数结果可能丢失。
at-least-once:
这表示计数结果可能大于正确值,但绝不会小于正确值。
exactly-once:
概述:
这指的是系统保证在发生故障后得到的计数结果与正确值一致。
分布式快照机制:
通过检查点实现,flink自动触发,能够保证作业出现 fail-over 后可以从最新的快照进行恢复
端到端Exactly-once:
内部保证 —— checkpoint
source 端 —— 支持数据重放
sink 端 —— 从故障恢复时,数据不会重复写入外部系统(幂等写入、事务写入)
事务写入:
实现思想:
构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中
实现方式:
1)预写日志(WAL):把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统。
缺点:做不到真正意义上的Exactly-once,sink写到一半时挂掉可能重复写入。
2)两阶段提交(2PC):
对于每个 checkpoint,Barrier到达后,sink 任务会启动一个事务,并将接下来所有接收的数据添加到事务里
然后将这些数据写入外部 sink 系统,但不提交它们,这时只是“预提交”
当它收到 checkpoint 完成的通知时,它才正式提交事务,实现结果的真正写入
这种方式真正实现了 exactly-once,它需要一个提供事务支持的外部 sink 系统。
Flink的Exactly-once:
Flink 自身是无法保证外部系统“精确一次”语义的,所以 Flink 若要实现所谓“端到端(End to End)的精确一次”的要求,那么外部系统必须支持“精确一次”语义;
分布式快照 + 两阶段提交
整个过程可以总结为下面四个阶段:
1.一旦 Flink 开始做 checkpoint 操作,那么就会进入 pre-commit 阶段,同时 Flink JobManager 会将上一个检查点的Barrier注入数据流中。
2.当barrier随着数据向下流动直到sink端,barrier每到一个算子,都会触发算子做本地快照。完成快照后,则 pre-commit 阶段完成;
3.等所有的算子完成“预提交”,就会发起一个“提交”动作,但是任何一个“预提交”失败都会导致 Flink 回滚到最近的 checkpoint;
4.pre-commit 完成,到达commit阶段,JobManager 会通知应用中每个 Operator Checkpoint 已完成了。
Data Source 和窗口操作无外部状态,因此在该阶段,这两个 Opeartor 无需执行任何逻辑,但是 Data Sink 是有外部状态的,此时我们必须提交外部事务
如果其中一个commit失败,协调者就会广播取消事务,回滚到上次的checkpoint。
一旦master做出了commit的决定,那么这个commit必须得到执行,就算宕机恢复也有继续执行。
TwoPhaseCommitSinkFunction:
beginTransaction。开始一次事务,在目的文件系统创建一个临时文件。接下来我们就可以将数据写到这个文件。
preCommit。在这个阶段,将文件flush掉,同时重起一个文件写入,作为下一次事务的开始。
commit。这个阶段,将文件写到真正的目的目录。值得注意的是,这会增加数据可视的延时。
abort。如果回滚,那么删除临时文件。
Checkpoint的大致流程:
1.暂停处理新流入数据,将新数据缓存起来。
2.将算子子任务的本地状态数据拷贝到一个远程的持久化存储上。
3.继续处理新流入的数据,包括刚才缓存起来的数据。
Checkpoint Barrier:
概述:
Checkpoint Barrier被插入到数据流中,它将数据流切分成段。
用途:
Flink的算子接收到Checpoint Barrier后,对状态进行快照。每个Checkpoint Barrier有一个ID,表示该段数据属于哪次Checkpoint。如图所示,当ID为n的Checkpoint Barrier到达每个算子后,表示要对n-1和n之间状态的更新做快照。Checkpoint Barrier有点像Event Time中的Watermark,它被插入到数据流中,但并不影响数据流原有的处理顺序。
Barrier对齐:
1.首先,Flink的检查点协调器(Checkpoint Coordinator)触发一次Checkpoint(Trigger Checkpoint),这个请求会发送给Source的各个子任务。
2.各Source算子子任务接收到这个Checkpoint请求之后,会将自己的状态写入到状态后端,生成一次快照,并且会向下游广播Checkpoint Barrier。
3.Source算子做完快照后,还会给Checkpoint Coodinator发送一个确认,告知自己已经做完了相应的工作。这个确认中包括了一些元数据,其中就包括刚才备份到State Backend的状态句柄,或者说是指向状态的指针。至此,Source完成了一次Checkpoint。跟Watermark的传播一样,一个算子子任务要把Checkpoint Barrier发送给所连接的所有下游算子子任务。
4.对于下游算子来说,可能有多个与之相连的上游输入,我们将算子之间的边称为通道。Source要将一个ID为n的Checkpoint Barrier向所有下游算子广播,这也意味着下游算子的多个输入里都有同一个Checkpoint Barrier,而且不同输入里Checkpoint Barrier的流入进度可能不同。Checkpoint Barrier传播的过程需要进行对齐(Barrier Alignment)
1.算子子任务在某个输入通道中收到第一个ID为n的Checkpoint Barrier,但是其他输入通道中ID为n的Checkpoint Barrier还未到达,该算子子任务开始准备进行对齐。
2.算子子任务将第一个输入通道的数据缓存下来,同时继续处理其他输入通道的数据,这个过程被称为对齐。
3.第二个输入通道的Checkpoint Barrier抵达该算子子任务,该算子子任务执行快照,将状态写入State Backend,然后将ID为n的Checkpoint Barrier向下游所有输出通道广播。
4.对于这个算子子任务,快照执行结束,继续处理各个通道中新流入数据,包括刚才缓存起来的数据。
5.数据流图中的每个算子子任务都要完成一遍上述的对齐、快照、确认的工作,当最后所有Sink算子确认完成快照之后,说明ID为n的Checkpoint执行结束,Checkpoint Coordinator向State Backend写入一些本次Checkpoint的元数据。(二阶段事务的commit阶段,sink也提交事务)
对齐作用:
为了保证一个Flink作业所有算子的状态是一致的。也就是说,某个ID为n的Checkpoint Barrier从前到后流入所有算子子任务后,所有算子子任务都能将同样的一段数据写入快照。
存在问题以及解决:
1.每次进行Checkpoint前,都需要暂停处理新流入数据,然后开始执行快照,假如状态比较大,一次快照可能长达几秒甚至几分钟。
Flink提供了异步快照(Asynchronous Snapshot)的机制。
Flink可以立即向下广播Checkpoint Barrier,表示自己已经执行完自己部分的快照。同时,Flink启动一个后台线程,它创建本地状态的一份拷贝,这个线程用来将本地状态的拷贝同步到State Backend上,一旦数据同步完成,再给Checkpoint Coordinator发送确认信息。
2.Checkpoint Barrier对齐时,必须等待所有上游通道都处理完,假如某个上游通道处理很慢,这可能造成整个数据流堵塞。
Flink允许跳过对齐这一步,或者说一个算子子任务不需要等待所有上游通道的Checkpoint Barrier,直接将Checkpoint Barrier广播,执行快照并继续处理后续流入数据。为了保证数据一致性,Flink必须将那些较慢的数据流中的元素也一起快照,一旦重启,这些元素会被重新处理一遍。
这样实现的是at-least-once,因为提前到达的算子可能会提前sink。
框架示例:
kafka productor和mysql sink,继承TwoPhaseCommitSinkFunction,实现方法beginTransaction、preCommit、commit、abort
hbase不支持跨行事务,可以选择幂等性写入,或者在客户端的基础上再包装一层来尽最大努力地提供事务保证。
HDFS不提供事务,参考BucketingSink,格式为/{base/path}/{bucket/path}/{part_prefix}-{parallel_task_index}-{count}{part_suffix},三种状态in-progress/pending/finished。
CEP:
概述:
复杂事件处理,Flink CEP 是在 Flink 中实现的复杂时间处理(CEP)库。
处理事件的规则,被叫做“模式”(Pattern),Flink CEP 提供了 Pattern API,用于对输入流数据进行复杂事件规则定义,用来提取符合规则的事件序列。
Pattern API 大致分为三种:个体模式,组合模式,模式组。
个体模式(Individual Patterns):
概述:
组成复杂规则的每一个单独的模式定义,就是个体模式。
量词:
start.time(4)// 匹配出现4次
start.time(4).optional// 匹配出现0次或4次
start.time(2,4)// 匹配出现2、3或4次
start.time(2,4).greedy// 匹配出现2、3或4次,并且尽可能多地重复匹配
start.oneOrMore// 匹配出现1次或多次
start.timesOrMore(2).optional.greedy// 匹配出现0、2或多次,并且尽可能多地重复匹配
条件:
每个模式都需要指定触发条件,作为模式是否接受事件进入的判断依据。CEP中的个体模式主要通过调用.where()、.or()和.until()来指定条件。按不同的调用方式,可以分成以下几类:
简单条件
通过.where()方法对事件中的字段进行判断筛选,决定是否接收该事件
start.where(event=>event.getName.startsWith(“foo”))
组合条件
将简单的条件进行合并;or()方法表示或逻辑相连,where的直接组合就相当于与and。
Pattern.where(event => …/*some condition*/).or(event => /*or condition*/)
终止条件
如果使用了oneOrMore或者oneOrMore.optional,建议使用.until()作为终止条件,以便清理状态
迭代条件
能够对模式之前所有接收的事件进行处理;调用.where((value,ctx) => {…}),可以调用ctx.getEventForPattern(“name”)
示例:
start.times(3).where(_.behavior.startsWith(‘fav’))
组合模式(Combining Patterns,也叫模式序列):
很多个体模式组合起来,就形成了整个的模式序列。模式序列必须以一个初始模式开始.
严格近邻
所有事件按照严格的顺序出现,中间没有任何不匹配的事件,由.next()指定。例如对于模式“a next b”,事件序列“a,c,b1,b2”没有匹配。
宽松近邻
允许中间出现不匹配的事件,由.followedBy()指定。例如对于模式“a followedBy b”,事件序列“a,c,b1,b2”匹配为{a,b1}。
非确定性宽松近邻
进一步放宽条件,之前已经匹配过的事件也可以再次使用,由.followedByAny()指定。例如对于模式“a followedByAny b”,事件序列“a,c,b1,b2”匹配为{ab1},{a,b2}。
除了以上模式序列外,还可以定义“不希望出现某种近邻关系”:
.notNext():不想让某个事件严格紧邻前一个事件发生。
.notFollowedBy():不想让某个事件在两个事件之间发生。
需要注意:
①所有模式序列必须以.begin()开始;
②模式序列不能以.notFollowedBy()结束;
③“not”类型的模式不能被optional所修饰;
④可以为模式指定时间约束,用来要求在多长时间内匹配有效。
模式组(Group of Pattern):
将一个模式序列作为条件嵌套在个体模式里,成为一组模式。
如何使用:
val patternStream:PatternStream[Event]=CEP.pattern(input,pattern)
匹配事件的提取:
创建PatternStream之后,就可以应用select或者flatSelect方法,从检测到的事件序列中提取事件了。
select()方法需要输入一个select function作为参数,每个成功匹配的事件序列都会调用它。
select()以一个Map[String,Iterable[IN]]来接收匹配到的事件序列,其中key就是每个模式的名称,而value就是所有接收到的事件的Iterable类型。
示例:
def selectFn(pattern : Map[String,Iterable[IN]]):OUT={
val startEvent = pattern.get(“start”).get.next
val endEvent = pattern.get(“end”).get.next
OUT(startEvent, endEvent)
}
超时事件的提取:
当一个模式通过within关键字定义了检测窗口时间时,部分事件序列可能因为超过窗口长度而被丢弃;为了能够处理这些超时的部分匹配,select和flatSelect API调用允许指定超时处理程序。
示例:
patternStream.select(orderTimeoutOutput, new PatternTimeoutFunction<PayEvent,PayEvent>() {
@Override
public PayEvent timeout(Map<String, List<PayEvent>> map, long l) throws Exception {
return map.get("begin").get(0);
}
}, new PatternSelectFunction<PayEvent, PayEvent>() {
@Override
public PayEvent select(Map<String, List<PayEvent>> map) throws Exception {
return map.get("pay").get(0);
}
}
Table API和SQL:
概述:
Apache Flink具有两个关系API - Table API和SQL,用于统一流和批处理。
Table API是Scala和Java语言集成查询API,以非常直观的方式组合关系查询,例如选择,过滤和连接。
Flink的SQL api是基于实现了SQL标准的Apache Calcite。
无论输入是批输入(DataSet)还是流输入(DataStream),任一接口中指定的查询都具有相同的语义并指定相同的结果。
table示例:
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStreamSource<Tuple2<String, Integer>> data = env.addSource(....)
Table table = tEnv.fromDataStream(data, $("name"), $("age"));
Table name = table.select($("name")); //DSL操作
DataStream<Tuple2<Boolean, Row>> result = tEnv.toRetractStream(name,Row.class); //转换为DataStream,方便输出
SQL示例:
tEnv.createTemporaryView("userss",data, $("name"), $("age"));
String s = "select name from userss";
Table table = tEnv.sqlQuery(s);
输入与输出:
文件:
tEnv.connect(new FileSystem().path("D:\\data\\out.txt"))
.withFormat(new Csv())
.withSchema(new Schema().field("name",DataTypes.STRING()).field("age",DataTypes.INT()))
.createTemporaryTable("outputTable");
tEnv.connect(new FileSystem().path("D:\\data\\out.txt"))
.withFormat(new Csv())
.withSchema(new Schema().field("name",DataTypes.STRING()).field("age",DataTypes.INT()))
.createTemporaryTable("inputTable");
inputTable转化为datastream
filtered.executeInsert("outputTable");
kafka:
ConnectTableDescriptor descriptor = tEnv.connect(
new Kafka().version("universal").topic("animal").startFromEarliest().property("bootstrap.servers", "hdp-2:9092")
)
.withFormat(new Csv())
sql优化:
设置TTL:
背景:
FlinkSQL 的 regu lar join inner 、 left 、 right ),左右表的数据都会 一直保 存在状态里,不会清理!要么设置 TTL ,要么使用 Flink SQL 的 interval join。
使用 Top N 语法进行去重,重复数据的出现一般都位于特定区间内(例如一小时或一天内),过了这段时间之后,对应的状态就不再需要了。
概述:
Flink SQL可以 指定空闲状态(即未更新的状态)被保留的最小时间,当状态中某个 key对应的 状态 未更新的时间达到阈值时,该条状态被自动清理。
配置:
#API 指定
tableEnv.getConfig().setIdleStateRetention(Duration.ofHours(1));
#参数指定
Configuration configuration = tableEnv.getConfig().getConfiguration();
configuration.setString("table.exec.state.ttl", "1h")
开启MiniBatch:
概述:
MiniBatch是微批处理,原理是 缓存一定的数据后再触发处理,以减少对 State 的访问从而 提升吞吐并减少数据的输出量。
MiniBatch 主要依靠在每个 Task 上注册的 Timer 线程来触发微批,需要消耗一定的线程调度性能。
配置:
TableEnvironment tEnv = ...
Configuration configuration = tEnv.getConfig().getConfiguration();
// 开启 miniBatch
configuration.setString("table.exec.mini batch.enabled", true)
// 批量输出的间隔时间
configuration.setString("table.exec.mini batch.allow latency", 5s)
// 防止 OOM 设置每个批次最多缓存数据的条数 ,可以设为 2 万条
configuration.setString("table.exec.mini batch.size", 20000)
适用场景:
微批处理通过增加延迟换取高吞吐,如果有超低延迟的要求,不建议开启微批处理。通常对于聚合的场景,微批处理可以显著的提升系统性能,建议开启。
注意事项:
1.目前, key value 配置项仅被 Blink planner 支持。
2. 1.12 之前的版本有 bug ,开启 miniBatch ,不会清理过期状态,也就是说如果设置状态的 TTL ,无法清理过期状态。 1.12 版本才修复这个问题。
开启LocalGlobal:
概述:
LocalGlobal优化将原先的 Aggregate 分成 Local+Global 两阶段聚合,即MapReduce 模型中的 Combine+Reduce 处理模式。
第一阶段在上游节点本地攒一批数据进行聚合( localAgg ),并输出这次微批的增量值(Accumulator)。第二阶段再将收到的 Accumulator 合并( Merge ),得到最终的结果(GlobalAgg)。
好处:
解决部分数据倾斜问题。
配置:
1.LocalGlobal 优化需要先开启 MiniBatch,依赖于 MiniBatch 的参数。
2.table.optimizer.agg-phase-strategy: 聚合策略。默认AUTO,支持参数AUTO、TWO_PHASE(使用LocalGlobal两阶段聚合)、ONE_PHASE(仅使用 Global 一阶段聚合)。
注意事项:
1.需要先开启 MiniBatch。
2.开启 LocalGlobal 需要UDAF实现 Merge 方法。
开启Split Distinct:
背景:
LocalGlobal优化针对普通聚合(例如 SUM 、 COUNT 、 MAX 、 MIN 和 AVG )有较好的效果,对于 DISTINCT 的聚合(如 COUNT DISTINCT) 收效不明显,因为 COUNT DISTINCT 在 Local 聚合时,对于 DISTINCT KEY 的去重率不高,导致在 Global 节点仍然存在热点。
手动解决:
之前,为了解决COUNT DISTINCT 的热点问题,通常需要手 动改写为两层聚合(增加按 Distinct Key 取模的打散层)。
示例:
SELECT a, SUM(cnt)
FROM (
SELECT a , COUNT(DISTINCT b ) as cnt
FROM T
GROUP BY a, MOD(HASH_CODE(b),1024)
)
GROUP BY a
自动打散:
概述:
从Flink1.9.0 版本开始,提供了 COUNT DISTINCT 自动打散功能, 通过HASH_CODE(distinct_key) % BUCKET_NUM 打散, 不需要手动重写。
Split Distinct 和LocalGlobal 的原理对比:
 image-20220204111438787
image-20220204111438787
配置:
要开启minibatch
table.optimizer.distinct-agg.split.enabled: true 默认 false 。
table.optimizer.distinct-agg.split.bucket-num: Split Distinct优化在第一层聚合中,被打散的bucket数目。默认1024。
注意事项:
1.目前不能在包含 UDAF 的 Flink SQL 中使用 Split Distinct 优化方法。
2.拆分出来的两个 GROUP 聚合还可参与 LocalGlobal 优化。
3.该功能在 F l ink1.9.0 版本 及以上版本才支持。
多维DISTINCT使用Filter:
概述:
在某些场景下,可能需要从不同维度来统计(count distinct)的结果 (比如统计 uv 、app 端的 uv 、 web 端的 uv)可能会使用如下 CASE WHEN 语法。
COUNT(DISTINCT CASE WHEN c IN ('A','B') THEN b ELSE NULL END) AS AB b
在这种情况下,建议使用FILTER 语法 , 目前的 Flink SQL 优化器可以识别同一唯一键上的不同 FILTER 参数。
如,在上面的示例中,三个 COUNT DISTINCT 都作用在 b 列上。此时,经过优化器识别后, Flink 可以只使用一个共享状态实例,而不是三个状态实例,可减少状态的大小和对状态的访问。
示例:
COUNT(DISTINCT b ) FILTER (WHERE c IN ('A', 'B')) AS AB_b
COUNT(DISTINCT b ) FILTER (WHERE c IN ('C', 'D')) AS CD b
常见生产问题与解决:
1.使用聚合函数GroupBy、Distinct、KeyBy等函数时出现数据热点:
在业务上规避这类问题
单独处理这部分数据
Key的设计上
热点数据再拆分。
参数设置
缓存一定的数据后再触发处理,以减少对State的访问,从而提升吞吐和减少数据的输出量。
2.反压问题:
网络流控:
静态限速:
可以在 Producer 端实现一个类似 Rate Limiter 这样的静态限流,Producer 的发送速率是 2MB/s,但是经过限流这一层后,往 Send Buffer 去传数据的时候就会降到 1MB/s 了,这样的话 Producer 端的发送速率跟 Consumer 端的处理速率就可以匹配起来了,就不会导致上述问题。
缺点:
事先无法预估 Consumer 到底能承受多大的速率
Consumer 的承受能力通常会动态地波动
适合场景:
比较简单
适合像ES这种,无法将反压进行传播反馈给Sink端。
动态反馈/自动反压:
针对静态限速的问题我们就演进到了动态反馈(自动反压)的机制,我们需要 Consumer 能够及时的给 Producer 做一个 feedback,即告知 Producer 能够承受的速率是多少。
动态反馈分为两种:
负反馈:接受速率小于发送速率时发生,告知 Producer 降低发送速率
正反馈:发送速率小于接收速率时发生,告知 Producer 可以把发送速率提上来
应用:
storm,spark streaming
flink1.5前基于TCP流控:
TCP的window size机制。
当window = 0,发送端是不能发送任何数据,也就会使发送端的发送速度降为 0。这个时候发送端不发送任何数据了。
TCP 当中有一个 ZeroWindowProbe 的机制,发送端会定期的发送 1 个字节的探测消息,这时候接收端就会把 window 的大小进行反馈。当接收端的消费恢复了之后,接收到探测消息就可以将 window 反馈给发送端端了从而恢复整个流程。TCP 就是通过这样一个滑动窗口的机制实现 feedback。
缺点:
1.在一个 TaskManager 中可能要执行多个 Task,如果多个 Task 的数据最终都要传输到下游的同一个 TaskManager 就会复用同一个 Socket 进行传输,这个时候如果单个 Task 产生反压,就会导致复用的 Socket 阻塞,其余的 Task 也无法使用传输,checkpoint barrier 也无法发出导致下游执行 checkpoint 的延迟增大。
2.依赖最底层的 TCP 去做流控,会导致反压传播路径太长,导致生效的延迟比较大。
Flink Credit-based 反压机制(since V1.5):
原理:
这个机制简单的理解起来就是在 Flink 层面实现类似 TCP 流控的反压机制来解决上述的弊端,Credit 可以类比为 TCP 的 Window 机制。
概述:
每一次 ResultSubPartition 向 InputChannel 发送消息的时候都会发送一个 backlog size 告诉下游准备发送多少消息,下游就会去计算有多少的 Buffer 去接收消息,算完之后如果有充足的 Buffer 就会返还给上游一个 Credit 告知他可以发送消息
现象:
简单来说,Flink 拓扑中每个节点( Task )间的数据都以阻塞队列的方式传输,下游来不及消费导致队列被占满后,上游的生产也会被阻塞,最终导致数据源的摄入被阻塞。
出现的场景:
短时间的负载高峰导致系统接收数据的速率远 高于 它处理数据的速率。
数据倾斜(UI可以看到task处理的数据量)
消费者代码性能不佳
TaskManager 内存以及 GC 问题,垃圾回收停顿可能会导致 流入 的数据快速堆积
反压的危害:
反压如果不能得到正确的处理,可能 会影响到 checkpoint 时长和 state 大小 ,甚至可能会导致资源耗尽甚至系统崩溃 。
1.影响checkpoint时长:
barrier 不会越过普通数据,普通数据的处理被阻塞也会导致checkpoint barrier 流经整个数据管道的时长变长, 导致 checkpoint 总体时间( End to End Duration )变长。
2.影响state大小:
barrier 对齐时,接受到较快的输入管道的 barrier 后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的 barrier 也到达,这些被缓存的数据会被放到 state 里面,导致 checkpoint 变大。
这两个影响对于生产环境的作业来说是十分危险的,因为checkpoint 是保证数据一致性的关键, checkpoint 时间变长有可能导致 checkpoint 超时失败 ,而 state 大小同样可能拖慢 checkpoint 甚至导致 OOM (使用 Heap ba sed StateBackend )或者物理内存使用 超出容器资源 (使用 RocksDBStateBackend )的稳定性问题。
定位:
排查的时候,先把 operator chain 禁用,方便定位 到具体算子 。
利用Flink Web UI定位:
概述:
Flink Web UI的反压监控提供了 SubTask 级别的反压监控, 1 .13 版本以前 是通过周期性对 Task 线程的栈信息采样,得到线程被阻塞在请求 Buffer (意味着被下游队列阻塞的频率来判断该节点是否处于反压状态。默认配置下,这个频率在 0.1 以下则为 OK 0.1至 0.5 为 LOW ,而超过 0.5 则为 HIGH 。
Flink 1.13优化了反压检测的逻辑(使用基于任务 Mailbox 计时,而不在再于堆栈采样),并且重新实现了作业图的 UI 展示: Fl ink 现在在 UI 上通过颜色和数值来展示繁忙和反压的程度。
颜色:
1.13后,蓝色表示正常,红色表示low,CPU满,灰色表示high。
分析瓶颈算子:
情况1:
该节点的发送速率跟不上它的产生数据速率。这一般会发生在一条输入多条输出的 Operator (比如 flatmap )。
这种情况,该节点是反压的根源节点,它是从 Source Task到 Sink Task 的第一个出现反压的节点。
ok->ok->反压->反压
情况2:
下游的节点接受速率较慢,通过反压机制限制了该节点的发送速率。 这种情况需要继续排查下游节点 ,一直找到第一个为OK的一般就是根源节点。
反压->反压->反压->ok->ok
通常来讲,第二种情况更常见。 如果无法确定,还需要结合 Metrics 进一步判断。
利用 Metrics 定位:
常见metrics:
outPoolUsage 发送端Buffer 的使用率
inPoolUsage 接收端Buffer 的使用率
floatingBuffersUsage(1.9 以上) 接收端Floating Buffer的使用率,network bufferPool,taskmanager共享。先使用完exclusiveBuffersUsage,再申请这个。
exclusiveBuffersUsage(1.9 以上) 接收端Exclusive Buffer的使用率,outPoolUsage或inPoolUsage
根据指标分析反压:
大致思路:
如果一个Subtask 的发送端 Buffer 占用率很高,则表明它被下游反压限速了;
如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。
情况分析:
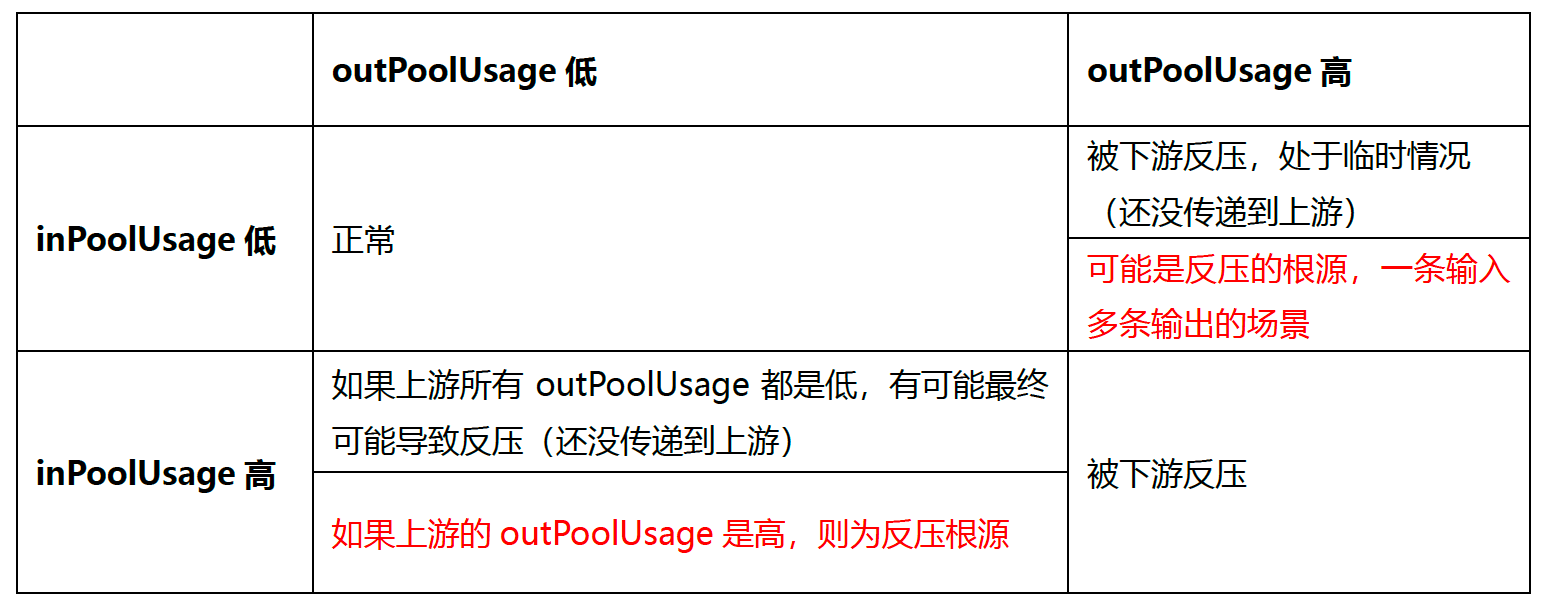
进一步分析数据传输
概述:
Flink1.9 及以上版本,还可以根据 floatingBuffersUsage/exclusiveBuffersUsage 以及其上游 Task 的 outPoolUsage 来进行进一步的分析一个 Subtask 和其上游Subtask 的数据传输。
在流量较大时,Channel 的 Exclusive Buffer 可能会被写满,此时 Flink 会向 BufferPool申请剩余的 Floating Buffer 。这些 Floating Buffer 属于备用 Buffer 。
分析:
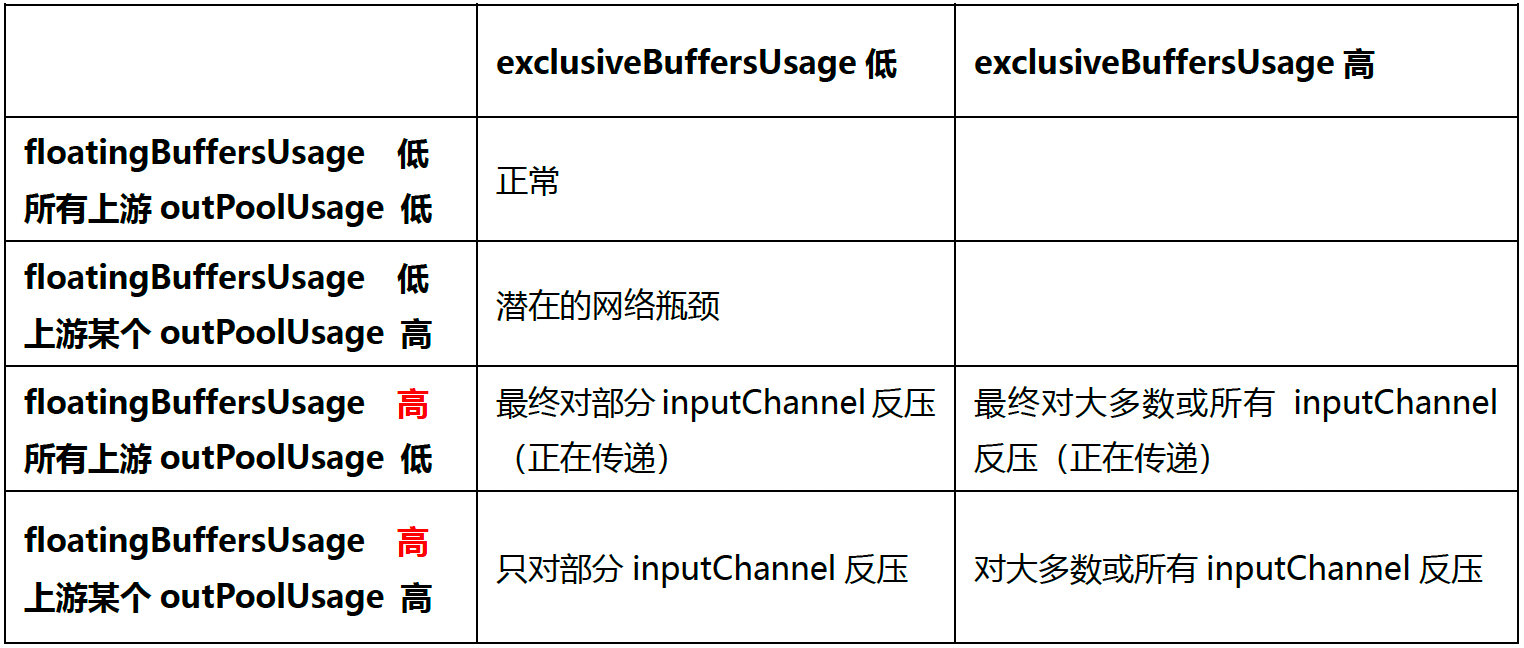
总结:
1.floatingBuffersUsage 为高 则表明反压正在传导至上游
2.同时exclusiveBuffersUsage为低,则表明可能有倾斜
比如,floatingBuffersUsage 高、 exclusiveBuffersUsage 低为有倾斜,因为少数channel 占用了大部分的 Floating Buffer。
反压的处理思路:
查看是否数据倾斜:
在实践中,很多情况下的反压是由于数据倾斜造成的,这点我们可以通过Web UI 各个SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。
使用火焰图分析(代码性能问题):
概述:
如果不是数据倾斜,最常见的问题可能是用户代码的执行效率问题(频繁被阻塞或者性能问题),需要找到瓶颈算子中的哪部分计算逻辑消耗巨大。
最有用的办法就是对TaskManager进行 CPU profile ,从中我们可以分析到 TaskThread 是否跑满一个 CPU 核:如果是的话要分析 CPU 主要花费在哪些函数里面;如果不是的话要看 Task Thread 阻塞在哪里,可能是用户函数本身有些同 步的调用,可能是checkpoint 或者 GC 等系统活动导致的暂时系统暂停。
Flink 1.13直接在 WebUI 提供 JVM 的 CPU 火焰图,这将大大简化性能瓶颈的分析。
开启火焰图:
rest.flamegraph.enabled: true # 默认 false
查看:
层次表示栈调用关系。
火焰图是通过对堆栈跟踪进行多次采样来构建的。每个方法调用都由一个条形表示,其中条形的长度与其在样本中出现的次数成正比。
On-CPU:
处于RUNNABLE, NEW状态的线程
Off-CPU: 处于TIMED_WAITING, WAITING, BLOCKED的线程,用于查看 在样本中发现的阻塞调用 。
分析:
颜色没有特殊含义 ,具体查看
纵向是调用链,从下往上,顶部就是正在执行的函数
横向是 样本出现次数,可以理解为 执行时长。
看顶层的哪个函数占据的宽度最大。只要有 平顶 plateaus ),就表示该函数可能存在性能问题。
手动制作火焰图:
如果是 Flink 1.13 以前的版本,可以手动做火焰图:
http://www.54tianzhisheng.cn/2020/10/05/flink-jvm-profiler/
分析 GC 情况:
TaskManager的内存以及 GC 问题也可能会导致反压,包括 TaskManager JVM 各区内存不合理导致的频繁 Full GC 甚至失联 。
通常建议使用默认的 G1 垃圾回收器。
可以通过打印GC日志(XX:+PrintGCDetails),使用 GC 分析器 GCViewer 工具来验证是否处于这种情况。
配置:
-Denv.java.opts=" XX:+PrintGCDetails XX:+PrintGCDateStamps"
流程:
下载stdout日志
通过GCViewer分析
外部组件交互:
如果发现我们的Source端数据读取性能比较低或者 Sink 端写入性能较差,需要检查第三方组件是否遇到瓶颈,还有就是做维表 join 时的性能问题。
关于第三方组件的性能问题,需要结合具体的组件来分析 ,最常用的思路:
1.异步 io 热缓存来优化读写性能
2.先攒批再读写
维表join:
实时数据库查找关联
异步数据库查找关联
带缓存的数据库查找关联
预加载维表关联(内存占用多,可以按照keyby单独加载,维护麻烦)
维表变更日志双流Join关联
解决:
资源调优即是对作业中的Operator的并发数(parallelism)、CPU(core)、堆内存(heap_memory)等参数进行调优。
作业参数调优包括:并行度的设置,State的设置,checkpoint的设置。
key 分布不均匀的无统计场景:随机前缀打散key分布。
3.数据倾斜问题:
现象:
相同Task 的多个 Subtask 中, 个别 Subtask 接收到的数据量 明显大于其他Subtask 接收 到 的数据量,通过 Flink Web UI 可以精确地看到每个 Subtask 处理了多少数据,即可判断出 Flink 任务是否存在数据倾斜。
通常,数据倾斜也会引起反压。
另外有时 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。
对应的现象和解决:
keyBy后的聚合操作存在数据倾斜:
不能直接用二次聚合来处理。
Flink是实时流处理,如果 keyby 之后的聚合操作存在数据倾斜,且没有开窗口 (没攒批) 的情况下,简单的认为使用两阶段聚合,是不能解决问题的。
因为这个时候 Flink 是来一条处理一条,且向下游发送一条结果,对于原来 key by 的维度(第二阶段聚合)来讲,数据量并没有减少,且结果重复计算(非 FlinkSQL ,未使用回撤流)。
使用 LocalKeyBy 的思想:
类似 MapReduce 中 Combiner 的思想,先利用flatMap自定义函数攒批,到达批次后再输出本地聚合后的结果(利用Checkpoint的state实现精准一次)。
其他方式:
SQL 可以指定参数,开启 miniBatch 和 LocalGlobal 功能(推荐,后续介绍)
开窗攒批。
keyBy之前发生数据倾斜:
概述:
如果keyBy 之前就存在数据倾斜 上游算子的某些实例可能处理的数据较多,某些实例可能处理的数据较少,产生该情况可能是因为数据源的数据本身就不均匀,例如由于某些原因Kafka的topic 中某些 partition 的数据量较 大 ,某些 partition 的数据量较少。
对于不存在 keyBy 的 Flink 任务也会出现该情况。
解决:
使用shuffle、rebalance或rescale算子 即可将数据均匀分配,从 而 解决数据倾斜的问题。
keyBy后的窗口聚合操作存在数据倾斜:
概述:
因为使用了窗口,变成了有界数据(攒批)的处理,窗口默认是触发时才会输出一条结果发往下游,所以可以使用两阶段聚合的方式
流程:
第一阶段聚合:
key拼接随机数前缀或后缀,进行keyby、开窗、聚合
注意:
聚合完不再是WindowedStream,要获取 WindowEnd 作为窗口标记作为第二阶段分组依据,避免不同窗口的结果聚合到一起
第二阶段聚合:
按照原来的key及windowEnd作keyby、聚合
4.WebUI看不到bytes:
原因:
如果没有多个repartition的算子,只有一条pipeline,web ui上看不到流动的字节byte
5.修改作业算子后提交报错,提示local class incompatible:
具体报错:java.io.InvalidClassException: scala.Tuple3; local class incompatible: stream classdesc serialVersionUID = -5455567931579979498, local class serialVersionUID = -8522163535874829495。
原因:
bin/flink的scala版本和代码的scala不一致。
解决:
修改project struct,修改scala和对应的java版本。然后maven clean,maven package。
常见优化:
1.流失一条条sink还不如window窗口,out直接collect收集一个list,sink拿到list后然后批量sink。比如mysql可以批量执行。
redis可以用hmset命令,减小网络传输次数。但是不保证原子性。
2.资源调优:
内存模型(1.10版本后):
结构:

进程内存:
由taskmanager.memory.process.size指定。包含flink内存(包含堆内和堆外)和JVM元空间、overhead执行开销(堆外)。(spark的executor memory指定的是JVM堆内存)
JVM metaspace:
概述:
JVM元空间,大小由taskmanager.memory.jvm-metaspace.size,默认 256 mb
JVM over head 执行开销:
概述:
JVM 执行时自身所需要的内容,包括线程堆栈、 IO 、编译缓存等所使用的内存。
总进程内存*配置的fraction ,如果小于 配置的 min (或大于配置的 max 大小),则使用 min/max大小
配置:
taskmanager.memory.jvm-overhead.fraction,默认 0.1
taskmanager.memory.jvm-overhead.min,默认 192mb
taskmanager.memory.jvm-overhead.max,默认 1gb
flink内存:
概述:
进程内存减去元空间和overhead后的内存部分。包含堆内内存和堆外内存。
组成:
堆内框架 + 堆外框架 + 堆外网络内存 + 堆外托管内存 + 堆内Task内存 + 堆外Task内存
框架内存:
概述:
Flink 框架,即 TaskManager 本身所占用的内存,内部数据结构及操作, 不计入 Slot 的资源中。
配置:
堆内:taskmanager .memory.framework.heap.size,默认 128MB
堆外:taskmanager .memory.framework.off heap.size,默认 128MB
Task内存:
概述:
Task 执行用户代码时所使用的内存
配置:
堆内:taskmanager.memory.task.heap.size,默认none,由Flink内存扣除掉其他部分的内存得到。
堆外:taskmanager.memory.task.off-heap.size,默认0,表示不使用堆外内存
网络内存:
概述:
堆外,网络数据交换所使用的堆外内存大小,如网络数据交换缓冲区。
Flink内存 *fraction ,如果小于 配置的 min (或大于配置的 max 大小),则使用 min/max大小
配置:
taskmanager.memory.network.fraction,默认 0.1
taskmanager.memory.network.min,默认 64mb
taskmanager.memory.network.max,默认 1gb
托管内存:
概述:
堆外,用于 RocksDB State Backend 的本地内存和批的排序、哈希表、缓存中间结果。
配置:
taskmanager.memory.managed.fraction ,默认 0.4
taskmanager.memory.managed.size ,默认 none,如果size 没指定,则等于 Flink 内存 *fraction
调优:
根据内存的使用率来调整各部分比例,都比较满的情况下可以考虑增加进程内存。
CPU分配:
调度策略:
Yarn的容量调度器 默认情况下是使用DefaultResourceCalculator分配策略,只根据内存调度资源,所以在 Yarn 的资源管理页面上看到每个容器的 vcore 个数还是 1 。
可以修改策略为DominantResourceCalculator ,该资源计算器在计算资源的时候会综合考虑 cpu 和内存的情况 。
在 capacity scheduler.xml中修改属性
<property>
<name>yarn.scheduler.capacity.resource calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<value>org.apache.hadoop.yarn.util.DominantResourceCalculator</value>
</property>
container数量计算公式:
根据并行度,-p来确定需要的slot总数,slots数量/taskmanager.numberOfTaskSlots向上取整。
CPU相关配置:
-Dtaskmanager.numberOfTaskSlots=2 配置每个taskmanager的slot数量。
-Dyarn.containers.vcores=3 默认情况下一个slot一个vcore,可以通过配置yarn来改变。一般不用配置。
并行度:
概述:
每个并行度占用一个slot
如何设置:
1.Operator Level(算子级别)(可以使用)
xxx.setParallelism(4);
2.Execution Environment Level(Env级别)(可以使用)
env.setParallelism(4);
3.Client Level(客户端级别,推荐使用)(可以使用)
./bin/flink run -p 10 WordCount-java.jar
4.System Level(系统默认级别,尽量不使用)
flink-conf.yaml文件中的parallelism.default
注意:
如果source不可以被并行执行,即使指定了并行度为多个,也不会生效
尽可能的规避算子的并行度的设置,因为并行度的改变会造成task的重新划分,带来shuffle问题
slot是静态的概念,是指taskmanager具有的并发执行能力; parallelism是动态的概念,是指程序运行时实际使用的并发能力。
如何计算:
全局并行度:
公式:
(总 QPS/ 单并行度的处理能力 * 1.2 )向上取整 = 并行度
流程:
先设置较少的并行度,进行压测,测试单个并行度的处理上限。
然后再根据公式计算。
source端:
数据源端是Kafka Source 的并行度,最多可以设置为 Kafka 对应 Topic 的分区数。
如果已经等于Kafka的分区数消费速度仍跟不上数据生产速度, 考虑下Kafka要扩大分区,同时调大并行度等于分区数。
Flink的一个并行度可以处理一至多个分区的数据,如果并行度多于 Kafka 的分区数,那么就会造成有的并行度空闲,浪费资源。
Transform 端:
Keyby 之前的算子一般不会做太重的操作,都是比如map 、 filter 、 flatmap 等处理较快的算子,并行度可以和 source 保持一致。
Keyby 之后的算子如果并发较大,建议设置并行度为2的整数次幂,例如:128、256、512(keyby根据 二次hash后的值 * 下游分区数 / 最大并行度 来shuffle)
小并发任务的并行度不一定需要设置成2的整数次幂,大并发任务如果没有KeyBy,并行度也无需设置为 2 的整数次幂
Sink 端:
Sink端是数据流向下游的地 方 ,可以根据 Sink 端的数据量 及 下游的服务抗压能力进行评估 。 如果 Sink 端是 Kafka ,可以设为 Kafka 对应 Topic 的分区数。
3.Job优化:
链路延迟测量:
概述:
对于实时的流式处理系统来说,我们需要关注数据输入、计算和输出的及时性,所以处理延迟是一个比较重要的监控指标,特别是在数据量大或者软硬件条件不佳的环境下。
Flink提供了开箱即用的 LatencyMarker 机制来 测量 链路延迟。
监控粒度:
single :每个算子单独统计延迟
operator (默认值):每个下游算子都统计自己与 Source 算子之间的延迟;
一般情况下采用默认的operator 粒度即可,这样在 Sink 端观察 到的 latency metric就是我们最想要的全链路(端到端)延迟 。
subtask 粒度太细,会增大所有并行度的负担,不建议使用。
如何查看metric:
webui看不到这个metric,需要promethes+grafana。格式:flink_taskmanager_job_latency_source_id_operator _id_operator_subtask_index_latency。
端到端延迟的 tag 只有 murmur hash 过的算子 ID (用 uid() 方法设定的),并没有算子名称,并且官方暂时不打算解决这个问题,所以我们要么用最大值来表示,要么将作业中 Sink 算子的 ID 统一化。
subtask :每个下游算子的 sub task 都统计自己与 Source 算子的 sub task 之间的延迟。
配置:
metrics.latency.inte rval: 30000 # 默认0,表示禁用,单位毫秒
metrics.latency.granularity: operator # 默认 operator
注意事项:
保证 Flink 集群内所有节点的时区、时间是同步的 ProcessingTimeService 产生时间戳最终是靠 System.currentTimeMillis() 方法,可以用 ntp 等工具来配置。
metrics.latency.interval的时间间隔宜大不宜小,一般配置成 30000 30 秒)左右。一是因为延迟监控的频率可以不用太频繁,二是因为 LatencyMarker 的处理也要消耗一定性能。
开启对象重用:
概述:
当调用了enableObjectReuse方法后, Flink 会把中间深拷贝的步骤都省略掉,SourceFunction 产生的数据直接作为 MapFunction 的输入 ,可以 减少 gc 压力 。
但需要特别注意的是,这个方法不能随便调用,必须要确保下游 Function 只有一种,或者下游的Function 均不会改变对象内部的值。否则可能会有线程安全的问题。
配置:
-Dpipeline.object-reuse=true
细粒度滑动窗口优化:
细粒度滑动的影响:
当使用细粒度的滑动窗口(窗口长度远远大于滑动步长)时, 重叠的窗口过多,一个数据 会属于 多个窗口, 性能会急剧下降。
比如以 3 分钟的频率实时计算 App 内各个子模块近 24 小时的PV和UV。
状态保存数据重复(主要):
对于一个元素,会将其写入对应的(key,window)二元组所圈定的 windowState 状态中。如果粒度为 480 ,那么每个元素到来,更新 windowState 时都要遍历 480 个窗口并写入,开销是非常大的。在采用 RocksDB 作为状态后端时, checkpoint 的瓶颈也尤其明显。
定时器增加:
每一个(key, 二元组)都需要注册两个定时器:一是触发器注册的定时器,用于决定窗口数据何时输出;二是 registerCleanupTimer() 方法注册的清理定时器,用于在窗口彻底过期(如 allowedLateness 过期)之后及时清理掉窗口的内部状态。细粒度滑动窗口会造成维护的定时器增多,内存负担加重。
解决:
滚动窗口 + listState状态存储 + 读时聚合:
流程:
1.从业务的视角来看,往往窗口的长度是可以被步长所整除的,可以找到窗口长度和窗口步长的最小公约数作为时间分片(一个滚动窗口的长度)
2.每个滚动窗口将其周期内的数据做聚合, 存到下游状态或 打入外部在线存储(内存数据库如 Redis LSM based NoSQL 存储如 HBase)
listState状态存储也可以。
3.扫描在线存储中对应时间区间(可以灵活指定)的所有行,并将计算结果返回给前端展示。
聚合listState状态存储,移除旧的数据即可。
1.13 SQL 模块的 Window TVF:
Flink1.13 对SQL模块的 Window TVF 进行了一系列的性能优化,可以自动对滑动窗口进行切片解决细粒度滑动问题。
内存管理:
措施:
TaskManager 的堆内存可以分为三部分:
1. Network Buffers: 一定数量的32KB大小的 buffer,主要用于数据的网络传输。在 TaskManager 启动的时候就会分配。默认数量是 2048 个,可以通过taskmanager.network.numberOfBuffers 来配置。
2. Memory Manager Pool: 这是一个由 MemoryManager 管理的,由众多MemorySegment组成的超大集合。Flink 中的算法(如 sort/shuffle/join)会向这个内存池申请MemorySegment,将序列化后的数据存于其中,使用完后释放回内存池。默认情况下,池子占了堆内存的 70% 的大小。
3. Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager的数据结构使用的。因为这些数据结构一般都很小,所以基本上这些内存都是给用户代码使用的。从GC的角度来看,可以把这里看成的新生代,也就是说这里主要都是由用户代码生成的短期对象。
采用类似 DBMS 的 sort 和 join 算法,直接操作二进制数据,从而使序列化/反序列化带来的开销达到最小。所以 Flink 的内部实现更像 C/C++ 而非Java。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。
优点:
减少GC压力。
所有常驻型数据都以二进制的形式存在 Flink 的MemoryManager中,这些MemorySegment一直呆在老年代而不会被GC回收。
避免了OOM。
所有的运行时数据结构和算法只能通过内存池申请内存,保证了其使用的内存大小是固定的,不会因为运行时数据结构和算法而发生OOM。
节省内存空间。
只存储实际数据的二进制内容
高效的二进制操作 & 缓存友好的计算
重启策略:
Worker重启策略:
1.固定延迟重启策略
固定延迟重启策略是尝试给定次数重新启动作业。如果超过最大尝试次数,则作业失败。在两次连续重启尝试之间,会有一个固定的延迟等待时间。
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 5
restart-strategy.fixed-delay.delay: 10s
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(20, 1000))
yarn启动参数:
-yD restart-strategy=fixed-delay
-yD restart-strategy.fixed-delay.attempts=20
2.故障率重启策略
故障率重启策略在故障后重新作业,当设置的故障率(failure rate)超过每个时间间隔的故障时,作业最终失败。在两次连续重启尝试之间,重启策略延迟等待一段时间。
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5min
restart-strategy.failure-rate.delay: 10s
代码env.setRestartStrategy(RestartStrategies.failureRateRestart(3,Time.of(5, TimeUnit.MINUTES),Time.of(10, TimeUnit.SECONDS)));
3.无重启策略
作业直接失败,不尝试重启。
env.setRestartStrategy(RestartStrategies.noRestart());
4.后备重启策略
使用群集定义的重新启动策略。这对于启用检查点的流式传输程序很有帮助。
Jobmnager重启配置:
yarn.application-attempt-failures-validity-interval am重启间隔,默认10000毫秒
yarn.application-attempts ApplicationMaster重启次数,默认为1,如果高可用,默认为2,同时被yarn.resourcemanager.am.max-attempts限制。
Python 流处理api使用心得:
基于自带的jython jar依赖来提供解释器
1.想使用第三方包,就记得添加sys.path,默认flink集群上的python解释器加载的path没有pip包位置(单独启动的python有,估计是pth的问题)
2.如果要import文件,位于flink-1.8.0/下的文件会被打包发送,直接import 该路径下存放的文件即可
如果执行的文件位于其他地方,import的文件不是位于flink-1.8.0/下,通过:
bin/pyflink-stream.sh ~/test.py ~/import_test.py 即可
3.对于依赖connector的jar文件,提交到集群yarn上时,需lib目录下存在
4.由于Flink Python流API使用Jython框架,所以python依赖编译c语言动态库的第三方库,在cpython可用,在jython不可用
一些so文件可以通过cdll.LoadLibrary()导入,另一些则不行,估计是还用到其他动态库
# 尝试手动cdll.LoadLibrary导入/user/lib和/lib下的so文件,结果内存不足
对于MySQLdb,可以使用
import pymysql # 这个jython有,用jython的,不然报Access denied (using password: NO)
pymysql.install_as_MySQLdb()
依赖包cryptography可以用python2的,配置sys.path即可
# 连接数据库的账号认证方式改为mysql_native_password,后来测试caching_sha2_password又正常了
5.python不能使用setStreamTimeCharacteristic
6.对于提交python作业到集群上
1)提交单个作业-m,--jobmanager需要改写bin/pyflink.sh脚本,加上参数即可
2)提交到flink session集群上,和提交到本地一样,run即可自动找到集群并提交。
python 批处理api使用心得:
基于cpython和自定义的path来提供解释器
1.启动脚本时还没到excute阶段前,sys.path是当前提交节点的路径path,即还在提交服务器上,只要该服务器有第三方库,都可import使用
# flink启动自定义的python进程来执行这个脚本,也可以在excute之前使用多进程。
可以使用多线程
2.map函数内可以mysql插入,flatmap则不行,原来是类的方法名字写错了,是flat_map,不同于流处理的flatMap
3.map函数的异常会raise出来,如果没有的话确认函数真正执行了
4.print和log没有显示,而raise抛出的异常栈信息会输出在client.log文件里
一开始是启动了flink后,rm所有log,结果print没有显示(只会生成client.log文件)。
得重启flink才生效
yarn集群的out文件大概在hadoop的log里面。
5.flink本地cluster只能parallelism为1,yarn cluster -s 8的话slot经常被remove
spark则不同了,setMaster("local[8]")即可用本地的8个进程来运行。
而且spark的map和reduce并行度和flink的parallelism概念层次不一样。
spark的是确定local 8 进程后,代码里面的map和reduce不用设置并发度
flink的是taskmanager启动多个slot后,代码里面设置parallelism为多少就用到多少个slot
6.用过spark后,spark默认获取所有CPU数,flink需要设置配置里的taskmanager.numberOfTaskSlots,默认是1
flink任务的并行度set_parallelism如果超过slot数量,会等待slot执行完一个并行度(多个阶段)才执行下一个并行度(开始阶段)
但等待slot的时间超过了5分钟(slot.idle.timeou默认配置)的话,就会自动失败!!!
此外,standalone模型下
1.需要配置jobmanager.rpc.address才能slaves节点间通信
2.slaves节点环境变量设置与master相同,就要求项目代码位置相同
3.如果需要类似spark一样传zip包,
./bin/pyflink.sh xx.py xx.zip
Java批式心得:
对于普通的map和reduce操作,python也可实现,只是提交到集群上时一些参数需要额外修改pyflink.sh文件手动添加
而对于高级功能如容错、迭代,需要java才可实现
Java流式心得:
1.对于flink相关依赖的版本,之前是1.8.0,会报java.lang.NoSuchMethodError,得为1.8.1。
2.对于Caused by: java.lang.NullPointerException,一般是找不到topic,注意不能多个topic逗号分割,得是{"",""}的形式
3.consumer使用flink自带JSONKeyValueDeserializationSchema类来解析,而Producer分两种情况:
- 不发送key,则使用lambda表达式来写函数即可,即只对value进行处理
- 自定义key、topic、value,则继承KeyedSerializationSchema这个类,可以指定发送的key和topic
也可以用SimpleStringSchema,然后用json工具解析。
4.对于group_id消费的offset,设置了setStartFromGroupOffsets后,如果一开始没有记录的时候从auto.offset.reset设置开始,默认是largest(kafka默认属性)
如果一开始kafka已经有该group_id,会从committed的位置开始消费。
checkpoint中保存的offset数据仅用于恢复。
5.自定义partitioner:
- 继承FlinkFixedPartitioner,同时添加参数泛型<T>(参考FlinkFixedPartitioner)
- import java.util.Optional;
- Optional.of(new KafkaUidPartitioner<>())即可
6.对于ObjectNode,通过!old_data.isNull()&&old_data.get(0).has("status")来判断是否存在
7.关于kafka consumer遗漏问题,一开始以为是数据库延迟导致条件没判断,后来每一条record输出一次,明显输出变少(有可能是还没消费到)
使用测试topic来测试,发现输出没少(一开始没,后来有了,可能是checkpoint的问题,重启就有了)
问题可能出在 checkpoint 上面
总结:生产topic sink到print还是有漏的情况,然而测试topic sink到print就没漏
生产topic 到 kafka 目前kafka没有遗漏,测试topic 到 kafka,kafka没漏,print漏了
# print漏了,说明是print flush的问题,addsink到kafka应该没有遗漏。
# 那么生产上消费遗漏就可能是其他问题了(新asetku抽样几个还款event都全)。
standalone模式:
./bin/flink run -c chenzl.flinktask.ModelEvent kafka-test/target/kafka-test-0.0.1-SNAPSHOT.jar
yarn单作业模式:
# 需要下载hadoop jar包,wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-7.0/flink-shaded-hadoop-2-uber-2.8.3-7.0.jar
./bin/flink run -m yarn-cluster -ys 10 -c chenzl.flinktask.ModelEvent /home/ubuntu/data/kafka-test/target/kafka-test-0.0.1-SNAPSHOT.jar
后台模式:
./bin/flink run -yd -m yarn-cluster -ynm model_event -ys 10 -c chenzl.flinktask.ModelEvent
/home/ubuntu/data/kafka-test/target/kafka-test-0.0.1-SNAPSHOT.jar
./bin/flink run -d -m yarn-cluster -ys 10 -c chenzl.flinktask.ModelEvent /home/ubuntu/data/kafka-test/target/kafka-test-0.0.1-SNAPSHOT.jar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号