泰坦尼克获救预测
数据中标签的含义:
- PassengerId => 乘客ID
- Pclass => 乘客等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 堂兄弟/妹个数
- Parch => 父母与小孩个数
- Ticket => 船票信息
- Fare => 票价
- Cabin => 客舱
- Embarked => 登船港口
将数据进行描述读取
import pandas
titanic = pandas.read_csv('titanic_train.csv')
print(titanic.describe())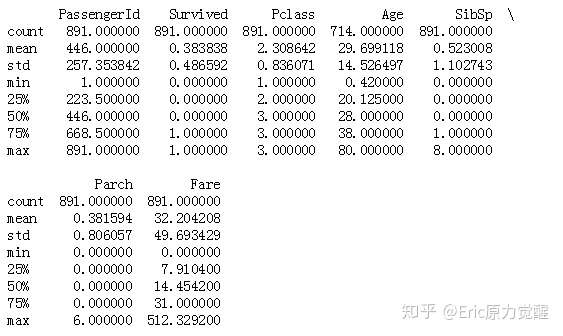
发现Age中有缺失值,使用平均值填补缺失值
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].median())
print(titanic.describe())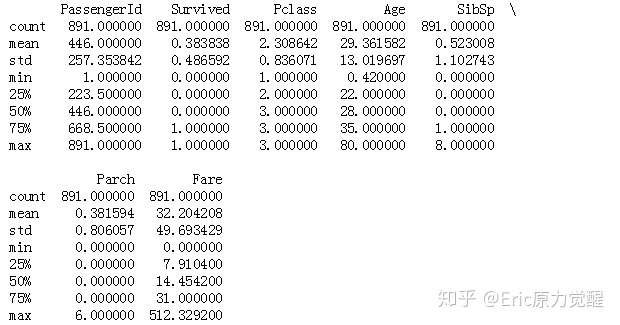
将字符型的值如,性别,上船地点,进行数值替换
print(titanic['Sex'].unique())
titanic.loc[titanic['Sex'] == 'male','Sex'] = 0
titanic.loc[titanic['Sex'] == 'female','Sex'] = 1
print(titanic['Embarked'].unique())
titanic['Embarked'] = titanic['Embarked'].fillna('S')
titanic.loc[titanic['Embarked'] == 'S','Embarked'] = 0
titanic.loc[titanic['Embarked'] == 'C','Embarked'] = 1
titanic.loc[titanic['Embarked'] == 'Q','Embarked'] = 2将Survived:获救与否,作为label值,引入交叉验证后,将label值与特征进行回顾分析
from sklearn.linear_model import LinearRegression
from sklearn.cross_validation import KFold
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
alg = LinearRegression()
#使用Kfold将样本的训练集做一个3倍的交叉验证
kf = KFold(titanic.shape[0],n_folds = 3,random_state = 1)
#在每次交叉验证中建立回归模型
predictions = []
for train,test in kf:
#取出训练集中的船员特征属性
train_predictors = (titanic[predictors].iloc[train,:])
#取出训练集中的是否获救的结果
train_target = titanic['Survived'].iloc[train]
#将线性回归应用到数据
alg.fit(train_predictors,train_target)
#运行测试结果
test_predictions = alg.predict(titanic[predictors].iloc[test,:])
#将结果收集
predictions.append(test_predictions)调用numpy将测试结果(获救概率)以50%为界做二分类,并将预测结果与真实结果比较得出正确率
import numpy as np
#调用数组操作函数
predictions = np.concatenate(predictions,axis=0)
#将输出的0到1区间内的结果以0.5作为分界点做二级分化
predictions[predictions > .5] = 1
predictions[predictions <= .5] = 0
#将预测输出的结果与训练集中的真实结果进行正确率比较
accuracy = sum(predictions ==titanic['Survived']) / len(predictions)
print(accuracy)0.7833894500561167
尝试使用随机森林的方法,看正确率是否能提升
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
#导入特征集合
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
#创建随机森林 决策树数量 为10个,停止条件为最小树枝为2或最小叶子数为一
alg = RandomForestClassifier(random_state = 1,n_estimators = 10,min_samples_split = 2,min_samples_leaf = 1)
#再进行一次交叉检验
kf =cross_validation.KFold(titanic.shape[0],n_folds = 3,random_state = 1)
#进行模型评估 分类器为随机森林,数据为船员特征,目标为生存率,参数为交叉检验的结果
scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic['Survived'],cv = kf)
print(scores.mean())0.7856341189674523
正确率略微提升。开发脑洞预备新加入一些特征如:家庭的规模=SibSp+Parch ,名字的全长,以及名字中间的身份称呼。
#统计家庭规模为长辈与兄弟的总和
titanic["FamilySize"] = titanic['SibSp'] + titanic['Parch']
#统计船员名字字母总长度
titanic['NameLength'] = titanic['Name'].apply(lambda x : len(x))
使用正则匹配挑选出名字中间的身份人称,进行数值编码后,导入新特征‘title’
import re
#使用正则表达 截取人名中的身份称呼
def get_title(name):
title_search = re.search('([A-Za-z]+)\.',name)
if title_search:
return title_search.group(1)
return ''
#以身份称呼为分类 统计船员个数
titles = titanic['Name'].apply(get_title)
print(pandas.value_counts(titles))
#将身份称呼进行 数字编码
title_mapping = {"Mr":1,"Miss":2,"Mrs":3,"Master":4,"Dr":5,"Rev":6,"Major":7,"Col":7,"Mlle":8,"Mme":8,"Don":9,"Lady":10,"Countess":10,"Jonkheer":10,"Str":9,"Capt":7,"Ms":2,"Sir":9}
for k,v in title_mapping.items():
titles[titles==k]=v
print(pandas.value_counts(titles))
#将转化好的特征新增到数据集名称Title中
titanic['Title'] = titles
导入SKlearn的特征选择模块,通过向训练集中加入噪音数值,来判断影响最大的特征
#导入特征选择模块
import numpy as np
from sklearn import cross_validation
from sklearn.feature_selection import SelectKBest,f_classif
import matplotlib.pyplot as plt
predictors = ["Pclass","Sex","Age","SibSp","Parch","Fare","Embarked","FamilySize","Title","NameLength"]
#通过加入噪音值观察
selector = SelectKBest(f_classif,k=5)
selector.fit(titanic[predictors],titanic["Survived"])
scores=-np.log10(selector.pvalues_)
#输出柱状图
plt.bar(range(len(predictors)),scores)
plt.xticks(range(len(predictors)),predictors,rotation='vertical')
plt.show()
#选取影响最大的特征作为新的特征集
predictors = ["Pclass","Sex","NameLength","Title","Fare""]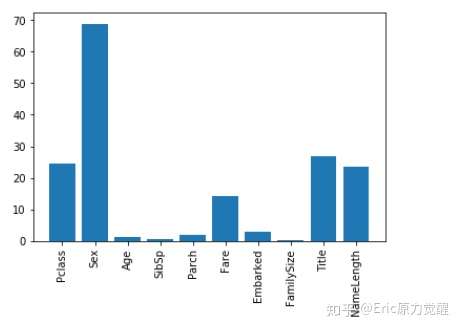
辛苦没白费新加入的两个特征影响果然较大,选取影响较大的五个个特征作为新的特征集,再次使用随机森林模型,并调整参数
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
#导入特征集合
predictors = ["Pclass","Sex","NameLength","Title","Fare"]
#创建随机森林 决策树数量 为50个,停止条件为最小树枝为4或最小叶子数为2
alg = RandomForestClassifier(random_state = 1,n_estimators = 50,min_samples_split = 4,min_samples_leaf = 10)
#再进行一次交叉检验
kf =cross_validation.KFold(titanic.shape[0],n_folds = 3,random_state = 1)
#进行模型评估 分类器为随机森林,数据为船员特征,目标为生存率,参数为交叉检验的结果
scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic['Survived'],cv = kf)
print(scores.mean())0.8159371492704826
正确率提高,再使用SKlearn的函数组合模块将回归与随机森林的算法结合使用
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
from sklearn.linear_model import LogisticRegression
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), ["Pclass","Sex","NameLength","Title","Fare"]],
[LogisticRegression(random_state=1), ["Pclass","Sex","NameLength","Title","Fare"]]
]
kf = KFold(titanic.shape[0], n_folds=3, random_state=1)
predictions = []
for train, test in kf:
train_target = titanic["Survived"].iloc[train]
full_test_predictions = []
for alg, predictors in algorithms:
alg.fit(titanic[predictors].iloc[train,:], train_target)
test_predictions = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1]
full_test_predictions.append(test_predictions)
test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2
test_predictions[test_predictions <= .5] = 0
test_predictions[test_predictions > .5] = 1
predictions.append(test_predictions)
predictions = np.concatenate(predictions, axis=0)
accuracy = sum(predictions[predictions == titanic["Survived"]]) / len(predictions)
print(accuracy)
0.821548821549
最终得出的最高正确率,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号