

hadoop安装详细步骤
安装包下载地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
1.卸载CentOS7自带jdk1.8,安装自己的jdk并设置环境变量
[root@localhost network-scripts]# rpm -qa |grep jdk java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 copy-jdk-configs-3.3-10.el7_5.noarch java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64 java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64
yum -y remove java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64 yum -y remove copy-jdk-configs-3.3-10.el7_5.noarch yum -y remove java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64 yum -y remove java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64 yum -y remove java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64
#判断有没有卸载好
java -version
[root@localhost network-scripts]# mkdir -p /usr/local/soft/java
把jdk包上传到/usr/local/soft/java ,并解压 tar -xvf jdk-8u311-linux-i586.tar.gz ,之后配置环境变量

vi /etc/profile #添加自己的jdk目录环境变量 root用户 对所有用户生效
export JAVA_HOME=/usr/local/soft/java/jdk1.8.0_311 #注意这里是自己的jdk解压目录 export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#用 source /etc/profile 命令是环境变量生效
#解压jdk
tar -xvf jak-8u311-linux-i586.tar.gz
#判断有没有安装好
java -version
#若报错bash: /usr/local/soft/java/jdk1.8.0_311/bin/java: /lib/ld-linux.so.2: bad ELF interpreter: No such file or directory
#执行下面命令
yum install glibc.i686
2.设置主机名
vi /etc/hosts
192.168.1.11 master
192.168.1.12 node1
192.168.1.13 node2
vi /etc/hosts #三台服务器做同样的操作 192.168.1.11 master 192.168.1.12 node1 192.168.1.13 node2
3.服务器之间设置免密登录
#master节点运行
ssh-keygen -t rsa ssh-copy-id -i node1 ssh-copy-id -i node2
4.安装hadoop
把安装包上传到 /usr/local/soft 路径
tar -zxvf hadoop-2.10.0.tar.gz
a) 在/usr/local/soft/hadoop-2.10.0/etc/hadoop 路径修改相应文件
1) 修改 slaves 文件中节点为
node1
node2
2)在 hadoop-env.sh 文件增加下面语句
export JAVA_HOME=/usr/local/soft/java/jdk1.8.0_311
3)修改core-site.xml文件 为下面配置 /usr/local/soft/hadoop-2.10.0 为实际安装路径
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/soft/hadoop-2.10.0/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> </configuration>
4)修改 hdfs-site.xml 下面配置
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
5)修改yarn-site.xml 为下面配置
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>20480</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> </configuration>
6)修改 mapred-site.xml(将mapred-site.xml.template 复制一份为 mapred-site.xml)
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
b) 同步hadoop解压文件到到node1 node2
scp -r /usr/local/soft/hadoop-2.10.0 node1:/usr/local/soft/ scp -r /usr/local/soft/hadoop-2.10.0 node2:/usr/local/soft/
首先看下hadoop-2.10.0目录下有没有tmp文件夹。
如果没有 执行一次格式化命令:
cd /usr/local/soft/hadoop-2.10.0目录下
执行命令:
./bin/hdfs namenode -format
会生成tmp文件。
然后
/usr/local/soft/hadoop-2.10.0目录下
启动执行:./sbin/start-all.sh
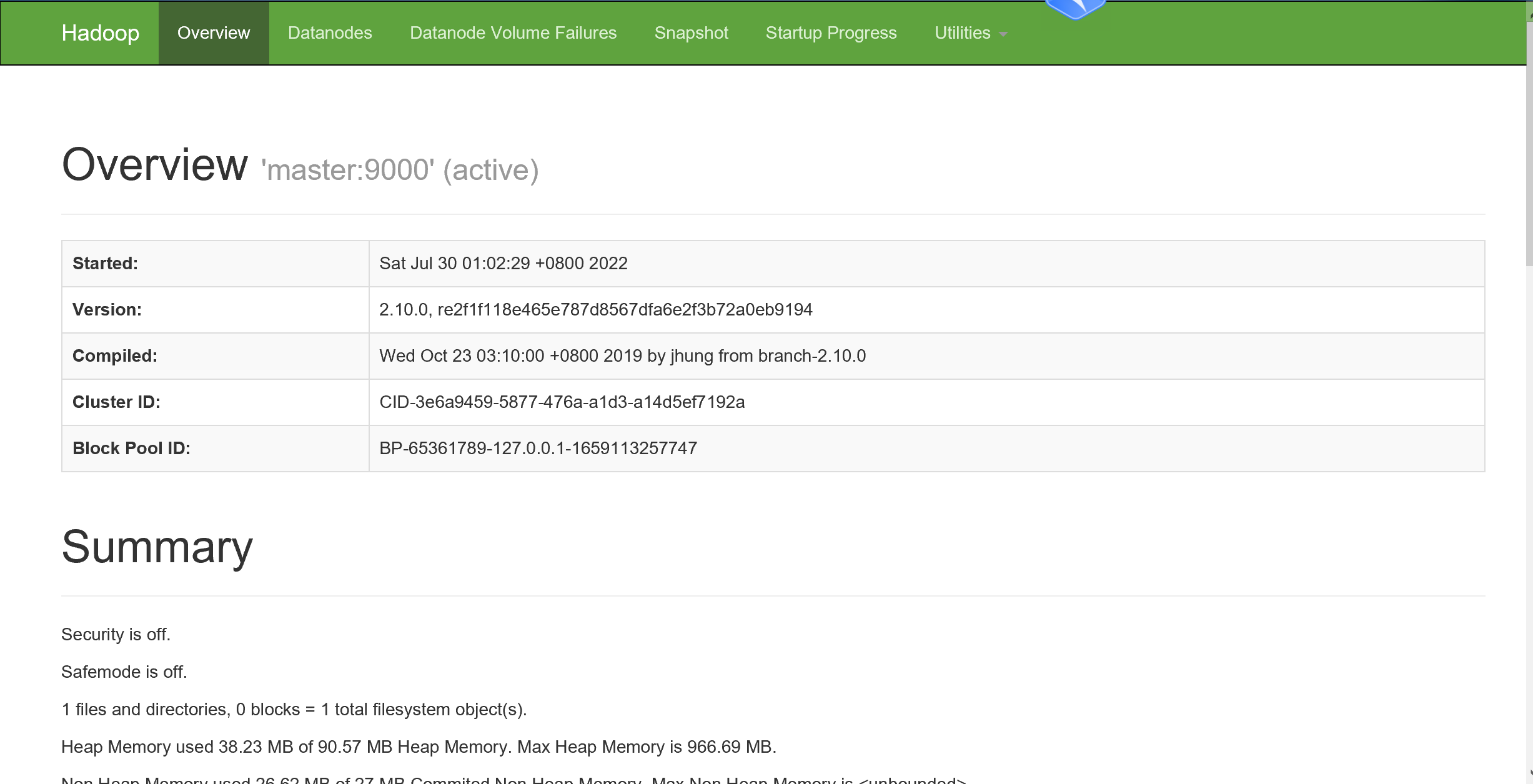
验证hdfs: 可以windows电脑登录浏览器(强烈建议chrome浏览器) 地址:192.168.0.11:50070 (ip地址是master的地址)
————————————————
版权声明:本文为CSDN博主「Kayleigh520」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Kayleigh520/article/details/121882874
部分取自博客链接:https://www.lmlphp.com/user/16591/article/item/563471/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通