
Pytorch Code积累
15个重要Python面试题 测测你适不适合做Python?
torch.squeeze()
Returns a tensor with all the dimensions of input of size 1 removed.
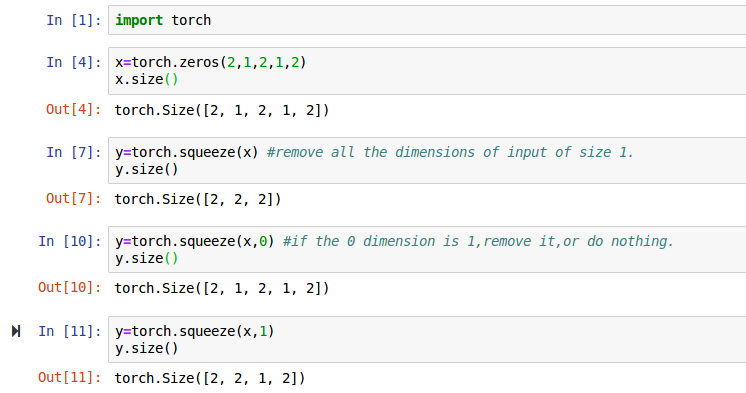
torch.unsqueeze(input, dim, out=None) → Tensor- Returns a new tensor with a dimension of size one inserted at the specified position.

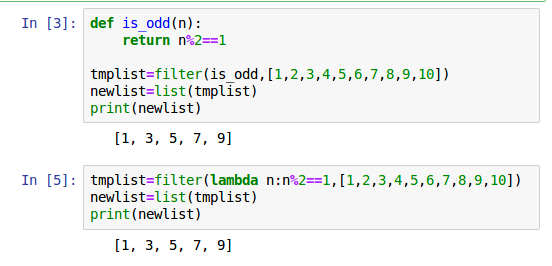
Python 3:filter()
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
Gensim
Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算,信息检索等一些常用任务的API接口。简单地说,Gensim主要处理文本数据,对文本数据进行建模挖掘。
https://blog.csdn.net/HuangZhang_123/article/details/80326363
traceback
捕获并打印异常,可以输出哪个文件哪个函数哪一行报的错。
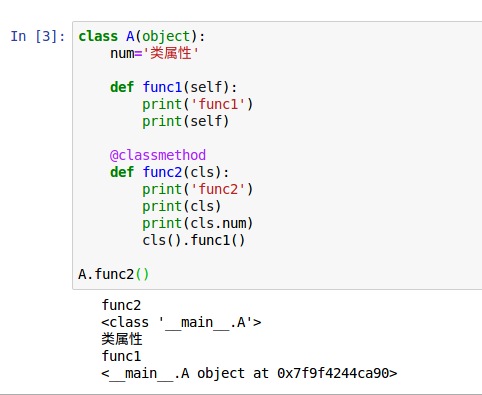
@classmethod,@staticmethod,@property
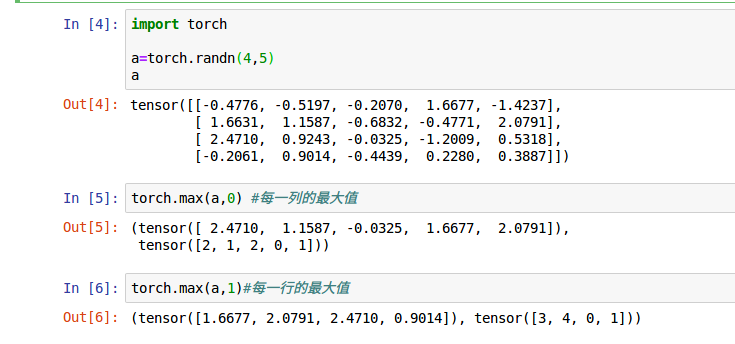
torch.max()
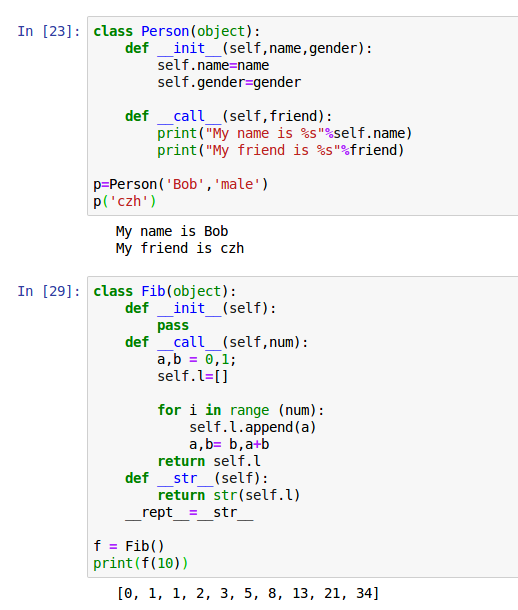
__call__
在类中实现该方法,一个类实例可以变成一个可调用对象。
代码出处:https://www.cnblogs.com/superxuezhazha/p/5793536.html
更多特殊函数: https://www.cnblogs.com/xiao987334176/p/8884002.html#autoid-0-1-0
IoU(Intersection over Union)的计算
def IOU(xywh1, xywh2):
x1, y1, w1, h1 = xywh1
x2, y2, w2, h2 = xywh2
dx = min(x1+w1, x2+w2) - max(x1, x2)
dy = min(y1+h1, y2+h2) - max(y1, y2)
intersection = dx * dy if (dx >=0 and dy >= 0) else 0.
union = w1 * h1 + w2 * h2 - intersection
return (intersection / union)
其中(x1,y1),(x2,y2)分别为两个矩阵左下角的顶点,w,h为宽和高。
xml解析
https://www.cnblogs.com/zqchen/articles/3936805.html
layer of model
model.children() returns an iterable of high-level layers present in model.
model.named_children() returns an iterable of two-element tuples, where the first element is the name of the high-level layer and the second element is the high-level layer.

inception loss
if is_inception and phase == 'train':
# From https://discuss.pytorch.org/t/how-to-optimize-inception-model-with-auxiliary-classifiers/7958
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
inception_v3 requires the input size to be (299,299), whereas all of the other models expect (224,224).
详解Pytorch中的网络构造(nn.Module)
https://zhuanlan.zhihu.com/p/53927068
affine_grad和grid_sample
https://www.jianshu.com/p/723af68beb2e
torch.gather


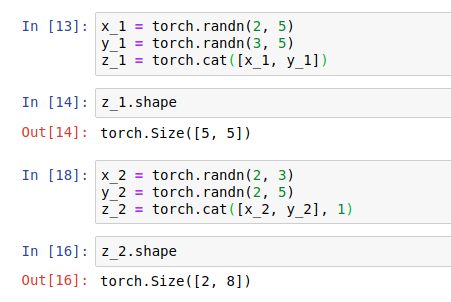
torch.cat
.view() : reshape a tensor.

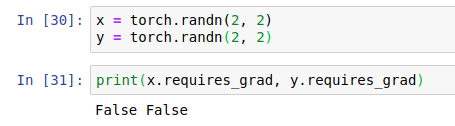
By default, user created Tensors have 'requires_grad = False'
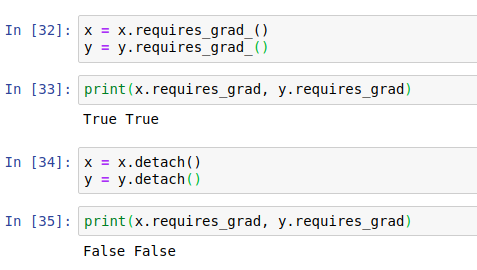
.requires_grad_() 和 .detach()
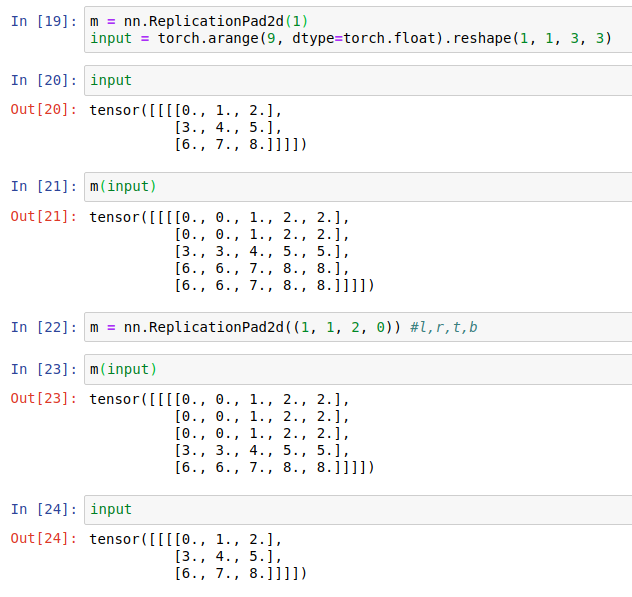
torch.nn.ReplicationPad2d(padding)
Pads the input tensor using replication of the input boundary.
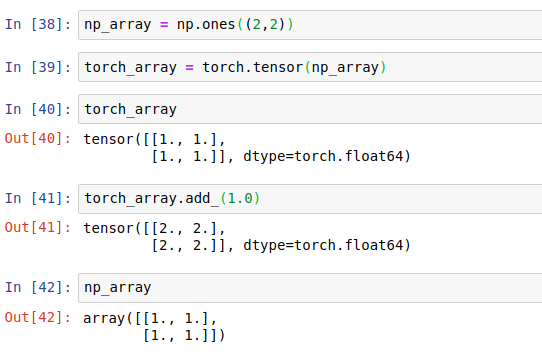
torch.tensor(np_array):
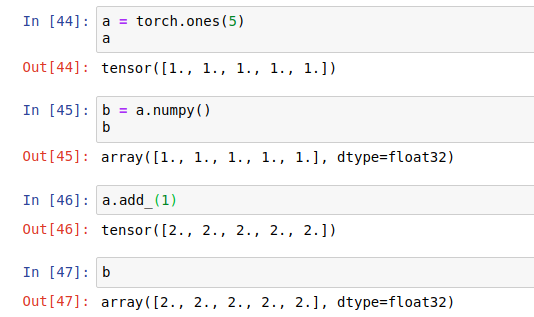
.numpy():Converting a Torch Tensor to a NumPy Array
.from_numpy: Converting NumPy Array to Torch Tensor

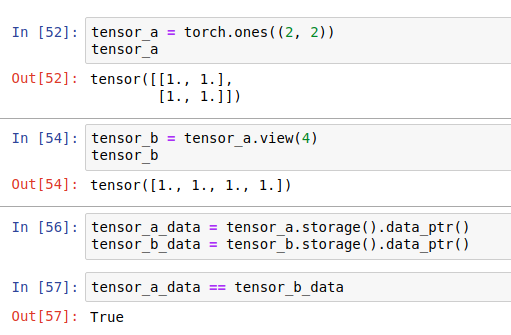
tensor_b is a different view (interpretation) of the same data present in the underlying storage
torch.stack: 增加新的维度做堆叠

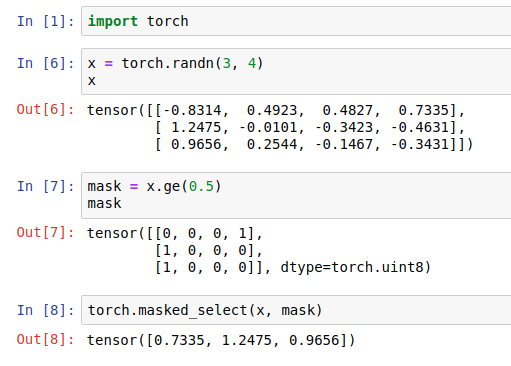
torch.masked_select :在训练阶段,损失函数通常需要进行mask操作,因为一个batch中句子的长度通常是不一样的,一个batch中不足长度的位置需要进行填充(pad)补0,最后生成句子计算loss时需要忽略那些原本是pad的位置的值,即只保留mask中值为1位置的值,忽略值为0位置的值
Python标准库(3.x): itertools库
https://www.cnblogs.com/tp1226/p/8453564.html
Python标准库(3.x): 内建函数
https://www.cnblogs.com/tp1226/p/8446503.html
torch.einsum:
https://www.jqr.com/article/000481
Scikit-Learn中TF-IDF权重计算方法主要用到两个类:CountVectorizer和TfidfTransformer
select first/last N
select by specific index
index_select
…
select by mask 会把数据打平

select by flatten index

Tensor维度变换
view/reshape: 丢失维度信息
squeeze

unsqueeze:插入的index的取值范围[-a.dim()-1, a.dim()+1)
transpose / .t() (only for 2D)

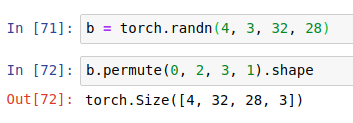
permute
expand: broadcasting (推荐)
repeat: memory copied

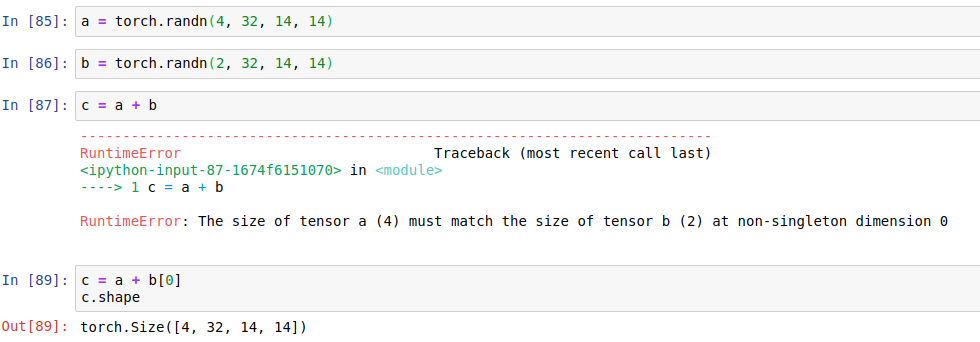
Broadcast
Expand
without copying data
match from last dim
Merge or Split
cat: concate的维度可以不一样,其它维度必须一样.

stack: create new dim at the dim value
所有的维度必须一样(e.g. a和b).

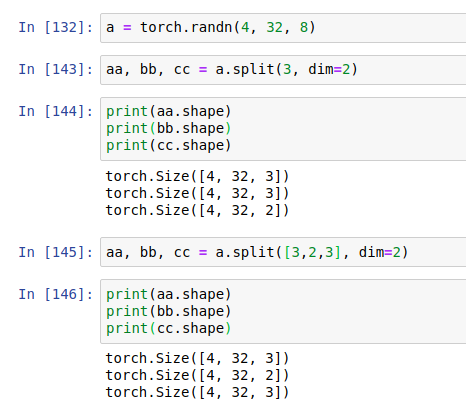
split: by length
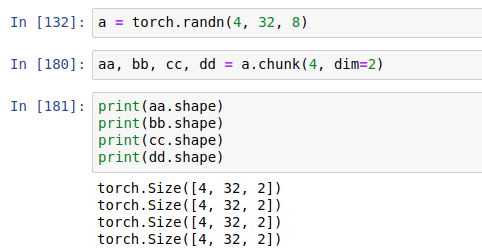
chunk: by num
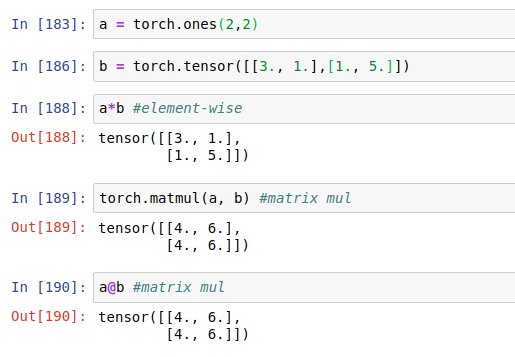
*: element-wise
matmul:matrix 乘法, torch.mm(only for 2D)、torch.matmul、@
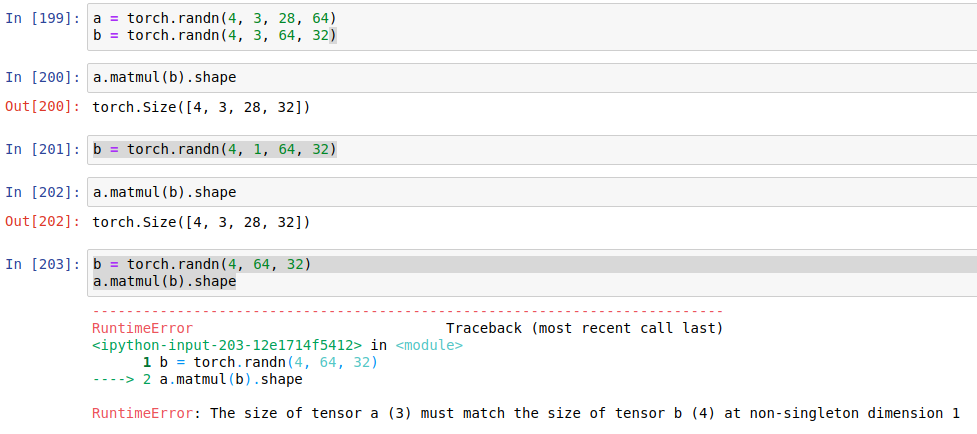
>2d tensor matmul
.floor() .ceil()
.round(): 四舍五入
.trunc() .frac()
clamp: gradient clipping, (min), (min, max)
statistics
norm: 范数用来衡量一个向量的大小
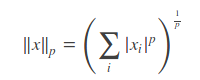
mean sum
prod
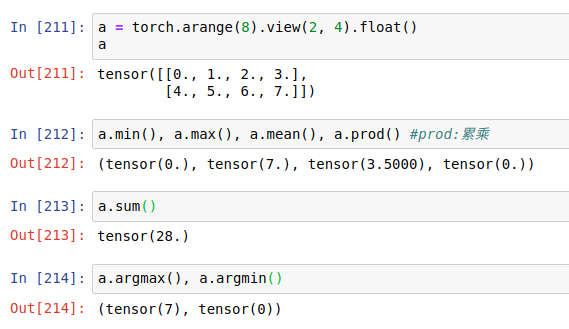
max, min,
argmin, argmax: 返回的是索引
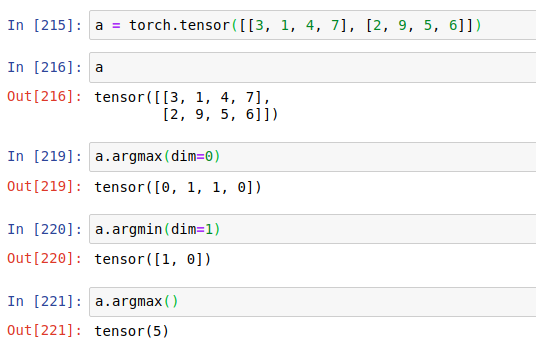
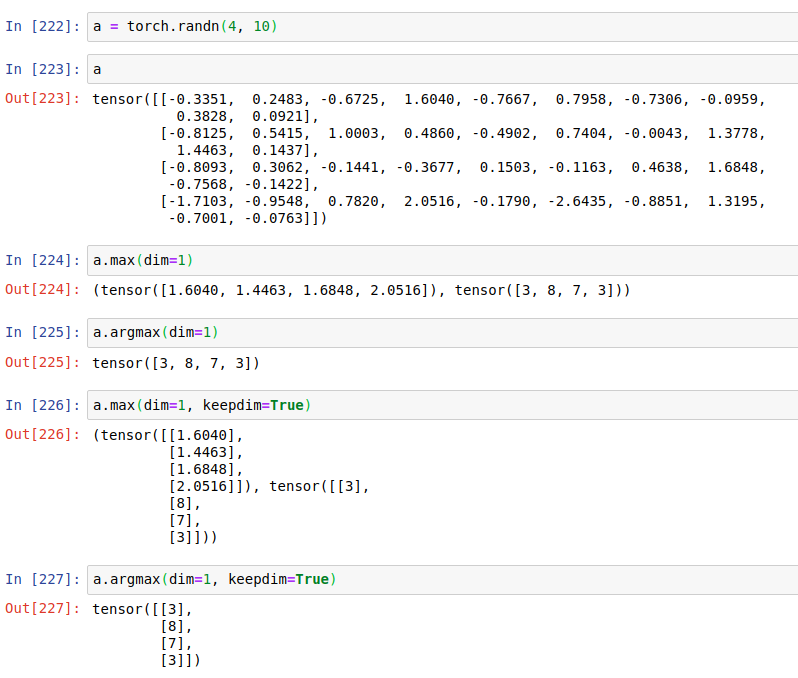
dim, keepdim
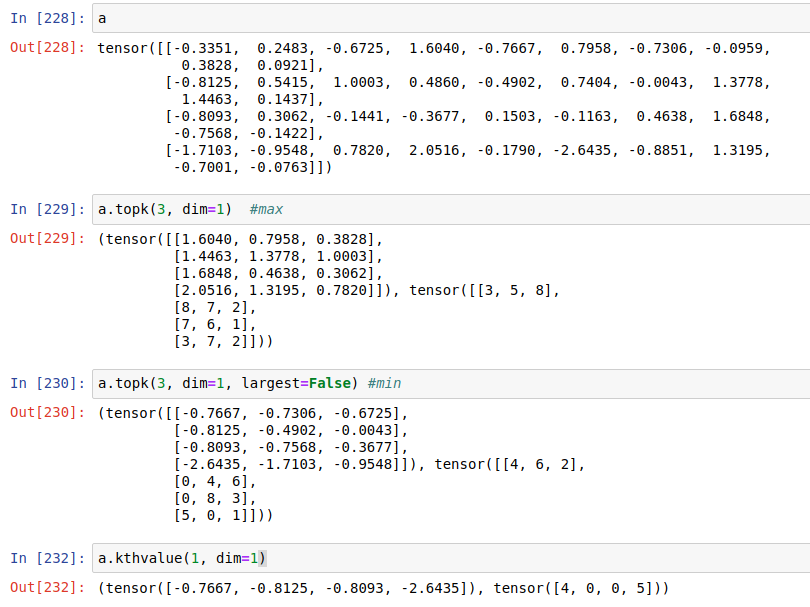
kthvalue(返回第k小), topk
compare
torch.eq
torch.gt
Tensor advanced operation
where (condition, a, b)
gather
Image Preprocessing:
Image Resize
Data Augumentation
Normalize
ToTensor
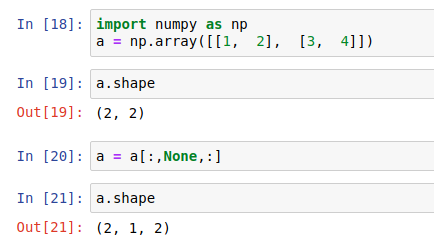
Numpy中数组索引为None
https://www.kaggle.com/gyani95/380000-lyrics-from-
metrolyrics

 浙公网安备 33010602011771号
浙公网安备 33010602011771号