HTML基础
此笔记是对各位博主的知识讲解进行自我总结和笔记抄录并附上自己实践的流程
博主: 千古一号.讲解很到位,并且维持更新.是很值得关注的博主
附上GitHub 链接: https://github.com/qianguyihao/Web
笔记内容:
1.Sublime Text安装Emmet插件(用于快速生成html骨架)
2.html 概述,概念和历史
3.书写第一个HTML
4.HTML结构讲解
5.其他知识
前期准备工作:
1.打开编辑器

2. ctrl + n 新建一个页面 ctrl + s (保存),并命名为 test.html(任意非中文名字+后缀名)

3.Sublime Text中安装Emmet插件(之前有讲过, ctrl + shift + p 输入 Emmet ,回车即可).这个操作不会的请看我之前的笔记
链接: https://www.cnblogs.com/czh333/p/12714858.html
4.在页面上按 输入html:5,按Tab键后,自动生成的代码如下:
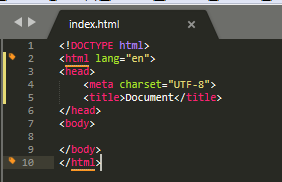
这样就快速生成了HTML 的基本骨架,(看不懂没关系.有个印象.以后就慢慢懂了)
在编写之前,先知其然,然后知其所以然.接下来我们先了解一下基本的知识
初识HTML:
HTML的概念:
HTML全称为 HyperText Markup Language,也就是 超文本 标记 语言.
HTML 不是一种编程语言,是一种描述性的 标记语言
作用:HTML 是负责描述文档语义的语言.
超文本:
两层含义:
(1)图片,音频,视频,动画,多媒体等内容,成为超文本,因为它们超出了文本
(2)不仅如此,他还可以从一个文件跳转到另一个文件,与世界主机的文件进行连接.即:超级链接文本
标记语言:
HTML 不是一种编程语言,是一种描述性的标记语言。这主要有两层含义:
(1)标记语言是一套标记标签。比如:标签<a>表示超链接、标签<img>表示图片、标签<h1>表示一级标题等等,它们都是属于 HTML 标签。
说的通俗一点就是:网页是由网页元素组成的,这些元素是由 HTML 标签描述出来,然后通过浏览器解析,就可以显示给用户看了。
(2)编程语言是有编译过程的,而标记语言没有编译过程,HTML标签是直接由浏览器解析执行。
HTML是负责描述文档语义的语言:
HTML 格式的文件是一个纯本文文件(就是用txt文件改名而成),用一些标签来描述语义,这些标签在浏览器页面上是无法直观看到的,所以称之为“超文本标记语言”。
HTML历史:
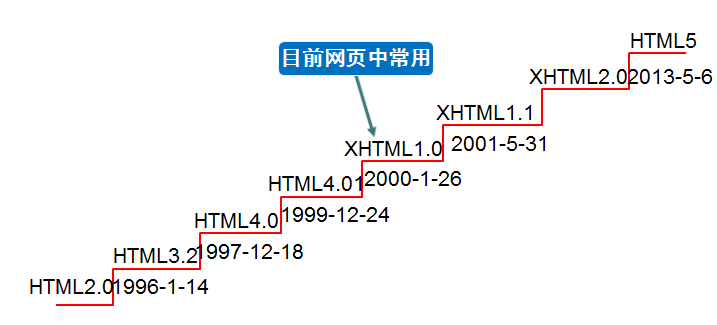
其中专门来对XHTML做一个介绍:(有待学习)
XHTML介绍: XHTML:Extensible Hypertext Markup Language,可扩展超文本标注语言。 XHTML的主要目的是为了取代HTML,也可以理解为HTML的升级版。 HTML的标记书写很不规范,会造成其它的设备(ipad、手机、电视等)无法正常显示。 XHTML与HTML4.0的标记基本上一样。 XHTML是严格的、纯净的HTML。
HTML的专有名词(总结超级到位,标注颜色的可以留个印象)
网页 :由各种标记组成的一个页面就叫网页。
主页(首页) : 一个网站的起始页面或者导航页面。
标记: 比如<p>称为开始标记 ,</p>称为结束标记,也叫标签。每个标签都规定好了特殊的含义。
元素:比如<p>内容</p>称为元素.
属性:给每一个标签所做的辅助信息。
XHTML:符合XML语法标准的HTML。
DHTML:dynamic,动态的。javascript + css + html合起来的页面就是一个 DHTML。
HTTP:超文本传输协议。用来规定客户端浏览器和服务端交互时数据的一个格式。SMTP:邮件传输协议,FTP:文件传输协议。
HTML的基本骨架:(不需要背,看多了自然就会了)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <body> </body> </html>
骨架标签(标记)介绍:(可以观察一下骨架的嵌套关系)
| 标签名 | 定义 | 说明 |
|---|---|---|
<html></html> |
HTML标签 | 页面中最大的标签,我们称为根标签 |
<head></head> |
文档的头部 | 注意在head标签中我们必须要设置的标签是title |
<titile></title> |
文档的标题 | 让页面拥有一个属于自己的网页标题 |
<body></body> |
文档的主体 | 元素包含文档的所有内容,页面内容 基本都是放到body里面的 |
编写第一个HTML 页面
然后在骨架上加入以下代码,用谷歌浏览器打开(右键浏览器打开,一般设置谷歌为默认浏览器即可)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>网页标题</title> </head> <body> <h3>我是三级标题</h3> <p>这是我的第一个段落</p> </body> </html>
效果:一种成功的感觉!
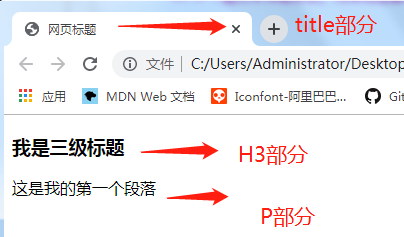
解释:
(以下内容文字比较多,建议回头多看,看了一号博主的总结,感觉经验值加一,感觉去gitHubstar 一下!!!!)
※文档声明头
<!DOCTYPE html> 这里的我们使用的html版本是HTML5 浏览器会使用对应机制解析.
任何一个标准的HTML页面,第一行一定是一个以<!DOCTYPE ……>开头的语句。
这一行,就是文档声明头,即 DocType Declaration,简称DTD。
DTD可告知浏览器文档使用哪种 HTML 或 XHTML 规范
HTML4.01有哪些规范呢?
HTML4.01这个版本是IE6开始兼容的。HTML5是IE9开始兼容的。如今,手机、移动端的网页,就可以使用HTML5
了,因为其兼容性更高.
html1 至 html3 是美国军方以及高等研究所用的,并未对外公开。
HTML4.01里面有两大种规范,每大种规范里面又各有3种小规范。所以一共6种规范
HTML4.01里面规定了普通和XHTML两大种规范。HTML觉得自己有一些规定不严谨,比如,标签是否可以用大写字母呢?<H1></H1>所以,HTML就觉得,把一些规范严格的标准,又制定了一个XHTML1.0。在XHTML中的字母X,表示“严格的”。
总结一下,HTML4.01一共有6种DTD。说白了,HTML的第一行语句一共有6种情况:

下面对上图中的三种小规范进行解释:
strict:
表示“严格的”,这种模式里面的要求更为严格。这种严格体现在哪里?有一些标签不能使用。 比如,u标签,就是给一个本文加下划线,但是这和HTML的本质有冲突,因为HTML最好是只负责语义,不要负责样式,而u这个下划线是样式。所以,在strict中是不能使用u标签的。
那怎么给文本增加下划线呢?今后将使用css属性来解决。
XHTML1.0更为严格,因为这个体系本身规定比如标签必须是小写字母、必须严格闭合标签、必须使用引号引起属性等等。
Transitional:表示“普通的”,这种模式就是没有一些别的规范。
Frameset:表示“框架”,在框架的页面使用。
在sublime输入的html:xt,x表示XHTML,t表示transitional。
在HTML5中极大的简化了DTD,也就是说HTML5中就没有XHTML了。HTML5的DTD(文档声明头)如下:
<!DOCTYPE html>
※页面语言 lang
下面这行标签,用于指定页面的语言类型:
<html lang="en"> //en 定义语言为英文
最常见的语言类型有两种:
en:定义页面语言为英语。
zh-CN:定义页面语言为中文。
※头部标签 head
//这个是千古一号博主的例子 html5 的比较完整的骨架
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> //字符集 <meta name="viewport" content="width=device-width, initial-scale=1.0"> //视口 <meta http-equiv="Content-Type" content="text/html;charset=UTF-8"> //字符集 html5之前的页面会这样写 <meta name="Author" content=""> //定义网页作者 <meta name="Keywords" content="厉害很厉害" /> // 网页关键词 <meta name="Description" content="网易是中国领先的互联网技术公司,为用户提供免费邮箱、游戏、搜索引擎服务,开设新闻、娱乐、体育等30多个内容频道,及博客、视频、论坛等互动交流,网聚人的力量。" /> //Description 网页描述
<title>Document</title> </head> <body> </body> </html>
附上 Ada zheng 大佬的总结可以根据需求查阅:https://www.cnblogs.com/ada-zheng/p/4318478.html
头标签内部的常见标签如下:
-
<title>:指定整个网页的标题,在浏览器最上方显示。<base>:为页面上的所有链接规定默认地址或默认目标。<meta>:提供有关页面的基本信息<body>:用于定义HTML文档所要显示的内容,也称为主体标签。我们所写的代码必须放在此标签內。<link>:定义文档与外部资源的关系。
meta 标签:
meta表示“元”。“元”配置,就是表示基本的配置项目。
常见的几种 meta 标签如下:
(1)字符集 charset:
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
字符集用meta标签中的charset定义,charset就是charactor set(即“字符集”),即网页的编码方式。
字符集(Character set)是多个字符的集合。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
上面这行代码非常关键, 是必须要写的代码,否则可能导致乱码。比如你保存的时候,meta写的和声明的不匹配,那么浏览器就是乱码。
utf-8是目前最常用的字符集编码方式,常用的字符集编码方式还有gbk和gb2312等。关于“编码方式”,下一段会详细介绍。
(2)视口 viewport:
<meta name="viewport" content="width=device-width, initial-scale=1.0">
width=device-width :表示视口宽度等于屏幕宽度。
viewport 这个知识点,刚开始还比较难理解,以后学 Web 移动端的时候会用到。
(3)定义“关键词”:
举例如下:
<meta name="Keywords" content="网易,邮箱,游戏,新闻,体育,娱乐,女性,亚运,论坛,短信" />
这些关键词,就是告诉搜索引擎,这个网页是干嘛的,能够提高搜索命中率。让别人能够找到你,搜索到你。
(4)定义“页面描述”:
meta除了可以设置字符集,还可以设置关键字和页面描述。
只要设置Description页面描述,那么百度搜索结果,就能够显示这些语句,这个技术叫做SEO(search engine optimization,搜索引擎优化)。
设置页面描述的举例:
<meta name="Description" content="网易是中国领先的互联网技术公司,为用户提供免费邮箱、游戏、搜索引擎服务,开设新闻、娱乐、体育等30多个内容频道,及博客、视频、论坛等互动交流,网聚人的力量。" />
有一个标签,说是需要我们必须记住的:
<meta http-equiv="refresh" content="3;http://www.baidu.com">
上面这个标签的意思是说,3秒之后,自动跳转到百度页面。
title 标签:
用于设置网页标题:
<title>网页的标题</title>
title标签也是有助于SEO搜索引擎优化的。
base标签:
<base href="/">
base 标签用于指定基础的路径。指定之后,所有的 a 链接都是以这个路径为基准。
※主体标签body
<body>标签的属性有:(有印象即可,以后主要用css操控样式)
-
-
bgcolor:设置整个网页的背景颜色。background:设置整个网页的背景图片。text:设置网页中的文本颜色。leftmargin:网页的左边距。IE浏览器默认是8个像素。topmargin:网页的上边距。rightmargin:网页的右边距。bottommargin:网页的下边距。
-
※计算机编码(这个必须要了解)
这是千古一号博主的总结:
计算机,不能直接存储文字,存储的是编码。
计算机只能处理二进制的数据,其它数据,比如:0-9、a-z、A-Z,这些字符,我们可以定义一套规则来表示。假如:A用110表示,B用111表示等。
ASCII码: 美国发布的,用1个字节(8位二进制)来表示一个字符,共可以表示2^8=256个字符。 美国的国家语言是英语,只要能表示0-9、a-z、A-Z、特殊符号。(也叫阿斯克码)
附上一份表自拿:http://ascii.911cha.com/
ANSI编码: 每个国家为了显示本国的语言,都对ASCII码进行了扩展。用2个字节(16位二进制)来表示一个汉字,共可以表示2^16=65536个汉字。例如: 中国的ANSI编码是GB2312编码(简体),对6763汉字进行编码,含600多特殊字符。另外还有GBK(简体)。 日本的ANSI编码是JIS编码。 台湾的ANSI编码是BIG5编码(繁体)。
GBK: 对GB2312进行了扩展,用来显示罕见的、古汉语的汉字。现在已经收录了2.1万左右。并提供了1890个汉字码位。K的含义就是“扩展”。
Unicode编码(统一编码): 用4个字节(32位二进制)来表示一个字符,想法不错,但效率太低。例如,字母A用ASCII表示的话一个字节就够,可用Unicode编码的话,得用4个字节表示,造成了空间的极大浪费。A的Unicode编码是0000 0000 0000 0000 0000 0000 0100 0000
UTF-8(Unicode Transform Format)编码: 根据字符的不同,选择其编码的长度。比如:一个字符A用1个字节表示,一个汉字用2个字节表示。
毫无疑问,开发中,都用UTF-8编码吧,准没错。
中文能够使用的字符集两种:
-
-
第一种:UTF-8。UTF-8是国际通用字库,里面涵盖了所有地球上所有人类的语言文字,比如阿拉伯文、汉语、鸟语……
-
第二种:GBK(对GB2312进行了扩展)。gb2312 是国标,是中国的字库,里面仅涵盖了汉字和一些常用外文,比如日文片假名,和常见的符号。
-
字库规模: UTF-8(字很全) > gb2312(只有汉字)
重点1:避免乱码
我们用meta标签声明的当前这个html文档的字库,一定要和保存的文件编码类型一样,否则乱码(重点)。
拿 sublime编辑器举例,当我们不设置的时候,sublime默认类型就是UTF-8。而一旦更改为gb2312的时候,就一定要记得设置一下sublime的保存类型: 文件→ set File Encoding to → Chinese Simplified(GBK)。VS Code 的道理一样。
重点2:UTF-8和gb2312的比较
保存大小:UTF-8(更臃肿、加载更慢) > gb2312 (更小巧,加载更快)
总结:
-
- UTF-8:字多,有各种国家的语言,但是保存尺寸大,文件臃肿;
- gb2312:字少,只用中文和少数外语和符号,但是尺寸小,文件小巧。
列出2个使用情形:
1) 你们公司是做日本动漫的,经常出现一些日语动漫的名字,网页要使用UTF-8。如果用gb2312将无法显示日语。 2) 你们公司就是中文网页,极度的追求网页的显示速度,要使用gb2312。如果使用UTF-8将每个汉字多一个byte,所以5000个汉字,多5kb。
我们亲测:
-
- qq网、网易、搜狐都是使用gb2312。这些公司,都追求显示速度。
- 新华网藏语频道,使用的是UTF-8,保证字符集的数量。
我们是怎么查看网页的编码方式的呢?在浏览器中打开网页,右键,选择“查看网页源代码”,找到meta标签中的charset属性即可。
那么,我们为什么可以查看网页的源代码呢?因为这个打开的html网页已经存到我的临时文件夹里了,临时文件夹里的html是纯文本文件,纯文本文件自然可以查看网页的源代码。
个人对以上内容的总结:
如果没有特殊要求: 使用 UTF-8 字符集,可以满足所有的开发要求
如果要求速度,和大小: 使用相对应的国家字符集,则可以更加有针对,轻量的开发
HTML的规范
HTML不区分大小写,但HTML的标签名、类名、标签属性、大部分属性值建议统一用小写。
HTML页面的后缀名是html或者htm
编写规范:
所有标记元素都要正确的嵌套,不能交叉嵌套。正确写法举例:<h1><font></font></h1>
所有的标签都必须闭合。 否则会出现意想不到的效果
双标签:<span></span>
单标签:<br> 建议写成 <br /> <hr> 建议转成 <hr />,还有<img src=“URL” />
(记忆方法:单标签比较少,建议都记住,剩下的都是双标签)
所有的属性值必须加引号。<font color="red"></font>
所有的属性必须有值。<hr noshade="noshade">、<input type="radio" checked="checked" /> (属性=“属性值”)
html 对换行和tab 不敏感
也就是说,HTML不是依靠缩进来表示嵌套的,而是看标签的嵌套关系。
但是,我们发现有良好的缩进,代码更易读。建议大家都正确缩进标签。
*HTML中所有的文字之间,如果有空格、换行、tab都将被折叠为一个空格显示。
(这个比较经常出现,有时候莫名其妙多出了空白,最好检查一下是不是因为这个原因)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号