
小菜鸟之数据库
数据库复习提纲之文字版(这个只是自己整理文案,答案是查的,勿喷,谢谢,希望给别人一些帮助)
1、Oracle和SQL server2005的区别
Oracle数据库:Oracle Database,又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。
它是在数据库领域一直处于领先地位的产品。可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的 适应高吞吐量的数据库解决方案。
sql server数据库:美国Microsoft公司推出的一种关系型数据库系统。SQL Server是一个可扩展的、高性能的、为分布式客户机/服务器计算所设计的数据库管理系统,实现了与WindowsNT的有机结合,提供了基于事务的企业级信息管理系统方案
两者的区别:
(1)操作的平台不同
- Oracle可在所有主流平台上运行,Oracle数据库采用开放的策略目标,它使得客户可以选择一种最适合他们特定需要的解决方案。客户可以利用很多种第三方应用程序、工具。而SQL Server却只能在Windows上运行了。
- 但SQL Sever在Window平台上的表现,和Windows操作系统的整体结合程度,使用方便性,和Microsoft开发平台的整合性都比Oracle强的很多。但Windows操作系统的稳定性及可靠性大家是有目共睹的,再说Microsoft公司的策略目标是将客户都锁定到Windows平台的环境当中,只有随着Windows性能的改善,SQL Server才能进一步提高。从操作平台这点上Oracle是完全优胜于SQL Server的了。
- 也就是说Oracle支持多种操作系统,sql server支持window系统
(2)文体结构不同
- oracle的文件体系结构为:
数据文件 .dbf(真实数据)
日志文件 .rdo
控制文件 .ctl
参数文件 .ora
sql server的文件体系结构为:
.mdf (数据字典)
.ndf (数据文件)
.ldf (日志文件)
(3)存储结构不同
-
oracle存储结构:
在oracle里有两个块参数pctfree(填充因子)和pctused(复用因子),可控制块确定块本身何时有,何时没有足够的空间接受新信息(对块的存储情况的分析机制)
这样可降低数据行连接与行迁移的可能性。块的大小可设置(oltp块和dss块)
在oracle中,将连续的块组成区,可动态分配区(区的分配可以是等额的也可以是自增长的)可减少空间分配次数
在oraclel里表可以分为多个段,段由多个区组成,每个段可指定分配在哪个表空间里(段的类型分为:数据段、索引段、回滚段、临时段、cash段。oracle里还可对表进行分区,可按照用户定义的业务规则、条件或规范,物理的分开磁盘上的数据。
这样大大降低了磁盘争用的可能性。
oracle有七个基本表空间:
·system表空间(存放数据字典和数据管理自身所需的信息)
·rbs回滚表空间
·temp临时表空间
·tools交互式表空间
·users用户默认表空间
·indx索引表空间
·dbsys福数据表空间
不同的数据分别放在不同的表空间(数据字典与真实数据分开存放),在oracle里基表(存储系统参数信息)是加密存储,任何人都无法访问。只能通过用户可视视图查看。
-
sql server 存储结构
以页为最小分配单位,每个页为8k(不可控制,缺乏对页的存储情况的分析机制),可将8个连续的页的组成一个‘扩展’,以进一步减少分配时所耗用的资源。(分配缺乏灵活性),在sql server里数据以表的方式存放,而表是存放在数据库里。
sql server有五个基本数据库: www.2cto.com
·master(数据字典)
·mode(存放样版)
·tempdb(临时数据库)
·msdb(存放调度信息和日志信息)
·pubs(示例数据库)
真实数据与数据字典存放在一起。对系统参数信息无安全机制。
(4)安全性
Oracle的安全认证获得最高认证级别的ISO标准认证,而SQL Server并没有获得什么安全认证。这方面证明了Oracle的安全性是高于SQL Server的。
(5)性能不同
SQL Server 多用户时性能不佳
Oracle 性能最高, 保持windowsNT下的TPC-D和TPC-C的世界记录。
(6)开放性
SQL Server 只能在windows 上运行,没有丝毫的开放性,操作系统的系统的稳定对数据库是十分重要的。Windows9X系列产品是偏重于桌面应用,NT server只适合中小型企业。而且windows平台的可靠性,安全性和伸缩性是非常有限的。它不象unix那样久经考验,尤其是在处理大数据量的关键业务时。
Oracle 能在所有主流平台上运行(包括 windows)。完全支持所有的工业标准。采用完全开放策略。可以使客户选择最适合的解决方案。对开发商全力支持
(7)客户端支持及应用模式
SQL Server C/S结构,只支持windows客户,可以用ADO,DAO,OLEDB ,ODBC连接.
Oracle 多层次网络计算,支持多种工业标准,可以用ODBC, JDBC,OCI等网络客户连接
意见:
SQL server 完全重写的代码,经历了长期的测试,不断延迟,许多功能需要时间来证明。并不十分兼容早期产品。使用需要冒一定风险。
Oracle 长时间的开发经验,完全向下兼容。得到广泛的应用。完全没有风险。
2. 如何使用Oracle的游标?
游标的概念:
游标是SQL的一个内存工作区,由系统或用户以变量的形式定义。游标的作用就是用于临时存储从数据库中提取的数据块。在某些情况下,需要把数据从存放在磁盘的表中调到计算机内存中进行处理,最后将处理结果显示出来或最终写回数据库。这样数据处理的速度才会提高,否则频繁的磁盘数据交换会降低效率。
游标有两种类型:显式游标和隐式游标。在前述程序中用到的SELECT...INTO...查询语句,一次只能从数据库中提取一行数据,对于这种形式的查询和DML操作,系统都会使用一个隐式游标。但是如果要提取多行数据,就要由程序员定义一个显式游标,并通过与游标有关的语句进行处理。显式游标对应一个返回结果为多行多列的SELECT语句。
游标一旦打开,数据就从数据库中传送到游标变量中,然后应用程序再从游标变量中分解出需要的数据,并进行处理。
隐式游标
如前所述,DML操作和单行SELECT语句会使用隐式游标,它们是:
* 插入操作:INSERT。
* 更新操作:UPDATE。
* 删除操作:DELETE。
* 单行查询操作:SELECT ... INTO ...。
当系统使用一个隐式游标时,可以通过隐式游标的属性来了解操作的状态和结果,进而控制程序的流程。隐式游标可以使用名字SQL来访问,但要注意,通过SQL游标名总是只能访问前一个DML操作或单行SELECT操作的游标属性。所以通常在刚刚执行完操作之后,立即使用SQL游标名来访问属性。游标的属性有四种,如下所示。
Sql代码
- 隐式游标的属性 返回值类型 意 义
- SQL%ROWCOUNT 整型 代表DML语句成功执行的数据行数
- SQL%FOUND 布尔型 值为TRUE代表插入、删除、更新或单行查询操作成功
- SQL%NOTFOUND 布尔型 与SQL%FOUND属性返回值相反
- SQL%ISOPEN 布尔型 DML执行过程中为真,结束后为假
【训练1】 使用隐式游标的属性,判断对雇员工资的修改是否成功。
步骤1:输入和运行以下程序:
Sql代码
- SET SERVEROUTPUT ON
- BEGIN
- UPDATE emp SET sal=sal+100 WHERE empno=1234;
- IF SQL%FOUND THEN
- DBMS_OUTPUT.PUT_LINE('成功修改雇员工资!');
- COMMIT;
- ELSE
- DBMS_OUTPUT.PUT_LINE('修改雇员工资失败!');
- END IF;
- END;
运行结果为:
Sql代码
- 修改雇员工资失败!
- PL/SQL 过程已成功完成。
步骤2:将雇员编号1234改为7788,重新执行以上程序:
运行结果为:
Sql代码
- 成功修改雇员工资!
- PL/SQL 过程已成功完成。
说明:本例中,通过SQL%FOUND属性判断修改是否成功,并给出相应信息。
显式游标
游标的定义和操作
游标的使用分成以下4个步骤。
1.声明游标
在DECLEAR部分按以下格式声明游标:
CURSOR 游标名[(参数1 数据类型[,参数2 数据类型...])]
IS SELECT语句;
参数是可选部分,所定义的参数可以出现在SELECT语句的WHERE子句中。如果定义了参数,则必须在打开游标时传递相应的实际参数。
SELECT语句是对表或视图的查询语句,甚至也可以是联合查询。可以带WHERE条件、ORDER BY或GROUP BY等子句,但不能使用INTO子句。在SELECT语句中可以使用在定义游标之前定义的变量。
2.打开游标
在可执行部分,按以下格式打开游标:
OPEN 游标名[(实际参数1[,实际参数2...])];
打开游标时,SELECT语句的查询结果就被传送到了游标工作区。
3.提取数据
在可执行部分,按以下格式将游标工作区中的数据取到变量中。提取操作必须在打开游标之后进行。
FETCH 游标名 INTO 变量名1[,变量名2...];
或
FETCH 游标名 INTO 记录变量;
游标打开后有一个指针指向数据区,FETCH语句一次返回指针所指的一行数据,要返回多行需重复执行,可以使用循环语句来实现。控制循环可以通过判断游标的属性来进行。
下面对这两种格式进行说明:
第一种格式中的变量名是用来从游标中接收数据的变量,需要事先定义。变量的个数和类型应与SELECT语句中的字段变量的个数和类型一致。
第二种格式一次将一行数据取到记录变量中,需要使用%ROWTYPE事先定义记录变量,这种形式使用起来比较方便,不必分别定义和使用多个变量。
定义记录变量的方法如下:
变量名 表名|游标名%ROWTYPE;
其中的表必须存在,游标名也必须先定义。
4.关闭游标
CLOSE 游标名;
显式游标打开后,必须显式地关闭。游标一旦关闭,游标占用的资源就被释放,游标变成无效,必须重新打开才能使用。
以下是使用显式游标的一个简单练习。
【训练1】 用游标提取emp表中7788雇员的名称和职务。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- v_ename VARCHAR2(10);
- v_job VARCHAR2(10);
- CURSOR emp_cursor IS
- SELECT ename,job FROM emp WHERE empno=7788;
- BEGIN
- OPEN emp_cursor;
- FETCH emp_cursor INTO v_ename,v_job;
- DBMS_OUTPUT.PUT_LINE(v_ename||','||v_job);
- CLOSE emp_cursor;
- END;
执行结果为:
Sql代码
- SCOTT,ANALYST
- PL/SQL 过程已成功完成。
说明:该程序通过定义游标emp_cursor,提取并显示雇员7788的名称和职务。
作为对以上例子的改进,在以下训练中采用了记录变量。
【训练2】 用游标提取emp表中7788雇员的姓名、职务和工资。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- CURSOR emp_cursor IS SELECT ename,job,sal FROM emp WHERE empno=7788;
- emp_record emp_cursor%ROWTYPE;
- BEGIN
- OPEN emp_cursor;
- FETCH emp_cursor INTO emp_record;
- DBMS_OUTPUT.PUT_LINE(emp_record.ename||','|| emp_record.job||','|| emp_record.sal);
- CLOSE emp_cursor;
- END;
执行结果为:
Sql代码
- SCOTT,ANALYST,3000
- PL/SQL 过程已成功完成。
说明:实例中使用记录变量来接收数据,记录变量由游标变量定义,需要出现在游标定义之后。
注意:可通过以下形式获得记录变量的内容:
记录变量名.字段名。
【训练3】 显示工资最高的前3名雇员的名称和工资。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- V_ename VARCHAR2(10);
- V_sal NUMBER(5);
- CURSOR emp_cursor IS SELECT ename,sal FROM emp ORDER BY sal DESC;
- BEGIN
- OPEN emp_cursor;
- FOR I IN 1..3 LOOP
- FETCH emp_cursor INTO v_ename,v_sal;
- DBMS_OUTPUT.PUT_LINE(v_ename||','||v_sal);
- END LOOP;
- CLOSE emp_cursor;
- END;
执行结果为:
Sql代码
- KING,5000
- SCOTT,3000
- FORD,3000
- PL/SQL 过程已成功完成。
说明:该程序在游标定义中使用了ORDER BY子句进行排序,并使用循环语句来提取多行数据。
游标循环
【训练1】 使用特殊的FOR循环形式显示全部雇员的编号和名称。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- CURSOR emp_cursor IS
- SELECT empno, ename FROM emp;
- BEGIN
- FOR Emp_record IN emp_cursor LOOP
- DBMS_OUTPUT.PUT_LINE(Emp_record.empno|| Emp_record.ename);
- END LOOP;
- END;
执行结果为:
Sql代码
- 7369SMITH
- 7499ALLEN
- 7521WARD
- 7566JONES
- PL/SQL 过程已成功完成。
说明:可以看到该循环形式非常简单,隐含了记录变量的定义、游标的打开、提取和关闭过程。Emp_record为隐含定义的记录变量,循环的执行次数与游标取得的数据的行数相一致。
【训练2】 另一种形式的游标循环。
Sql代码
- SET SERVEROUTPUT ON
- BEGIN
- FOR re IN (SELECT ename FROM EMP) LOOP
- DBMS_OUTPUT.PUT_LINE(re.ename)
- END LOOP;
- END;
执行结果为:
Sql代码
- SMITH
- ALLEN
- WARD
- JONES
说明:该种形式更为简单,省略了游标的定义,游标的SELECT查询语句在循环中直接出现。
显式游标属性
虽然可以使用前面的形式获得游标数据,但是在游标定义以后使用它的一些属性来进行结构控制是一种更为灵活的方法。显式游标的属性如下所示。
Sql代码
- 游标的属性 返回值类型 意 义
- %ROWCOUNT 整型 获得FETCH语句返回的数据行数
- %FOUND 布尔型 最近的FETCH语句返回一行数据则为真,否则为假
- %NOTFOUND 布尔型 与%FOUND属性返回值相反
- %ISOPEN 布尔型 游标已经打开时值为真,否则为假
可按照以下形式取得游标的属性:
游标名%属性
要判断游标emp_cursor是否处于打开状态,可以使用属性emp_cursor%ISOPEN。如果游标已经打开,则返回值为“真”,否则为“假”。具体可参照以下的训练。
【训练1】 使用游标的属性练习。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- V_ename VARCHAR2(10);
- CURSOR emp_cursor IS
- SELECT ename FROM emp;
- BEGIN
- OPEN emp_cursor;
- IF emp_cursor%ISOPEN THEN
- LOOP
- FETCH emp_cursor INTO v_ename;
- EXIT WHEN emp_cursor%NOTFOUND;
- DBMS_OUTPUT.PUT_LINE(to_char(emp_cursor%ROWCOUNT)||'-'||v_ename);
- END LOOP;
- ELSE
- DBMS_OUTPUT.PUT_LINE('用户信息:游标没有打开!');
- END IF;
- CLOSE emp_cursor;
- END;
执行结果为:
Sql代码
- 1-SMITH
- 2-ALLEN
- 3-WARD
- PL/SQL 过程已成功完成。
说明:本例使用emp_cursor%ISOPEN判断游标是否打开;使用emp_cursor%ROWCOUNT获得到目前为止FETCH语句返回的数据行数并输出;使用循环来获取数据,在循环体中使用FETCH语句;使用emp_cursor%NOTFOUND判断FETCH语句是否成功执行,当FETCH语句失败时说明数据已经取完,退出循环。
【练习1】去掉OPEN emp_cursor;语句,重新执行以上程序。
游标参数的传递
【训练1】 带参数的游标。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- V_empno NUMBER(5);
- V_ename VARCHAR2(10);
- CURSOR emp_cursor(p_deptno NUMBER, p_job VARCHAR2) IS
- SELECT empno, ename FROM emp
- WHERE deptno = p_deptno AND job = p_job;
- BEGIN
- OPEN emp_cursor(10, 'CLERK');
- LOOP
- FETCH emp_cursor INTO v_empno,v_ename;
- EXIT WHEN emp_cursor%NOTFOUND;
- DBMS_OUTPUT.PUT_LINE(v_empno||','||v_ename);
- END LOOP;
- END;
执行结果为:
Sql代码
- 7934,MILLER
- PL/SQL 过程已成功完成。
说明:游标emp_cursor定义了两个参数:p_deptno代表部门编号,p_job代表职务。语句OPEN emp_cursor(10, 'CLERK')传递了两个参数值给游标,即部门为10、职务为CLERK,所以游标查询的内容是部门10的职务为CLERK的雇员。循环部分用于显示查询的内容。
【练习1】修改Open语句的参数:部门号为20、职务为ANALYST,并重新执行。
也可以通过变量向游标传递参数,但变量需要先于游标定义,并在游标打开之前赋值。对以上例子重新改动如下:
【训练2】 通过变量传递参数给游标。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- v_empno NUMBER(5);
- v_ename VARCHAR2(10);
- v_deptno NUMBER(5);
- v_job VARCHAR2(10);
- CURSOR emp_cursor IS
- SELECT empno, ename FROM emp
- WHERE deptno = v_deptno AND job = v_job;
- BEGIN
- v_deptno:=10;
- v_job:='CLERK';
- OPEN emp_cursor;
- LOOP
- FETCH emp_cursor INTO v_empno,v_ename;
- EXIT WHEN emp_cursor%NOTFOUND;
- DBMS_OUTPUT.PUT_LINE(v_empno||','||v_ename);
- END LOOP;
- END;
执行结果为:
Sql代码
- 7934,MILLER
- PL/SQL 过程已成功完成。
说明:该程序与前一程序实现相同的功能。
动态SELECT语句和动态游标的用法
Oracle支持动态SELECT语句和动态游标,动态的方法大大扩展了程序设计的能力。
对于查询结果为一行的SELECT语句,可以用动态生成查询语句字符串的方法,在程序执行阶段临时地生成并执行,语法是:
execute immediate 查询语句字符串 into 变量1[,变量2...];
以下是一个动态生成SELECT语句的例子。
【训练1】 动态SELECT查询。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- str varchar2(100);
- v_ename varchar2(10);
- begin
- str:='select ename from scott.emp where empno=7788';
- execute immediate str into v_ename;
- dbms_output.put_line(v_ename);
- END;
执行结果为:
Sql代码
- SCOTT
- PL/SQL 过程已成功完成。
说明:SELECT...INTO...语句存放在STR字符串中,通过EXECUTE语句执行。
在变量声明部分定义的游标是静态的,不能在程序运行过程中修改。虽然可以通过参数传递来取得不同的数据,但还是有很大的局限性。通过采用动态游标,可以在程序运行阶段随时生成一个查询语句作为游标。要使用动态游标需要先定义一个游标类型,然后声明一个游标变量,游标对应的查询语句可以在程序的执行过程中动态地说明。
定义游标类型的语句如下:
TYPE 游标类型名 REF CURSOR;
声明游标变量的语句如下:
游标变量名 游标类型名;
在可执行部分可以如下形式打开一个动态游标:
OPEN 游标变量名 FOR 查询语句字符串;
【训练2】 按名字中包含的字母顺序分组显示雇员信息。
输入并运行以下程序:
Sql代码
- declare
- type cur_type is ref cursor;
- cur cur_type;
- rec scott.emp%rowtype;
- str varchar2(50);
- letter char:= 'A';
- begin
- loop
- str:= 'select ename from emp where ename like ''%'||letter||'%''';
- open cur for str;
- dbms_output.put_line('包含字母'||letter||'的名字:');
- loop
- fetch cur into rec.ename;
- exit when cur%notfound;
- dbms_output.put_line(rec.ename);
- end loop;
- exit when letter='Z';
- letter:=chr(ascii(letter)+1);
- end loop;
- end;
运行结果为:
Sql代码
- 包含字母A的名字:
- ALLEN
- WARD
- MARTIN
- BLAKE
- CLARK
- ADAMS
- JAMES
- 包含字母B的名字:
- BLAKE
- 包含字母C的名字:
- CLARK
- SCOTT
说明:使用了二重循环,在外循环体中,动态生成游标的SELECT语句,然后打开。通过语句letter:=chr(ascii(letter)+1)可获得字母表中的下一个字母。
异常处理
错误处理
错误处理部分位于程序的可执行部分之后,是由WHEN语句引导的多个分支构成的。错误处理的语法如下:
EXCEPTION
WHEN 错误1[OR 错误2] THEN
语句序列1;
WHEN 错误3[OR 错误4] THEN
语句序列2;
WHEN OTHERS
语句序列n;
END;
其中:
错误是在标准包中由系统预定义的标准错误,或是由用户在程序的说明部分自定义的错误,参见下一节系统预定义的错误类型。
语句序列就是不同分支的错误处理部分。
凡是出现在WHEN后面的错误都是可以捕捉到的错误,其他未被捕捉到的错误,将在WHEN OTHERS部分进行统一处理,OTHENS必须是EXCEPTION部分的最后一个错误处理分支。如要在该分支中进一步判断错误种类,可以通过使用预定义函数SQLCODE( )和SQLERRM( )来获得系统错误号和错误信息。
如果在程序的子块中发生了错误,但子块没有错误处理部分,则错误会传递到主程序中。
下面是由于查询编号错误而引起系统预定义异常的例子。
【训练1】 查询编号为1234的雇员名字。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- v_name VARCHAR2(10);
- BEGIN
- SELECT ename
- INTO v_name
- FROM emp
- WHERE empno = 1234;
- DBMS_OUTPUT.PUT_LINE('该雇员名字为:'|| v_name);
- EXCEPTION
- WHEN NO_DATA_FOUND THEN
- DBMS_OUTPUT.PUT_LINE('编号错误,没有找到相应雇员!');
- WHEN OTHERS THEN
- DBMS_OUTPUT.PUT_LINE('发生其他错误!');
- END;
执行结果为:
Sql代码
- 编号错误,没有找到相应雇员!
- PL/SQL 过程已成功完成。
说明:在以上查询中,因为编号为1234的雇员不存在,所以将发生类型为“NO_DATA_
FOUND”的异常。“NO_DATA_FOUND”是系统预定义的错误类型,EXCEPTION部分下的WHEN语句将捕捉到该异常,并执行相应代码部分。在本例中,输出用户自定义的错误信息“编号错误,没有找到相应雇员!”。如果发生其他类型的错误,将执行OTHERS条件下的代码部分,显示“发生其他错误!”。
【训练2】 由程序代码显示系统错误。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- v_temp NUMBER(5):=1;
- BEGIN
- v_temp:=v_temp/0;
- EXCEPTION
- WHEN OTHERS THEN
- DBMS_OUTPUT.PUT_LINE('发生系统错误!');
- DBMS_OUTPUT.PUT_LINE('错误代码:'|| SQLCODE( ));
- DBMS_OUTPUT.PUT_LINE('错误信息:' ||SQLERRM( ));
- END;
执行结果为:
Sql代码
- 发生系统错误!
- 错误代码:?1476
- 错误信息:ORA-01476: 除数为 0
- PL/SQL 过程已成功完成。
说明:程序运行中发生除零错误,由WHEN OTHERS捕捉到,执行用户自己的输出语句显示错误信息,然后正常结束。在错误处理部分使用了预定义函数SQLCODE( )和SQLERRM( )来进一步获得错误的代码和种类信息。
预定义错误
Oracle的系统错误很多,但只有一部分常见错误在标准包中予以定义。定义的错误可以在EXCEPTION部分通过标准的错误名来进行判断,并进行异常处理。常见的系统预定义异常如下所示。
Sql代码
- 错 误 名 称 错误代码 错 误 含 义
- CURSOR_ALREADY_OPEN ORA_06511 试图打开已经打开的游标
- INVALID_CURSOR ORA_01001 试图使用没有打开的游标
- DUP_VAL_ON_INDEX ORA_00001 保存重复值到惟一索引约束的列中
- ZERO_DIVIDE ORA_01476 发生除数为零的除法错误
- INVALID_NUMBER ORA_01722 试图对无效字符进行数值转换
- ROWTYPE_MISMATCH ORA_06504 主变量和游标的类型不兼容
- VALUE_ERROR ORA_06502 转换、截断或算术运算发生错误
- TOO_MANY_ROWS ORA_01422 SELECT…INTO…语句返回多于一行的数据
- NO_DATA_FOUND ORA_01403 SELECT…INTO…语句没有数据返回
- TIMEOUT_ON_RESOURCE ORA_00051 等待资源时发生超时错误
- TRANSACTION_BACKED_OUT ORA_00060 由于死锁,提交失败
- STORAGE_ERROR ORA_06500 发生内存错误
- PROGRAM_ERROR ORA_06501 发生PL/SQL内部错误
- NOT_LOGGED_ON ORA_01012 试图操作未连接的数据库
- LOGIN_DENIED ORA_01017 在连接时提供了无效用户名或口令
比如,如果程序向表的主键列插入重复值,则将发生DUP_VAL_ON_INDEX错误。
如果一个系统错误没有在标准包中定义,则需要在说明部分定义,语法如下:
错误名 EXCEPTION;
定义后使用PRAGMA EXCEPTION_INIT来将一个定义的错误同一个特别的Oracle错误代码相关联,就可以同系统预定义的错误一样使用了。语法如下:
PRAGMA EXCEPTION_INIT(错误名,- 错误代码);
【训练1】 定义新的系统错误类型。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- V_ENAME VARCHAR2(10);
- NULL_INSERT_ERROR EXCEPTION;
- PRAGMA EXCEPTION_INIT(NULL_INSERT_ERROR,-1400);
- BEGIN
- INSERT INTO EMP(EMPNO) VALUES(NULL);
- EXCEPTION
- WHEN NULL_INSERT_ERROR THEN
- DBMS_OUTPUT.PUT_LINE('无法插入NULL值!');
- WHEN OTHERS THEN
- DBMS_OUTPUT.PUT_LINE('发生其他系统错误!');
- END;
执行结果为:
Sql代码
- 无法插入NULL值!
- PL/SQL 过程已成功完成。
说明:NULL_INSERT_ERROR是自定义异常,同系统错误1400相关联。
自定义异常
程序设计者可以利用引发异常的机制来进行程序设计,自己定义异常类型。可以在声明部分定义新的异常类型,定义的语法是:
错误名 EXCEPTION;
用户定义的错误不能由系统来触发,必须由程序显式地触发,触发的语法是:
RAISE 错误名;
RAISE也可以用来引发模拟系统错误,比如,RAISE ZERO_DIVIDE将引发模拟的除零错误。
使用RAISE_APPLICATION_ERROR函数也可以引发异常。该函数要传递两个参数,第一个是用户自定义的错误编号,第二个参数是用户自定义的错误信息。使用该函数引发的异常的编号应该在20 000和20 999之间选择。
自定义异常处理错误的方式同前。
【训练1】 插入新雇员,限定插入雇员的编号在7000~8000之间。
Java代码
- SET SERVEROUTPUT ON
- DECLARE
- new_no NUMBER(10);
- new_excp1 EXCEPTION;
- new_excp2 EXCEPTION;
- BEGIN
- new_no:=6789;
- INSERT INTO emp(empno,ename)
- VALUES(new_no, '小郑');
- IF new_no<7000 THEN
- RAISE new_excp1;
- END IF;
- IF new_no>8000 THEN
- RAISE new_excp2;
- END IF;
- COMMIT;
- EXCEPTION
- WHEN new_excp1 THEN
- ROLLBACK;
- DBMS_OUTPUT.PUT_LINE('雇员编号小于7000的下限!');
- WHEN new_excp2 THEN
- ROLLBACK;
- DBMS_OUTPUT.PUT_LINE('雇员编号超过8000的上限!');
- END;
执行结果为:
雇员编号小于7000的下限!
PL/SQL 过程已成功完成。
说明:在此例中,自定义了两个异常:new_excp1和new_excp2,分别代表编号小于7000和编号大于8000的错误。在程序中通过判断编号大小,产生对应的异常,并在异常处理部分回退插入操作,然后显示相应的错误信息。
【训练2】 使用RAISE_APPLICATION_ERROR函数引发系统异常。
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- New_no NUMBER(10);
- BEGIN
- New_no:=6789;
- INSERT INTO emp(empno,ename)
- VALUES(new_no, 'JAMES');
- IF new_no<7000 THEN
- ROLLBACK;
- RAISE_APPLICATION_ERROR(-20001, '编号小于7000的下限!');
- END IF;
- IF new_no>8000 THEN
- ROLLBACK;
- RAISE_APPLICATION_ERROR (-20002, '编号大于8000的下限!');
- END IF;
- END;
执行结果为:
Sql代码
- DECLARE
- *
- ERROR 位于第 1 行:
- ORA-20001: 编号小于7000的下限!
- ORA-06512: 在line 9
说明:在本训练中,使用RAISE_APPLICATION_ERROR引发自定义异常,并以系统错误的方式进行显示。错误编号为20001和20002。
注意:同上一个训练比较,此种方法不需要事先定义异常,可直接引发。
可以参考下面的程序片断将出错信息记录到表中,其中,errors为记录错误信息的表,SQLCODE为发生异常的错误编号,SQLERRM为发生异常的错误信息。
DECLARE
v_error_code NUMBER;
v_error_message VARCHAR2(255);
BEGIN
...
EXCEPTION
...
WHEN OTHERS THEN
v_error_code := SQLCODE ;
v_error_message := SQLERRM ;
INSERT INTO errors
VALUES(v_error_code, v_error_message);
END;
【练习1】修改雇员的工资,通过引发异常控制修改范围在600~6000之间。
阶段训练
【训练1】 将雇员从一个表复制到另一个表。
步骤1:创建一个结构同EMP表一样的新表EMP1:
CREATE TABLE emp1 AS SELECT * FROM SCOTT.EMP WHERE 1=2;
步骤2:通过指定雇员编号,将雇员由EMP表移动到EMP1表:
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- v_empno NUMBER(5):=7788;
- emp_rec emp%ROWTYPE;
- BEGIN
- SELECT * INTO emp_rec FROM emp WHERE empno=v_empno;
- DELETE FROM emp WHERE empno=v_empno;
- INSERT INTO emp1 VALUES emp_rec;
- IF SQL%FOUND THEN
- COMMIT;
- DBMS_OUTPUT.PUT_LINE('雇员复制成功!');
- ELSE
- ROLLBACK;
- DBMS_OUTPUT.PUT_LINE('雇员复制失败!');
- END IF;
- END;
执行结果为:
雇员复制成功!
PL/SQL 过程已成功完成。
步骤2:显示复制结果:
SELECT empno,ename,job FROM emp1;
执行结果为:
Sql代码
- EMPNO ENAME JOB
- ------------- -------------- ----------------
- 7788 SCOTT ANALYST
说明:emp_rec变量是根据emp表定义的记录变量,SELECT...INTO...语句将整个记录传给该变量。INSERT语句将整个记录变量插入emp1表,如果插入成功(SQL%FOUND为真),则提交事务,否则回滚撤销事务。试修改雇员编号为7902,重新执行以上程序。
【训练2】 输出雇员工资,雇员工资用不同高度的*表示。
输入并执行以下程序:
Sql代码
- SET SERVEROUTPUT ON
- BEGIN
- FOR re IN (SELECT ename,sal FROM EMP) LOOP
- DBMS_OUTPUT.PUT_LINE(rpad(re.ename,12,' ')||rpad('*',re.sal/100,'*'));
- END LOOP;
- END;
输出结果为:
Sql代码
- SMITH ********
- ALLEN ****************
- WARD *************
- JONES ******************************
- MARTIN *************
- BLAKE *****************************
- CLARK *****************************
- SCOTT ******************************
- KING **************************************************
- TURNER ***************
- ADAMS ***********
- JAMES **********
- FORD ******************************
- MILLER *************
- 执行结果为:
- PL/SQL 过程已成功完成。
说明:第一个rpad函数产生对齐效果,第二个rpad函数根据工资额产生不同数目的*。该程序采用了隐式的简略游标循环形式。
【训练3】 编写程序,格式化输出部门信息。
输入并执行如下程序:
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- v_count number:=0;
- CURSOR dept_cursor IS SELECT * FROM dept;
- BEGIN
- DBMS_OUTPUT.PUT_LINE('部门列表');
- DBMS_OUTPUT.PUT_LINE('---------------------------------');
- FOR Dept_record IN dept_cursor LOOP
- DBMS_OUTPUT.PUT_LINE('部门编号:'|| Dept_record.deptno);
- DBMS_OUTPUT.PUT_LINE('部门名称:'|| Dept_record.dname);
- DBMS_OUTPUT.PUT_LINE('所在城市:'|| Dept_record.loc);
- DBMS_OUTPUT.PUT_LINE('---------------------------------');
- v_count:= v_count+1;
- END LOOP;
- DBMS_OUTPUT.PUT_LINE('共有'||to_char(v_count)||'个部门!');
- END;
输出结果为:
Sql代码
- 部门列表
- ------------------------------------
- 部门编号:10
- 部门名称:ACCOUNTING
- 所在城市:NEW YORK
- ------------------------------------
- 部门编号:20
- 部门名称:RESEARCH
- 所在城市:DALLAS
- ...
- 共有4个部门!
- PL/SQL 过程已成功完成。
说明:该程序中将字段内容垂直排列。V_count变量记录循环次数,即部门个数。
【训练4】 已知每个部门有一个经理,编写程序,统计输出部门名称、部门总人数、总工资和部门经理。
输入并执行如下程序:
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- v_deptno number(8);
- v_count number(3);
- v_sumsal number(6);
- v_dname varchar2(15);
- v_manager varchar2(15);
- CURSOR list_cursor IS
- SELECT deptno,count(*),sum(sal) FROM emp group by deptno;
- BEGIN
- OPEN list_cursor;
- DBMS_OUTPUT.PUT_LINE('----------- 部 门 统 计 表 -----------');
- DBMS_OUTPUT.PUT_LINE('部门名称 总人数 总工资 部门经理');
- FETCH list_cursor INTO v_deptno,v_count,v_sumsal;
- WHILE list_cursor%found LOOP
- SELECT dname INTO v_dname FROM dept
- WHERE deptno=v_deptno;
- SELECT ename INTO v_manager FROM emp
- WHERE deptno=v_deptno and job='MANAGER';
- DBMS_OUTPUT.PUT_LINE(rpad(v_dname,13)||rpad(to_char(v_count),8)
- ||rpad(to_char(v_sumsal),9)||v_manager);
- FETCH list_cursor INTO v_deptno,v_count,v_sumsal;
- END LOOP;
- DBMS_OUTPUT.PUT_LINE('--------------------------------------');
- CLOSE list_cursor;
- END;
输出结果为:
Sql代码
- -------------------- 部 门 统 计 表 -----------------
- 部门名称 总人数 总工资 部门经理
- ACCOUNTING 3 8750 CLARK
- RESEARCH 5 10875 JONES
- SALES 6 9400 BLAKE
- -------------------------------------------------------------
- PL/SQL 过程已成功完成。
说明:游标中使用到了起分组功能的SELECT语句,统计出各部门的总人数和总工资。再根据部门编号和职务找到部门的经理。该程序假定每个部门有一个经理。
【训练5】 为雇员增加工资,从工资低的雇员开始,为每个人增加原工资的10%,限定所增加的工资总额为800元,显示增加工资的人数和余额。
输入并调试以下程序:
Sql代码
- SET SERVEROUTPUT ON
- DECLARE
- V_NAME CHAR(10);
- V_EMPNO NUMBER(5);
- V_SAL NUMBER(8);
- V_SAL1 NUMBER(8);
- V_TOTAL NUMBER(8) := 800; --增加工资的总额
- V_NUM NUMBER(5):=0; --增加工资的人数
- CURSOR emp_cursor IS
- SELECT EMPNO,ENAME,SAL FROM EMP ORDER BY SAL ASC;
- BEGIN
- OPEN emp_cursor;
- DBMS_OUTPUT.PUT_LINE('姓名 原工资 新工资');
- DBMS_OUTPUT.PUT_LINE('---------------------------');
- LOOP
- FETCH emp_cursor INTO V_EMPNO,V_NAME,V_SAL;
- EXIT WHEN emp_cursor%NOTFOUND;
- V_SAL1:= V_SAL*0.1;
- IF V_TOTAL>V_SAL1 THEN
- V_TOTAL := V_TOTAL - V_SAL1;
- V_NUM:=V_NUM+1;
- DBMS_OUTPUT.PUT_LINE(V_NAME||TO_CHAR(V_SAL,'99999')||
- TO_CHAR(V_SAL+V_SAL1,'99999'));
- UPDATE EMP SET SAL=SAL+V_SAL1
- WHERE EMPNO=V_EMPNO;
- ELSE
- DBMS_OUTPUT.PUT_LINE(V_NAME||TO_CHAR(V_SAL,'99999')||TO_CHAR(V_SAL,'99999'));
- END IF;
- END LOOP;
- DBMS_OUTPUT.PUT_LINE('---------------------------');
- DBMS_OUTPUT.PUT_LINE('增加工资人数:'||V_NUM||' 剩余工资:'||V_TOTAL);
- CLOSE emp_cursor;
- COMMIT;
- END;
输出结果为:
Sql代码
- 姓名 原工资 新工资
- ---------------------------------------------
- SMITH 1289 1418
- JAMES 1531 1684
- MARTIN 1664 1830
- MILLER 1730 1903
- ALLEN 1760 1936
- ADAMS 1771 1771
- TURNER 1815 1815
- WARD 1830 1830
- BLAKE 2850 2850
- CLARK 2850 2850
- JONES 2975 2975
- FORD 3000 3000
- KING 5000 5000
- -----------------------------------------------
- 增加工资人数:5 剩余工资:3
- PL/SQL 过程已成功完成。
3. Oracle中function和procedure的区别?
Oracle 存储过程(procedure)和函数(Function)的区别
1、返回值的区别
函数有1个返回值,而存储过程是通过参数返回的,可以有多个或者没有
2. 调用的区别,函数可以在查询语句中直接调用,而存储过程必须单独调用.
函数:一般情况下是用来计算并返回一个计算结果;
存储过程: 一般是用来完成特定的数据操作(比如修改、插入数据库表或执行某些DDL语句等等)
下图说明它们之间的区别:
和函数(Function)的区别")
4. Oracle的导入导出有几种方式,有何区别?
1.dmp文件方式
描述:dmp文件是二进制的,可以跨平台,并且包含权限,支持大字段数据,是用的最广泛的一种。
导出语法:exp 用户名/密码@监听器路径/数据库实例名称 file=e:数据库文件.dmp full=y ignore=y ;其中full = y ,表示整个数据库操作; ignore=y,忽略错误,继续操作;
重点内容
导出举例:exp jojo/jojo@localhost/my_database file=e:my_database.dmp full=y ignore=y
导入语法:imp 用户名/密码@监听器路径/数据库实例名称 file=e:数据库文件.dmp full=y ignore=y ;
导入举例:imp jojo/jojo@localhost/my_database file=e:my_database.dmp full=y ignore=y
2.sql文件方式
SQL文件可用文本编辑器查看,有利于可读性,但效率不如dmp文件,适合小数据量导入导出。尤其注意的是表中不能有大字段(blob,clob,long),如果有,会提示不能导出(提示如下: table contains one or more LONG columns cannot export in sql format,user Pl/sql developer format instead)
3.pde文件
第三种是导出为pde格式,pde格式是PL/SQL 自带的文件格式,且且适用于PL/SQL工具,编辑器无法查看,一般不常用。
---------------------
版权声明:本文为CSDN博主「导哥」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jingtianyiyi/article/details/80432626
5. Oracle中有哪几种文件?
Oracle单实例下一共有8种主要的文件类型,分别是
参数文件:这些文件告诉oracle在哪里可以找到控制文件,并定义一些参数
跟踪文件:这通常是一个服务器进程对某种异常错误做出响应时产生的诊断文件
警告文件:与跟踪文件类似,但是包含”期望“事件的有关信息,并通过一个集中式文件警告DBA
数据文件:存放数据表,索引以及其他段的文件
临时文件:这些文件用于完成基于磁盘的排序和临时存储
控制文件:这些文件能告诉你数据文件,临时文件以及重做日志文件在哪里,还会指出与文件状态有关的其他元数据
重做日志文件:这些就是事物日志
密码文件:这些文件用于通过网络完成管理活动的用户进行认证。
从oracle10g开始又增加了2种可选的文件
修改跟踪文件:这个文件有利于对oracle数据建立真正的增量备份。它不一定要放在闪回区,但是它只与数据库的备份与恢复有关
闪回日志文件:这些文件存储数据块的“前映像”,以便完成新增加的FLASHBACK DATABASE命令
与数据库有关的其他类型文件
转储文件:这些文件有exp导出并由imp导入
数据泵文件:这些文件有expdp导出并由inpdp导入
---------------------
版权声明:本文为CSDN博主「loveofmylife」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/viszl/article/details/7765133
6. Oracle中字符串用什么符号链接?
1.和其他数据库系统类似,Oracle字符串连接使用“||”进行字符串拼接,其使用方式和MSSQLServer中的加号“+”一样。
例如:
SELECT '工号为'||FNumber||'的员工姓名为'||FName FROM T_Employee WHERE FName IS NOT NULL
2.除了“||”,Oracle还支持使用CONCAT()函数进行字符串拼接,比如执行下面的SQL语句:
SELECT CONCAT('工号:',FNumber) FROM T_Employee
如果CONCAT中连接的值不是字符串,Oracle会尝试将其转换为字符串,比如执行下面的SQL语句:
SELECT CONCAT('年龄:',FAge) FROM T_Employee
与MYSQL的CONCAT()函数不同,Oracle的CONCAT()函数只支持两个参数,不支持两个以上字符串的拼接,比如下面的SQL语句在Oracle中是错误的:
SELECT CONCAT('工号为',FNumber,'的员工姓名为',FName) FROM T_Employee WHERE FName IS NOT NULL
运行以后Oracle会报出下面的错误信息:
参数个数无效
3.如果要进行多个字符串的拼接的话,可以使用多个CONCAT()函数嵌套使用,上面的SQL可以如下改写:
SELECT CONCAT(CONCAT(CONCAT('工号为',FNumber),'的员工姓名为'),FName) FROM T_Employee WHERE FName IS NOT NULL
转:http://www.jb51.net/article/36428.htm
7. Oracle是怎样分页的?
在Oracle中实现分页的方法大致分为两种,用ROWNUM关键字和用ROWID关键字,下面来详细介绍一下:
1、ROWNUM
其代码为:
SELECT *
FROM (SELECT ROW_.*, ROWNUM ROWNUM_
FROM (SELECT *
FROM TABLE1
WHERE TABLE1_ID = XX
ORDER BY GMT_CREATE DESC) ROW_
WHERE ROWNUM <= 20)
WHERE ROWNUM_ >= 10;
12345678
这应该是我们大部分程序里所用到的版本,因为这个版本很容易实现复用,中间ROW_部分,就是我们平常写到的sql语句,然后再将起始条数和终止条数作为专门的分页sql语句传入即可查询出我们想要的结果。
从效率上看,上面的SQL语句在大多数情况拥有较高的效率,主要体现在WHERE ROWNUM <= 20这句上,这样就控制了查询过程中的最大记录数,而在查询的最外层控制最小值。但最大值意味着如果查到了很大的范围(如百万级别的数据),查询就会从很大范围内往里减少,效率就会很低,因此,当面对大数据量时或者优化查询效率时,如果你用了ROWNUM,可以换第二种方法。
1
由以上的方法,又可以引申出3种方式:
A、结合BETWEEN AND
代码如下:
SELECT *
FROM (SELECT A.*, ROWNUM RN
FROM (SELECT *
FROM TABLE1
WHERE TABLE1_ID = XX
ORDER BY GMT_CREATE DESC) A)
WHERE RN BETWEEN 10 AND 20;
1234567
这个就是换汤不换药了,而且查询效率更低,因为:
Oracle可以将外层的查询条件推到内层查询中,以提高内层查询的执行效率,但不能跨越多层。
1
由于查询条件BETWEEN 10 AND 20是存在于查询的第三层,而Oracle无法将第三层的查询条件推到最内层(即使推到最内层也没有意义,因为最内层查询不知道RN代表什么)。因此,这个查询语句,Oracle最内层返回给中间层的是所有满足条件的数据,而中间层返回给最外层的也是所有数据。数据的过滤在最外层完成,显然这个效率要比原始的查询低得多。
B、结合MINUS
SELECT *
FROM TABLE1
WHERE ROWNUM <= 20
MINUS
SELECT * FROM TABLE1 WHERE ROWNUM <= 10;
12345
查询了两次,效率上更差了一些。
C、ROW_NUMBER() OVER( ORDER BY ORDER_DATE DESC)
这个和ROWNUM关键字类似,生成的顺序和rownum的语句一样,效率也一样(对于同样有ORDER BY 的ROWNUM语句来说),所以在这种情况下两种用法是一样的。
而对于分组后查询做分页的话,则是ROWNUM无法实现的,这时只有ROW_NUMBER可以实现,ROW_NUMBER() OVER(PARTITION BY 分组字段 ORDER BY 排序字段)就能实现分组后编号,其代码为:
SELECT *
FROM (SELECT a.*,
ROW_NUMBER() OVER(PARTITION BY TRUNC(order_date) ORDER BY order_date DESC) rn
FROM TABLE1 a)
WHERE rn <= 10;
12345
2、ROWID
ROWID仍旧需求ROWNUM,但方式不同,因此我将其归为另一大类,其代码为:
SELECT *
FROM (SELECT RID
FROM (SELECT R.RID, ROWNUM LINENUM
FROM (SELECT ROWID RID
FROM TABLE1
WHERE TABLE1_ID = XX
ORDER BY order_date DESC) R
WHERE ROWNUM <= 20)
WHERE LINENUM >= 10) T1,
TABLE1 T2
WHERE T1.RID = T2.ROWID;
1234567891011
从语句上看,共有4层Select嵌套查询,最内层为可替换的不分页原始SQL语句,但是他查询的字段只有ROWID,而没有任何待查询的实际表字段,具体查询实际字段值是在最外层实现的;
这种方式的原理大致为:
首先通过ROWNUM查询到分页之后的10条实际返回记录的ROWID,最后通过ROWID将最终返回字段值查询出来并返回;
1
和前面ROWNUM实现方式相比,该SQL的实现方式更加繁琐,通用性也不是非常好,因为要将原始的查询语句分成两部分(查询字段在最外层,表及其查询条件在最内层),想要复用就很困难了;
但这种实现在特定场景下还是有优势的:比如我们经常要翻页到很后面,比如10000条记录中我们经常需要查9000-9100及其以后的数据;此时该方案效率可能要比前面的高;
因为前面的方案中是通过ROWNUM <= 9100来控制的,这样就需要查询出9100条数据,然后取最后9000-9100之间的数据,而这个方案直接通过ROWID取需要的那100条数据;
从不断向后翻页这个角度来看,第一种实现方案的成本会越来越高,基本上是线性增长,而第三种方案的成本则不会像前者那样快速,他的增长只体现在通过查询条件读取ROWID的部分;
因此,在我们实际项目中,基本分页都是可以单靠ROWNUM就可以实现,而在数据量只有几十万的情况下,效率也是够的,如果一定要优化,则可以考虑ROWID。
---------------------
版权声明:本文为CSDN博主「death05」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/death05/article/details/78744250
1. Oracle跟SQL Server 2005的区别?
宏观上:
1). 最大的区别在于平台,oracle可以运行在不同的平台上,sql server只能运行在windows平台上,由于windows平台的稳定性和安全性影响了sql server的稳定性和安全性
2). oracle使用的脚本语言为PL-SQL,而sql server使用的脚本为T-SQL
微观上: 从数据类型,数据库的结构等等回答
2. 如何使用Oracle的游标?
1). oracle中的游标分为显示游标和隐式游标
2). 显示游标是用cursor...is命令定义的游标,它可以对查询语句(select)返回的多条记录进行处理;隐式游标是在执行插入 (insert)、删除(delete)、修改(update)和返回单条记录的查询(select)语句时由PL/SQL自动定义的。
3). 显式游标的操作:打开游标、操作游标、关闭游标;PL/SQL隐式地打开SQL游标,并在它内部处理SQL语句,然后关闭它
3. Oracle中function和procedure的区别?
1). 可以理解函数是存储过程的一种
2). 函数可以没有参数,但是一定需要一个返回值,存储过程可以没有参数,不需要返回值
3). 函数return返回值没有返回参数模式,存储过程通过out参数返回值, 如果需要返回多个参数则建议使用存储过程
4). 在sql数据操纵语句中只能调用函数而不能调用存储过程
4. Oracle的导入导出有几种方式,有何区别?
1). 使用oracle工具 exp/imp
2). 使用plsql相关工具
方法1. 导入/导出的是二进制的数据, 2.plsql导入/导出的是sql语句的文本文件
5. Oracle中有哪几种文件?
数据文件(一般后缀为.dbf或者.ora),日志文件(后缀名.log),控制文件(后缀名为.ctl)
6. 怎样优化Oracle数据库,有几种方式?
个人理解,数据库性能最关键的因素在于IO,因为操作内存是快速的,但是读写磁盘是速度很慢的,优化数据库最关键的问题在于减少磁盘的IO,就个人理解应该分为物理的和逻辑的优化, 物理的是指oracle产品本身的一些优化,逻辑优化是指应用程序级别的优化
物理优化的一些原则:
1). Oracle的运行环境(网络,硬件等)
2). 使用合适的优化器
3). 合理配置oracle实例参数
4). 建立合适的索引(减少IO)
5). 将索引数据和表数据分开在不同的表空间上(降低IO冲突)
6). 建立表分区,将数据分别存储在不同的分区上(以空间换取时间,减少IO)
逻辑上优化:
1). 可以对表进行逻辑分割,如中国移动用户表,可以根据手机尾数分成10个表,这样对性能会有一定的作用
2). Sql语句使用占位符语句,并且开发时候必须按照规定编写sql语句(如全部大写,全部小写等)oracle解析语句后会放置到共享池中
如: select * from Emp where name=? 这个语句只会在共享池中有一条,而如果是字符串的话,那就根据不同名字存在不同的语句,所以占位符效率较好
3). 数据库不仅仅是一个存储数据的地方,同样是一个编程的地方,一些耗时的操作,可以通过存储过程等在用户较少的情况下执行,从而错开系统使用的高峰时间,提高数据库性能
4). 尽量不使用*号,如select * from Emp,因为要转化为具体的列名是要查数据字典,比较耗时
5). 选择有效的表名
对于多表连接查询,可能oracle的优化器并不会优化到这个程度, oracle 中多表查询是根据FROM字句从右到左的数据进行的,那么最好右边的表(也就是基础表)选择数据较少的表,这样排序更快速,如果有link表(多对多中间表),那么将link表放最右边作为基础表,在默认情况下oracle会自动优化,但是如果配置了优化器的情况下,可能不会自动优化,所以平时最好能按照这个方式编写sql
6). Where字句 规则
Oracle 中Where字句时从右往左处理的,表之间的连接写在其他条件之前,能过滤掉非常多的数据的条件,放在where的末尾, 另外!=符号比较的列将不使用索引,列经过了计算(如变大写等)不会使用索引(需要建立起函数), is null、is not null等优化器不会使用索引
7). 使用Exits Not Exits 替代 In Not in
8). 合理使用事务,合理设置事务隔离性
数据库的数据操作比较消耗数据库资源的,尽量使用批量处理,以降低事务操作次数
7. Oracle中字符串用什么符号链接?
Oracle中使用 || 这个符号连接字符串 如 ‘abc’ || ‘d’
8. Oracle分区是怎样优化数据库的?
Oracle的分区可以分为:列表分区、范围分区、散列分区、复合分区。
1). 增强可用性:如果表的一个分区由于系统故障而不能使用,表的其余好的分区仍可以使用;
2). 减少关闭时间:如果系统故障只影响表的一部份分区,那么只有这部份分区需要修复,可能比整个大表修复花的时间更少;
3). 维护轻松:如果需要得建表,独产管理每个公区比管理单个大表要轻松得多;
4). 均衡I/O:可以把表的不同分区分配到不同的磁盘来平衡I/O改善性能;
5). 改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,可使运行速度更快
6). 分区对用户透明,最终用户感觉不到分区的存在。
9. Oracle是怎样分页的?
Oracle中使用rownum来进行分页, 这个是效率最好的分页方法,hibernate也是使用rownum来进行oralce分页的
select * from
( select rownum r,a from tabName where rownum <= 20 )
where r > 10
10. Oralce怎样存储文件,能够存储哪些文件?
Oracle 能存储 clob、nclob、 blob、 bfile
Clob 可变长度的字符型数据,也就是其他数据库中提到的文本型数据类型
Nclob 可变字符类型的数据,不过其存储的是Unicode字符集的字符数据
Blob 可变长度的二进制数据
Bfile 数据库外面存储的可变二进制数据
11. Oracle中使用了索引的列,对该列进行where条件查询、分组、排序、使用聚集函数,哪些用到了索引?
均会使用索引, 值得注意的是复合索引(如在列A和列B上建立的索引)可能会有不同情况
12. 数据库怎样实现每隔30分钟备份一次?
通过操作系统的定时任务调用脚本导出数据库
13. Oracle中where条件查询和排序的性能比较?
Order by使用索引的条件极为严格,只有满足如下情况才可以使用索引,
1). order by中的列必须包含相同的索引并且索引顺序和排序顺序一致
2). 不能有null值的列
所以排序的性能往往并不高,所以建议尽量避免order by
14. 解释冷备份和热备份的不同点以及各自的优点?
冷备份发生在数据库已经正常关闭的情况下,将关键性文件拷贝到另外位置的一种说法
热备份是在数据库运行的情况下,采用归档方式备份数据的方法
冷备的优缺点:
1).是非常快速的备份方法(只需拷贝文件)
2).容易归档(简单拷贝即可)
3).容易恢复到某个时间点上(只需将文件再拷贝回去)
4).能与归档方法相结合,作数据库“最新状态”的恢复。
5).低度维护,高度安全。
冷备份不足:
1).单独使用时,只能提供到“某一时间点上”的恢复。
2).在实施备份的全过程中,数据库必须要作备份而不能作其它工作。也就是说,在冷备份过程中,数据库必须是关闭状态。
3).若磁盘空间有限,只能拷贝到磁带等其它外部存储设备上,速度会很慢。
4).不能按表或按用户恢复。
热备的优缺点
1).可在表空间或数据文件级备份,备份时间短。
2).备份时数据库仍可使用。
3).可达到秒级恢复(恢复到某一时间点上)。
4).可对几乎所有数据库实体作恢复。
5).恢复是快速的,在大多数情况下在数据库仍工作时恢复。
热备份的不足是:
1).不能出错,否则后果严重。
2).若热备份不成功,所得结果不可用于时间点的恢复。
3).因难于维护,所以要特别仔细小心,不允许“以失败而告终”。
15. 解释data block , extent 和 segment的区别?
data block 数据块,是oracle最小的逻辑单位,通常oracle从磁盘读写的就是块
extent 区,是由若干个相邻的block组成
segment段,是有一组区组成
tablespace表空间,数据库中数据逻辑存储的地方,一个tablespace可以包含多个数据文件
16. 比较truncate和delete命令 ?
1). Truncate 和delete都可以将数据实体删掉,truncate 的操作并不记录到 rollback日志,所以操作速度较快,但同时这个数据不能恢复
2). Delete操作不腾出表空间的空间
3). Truncate 不能对视图等进行删除
4). Truncate是数据定义语言(DDL),而delete是数据操纵语言(DML)
17. 解释什么是死锁,如何解决Oracle中的死锁?
简言之就是存在加了锁而没有解锁,可能是使用锁没有提交或者回滚事务,如果是表级锁则不能操作表,客户端处于等在状态,如果是行级锁则不能操作锁定行
解决办法:
1). 查找出被锁的表
select b.owner,b.object_name,a.session_id,a.locked_mode
from v$locked_object a,dba_objects b
where b.object_id = a.object_id;
select b.username,b.sid,b.serial#,logon_time
from v$locked_object a,v$session b
where a.session_id = b.sid order by b.logon_time;
2). 杀进程中的会话
alter system kill session "sid,serial#";
18. 简述oracle中 dml、ddl、dcl的使用
Dml 数据操纵语言,如select、update、delete,insert
Ddl 数据定义语言,如create table 、drop table 等等
Dcl 数据控制语言, 如 commit、 rollback、grant、 invoke等
19. 说说oracle中的经常使用到得函数
Length 长度、 lower 小写、upper 大写, to_date 转化日期, to_char转化字符
Ltrim 去左边空格、 rtrim去右边空格,substr取字串,add_month增加或者减掉月份、to_number转变为数字
20. 怎样创建一个存储过程, 游标在存储过程怎么使用, 有什么好处?
附:存储过程的一般格式,游标使用参考问题
1 .使用游标可以执行多个不相关的操作.如果希望当产生了结果集后,对结果集中的数据进行多种不相关的数据操作
2. 使用游标可以提供脚本的可读性
3. 使用游标可以建立命令字符串,使用游标可以传送表名,或者把变量传送到参数中,以便建立可以执行的命令字符串.
但是个人认为游标操作效率不太高,并且使用时要特别小心,使用完后要及时关闭
存储过程优缺点:
优点:
1. 存储过程增强了SQL语言的功能和灵活性。存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
2. 可保证数据的安全性和完整性。
3. 通过存储过程可以使没有权限的用户在控制之下间接地存取数据库,从而保证数据的安全。
通过存储过程可以使相关的动作在一起发生,从而可以维护数据库的完整性。
3. 再运行存储过程前,数据库已对其进行了语法和句法分析,并给出了优化执行方案。这种已经编译好的过程可极大地改善SQL语句的性能。 由于执行SQL语句的大部分工作已经完成,所以存储过程能以极快的速度执行。
4. 可以降低网络的通信量, 不需要通过网络来传送很多sql语句到数据库服务器了
5. 使体现企业规则的运算程序放入数据库服务器中,以便集中控制
当企业规则发生变化时在服务器中改变存储过程即可,无须修改任何应用程序。企业规则的特点是要经常变化,如果把体现企业规则的运算程序放入应用程序中,则当企业规则发生变化时,就需要修改应用程序工作量非常之大(修改、发行和安装应用程序)。如果把体现企业规则的 运算放入存储过程中,则当企业规则发生变化时,只要修改存储过程就可以了,应用程序无须任何变化。
缺点:
1. 可移植性差
2. 占用服务器端多的资源,对服务器造成很大的压力
3. 可读性和可维护性不好
Create [or replace] procedure 过程名字(参数 …)as
vs_ym_sn_end CHAR(6); --同期终止月份
CURSOR cur_1 IS --定义游标(简单的说就是一个可以遍历的结果集)
SELECT area_code,CMCODE,SUM(rmb_amt)/10000 rmb_amt_sn,SUM(usd_amt)/10000 usd_amt_sn
FROM BGD_AREA_CM_M_BASE_T
WHERE ym >= vs_ym_sn_beg
AND ym <= vs_ym_sn_end
GROUP BY area_code,CMCODE;
BEGIN
--用输入参数给变量赋初值,用到了Oralce的SUBSTR TO_CHAR ADD_MONTHS TO_DATE 等很常用的函数。
vs_ym_beg := SUBSTR(is_ym,1,6);
vs_ym_end := SUBSTR(is_ym,7,6);
vs_ym_sn_beg := TO_CHAR(ADD_MONTHS(TO_DATE(vs_ym_beg,"yyyymm"), -12),"yyyymm");
vs_ym_sn_end := TO_CHAR(ADD_MONTHS(TO_DATE(vs_ym_end,"yyyymm"), -12),"yyyymm");
--先删除表中特定条件的数据。
DELETE FROM xxxxxxxxxxx_T WHERE ym = is_ym;
--然后用内置的DBMS_OUTPUT对象的put_line方法打印出影响的记录行数,其中用到一个系统变量SQL%rowcount
DBMS_OUTPUT.put_line("del上月记录="||SQL%rowcount||"条");
INSERT INTO xxxxxxxxxxx_T(area_code,ym,CMCODE,rmb_amt,usd_amt)
SELECT area_code,is_ym,CMCODE,SUM(rmb_amt)/10000,SUM(usd_amt)/10000
FROM BGD_AREA_CM_M_BASE_T
WHERE ym >= vs_ym_beg
AND ym <= vs_ym_end
GROUP BY area_code,CMCODE;
DBMS_OUTPUT.put_line("ins当月记录="||SQL%rowcount||"条");
--遍历游标处理后更新到表。遍历游标有几种方法,用for语句是其中比较直观的一种。
FOR rec IN cur_1 LOOP
UPDATE xxxxxxxxxxx_T
SET rmb_amt_sn = rec.rmb_amt_sn,usd_amt_sn = rec.usd_amt_sn
WHERE area_code = rec.area_code
AND CMCODE = rec.CMCODE
AND ym = is_ym;
END LOOP;
COMMIT;
--错误处理部分。OTHERS表示除了声明外的任意错误。SQLERRM是系统内置变量保存了当前错误的详细信息。
EXCEPTION
WHEN OTHERS THEN
vs_msg := "ERROR IN xxxxxxxxxxx_p("||is_ym||"):"||SUBSTR(SQLERRM,1,500);
ROLLBACK;
--把当前错误记录进日志表。
INSERT INTO LOG_INFO(proc_name,error_info,op_date)
VALUES("xxxxxxxxxxx_p",vs_msg,SYSDATE);
COMMIT;
RETURN;
END;
21. 怎样创建一个一个索引,索引使用的原则,有什么优点和缺点
创建标准索引:
CREATE INDEX 索引名 ON 表名 (列名) TABLESPACE 表空间名;
创建唯一索引:
CREATE unique INDEX 索引名 ON 表名 (列名) TABLESPACE 表空间名;
创建组合索引:
CREATE INDEX 索引名 ON 表名 (列名1,列名2) TABLESPACE 表空间名;
创建反向键索引:
CREATE INDEX 索引名 ON 表名 (列名) reverse TABLESPACE 表空间名;
索引使用原则:
索引字段建议建立NOT NULL约束
经常与其他表进行连接的表,在连接字段上应该建立索引;
经常出现在Where子句中的字段且过滤性很强的,特别是大表的字段,应该建立索引;
可选择性高的关键字 ,应该建立索引;
可选择性低的关键字,但数据的值分布差异很大时,选择性数据比较少时仍然可以利用索引提高效率
复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的第一个字段,一般是选择性较好的且在where子句中常用的字段上;
B、复合索引的几个字段经常同时以AND方式出现在Where子句中可以建立复合索引;否则单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
频繁DML的表,不要建立太多的索引;
不要将那些频繁修改的列作为索引列;
索引的优缺点:
有点:
1. 创建唯一性索引,保证数据库表中每一行数据的唯一性
2. 大大加快数据的检索速度,这也是创建索引的最主要的原因
3. 加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
4. 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
缺点:
1. 索引创建在表上,不能创建在视图上
2. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
3. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大
4. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度
22. 怎样创建一个视图,视图的好处, 视图可以控制权限吗?
create view 视图名 as select 列名 [别名] … from 表 [unio [all] select … ] ]
好处:
1. 可以简单的将视图理解为sql查询语句,视图最大的好处是不占系统空间
2. 一些安全性很高的系统,不会公布系统的表结构,可能会使用视图将一些敏感信息过虑或者重命名后公布结构
3. 简化查询
可以控制权限的,在使用的时候需要将视图的使用权限grant给用户
23. 怎样创建一个触发器, 触发器的定义, 触发器的游标怎样定义
CREATE [OR REPLACE] TIGGER触发器名 触发时间 触发事件
ON表名
[FOR EACH ROW]
BEGIN
pl/sql语句
CURSOR 游标名 is SELECT * FROM 表名 (定义游标)
END
其中:
触发器名:触发器对象的名称。
由于触发器是数据库自动执行的,因此该名称只是一个名称,没有实质的用途。
触发时间:指明触发器何时执行,该值可取:
before---表示在数据库动作之前触发器执行;
after---表示在数据库动作之后出发器执行。
触发事件:指明哪些数据库动作会触发此触发器:
insert:数据库插入会触发此触发器;
24. oracle创建表的几种方式;应该注意些什么
不知道这个题目是不是记错了,感觉很怪
1. 使用图形工具创建表
2. 使用数据ddl语句创建表
3. 可以在plsql代码中动态创建表
应该注意: 是否有创建表的权限, 使用什么表空间等
25. 怎样将一个旧数据库数据移到一个新的数据库
1. Imp/exp将数据库中的数据导入到新的库中
2. 如果是存储迁移直接将存储设备挂到新机器上
26. 主键有几种;
字符型,整数型、复合型
27. oracle的锁又几种,定义分别是什么;
1. 行共享锁 (ROW SHARE)
2. 行排他锁(ROW EXCLUSIVE)
3 . 共享锁(SHARE)
4. 共享行排他锁(SHARE ROW EXCLUSIVE)
5. 排他锁(EXCLUSIVE)
使用方法:
SELECT * FROM order_master WHERE vencode="V002"
FOR UPDATE WAIT 5;
LOCK TABLE order_master IN SHARE MODE;
LOCK TABLE itemfile IN EXCLUSIVE MODE NOWAIT;
ORACLE锁具体分为以下几类:
1.按用户与系统划分,可以分为自动锁与显示锁
自动锁:当进行一项数据库操作时,缺省情况下,系统自动为此数据库操作获得所有有必要的锁。
显示锁:某些情况下,需要用户显示的锁定数据库操作要用到的数据,才能使数据库操作执行得更好,显示锁是用户为数据库对象设定的。
2 . 按锁级别划分,可分为共享锁与排它锁
共享锁:共享锁使一个事务对特定数据库资源进行共享访问——另一事务也可对此资源进行访问或获得相同共享锁。共享锁为事务提供高并发性,但如拙劣的事务设计+共享锁容易造成死锁或数据更新丢失。
排它锁:事务设置排它锁后,该事务单独获得此资源,另一事务不能在此事务提交之前获得相同对象的共享锁或排它锁。
3.按操作划分,可分为DML锁、DDL锁
DML锁又可以分为,行锁、表锁、死锁
行锁:当事务执行数据库插入、更新、删除操作时,该事务自动获得操作表中操作行的排它锁。
表级锁:当事务获得行锁后,此事务也将自动获得该行的表锁(共享锁),以防止其它事务进行DDL语句影响记录行的更新。事务也可以在进行过程中获得共享锁或排它锁,只有当事务显示使用LOCK TABLE语句显示的定义一个排它锁时,事务才会获得表上的排它锁,也可使用LOCK TABLE显示的定义一个表级的共享锁(LOCK TABLE具体用法请参考相关文档)。
死锁:当两个事务需要一组有冲突的锁,而不能将事务继续下去的话,就出现死锁。
如事务1在表A行记录#3中有一排它锁,并等待事务2在表A中记录#4中排它锁的释放,而事务2在表A记录行#4中有一排它锁,并等待事务; 1在表A中记录#3中排它锁的释放,事务1与事务2彼此等待,因此就造成了死锁。死锁一般是因拙劣的事务设计而产生。死锁只能使用SQL下:alter system kill session "sid,serial#";或者使用相关操作系统kill进程的命令,如UNIX下kill -9 sid,或者使用其它工具杀掉死锁进程。
DDL锁又可以分为:排它DDL锁、共享DDL锁、分析锁
排它DDL锁:创建、修改、删除一个数据库对象的DDL语句获得操作对象的 排它锁。如使用alter table语句时,为了维护数据的完成性、一致性、合法性,该事务获得一排它DDL锁。
共享DDL锁:需在数据库对象之间建立相互依赖关系的DDL语句通常需共享获得DDL锁。
如创建一个包,该包中的过程与函数引用了不同的数据库表,当编译此包时,该事务就获得了引用表的共享DDL锁。
分析锁:ORACLE使用共享池存储分析与优化过的SQL语句及PL/SQL程序,使运行相同语句的应用速度更快。一个在共享池中缓存的对象获得它所引用数据库对象的分析锁。分析锁是一种独特的DDL锁类型,ORACLE使用它追踪共享池对象及它所引用数据库对象之间的依赖关系。当一个事务修改或删除了共享池持有分析锁的数据库对象时,ORACLE使共享池中的对象作废,下次在引用这条SQL/PLSQL语句时,ORACLE重新分析编译此语句。
4.内部闩锁
内部闩锁:这是ORACLE中的一种特殊锁,用于顺序访问内部系统结构。当事务需向缓冲区写入信息时,为了使用此块内存区域,ORACLE首先必须取得这块内存区域的闩锁,才能向此块内存写入信息。
28. 在java种怎样调用oracle存储过程;
在java中使用 CallableStatement调用存储过程
创建需要的测试表:create table Test(tid varchar2(10),tname varchar2(10));
第一种情况:无返回值.
create or replace procedure test_a(param1 in varchar2,param2 in varchar2) as
begin
insert into test value(param1,param2);
end;
Java调用代码:
package com.test;
import java.sql.*;
import java.io.*;
import java.sql.*;
public class TestProcA
{
public TestProcA(){
}
public static void main(String []args)
{
ResultSet rs = null;
Connection conn = null;
CallableStatement proc = null;
try{
Class.forName("oracle.jdbc.driver.OracleDriver");
conn = DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:test", "test", "test");
proc = conn.prepareCall("{ call test_a(?,?) }");
proc.setString(1, "1001");
proc.setString(2, "TestA");
proc.execute();
}catch(Exception e){
e.printStackTrace();
}finally{
try{
if(null!=rs){
rs.close();
if(null!=proc){
proc.close();
}
if(null!=conn){
conn.close();
}
}
}catch(Exception ex){
}
}
}
}
第二种情况:有返回值的存储过程(返回值非列表).
存储过程为:
create or replace procedure test_b(param1 in varchar2,param2 out varchar2)
as
begin
select tname into param2 from test where tid=param1;
end;
Java调用代码:
package com.test;
import java.sql.*;
import java.io.*;
import java.sql.*;
public class TestProcB
{
public TestProcB(){
}
public static void main(String []args)
{
Connection conn = null;
CallableStatement proc = null;
try{
Class.forName("oracle.jdbc.driver.OracleDriver");
conn = DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:test", "test", "test");
proc = conn.prepareCall("{ call test_b(?,?) }");
proc.setString(1, "1001");
proc.registerOutParameter(2, Types.VARCHAR);
proc.execute();
System.out.println("Output is:"+proc.getString(2));
}catch(Exception e){
e.printStackTrace();
}finally{
try{
if(null!=proc){
proc.close();
}
if(null!=conn){
conn.close();
}
}catch(Exception ex){
}
}
}
}
第三种情况:返回列表.
由于oracle存储过程没有返回值,它的所有返回值都是通过out参数来替代的,列表同样也不例外,但由于是集合,所以不能用一般的参数,必须要用pagkage了.要分两部分来写:
create or replace package tpackage as
type t_cursor is ref cursor;
procedure test_c(c_ref out t_cursor);
end ;
create or replace package body tpackage as
procedure test_c(c_ref out t_cursor) is
begin
open c_ref for select * from test;
end test_c;
end tpackage;
Java调用代码:
package com.test;
import java.sql.*;
import java.io.*;
import java.sql.*;
public class TestProcB
{
public TestProcB(){
}
public static void main(String []args)
{
Connection conn = null;
CallableStatement proc = null;
ResultSet rs = null;
try{
Class.forName("oracle.jdbc.driver.OracleDriver");
conn = DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:test", "test", "test");
proc = conn.prepareCall("{? = call tpackage.test_b(?) }");
proc.registerOutParameter(1, OracleTypes.CURSOR);
proc.execute();
while(rs.next()){
System.out.println(rs.getObject(1) + "\t" + rs.getObject(2));
}
}catch(Exception e){
e.printStackTrace();
}finally{
try{
if(null!=rs){
rs.close();
if(null!=proc){
proc.close();
}
if(null!=conn){
conn.close();
}
}
}catch(Exception ex){
}
}
}
}
29. rowid, rownum的定义
1. rowid和rownum都是虚列
2. rowid是物理地址,用于定位oracle中具体数据的物理存储位置
3. rownum则是sql的输出结果排序,从下面的例子可以看出其中的区别。
30. oracle中存储过程,游标和函数的区别
游标类似指针,游标可以执行多个不相关的操作.如果希望当产生了结果集后,对结果集中的数据进行多 种不相关的数据操作
函数可以理解函数是存储过程的一种; 函数可以没有参数,但是一定需要一个返回值,存储过程可以没有参数,不需要返回值;两者都可以通过out参数返回值, 如果需要返回多个参数则建议使用存储过程;在sql数据操纵语句中只能调用函数而不能调用存储过程
31. 使用oracle 伪列删除表中重复记录:
Delete table t where t.rowid!=(select max(t1.rowid) from table1 t1 where t1.name=t.name)
30. 常见的关系型数据库有哪些
关系型数据库:
Oracle、DB2、Microsoft SQL Server、Microsoft Access、MySQL
非关系型数据库:
NoSql、Cloudant、MongoDb、redis、HBase
两种数据库之间的区别:
关系型数据库
关系型数据库的特性
1、关系型数据库,是指采用了关系模型来组织数据的数据库;
2、关系型数据库的最大特点就是事务的一致性;
3、简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
关系型数据库的优点
1、容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解;
2、使用方便:通用的SQL语言使得操作关系型数据库非常方便;
3、易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率;
4、支持SQL,可用于复杂的查询。
关系型数据库的缺点
1、为了维护一致性所付出的巨大代价就是其读写性能比较差;
2、固定的表结构;
3、高并发读写需求;
4、海量数据的高效率读写;
非关系型数据库
非关系型数据库的特性
1、使用键值对存储数据;
2、分布式;
3、一般不支持ACID特性;
4、非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
非关系型数据库的优点
1、无需经过sql层的解析,读写性能很高;
2、基于键值对,数据没有耦合性,容易扩展;
3、存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,而关系型数据库则只支持基础类型。
非关系型数据库的缺点
1、不提供sql支持,学习和使用成本较高;
2、无事务处理,附加功能bi和报表等支持也不好;
31. SQL结构化查询语言(Structured Query Language)有哪些内容
1.关键词
SELECT,UPDATE,DELETE,INSERECT,WHERE
2.RDBMS(Relational Database Management System)关系型数据库管理系统
比如MS SQL Server,IBM DB2,Oracle,MySQL,Microsoft Access
3.RDBMS中的数据存储在被称为表(tables)的数据库对象中。 (解析理解 表(tables)被称为数据库对象?)
表是相关数据项的集合,它由列和行组成
4.数据库表
一个数据库通常包含一个或者多个表,每个表由一个名字标识(例如“客户”或“订单”),表包含带有数据的记录。
5.可以吧SQL分为2部分,DML(数据操作语言)、DDL(数据定义语言)
6.查询和更新指令构成了SQL的DML部分,
SELECT-从数据库表中获取数据
UPDATE-更新数据库表中的数据
DELETE-从数据库表中删除数据
INSERT INTO-向数据库表中插入数据
7.SQL数据定义语言(DDL)部分使我们有能力创建或者删除表格。我们也可以定义索引(键),规定表之间的链接,以及施加表间的约束
SQL中最重要的DDL语句
-CREATE DATABASE 创建新数据库
-ALTER DATABASE 修改数据库
-CREATE TABLE 创建新表
-ALTER TABLE 变更(改变)数据库表
-DROP TABLE 删除表
-CREATE INDEX 创建索引(搜索键)
-DROP INDEX(删除索引)
---------------------
版权声明:本文为CSDN博主「匠人科」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhangke_zhangke/article/details/76563189
32. 单行函数有哪些
单行函数介绍
SQL函数即数据库的内置函数,可以运用在SQL语句中实现特定的功能。SQL单行函数对于每一行数据进行计算后得到一行输出结果。SQL单行函数根据数据类型分为字符函数、数字函数、日期函数、转换函数,另外还有一些别的函数。——来自百度

一、字符函数
大小写转换函数
大小写转换函数包括:
1. UPPER() , 将查询的字符串小写转换为大写 ;
2. LOWER() , 将查询的字符串大写转换为小写 ;
3. INITCAP() , 将查询的字符串首字母大写 ;
将表中的id和t_string查询出来,并将string大写
select id , upper(string)
from T_CHAR ;12
查询结果:

将表中的id和t_string查询出来,并将string小写
select id , lower(string)
from T_CHAR ;12
查询结果:

将表中的id和t_string查询出来,并将string首字母大写
select id , initcap(string)
from T_CHAR ;12
查询结果:

字符控制函数
SQL中常用的字符控制函数有:
1. CONCAT(),字符串连接函数
2. SUBSTR(),字符串截取函数
3. LEANTH(),求字符串长度函数
4. LPAD(),左填充函数
5. RPAD(),右填充函数
6. TRIM(),字符移除函数
7. REPLACE(),字符替换函数
CONCAT():将T_CHAR表string 和 string2连接起来
select id , concat(t_string , t_string2)
from T_CHAR12
查询结果:

SUBSTR():截取string 中的前2个字符和string2中的前4个字符 。
select id , substr(t_string , 1 , 2 ) ,substr(t_string2 , 1 , 4 )
from T_CHAR12
查询结果:

LEANTH():求string和string2的字符串长度
select id , t_string , length(t_string) ,t_string2 ,length(t_string2)
from T_CHAR12
运行结果:

LPAD() ,RPAD(), 将string用‘*’填充,string2用‘#’填充,总长为10
select id , rpad(t_string,10,'*') ,lpad(t_string2,10,'#')
from T_CHAR12
查询结果:

TRIM(),将string中的首位字母 ‘a’ 删除 ,string2中的首尾字母 ‘o’ 删除。
select id , trim('d' from t_string) ,trim('w' from t_string2 )
from T_CHAR ;12
查询结果:

REPLACE() ,将string中的所有 ‘a’ 替换成‘*’ , string2中的所有‘o’替换成‘#’ 。
select id , replace(t_string , 'a' , '*') ,replace(t_string2 ,'o' ,'#' )
from T_CHAR ;12
查询结果:

二、数字函数
SQL中用于数字计算的数字函数有:
1. ROUND() ,四舍五入函数;
2. TRUNC() ,截取函数
3. MOD() ,求余函数
ROUND() ,将T_CHAR表中的 t_number保留两位小数第三位四舍五入。
select id , round(t_number , 2)
from T_CHAR ;12
查询结果:

TRUNC() ,截取T_CHAR中的 t_number 保留小数点后四位,其余舍去。
select id , trunc(t_number , 4)
from T_CHAR ;12
查询结果:

MOD() ,将T_CHAR中的 t_number 取模10 。
select id , mod(t_number , 10)
from T_CHAR ;12
查询结果:

三、日期函数
对日期进行粗略计算
SQL中可以对日期进行粗略计算:
1. 可以将日期加上或者减去n天
2. 可以用两个日期相减得到相差天数
将T_CHAR中的 t_date加上一天,减去两天。
select t_date , t_date + 1 , t_date - 2
from T_CHAR ;12
查询结果:

计算t_date到系统时间的天数 。
select t_date , sysdate , sysdate - t_date
from T_CHAR ;12
查询结果:

对日期进行精确计算
SQL中提供了精确计算日期的函数:
1. MONTHS_BETWEEN() 计算两个日期相差的天数;
2. ADD_MONTHS() 往一个日期中加n月;
3. NEXT_DAY() 当前系统时间的下一星期n的时间
4. LAST_DAY() 日期中月的最后一天
5. ROUND() 对日期的四舍五入
6. TRUNC() 对日期的截取
计算T_CHAR中的 t_date和系统时间相差的天数 , 并将t_date加2个月
select t_date , months_between(sysdate , t_date) , add_months(t_date , 2)
from T_CHAR ;12
查询结果:

计算T_CHAR中 t_date 下一个星期三的日期,并计算系统时间的t_date最后一天的日期
select t_date , next_day(t_date , '星期三' ) , last_day(t_date)
from T_CHAR ;12
查询结果:

将T_CHAR中 t_date按月四舍五入,将t_date按日截取
select t_date , round(t_date,'month') , trunc(t_date , 'day')
from T_CHAR ;12
查询结果:

四、转换函数
SQL中可以进行两种数据类型的转换,即隐式转换和显示转换。
隐式数据类型转换
ORACLE数据库中会将 char或varchar2 与 date 和 number 之间进行相互转换。如前例中日期date可以和number进行加减运算,也可以将输入的varchar2类型存入date型的数据库中,称之为隐形转换。
显式数据类型转换
ORACLE数据库中也可以通过方法 to_char() , to_date() , to_number(),完成数据类型之间的转换。
- 查询T_CHAR表中日期为’2016年7月21日’ 的数据(日期转字符串)。
select *
from T_CHAR
where to_char(t_date , 'yyyy-mm-dd') = '2016-07-21' ;123
查询结果:

查询T_CHAR表中日期为’2015年11月19日’ 的数据(字符串转日期)。
select *
from T_CHAR
where to_date('2015年11月19日' , 'yyyy"年"mm"月"dd"日"') = t_date ;123
查询结果:

注:日期格式说明表示year的:y 表示年的最后一位 yy 表示年的最后2位 yyy 表示年的最后3位 yyyy 用4位数表示年;
表示month的:mm 用2位数字表示月;mon 用简写形式 比如11月或者nov ;month 用全称 比如11月或者november;
表示day的:dd 表示当月第几天;ddd表示当年第几天;dy 当周第几天 简写 比如星期五或者fri;day当周第几天 全写比如星期五或者friday;
表示hour的:hh 2位数表示小时 12进制; hh24 2位数表示小时 24小时;
表示minute的:mi 2位数表示分钟;
表示second的:ss 2位数表示秒 60进制;
表示季度的:q 一位数 表示季度 (1-4);
另外还有ww 用来表示当年第几周 w用来表示当月第几周;
24小时制下的时间范围:00:00:00-23:59:59 ;
12小时制下的时间范围:1:00:00-12:59:59
将T_CHAR中 t_number 转换为格式‘999,999.999’(数字转字符串)
select id , to_char(t_number , '999,999.999')
from T_CHAR ;12
查询结果: 
注:数字格式说明,用数字‘9’站位数字前有空位不补位,用数字‘0’站位前有空位时补‘0’; ‘$’放在最前表示美元,大写字母‘L’表示当地货币
将字符串’¥47.453’ 转换为数字(字符串转数字)
select to_number('¥47.453','L999,999.999')
from dual ;12
查询结果:

五、通用函数
ORACLE中提供了适合所有数据类型的函数,包括空值。
NVL(A,B) ,能够将一个空值转换成已知的值,若A为空显示A,非空显示B;
NVL2(A,B,C) , 若A非空显示B 为空显示C ;
NULLIF(A,B), A,B相等时返回null,不等时返回A ;
COALESCE(A,B,C…) ,A为空返回B,B为空返回C,以此类推。
修改数据库中数据以便演示通用函数:
查询T_CHAR中所有数据,要求若t_date为空则显示‘日期为空’,若t_string2为空显示‘字符串为空’,若t_number为空则显示‘数字为空’ (NVL)。
select id , t_string , nvl(to_char(t_date , 'yyyy/mm/dd') ,'日期为空') , nvl(t_string2 ,'字符串为空') , nvl(to_char(t_number , '9999999'),'数字为空')
from T_CHAR ;12
查询结果:

查询T_CHAR中所有数据,要求若t_date为空则显示‘日期为空’否则显示‘有日期’,若t_string2为空显示‘字符串为空’否则显示‘有字符串’,若t_number为空则显示‘数字为空’ 否则显示‘有数字’(NVL2类似于if-else,或c语言中的三目运算符?:)。
select id , t_string , nvl2(to_char(t_date , 'yyyy/mm/dd'),'有日期' ,'日期为空') , nvl2(t_string2 ,'有字符串' ,'字符串为空') , nvl2(to_char(t_number , '9999999'),'有数字','数字为空')
from T_CHAR ;12
查询结果:

单行函数介绍
SQL函数即数据库的内置函数,可以运用在SQL语句中实现特定的功能。SQL单行函数对于每一行数据进行计算后得到一行输出结果。SQL单行函数根据数据类型分为字符函数、数字函数、日期函数、转换函数,另外还有一些别的函数。——来自百度
查询T_CHAR中t_string , t_string2的长度,并比较若长度相等显示‘null’ 否则显示t_string长度 ;
select id , t_string , t_string2 , nullif(length(t_string),length(t_string2))
from T_CHAR ;12
查询结果:
------------ ---------
---------
版权声明:本文为CSDN博主「叶清逸」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u013634252/article/details/80570432
33. 分组函数有哪些
34. 多表查询有哪几种方式
分组函数作用于一组数据,并对一组数据返回一个值。
分组函数作用于一组数据,并对一组数据返回一个值。
1.关键字AVG(平均值)、SUM(合计) ,在查询数值型的数据时可以使用AVG 和 SUM 函数。示例代码如下:
select avg(salary),sum(salary)
from employees
where department_id=30;
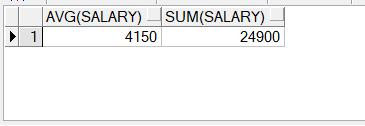
需要注意一个问题,AVG函数只是计算不为空的数据,可以使用NVL函数解决该问题,NVL函数使分组函数无法忽略空值。
SELECT AVG(NVL(commission_pct, 0))
FROM employees;
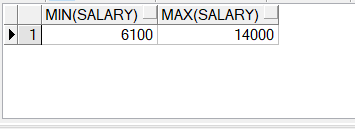
2.关键字MAX(最大值)、MIN(最小值),可以对任意数据类型的数据使用MIN和MAX 函数select
min(salary),max(salary)
from employees
where department_id=80;
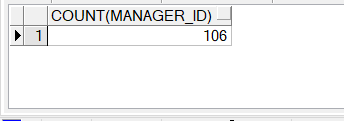
3. COUNT(计数)函数,COUNT(*) 返回表中记录总数,适用于任意数据类型,COUNT(expr) 返回expr不为空的记录总数。如以下两个例子:
SELECT COUNT(manager_id)
FROM employees;
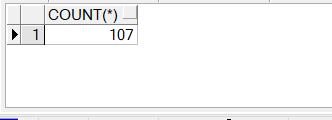
select count(*) from employees;
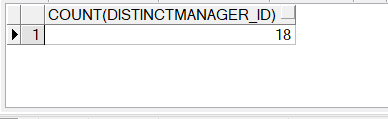
4.distinct关键字,例如COUNT(DISTINCT expr)返回expr非空且不重复的记录总数
select count(distinct manager_id)
from employees;
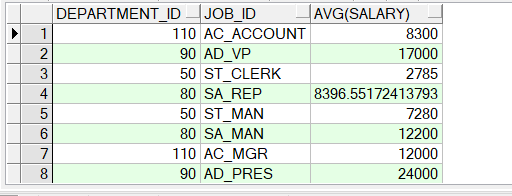
5.group by字句:在SELECT 列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中, 包含在 GROUP BY 子句中的列不必包含在SELECT 列表中。另外需要注意的是,不能
在WHERE 子句中使用组函数,可以在 HAVING 子句中使用组函数。
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id, job_id ;
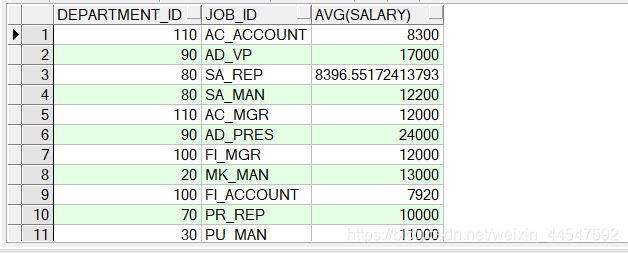
5.过滤分组:having字句
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id, job_id
having AVG(salary)>7500;
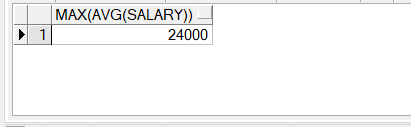
6.嵌套组函数,例如查询各个职位平均工资的最大值
SELECT MAX(AVG(salary))
FROM employees
GROUP BY job_id;
分组函数作用于一组数据,并对一组数据返回一个值。
1.关键字AVG(平均值)、SUM(合计) ,在查询数值型的数据时可以使用AVG 和 SUM 函数。示例代码如下:
select avg(salary),sum(salary)
from employees
where department_id=30;
需要注意一个问题,AVG函数只是计算不为空的数据,可以使用NVL函数解决该问题,NVL函数使分组函数无法忽略空值。
SELECT AVG(NVL(commission_pct, 0))
FROM employees;
2.关键字MAX(最大值)、MIN(最小值),可以对任意数据类型的数据使用MIN和MAX 函数select
min(salary),max(salary)
from employees
where department_id=80;
3. COUNT(计数)函数,COUNT(*) 返回表中记录总数,适用于任意数据类型,COUNT(expr) 返回expr不为空的记录总数。如以下两个例子:
SELECT COUNT(manager_id)
FROM employees;
select count(*) from employees;
4.distinct关键字,例如COUNT(DISTINCT expr)返回expr非空且不重复的记录总数
select count(distinct manager_id)
from employees;
5.group by字句:在SELECT 列表中所有未包含在组函数中的列都应该包含在 GROUP BY 子句中, 包含在 GROUP BY 子句中的列不必包含在SELECT 列表中。另外需要注意的是,不能
在WHERE 子句中使用组函数,可以在 HAVING 子句中使用组函数。
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id, job_id ;
5.过滤分组:having字句
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id, job_id
having AVG(salary)>7500;
6.嵌套组函数,例如查询各个职位平均工资的最大值
SELECT MAX(AVG(salary))
FROM employees
GROUP BY job_id;
35. 子查询中空值和多值怎么处理?
空值
方法一:使用coalesce函数
百度百科
定义: COALESCE是一个函数, (expression_1, expression_2, …,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。使用COALESCE在于大部分包含空值的表达式最终将返回空值。
// 场景一:你想要获取最大值,然后+1返回(即返回的值已经默认为空了),程序接收了本来不该为空的值去运算,就会出错。
SELECT MAX(my_money)+1 FROM tb_test;
// 改进方法:使用 coalesce函数 COALESCE(值1, 值2,......, 值n) ,只要遇到非null值就返回。
// 这样子就可以设置一个值,让你第一个不成功后,返回指定的值,如下面,返回的是1.
SELECT COALESCE(MAX(my_money)+1, 1) FROM tb_test;
方法二:使用case when then else end
Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
Case when 相当于一个自定义的数据透视表,group by 是行名,case when 负责列名。
// 场景一:你想要获取最大值,然后+1返回(即返回的值已经默认为空了),程序接收了本来不该为空的值去运算,就会出错。
SELECT MAX(my_money)+1 FROM tb_test;
// 改进方法:使用 case when then函数。
// 这样子就可以设置一个值,让你第一个不成功后,返回指定的值,如下面,返回的是1.
SELECT
(CASE
WHEN ( MAX(my_money) IS NOT NULL)
THEN MAX(my_money)+1
ELSE 1
END)
FROM tb_test;
---------------------
版权声明:本文为CSDN博主「pengjunzhen」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Pengxiaozhen1111/article/details/86231776
多值
36. Oracle的主要数据类型
一 字符串类型
字符串数据类型还可以依据存储空间分为固定长度类型(CHAR/NCHAR) 和可变长度类型(VARCHAR2/NVARCHAR2)两种.
所谓固定长度:是指虽然输入的字段值小于该字段的限制长度,但是实际存储数据时,会先自动向右补足空格后,才将字段值的内容存储到数据块中。这种方式虽然比较浪费空间,但是存储效率较可变长度类型要好。同时还能减少数据行迁移情况发生。
所谓可变长度:是指当输入的字段值小于该字段的限制长度时,直接将字段值的内容存储到数据块中,而不会补上空白,这样可以节省数据块空间。
1.1:CHAR类型 CHAR(size [BYTE | CHAR])
CHAR类型,定长字符串,会用空格填充来达到其最大长度。非NULL的CHAR(12)总是包含12字节信息。CHAR字段最多可以存储2,000字节的信息。如果创建表时,不指定CHAR长度,则默认为1。另外你可以指定它存储字节或字符,例如 CHAR(12 BYTYE) CHAR(12 CHAR).一般来说默认是存储字节,你可以查看数据库参数
NLS_LENGTH_SEMANTICS的值。
SQL Code
- SQL> show parameter nls_length_semantics;
- NAME TYPE VALUE
- ------------------ ----------- -----------------
- nls_length_semantics string BYTE
- eg:
- CREATE TABLE TEST
- (
- NAME_OLD CHAR(10),
- NAME_NEW CHAR(10 CHAR)
- )
- INSERT INTO TEST
- ( NAME_OLD, NAME_NEW)
- SELECT 'ABCDEFGHIJ' , '你清除字节与字符' FROM DUAL;
- COMMIT;
- INSERT INTO TEST
- ( NAME_OLD, NAME_NEW)
- SELECT '你清除字节与字符' , 'ABCDEFGHIJ' FROM DUAL;
- ORA-12899: 列 "SYS"."TEST"."NAME_OLD" 的值太大 (实际值: 24, 最大值: 10)
注意:数据库的NLS_CHARACTERSET 为AL32UTF8,即一个汉字占用三到四个字节。如果NLS_CHARACTERSET为ZHS16GBK,则一个字符占用两个字节。
如果串的长度小于或等于250(0x01~0xFA), Oracle 会使用1 个字节来表示长度。对于所有长度超过250 的串,都会在一个标志字节0xFE 后跟有两个字节来表示长度。因此,如果有一个包含“Hello World”的VARCHAR2(80),则在块中可能如图12.-1 所示

1.2: NCHAR类型
这是一个包含UNICODE格式数据的定长字符串。NCHAR字段最多可以存储2,000字节的信息。它的最大长度取决于国家字符集。另外查询时,如果字段是NCHAR类型,则需要如下书写
SELECT translated_description FROM product_descriptions
WHERE translated_name = N'LCD Monitor 11/PM';
1.3 VARCHAR类型
不要使用VARCHAR数据类型。使用VARCHAR2数据类型。虽然VARCHAR数据类型目前是VARCHAR2的同义词,VARCHAR数据类型将计划被重新定义为一个单独的数据类型用于可变长度的字符串相比,具有不同的比较语义。
1.4: VARCHAR2类型
变长字符串,与CHAR类型不同,它不会使用空格填充至最大长度。VARCHAR2最多可以存储4,000字节的信息。
1.5: NVARCHAR2类型
这是一个包含UNICODE格式数据的变长字符串。 NVARCHAR2最多可以存储4,000字节的信息。
二. 数字类型
2.1 NUMBER类型
NUMBER(P,S)是最常见的数字类型,可以存放数据范围为10^130~10^126(不包含此值),需要1~22字节(BYTE)不等的存储空间。
P 是Precison的英文缩写,即精度缩写,表示有效数字的位数,最多不能超过38个有效数字
S是Scale的英文缩写,可以使用的范围为-84~127。Scale为正数时,表示从小数点到最低有效数字的位数,它为负数时,表示从最大有效数字到小数点的位数
下面是官方文档的示例
| Actual Data | Specified As | Specified As |
| Specified As | ||
123.89
NUMBER
123.89
123.89
NUMBER(3)
124
123.89
NUMBER(6,2)
123.89
123.89
NUMBER(6,1)
123.9
123.89
NUMBER(3)
124
123.89
NUMBER(4,2)
exceeds precision
123.89
NUMBER(6,-2)
100
.01234
NUMBER(4,5)
.01234
.00012
NUMBER(4,5)
.00012
.000127
NUMBER(4,5)
.00013
.0000012
NUMBER(2,7)
.0000012
.00000123
NUMBER(2,7)
.0000012
1.2e-4
NUMBER(2,5)
0.00012
1.2e-5
NUMBER(2,5)
0.00001
2.2 INTEGER类型
INTEGER是NUMBER的子类型,它等同于NUMBER(38,0),用来存储整数。若插入、更新的数值有小数,则会被四舍五入。
例如:
CREATE TABLE TEST
(
ID INTEGER
)
查看表TEST的DDL(如何查看创建表的DDL语句)定义如下所示
CREATE TABLE "SYS"."TEST"
( "ID" NUMBER(*,0)
) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
INSERT INTO TEST
SELECT 12.34 FROM DUAL;
INSERT INTO TEST
SELECT 12.56 FROM DUAL;
SQL> SELECT * FROM TEST;
ID
----------
12
13
2.3 浮点数
浮点数可以有一个十进制数点任何地方从第一个到最后一个数字,或者可以在所有有没有小数点。指数可能(可选) 用于以下数量增加的范围 (例如, 1.777e-20)。刻度值不适用于浮点数字,因为可以显示在小数点后的位数的数量不受限制。
二进制浮点数不同数量的值由 Oracle 数据库内部存储的方式。使用小数精度数存储值。完全相同号码存储范围和数量由支持的精度内的所有文本。正是因为使用小数精度(数字 0 到 9) 表示文本存储文本。使用二进制精度 (数字 0 和 1) 存储二进制浮点数。这种存储方案不能代表所有确切地使用小数精度的值。频繁地,将值从十进制转换为二进制的精度时出现的错误时撤消值回从二进制转换为十进制精度。在字面 0.1 是一个这样的例子。
Oracle 数据库提供了专为浮点数的两种数值数据类型:
BINARY_FLOAT
BINARY_FLOAT 是 32 位、 单精度浮点数字数据类型。可以支持至少6位精度,每个 BINARY_FLOAT 的值需要 5 个字节,包括长度字节。
BINARY_DOUBLE
BINARY_DOUBLE 是为 64 位,双精度浮点数字数据类型。每个 BINARY_DOUBLE 的值需要 9 个字节,包括长度字节。
在数字的列中,浮点数有小数精度。在 BINARY_FLOAT 或 BINARY_DOUBLE 的列中,浮点数有二进制的精度。二进制浮点数支持的特殊值无穷大和 NaN (不是数字)。
您可以指定列在表 2-4 范围内的浮点数。"数字文本"中定义了用于指定浮点数的格式。
Table 2-3 Floating Point Number Limits
Value
Binary-Float
Binary-Double
Maximum positive finite value
3.40282E+38F
1.79769313486231E+308
Minimum positive finite value
1.17549E-38F
2.22507485850720E-308
2.5 FLOAT类型
FLOAT类型也是NUMBER的子类型。
Float(n),数 n 指示位的精度,可以存储的值的数目。N 值的范围可以从 1 到 126。若要从二进制转换为十进制的精度,请将 n 乘以 0.30103。要从十进制转换为二进制的精度,请用 3.32193 乘小数精度。126 位二进制精度的最大值是大约相当于 38 位小数精度。
三. 日期类型
日期类型用于存储日期数据,但是并不是使用一般的格式(2012-08-08)直接存储到数据库的。
3.1 DATE类型
DATE是最常用的数据类型,日期数据类型存储日期和时间信息。虽然可以用字符或数字类型表示日期和时间信息,但是日期数据类型具有特殊关联的属性。为每个日期值,Oracle 存储以下信息: 世纪、 年、 月、 日期、 小时、 分钟和秒。一般占用7个字节的存储空间。
3.2 TIMESTAMP类型
这是一个7字节或12字节的定宽日期/时间数据类型。它与DATE数据类型不同,因为TIMESTAMP可以包含小数秒,带小数秒的TIMESTAMP在小数点右边最多可以保留9位
3.3 TIMESTAMP WITH TIME ZONE类型
这是TIMESTAMP类型的变种,它包含了时区偏移量的值
3.4 TIMESTAMP WITH LOCAL TIME ZONE类型
3.5 INTERVAL YEAR TO MOTH
3.6 INTERVAL DAY TO SECOND
四. LOB类型
内置的LOB数据类型包括BLOB、CLOB、NCLOB、BFILE(外部存储)的大型化和非结构化数据,如文本、图像、视屏、空间数据存储。BLOB、CLOB、NCLOB类型
4.1 CLOB 数据类型
它存储单字节和多字节字符数据。支持固定宽度和可变宽度的字符集。CLOB对象可以存储最多 (4 gigabytes-1) * (database block size) 大小的字符
4.2 NCLOB 数据类型
它存储UNICODE类型的数据,支持固定宽度和可变宽度的字符集,NCLOB对象可以存储最多(4 gigabytes-1) * (database block size)大小的文本数据。
4.3 BLOB 数据类型
它存储非结构化的二进制数据大对象,它可以被认为是没有字符集语义的比特流,一般是图像、声音、视频等文件。BLOB对象最多存储(4 gigabytes-1) * (database block size)的二进制数据。
4.4 BFILE 数据类型
二进制文件,存储在数据库外的系统文件,只读的,数据库会将该文件当二进制文件处理
五. RAW & LONG RAW类型
5.1 LONG类型
它存储变长字符串,最多达2G的字符数据(2GB是指2千兆字节, 而不是2千兆字符),与VARCHAR2 或CHAR 类型一样,存储在LONG 类型中的文本要进行字符集转换。ORACLE建议开发中使用CLOB替代LONG类型。支持LONG 列只是为了保证向后兼容性。CLOB类型比LONG类型的限制要少得多。 LONG类型的限制如下:
1.一个表中只有一列可以为LONG型。(Why?有些不明白)
2.LONG列不能定义为主键或唯一约束,
3.不能建立索引
4.LONG数据不能指定正则表达式。
5.函数或存储过程不能接受LONG数据类型的参数。
6.LONG列不能出现在WHERE子句或完整性约束(除了可能会出现NULL和NOT NULL约束)
官方文档描叙如下:
The use of LONG values is subject to these restrictions:
A table can contain only one LONG column.
You cannot create an object type with a LONG attribute.
LONG columns cannot appear in WHERE clauses or in integrity constraints (except that they can appear in NULL and NOT NULL constraints).
LONG columns cannot be indexed.
LONG data cannot be specified in regular expressions.
A stored function cannot return a LONG value.
You can declare a variable or argument of a PL/SQL program unit using the LONG datatype. However, you cannot then call the program unit from SQL.
Within a single SQL statement, all LONG columns, updated tables, and locked tables must be located on the same database.
LONG and LONG RAW columns cannot be used in distributed SQL statements and cannot be replicated.
If a table has both LONG and LOB columns, then you cannot bind more than 4000 bytes of data to both the LONG and LOB columns in the same SQL statement. However, you can bind more than 4000 bytes of data to either the LONG or the LOB column.
In addition, LONG columns cannot appear in these parts of SQL statements:
GROUP BY clauses, ORDER BY clauses, or CONNECT BY clauses or with the DISTINCT operator in SELECT statements
The UNIQUE operator of a SELECT statement
The column list of a CREATE CLUSTER statement
The CLUSTER clause of a CREATE MATERIALIZED VIEW statement
SQL built-in functions, expressions, or conditions
SELECT lists of queries containing GROUP BY clauses
SELECT lists of subqueries or queries combined by the UNION, INTERSECT, or MINUS set operators
SELECT lists of CREATE TABLE ... AS SELECT statements
ALTER TABLE ... MOVE statements
SELECT lists in subqueries in INSERT statements
5.2 LONG RAW 类型,能存储2GB 的原始二进制数据(不用进行字符集转换的数据)
5.3 RAW类型
用于存储二进制或字符类型数据,变长二进制数据类型,这说明采用这种数据类型存储的数据不会发生字符集转换。这种类型最多可以存储2,000字节的信息
六. ROWID & UROWID类型
在数据库中的每一行都有一个地址。然而,一些表行的地址不是物理或永久的,或者不是ORACLE数据库生成的。
例如,索引组织表行地址存储在索引的叶子,可以移动。
例如,外部表的ROWID(如通过网关访问DB2表)不是标准的ORACLE的rowid。
ORACLE使用通用的ROWID(UROWIDs)的存储地址的索引组织表和外表。索引组织表有逻辑urowids的,和国外表的外urowids,。UROWID这两种类型的存储在ROWID伪(堆组织的表的物理行id)。
创建基于逻辑的rowid在表中的主键。逻辑的rowid不会改变,只要主键不改变。索引组织表的ROWID伪UROWID数据类型。你可以访问这个伪列,你会堆组织表的ROWID伪(即使用一个SELECT ...ROWID语句)。如果你想存储的rowid索引组织表,那么你就可以定义一列的表型UROWID到列检索值的ROWID伪。
37. 常见的约束有哪些
Mysql数据库的约束类型有:主键约束(Primary Key),外键约束(Foreign Key),非空约束(Not Null),唯一性约束(Unique),默认约束(Default)。一.主键约束(Primary Key) 主键约束要求主键列的数据唯一,并且不能为空。主键分为两种类型:单字段主键和多字段联合主键。1.单字段主键在定义列的同时指定主键,语法规则:字段名 数据类型 Primary Key [默认值]
--------------------

在定义完成所有列之后指定主键,语法规则:[Constraint<约束名>] Primary Key [字段名]

-
一般在建表时我们会选择将主键放在所有列后。2.多字段联合主键主键由多个字段联合组成。语法规则:Primary Key[字段1,字段2,....,字段n]
二.外键约束(Foreign Key) 外键用来在两个表的
一般在建表时我们会选择将主键放在所有列后。
2.多字段联合主键
主键由多个字段联合组成。语法规则:Primary Key[字段1,字段2,....,字段n]

二.外键约束(Foreign Key)
外键用来在两个表的数据之间建立连接,它可以是一列或者多列。一个表可以有一个或者多个外键。一个表的外键可以为空,若不为空,则每一个外键值必须等于另一个表中主键的某个值。
外键的作用:保证数据应用的完整性。
主表(父表):对于两个具有关联关系的表而言,相关联字段中的主键所在的那个表即是主表。
从表(子表):对于两个具有关联关系的表而言,相关联字段中的外键所在的那个表即是从表。
创建外表的语法规则:[Constraint<外键名>]Foreign Key 字段名1[,字段名2,....] References<主表名> 主键列1 [,主键列2,....]
创建一个表test_1

定义数据表test_2,让它的主键deptId作为外键关联到的test_1的主键id,
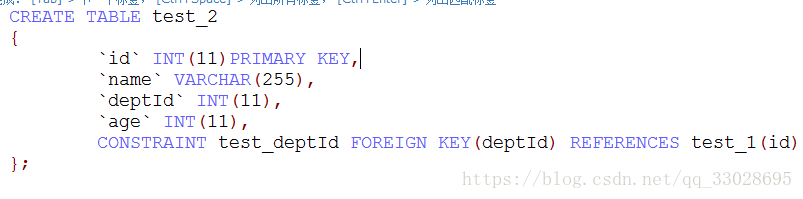
在表test_2上添加了名称为test_deptId的外键约束,外键名称为deptId,其依赖于表test_2的主键id.
三.使用非空约束(Not Null)
非空约束指字段的值不能为空。
非空约束 语法规则:字段名 数据类型 not null
四.唯一性约束(Unique)
唯一性约束要求该列唯一,允许为空,但是只能出现一个空值。唯一约束可以保证一列或者几列不出现重复值。
非空约束的语法规则
1.在定义完列之后直接指定唯一约束
字段名 数据类型 unique
2.在定义完所有列之后指定唯一约束
[Constraint<约束名>] Unique(<字段名>)
声明:Unique在表中可以有一个或者多个字段声明,而Primary Key,只能有一个。
五.默认约束(Default)(最简单)
默认约束指定某列的默认值。
语法规则: 字段名 数据类型 Dfault 默认值
38. 什么是序列
序列(SEQUENCE)是序列号生成器,可以为表中的行自动生成序列号,产生一组等间隔的数值(类型为数字)。
其主要的用途是生成表的主键值,可以在插入语句中引用,也可以通过查询检查当前值,或使序列增至下一个值。
创建序列需要CREATE SEQUENCE系统权限。
序列的创建语法如下: CREATE SEQUENCE 序列名 [INCREMENT BY n] [START WITH n] [{MAXVALUE/ MINVALUE n|NOMAXVALUE}] [{CYCLE|NOCYCLE}] [{CACHE n|NOCACHE}]; INCREMENT BY 用于定义序列的步长,如果省略,则默认为1,如果出现负值,则代表序列的值是按照此步长递减的。
START WITH 定义序列的初始值(即产生的第一个值),默认为1。
MAXVALUE 定义序列生成器能产生的最大值。选项NOMAXVALUE是默认选项,代表没有最大值定义,这时对于递增序列,系统能够产生的最大值是10的27次方;对于递减序列,最大值是-1。
MINVALUE定义序列生成器能产生的最小值 ...
39. 事务控制的四大特性
事务是由一步或者几步数据库操作序列组成的逻辑执行单元,这系列操作要么全部执行,要么全部放弃执行。
通俗的说的话,事务就是一件事情,要么成功执行到底,要么回到起点,什么都不做。
事物的特性(ACID)
原子性(Atomicity):正如原子时自然界最小颗粒,具有不可再分的特征一样。意思就是说,咱的事务是一个逻辑单元,不能再拆分了,比如整体的执行。
一致性(Consistency):事务执行的结果,必须使数据库从一个一致性状态,变到另一个一致性状态。比如说银行之间的转账,从A账户向B账户转入1000元。系统先减少A账户1000元,然后再为B账户增加1000元。如果全部执行成功的话,则数据库就处于一致性状态。如果仅仅A账户金额修改,B账户没有增加的话,那么数据库就处于不一致的状态。因此,一致性必须通过原子性来保证。
隔离型(Isolation):各个事务执行互不干扰,任意一个事务的内部操作对其他并发的事务都是隔离的。也就是说,并发执行的事务之间不能看到对方的中间状态。并发事务之间是不能互相影响的。
持久性(Durability):事务一旦提交,对数据所做的改变都要记录到存储器中,通常就是保存进物理数据库。
40. 数据库设计范式如何应用在数据库设计中
什么是数据库设计范式?
我们设计数据库的目的是什么?当然是为了我们使用起来方便,管理起来方便等等。这样,我们就需要一套科学的、规则的规范来满足它。
范式的英文名称是 Normal Form,它是英国人 E.F.Codd(关系数据库的老祖宗)在上个世纪70年代提出关系数据库模型后总结出来的,范式是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法。目前有迹可寻的共有8种范式,依次是:1NF,2NF,3NF,BCNF,4NF,5NF,DKNF,6NF。通常所用到的只是前三个范式,即:第一范式(1NF),第二范式(2NF),第三范式(3NF)。
数据库设计范式的好处和不足
好处:数据库的设计范式是数据库设计所需要满足的规范,刚刚也说过,它是为了满足我们使用和管理的需要,由此可见,它是对原先数据的优化,使我们处理数据更为便利。
不足:数据往往种类繁多,而且每种数据之间又互相关联,因此,在设计数据库时,所需要满足的范式越多,那表的层次及结构也就越复杂,最终造成数据的处理困难。这样,还不如不满足这些范式呢。所以在使用范式的时候也要细细斟酌,是否一定要使用该范式,必须根据实际情况做出选择。一般情况下,我们使用前三个范式已经够用了,不再使用更多范式,就能完成对数据的优化,达到最优效果。
一、第一范式(1NF)
规范定义:第一范式是指数据库表中的每一列都是不可分割的基本数据项;同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
有两个点:实体的属性的不可分割性(原子性)、实体的属性的不重复性 / 不能有多个值。
解释一下实体和属性:就好比一个客户(实体),他有姓名(属性),年龄(属性),电话(属性),地址(属性)等属性。说通俗点就是表中的一行数据。
1.实体的属性的不可分割性(原子性)
这个说的就是实体的属性不可再分,就好比一个人的电话号码分为三种:手机号码、家庭电话以及办公电话。这样,我们在设计表时,就不能这样设计:

而应该这样设计:

2.实体的属性的不重复性 / 不能有多个值(其实就是一个属性栏里不能出现多个值,毕竟同一个属性栏中的值的属性也必然是一样的)
即不能出现多个或者是重复的实体的属性。注意,这里是属性的不重复或单一性,什么叫属性不重复?打个比方,如手机号码、家庭电话以及办公电话三者都属于电话号码这一属性,而当我们在设计表时,在电话号码这一属性中就可能会出现这个人的三个号码,刚也说了,这三个号码都属于电话号码这一属性,因此属于相同属性,这样就违反了实体的属性的不重复性这一特性。又因为三个号码出现在了同一个属性中,因此也就同时违反了实体的属性不能有多个值这一特性。
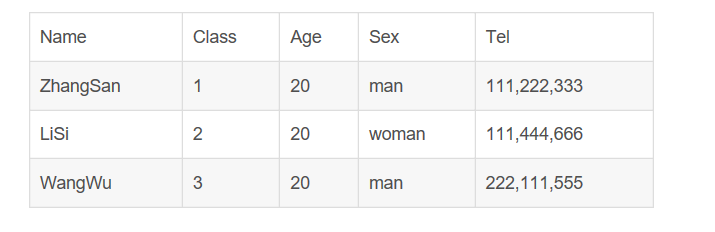
例如:
![{UTQN@QUNVGHX]TDNPZ}(07[4]](https://img2018.cnblogs.com/blog/1763268/201908/1763268-20190812200226542-1879790774.png "{UTQN@QUNVGHX]TDNPZ}(07[4]")
显然,我们可以看到,Tel这一栏存放的是客户的联系电话,但是对于每个客户而言,他们都具有三个电话(手机号码、家庭电话以及办公电话),这样,我们在设计时就不能将这三个相同的属性放在同一个属性列表当中,因此,上面这张表违反了数据库设计的第一范式。具体解决方案如下:

1NF是关系模式应具备的最起码的条件,如果数据库设计不能满足第一范式,就不能被称为关系型数据库。也就是说,只要是关系型数据库,就一定要满足第一范式。
二、第二范式(2NF)
是在第一范式( 1NF) 的基础上建立起来的,即满足第二范式( 2NF)必须先满足第一范式( 1NF)。
规范定义:如果关系模型R为第一范式,并且数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖,即符合第二范式。R中的每一个非主属性完全函数依赖于R的某个候选键,则称R为第二范式(如果A是关系模式R的候选键的一个属性,则称A是R的主属性,否则称A是R的非主属性)。
主属性:存在于所有候选键中的属性,称之为主属性。
候选键(候选关键字段):就是可以区别一个个实体的最少属性组合,是每个实体的唯一标识。一个表可能有多个候选键,从这些候选键中选择一个作为主键。
部分函数依赖:一个属性与另一个属性不完全相关。
完全函数依赖:一个属性与另一个属性完全相关。(下面会详细解释)
比如,一个学生信息表,其中每一个学生都拥有Id,Name,Age,Sex,Add等属性,我们假设Id存放的是学生的身份证号码,这样Id就可以作为每个学生的唯一标识,那么这个Id就可以被称为候选键。又因为它作为每个学生的唯一标识,那么我们可以理解为它与其他属性完全相关,这就是完全函数依赖。
这时,我们假设Id和Name作为学生的唯一标识,也就是候选键,这样做显然是不行的。因为即使去掉Name,我们也同样可以确定一个学生,也就是说,作为候选键的属性组合,必须都有自己的作用。而且,假设又出现了一个字段(属性)银行卡号,那么,这个银行卡号仅与Id有关,而不与Name相关,这样,就出现了非关键字段对候选关键字段的部分函数依赖,那么这个属性组合是不符合要求的,应当重新选择。
举个例子:
化工![@T]1$@)%6XW(7NNCJI[%CU4](https://img2018.cnblogs.com/blog/1763268/201908/1763268-20190812200257935-896578745.png "@T]1$@)%6XW(7NNCJI[%CU4")
99
该表中一个学生可以选多门课,一门课有多个学生,学生姓名可能出现重名。因此学号和课程号可以唯一确定一条记录,因此用学号和课程号做主键。表中姓名、专业通过学号就能唯一确定,但是课程名却只与课程号有关,这样就形成了部分函数依赖,违背了第二范式。
违背第二范式将产生数据信息冗余和数据更新异常的问题。
1.数据信息冗余:出现了重复的课程号-课程名。
2.数据更新异常:假如现在有一门“计算机导论”要加入表中,但是由于没有学生考这一门课,那么这么课程就不能加入到表中(只有课程号和课程名而没有其他信息)。
解决办法:将其分为三种关系模式:学生表、课程表和成绩表
学生表:


![MUPT)]S74@XNKHVHH@`QM_G](https://img2018.cnblogs.com/blog/1763268/201908/1763268-20190812205529737-779760524.png "MUPT)]S74@XNKHVHH@`QM_G")
三、第三范式(3NF)
规范定义:在满足第二范式的基础上,在实体中不存在非主键属性传递函数依赖于主键属性。
传递函数依赖:A依赖于B,B依赖于C,就可以说A依赖C。
第三范式具有如下特征:
1. 每一列(属性)只有一个值。(1NF)
2. 每一行都能区分。(2NF)
3. 每一个表都不包含其他表已经包含的非主关键字信息。通俗的说:就是表中每一列都要与主键直接相关,而不是间接相关。
就比如上面的例子中,在成绩表中可以出现学号,但是不能出现与学号相关的其他信息,就是这个意思。
---------------------
版权声明:本文为CSDN博主「史博辉的开发日记」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/baidu_38760069/article/details/81162496


{kind=link}