

kafka糊弄学(核心知识碎片)
之前讲过一些kafka的api与简单使用,但是在一些大公司和面试高级工程师岗位过程中发现kafka有很多薄弱点需要加强。这里重点学习一下原理,还有集群部署以及宕机恢复还有实际使用中的一些问题。
以下图文主要转载自尚硅谷kafka课件,链接: https://pan.baidu.com/s/17XOeCBYdyfNqWJPxb_dMsA 提取码: 5sp9
一、kafka基础知识
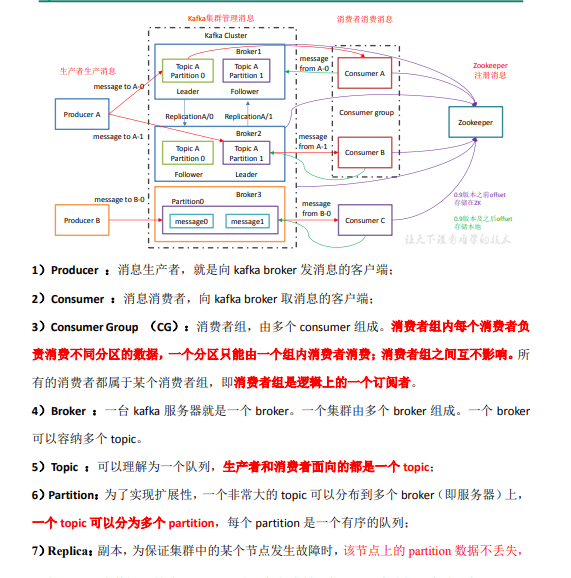

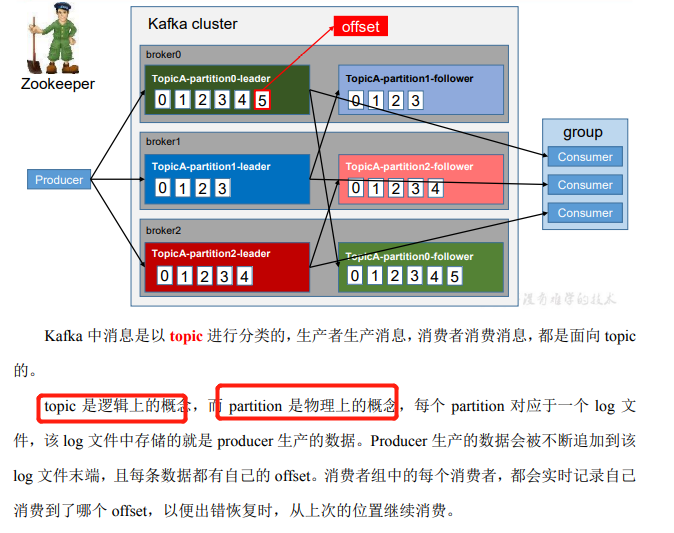
kafka提高并发的方式主要是通过增加分区,分区默认采用round-robin算法,这里不赘述,因为一般面试不问这个。
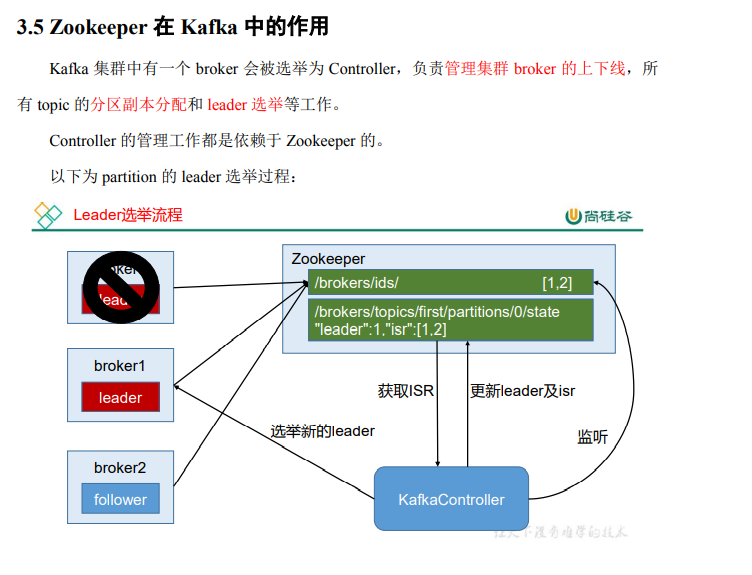
下面这个是面试中经常问到的

这里蛮记一下ISR

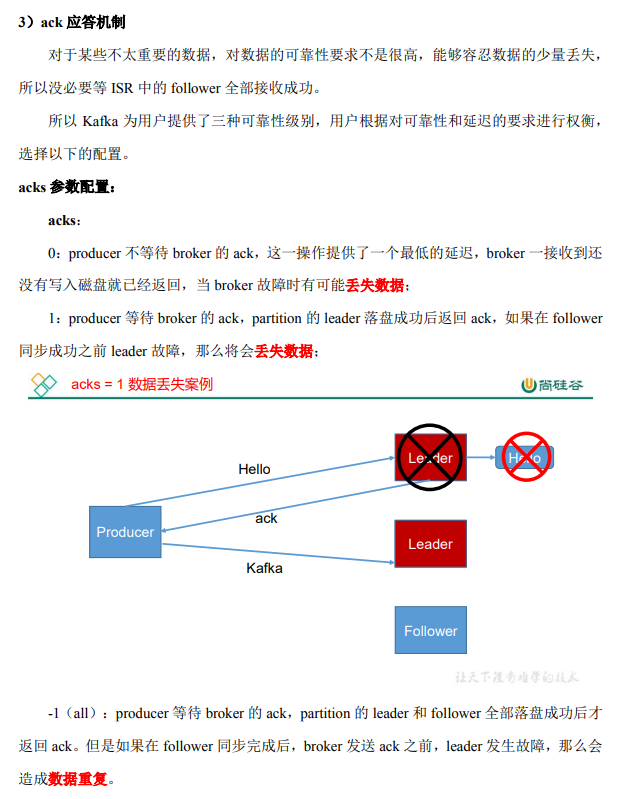
这里的leader是指partition的副本有分为lead和follw
简单理解就是ack有三个等级,一个是不等待broker相应,如果broker挂了,消息就丢失了;第二个是等待leader落盘后,答复,但是如果leader挂了就没有。
第三种如果是在follw同步完成后,broker发送ack之前,leader再次挂了,会造成数据重复。如下图
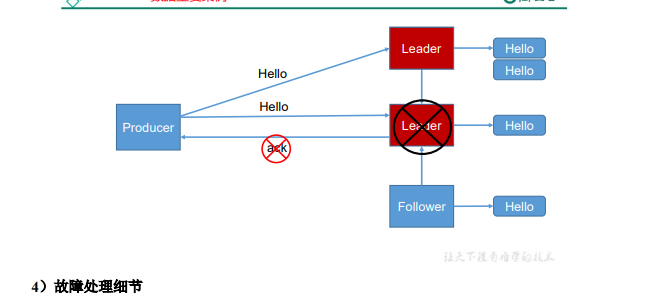
接下来这个比较绕,可能一些变态面试官会问这个。
就是
follw挂了如何恢复:挂了时候会被踢出ISR,这时候会记录一个所有副本最低的offset,恢复后,将自身比这个offset多的改成一样。然后再从leader获取。
leader挂了怎么恢复:首先选出一个新的leader,这时候所有follwer会将全集的最低offset以上的截掉,改成和新的leader一样。最重要的是,这里只保证了数据一致性,没法保证消息不丢失

简单用人话讲就是可以保证不丢失,但是不重复。可以保证不重复,但是不能保证不丢失。当消息非常重要的时候,必须发送成功必须消费时候,提供提供
开始类似全局事务提供一个pid,但是这个pid重启就会变化,也没法保证不同parttion有不通。所以在使用的时候,最后指定某个分区。






还有一部分讲producer拦截器的,这里省略一般考不到。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现