

史上最差的kafka教程第一天
Kafka是分布式发布-订阅消息系统,它最初由 LinkedIn 公司开发,使用 Scala语言编写,之后成为 Apache 项目的一部分。在Kafka集群中,没有“中心主节点”的概念,集群中所有的服务器都是对等的,因此,可以在不做任何配置的更改的情况下实现服务器的的添加与删除,同样的消息的生产者和消费者也能够做到随意重启和机器的上下线。
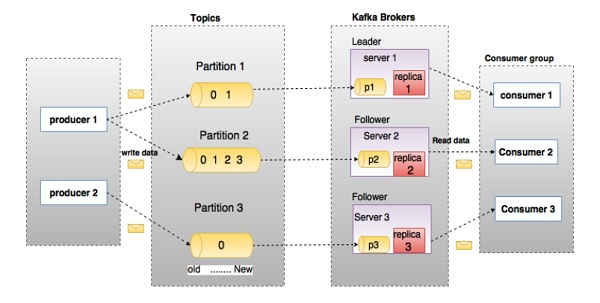
一.No 组件和说明
Topics(主题)
属于特定类别的消息流称为主题。 数据存储在主题中。
主题被拆分成分区。 对于每个主题,Kafka保存一个分区的数据。 每个这样的分区包含不可变有序序列的消息。 分区被实现为具有相等大小的一组分段文件。
Partition(分区)
主题可能有许多分区,因此它可以处理任意数量的数据。
Partition offset(分区偏移)
每个分区消息具有称为 offset
的唯一序列标识。
Replicas of partition(分区备份)
副本只是一个分区的备份
。 副本从不读取或写入数据。 它们用于防止数据丢失。
Brokers(经纪人)
1、Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为 broker。
2、Message在Broker中通Log追加的方式进行持久化存储。并进行分区(patitions)。
3、为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数。
4、Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。Message消息是有多份的。
5、Broker不保存订阅者的状态,由订阅者自己保存。
6、无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除。
7、消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息。
Kafka Cluster(Kafka集群)
Kafka有多个代理被称为Kafka集群。 可以扩展Kafka集群,无需停机。 这些集群用于管理消息数据的持久性和复制。
Producers(生产者)
生产者是发送给一个或多个Kafka主题的消息的发布者。 生产者向Kafka经纪人发送数据。 每当生产者将消息发布给代理时,代理只需将消息附加到最后一个段文件。 实际上,该消息将被附加到分区。 生产者还可以向他们选择的分区发送消息。
Consumers(消费者)
Consumers从brokers处读取数据。 消费者订阅一个或多个主题,并通过从代理中提取数据来使用已发布的消息。
一个分区最多只能被同一个消费者组下的一个消费者消费。
Leader(领导者,主节点)
Leader
是负责给定分区的所有读取和写入的节点。 每个分区都有一个服务器充当Leader。
Follower(追随者,从节点)
跟随领导者指令的节点被称为Follower。 如果领导失败,一个追随者将自动成为新的领导者。 跟随者作为正常消费者,拉取消息并更新其自己的数据存储。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现