
yolov8训练结果分析
1.训练结果
2.weights
里面有两个权重文件:best.pt和last.pt。best为训练的最好的一次权重,用于预测。last为最后一次训练的权重。
3.args.yaml(记录了任务、模型、轮数、配置文件、是否保存等一些文件)
4.confusion_matrix.png(混淆矩阵)
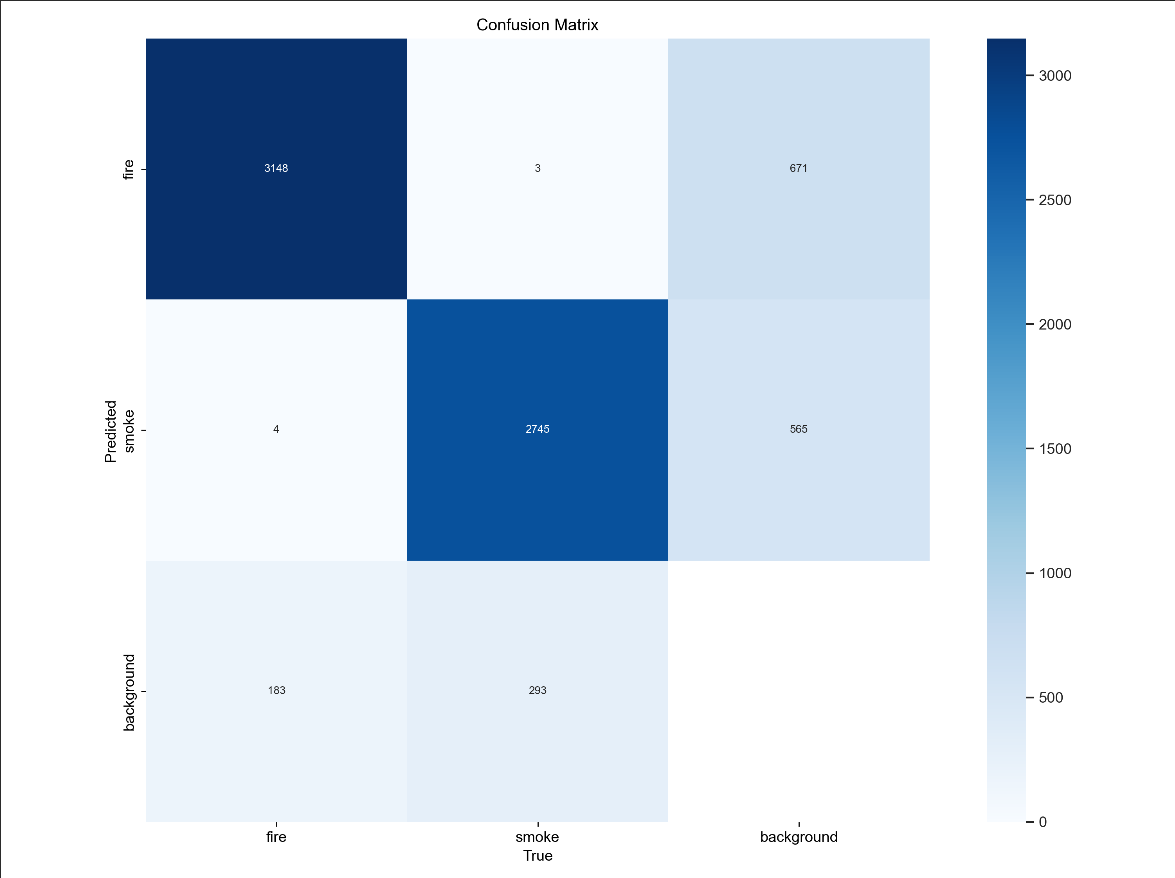
行是预测结果,列是真实结果。第一列之和是fire数量,被分别预测为fire,smoke,background。
5.confusion_matrix_normalized.png
里面是预测结果数量的占比
6.F1_curve.png
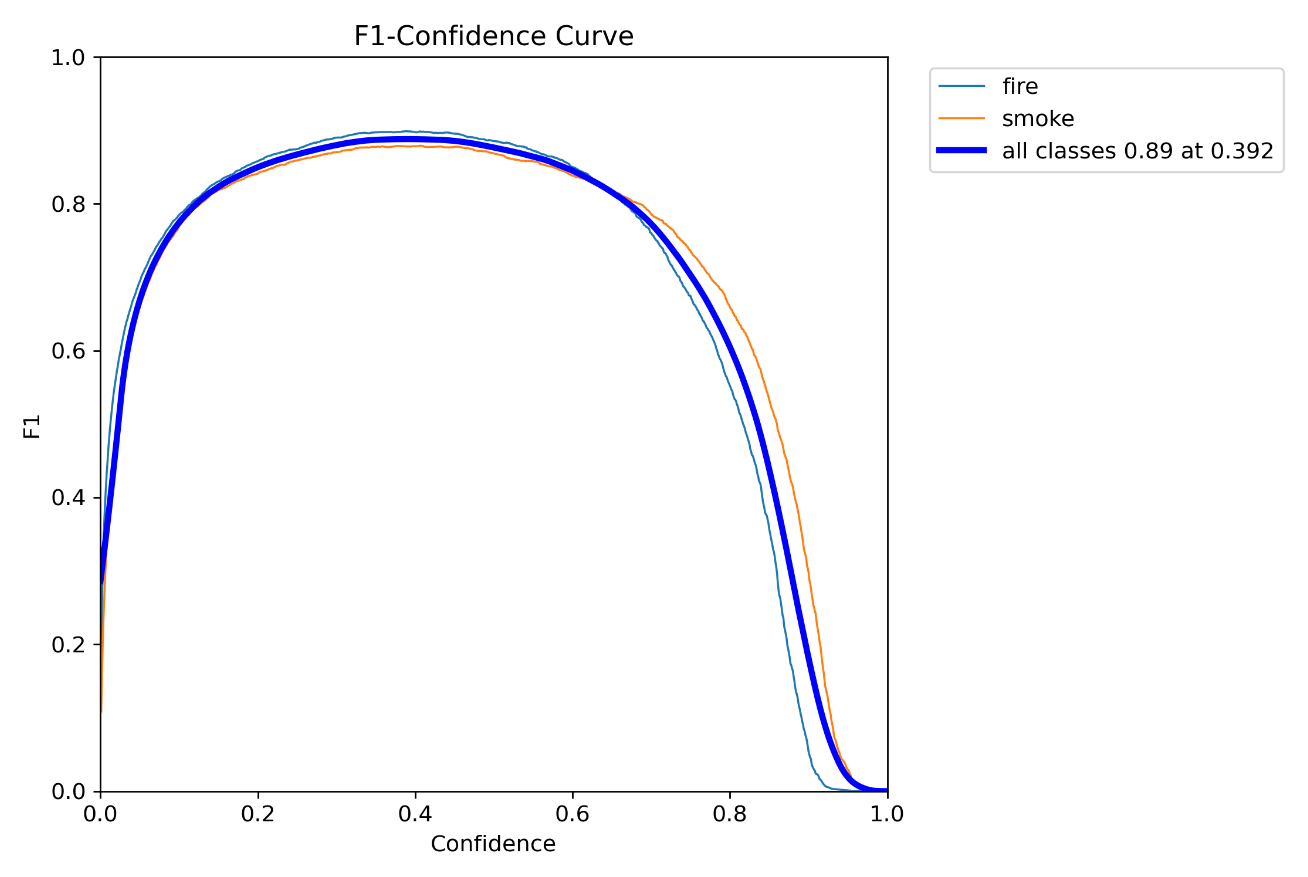
F1曲线,被定义为查准率和召回率的调和平均数最大为1,其中1是最好,0是最差。蓝色线是本次训练的模型,它在置信度为0.392时,F1分数最高为0.89
7.labels.jpg
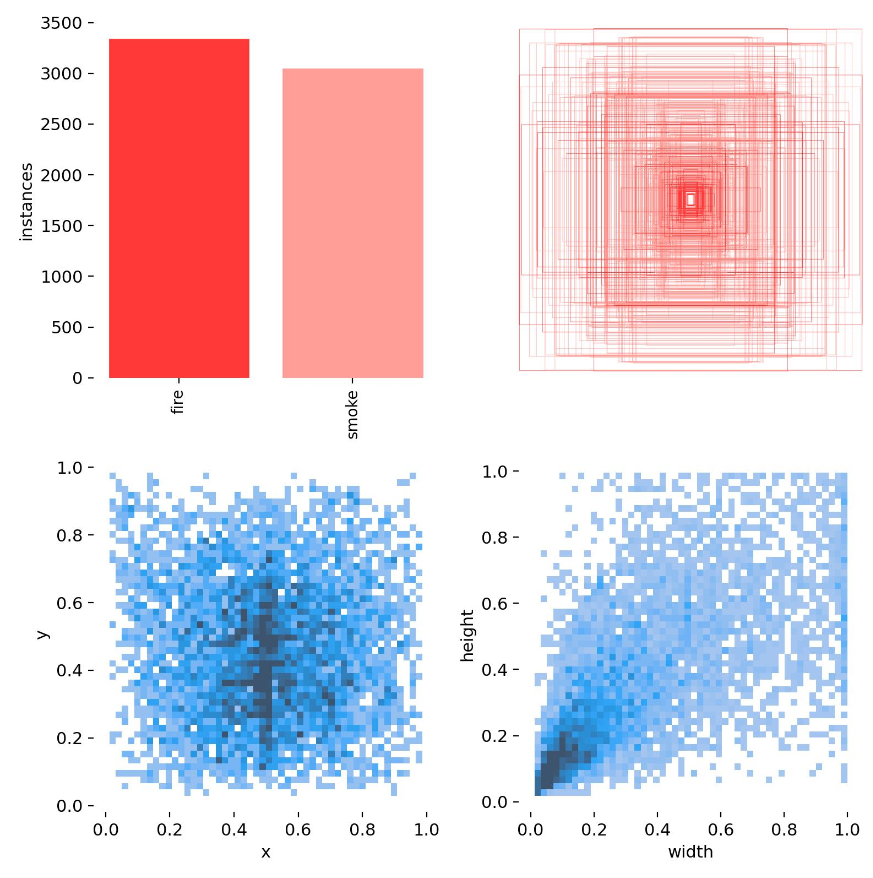
第一个图是训练集得数据量,每个类别有多少个
第二个图是框的尺寸和数量
第三个图是中心点相对于整幅图的位置
第四个图是图中目标相对于整幅图的高宽比例
8.labels_correlogram.jpg
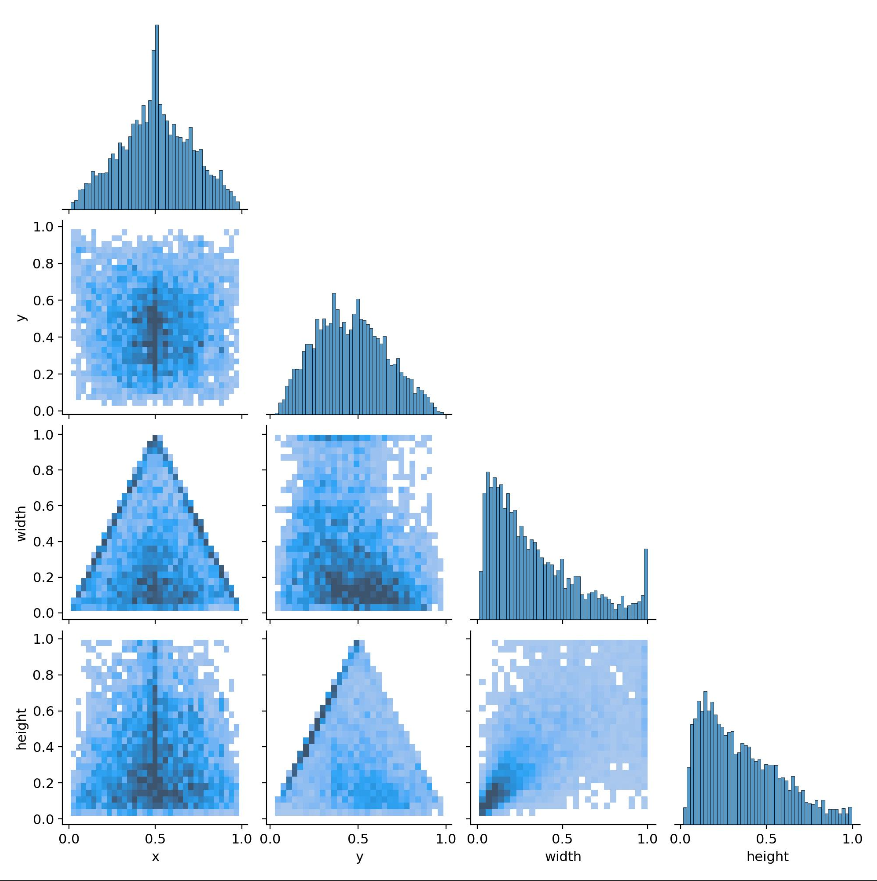
颜色矩阵图,它展示了目标检测算法在训练过程中预测标签之间的相关性。
9.P_curve.png(置信度阈值 - 准确率曲线图)
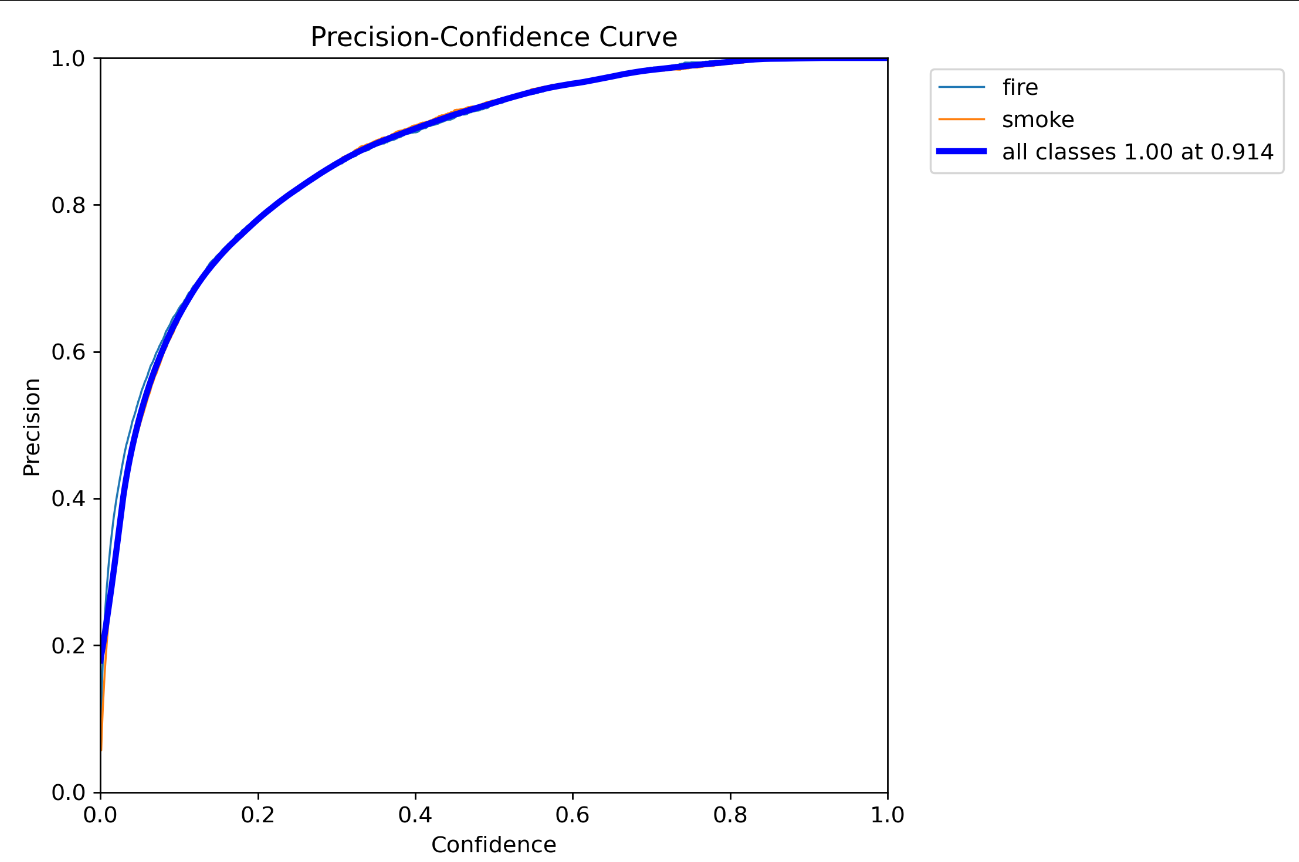
横坐标为置信度,纵坐标为精度(也可以是召回率)。曲线的形状和位置可以反映出检测器的性能和稳定性。
10.PR_curve.png(精确率和召回率的关系图)
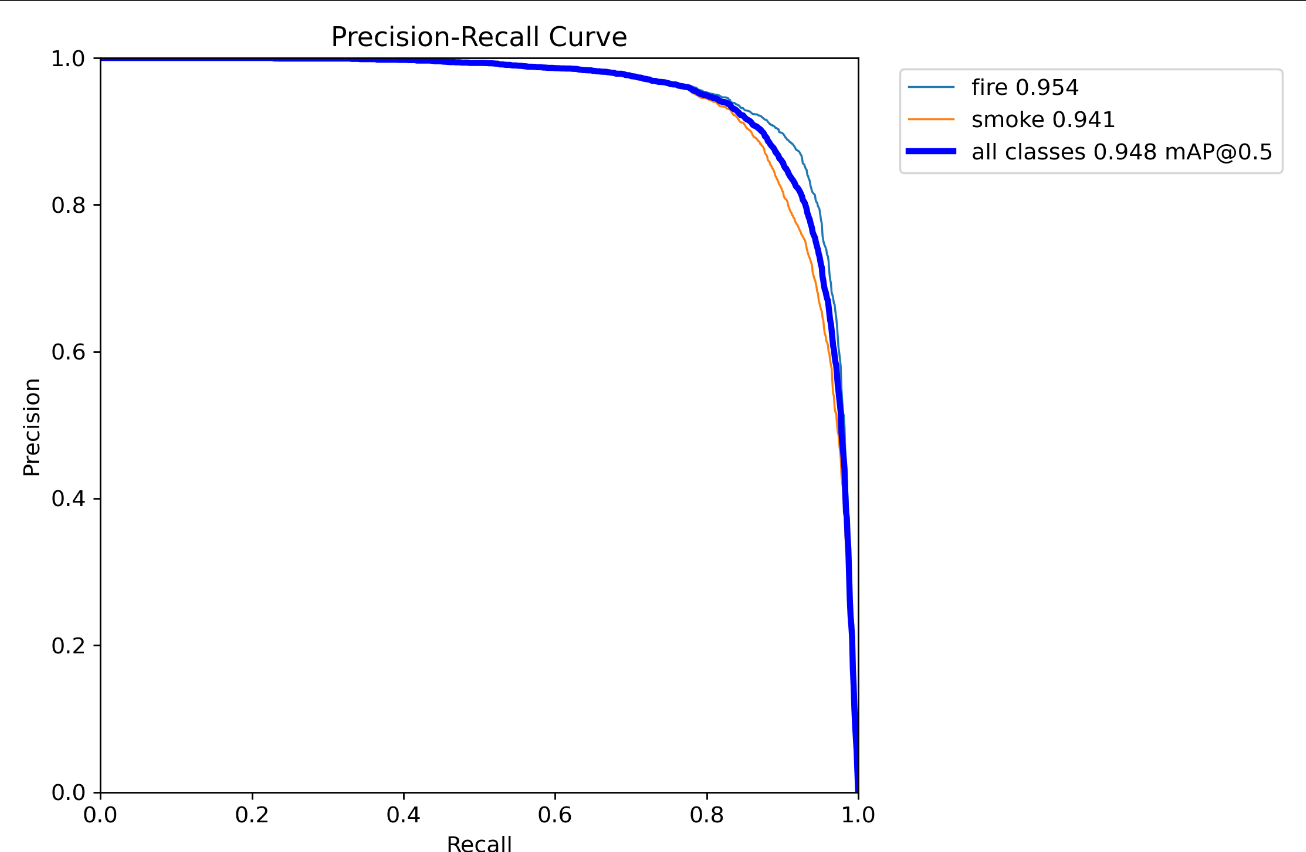
改图表示不同阈值下,精确率与召回率之间的关系曲线。
测为正例的样本中真正为正例的比例,召回率(Recall)表示真正为正例的样本中被预测为正例的比例。
在PR Curve中,横坐标为召回率,纵坐标为精确率。一般而言,当召回率较高时,精确率较低;当精确率较高时,召回率较低。而PR Curve则体现了这种“取舍”关系。当PR Curve越靠近右上角时,表示模型在预测时能够同时保证高的精确率和高的召回率,即预测结果较为准确。相反,当PR Curve越靠近左下角时,表示模型在预测时难以同时保证高的精确率和高的召回率,即预测结果较为不准确。
11.R_curve.png(置信度阈值 - 召回率曲线图)
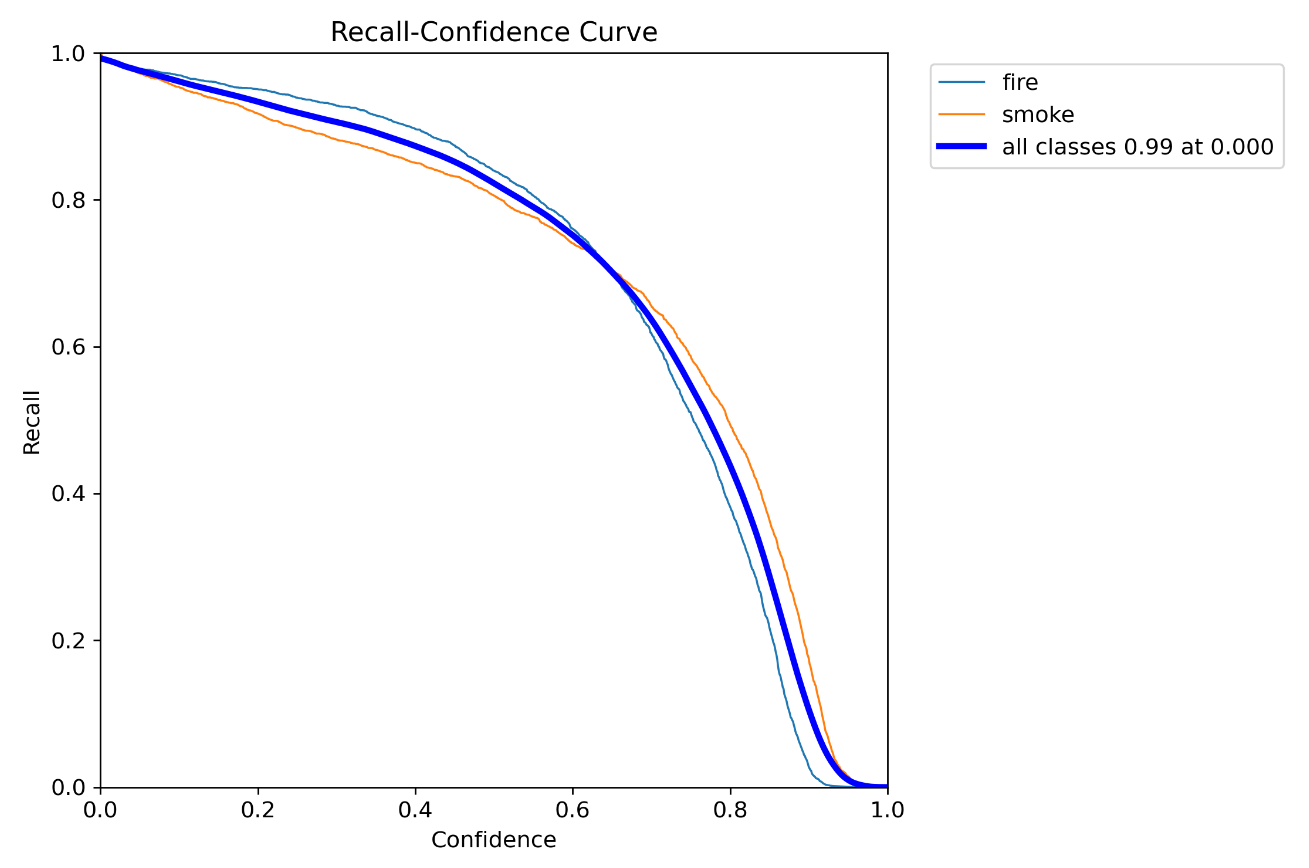
是目标检测中用于评估算法性能的一种方法。它是在不同置信度阈值下,召回率的变化情况的可视化表示。
12.results.csv
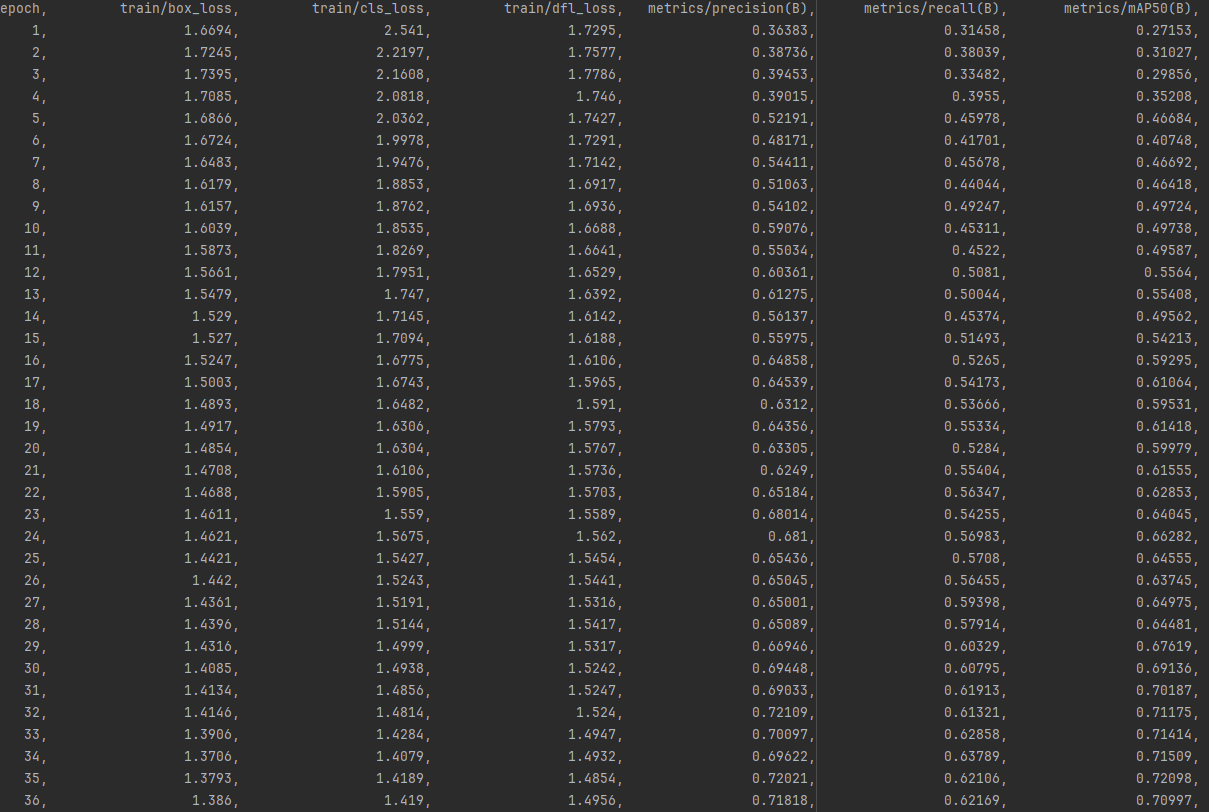
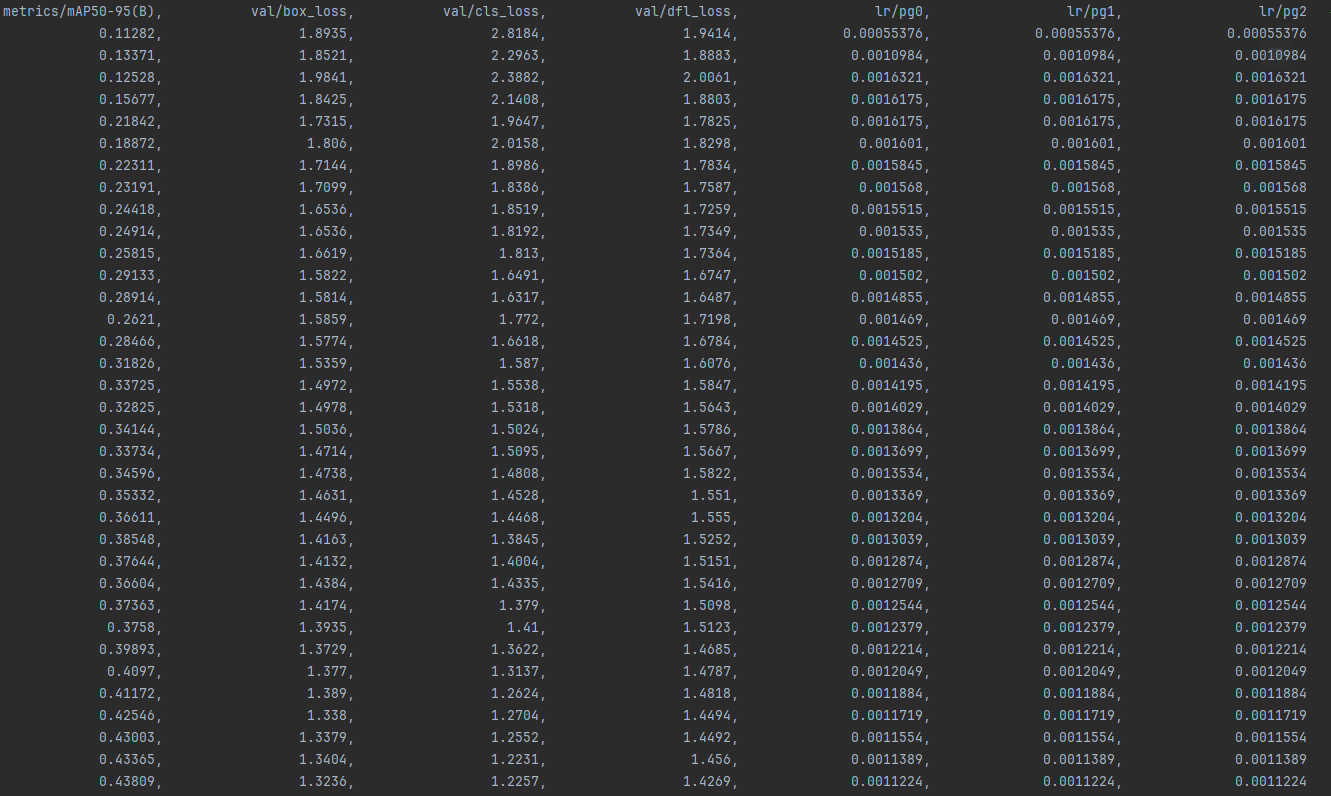
box_loss :用于监督检测框的回归,预测框与标定框之间的误差(CIoU)。
cls_loss :用于监督类别分类,计算锚框与对应的标定分类是否正确。
dfl_loss(Distribution Focal Loss):这个函数与GIOU loss一样,都是用来优化bbox的。
Precision:精度(找对的正类/所有找到的正类);
Recall:真实为positive的准确率;
Precision:精度(找对的正类/所有找到的正类);
Recall:真实为positive的准确率;
mAP50-95:表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP;
mAP50:表示在IoU阈值为0.5时的mAP值变化曲线
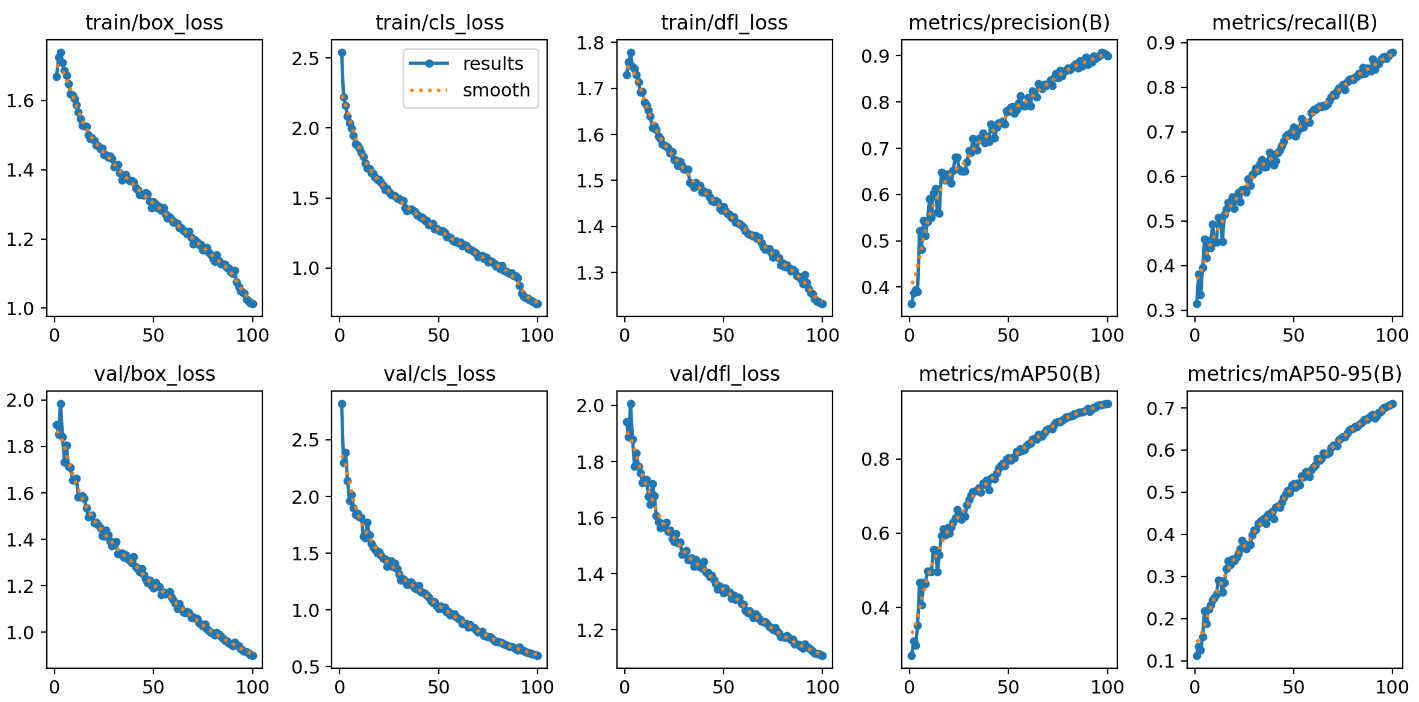
13.results.png(results.csv图示)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号