


Hadoop 3.3.2 集群安装
一、虚拟机环境准备
|
系统 |
主机 |
地址 |
hadoop版本 |
jdk版本 |
|
centos9 |
hadoop01 |
10.211.55.4 |
3.2.2 |
1.8.0_322 |
|
centos9 |
hadoop02 |
10.211.55.7 |
3.2.2 |
1.8.0_322 |
|
centos9 |
hadoop03 |
10.211.55.6 |
3.2.2 |
1.8.0_322 |
二、分别在三台虚拟机中进行hosts 配置 ,配置内容如下
1 2 3 4 5 | 10.211.55.4 hadoop0110.211.55.7 hadoop0210.211.55.6 hadoop03 |
三、分别在三台虚拟机中设置用户及免密登陆
新增用户
groupadd hadoop useradd -d /home/hadoop -g hadoop -s /bin/bash -m hadoop
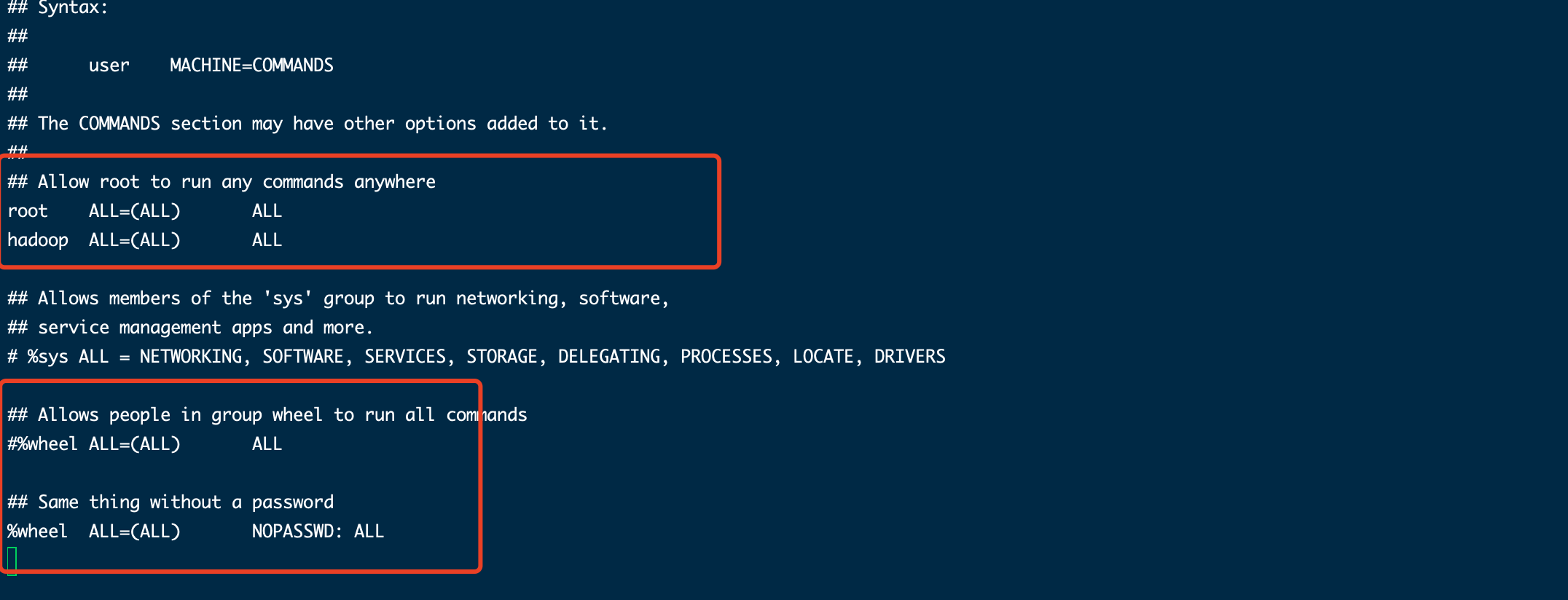
免密登陆方式一:
visudo
#在文中root行下添加hadoop行
hadoop ALL=(ALL) NOPASSWD:ALL

免密登陆方式二:

visudo #在文中root行下添加hadoop行 hadoop ALL=(ALL) ALL
#注释掉wheel用户组需要登陆的行
#%wheel ALL=(ALL) ALL
#打开wheel用户组免密登陆
%wheel ALL=(ALL) NOPASSWD: ALL
#将hadoop用户添加到wheel用户组
gpasswd -a hadoop wheel
修改主机的hostname配置,并重启
#第一台注解配置 hostnamectl set-hostname hadoop01 #重启 reboot #查看是否更改成功 hostname #第二台注解配置 hostnamectl set-hostname hadoop01 #重启 reboot #查看是否更改成功 hostname #查看是否更改成功 username #第三台注解配置 hostnamectl set-hostname hadoop01 #重启 reboot #查看是否更改成功 hostname
关闭防火墙
1 2 3 | 关闭防⽕墙: systemctl stop firewalld查看状态: systemctl status firewalld开机禁⽤: systemctl disable firewalld |
免密登陆配置
#切换到hadoop用户 su hadoop #生城公钥,先查看本地有没有生成密钥,如果有的话,再次生成会影响前面已经设置好的,用下面这条命令就可以 cat ~/.ssh/id_rsa.pub #如果没有的话,输入下面的命令来在本机上生成公钥和私钥 ssh-keygen -t rsa #把公钥复制到远程主机上,此处主要是将三台虚拟机的公钥相互复制,以支持三台服务器可以使用hadoop账号使用ssh直接登录 ssh-copy-id -i ~/.ssh/id_rsa.pub root@ip地址
四、集群规划
注意1:NameNode和SecondaryNameNode不要部署在同一台服务器
注意2:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode部署在同一台服务器上
|
|
hadoop01 |
hadoop02 |
hadoop03 |
|
HDFS
|
DataNode |
DataNode |
DataNode |
|
NameNode |
|
SecondaryNameNode |
|
|
YARN
|
NodeManager |
NodeManager |
NodeManager |
|
|
ResourceManager |
|
五、开始安装
#下载解压 midir -p /opt/module /opt/software cd /opt/software wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz tar -xzvf hadoop-3.3.2.tar.gz -C /opt/module cd /opt/module mv hadoop-3.3.2.tar.gz hadoop # 移出旧版本JDK yum remove -y `yum list installed | grep java | awk '{print $1}'` yum remove -y `yum list installed | grep jdk | awk '{print $1}'` # 安装JDK1.8 yum install -y java-1.8.0-openjdk*
配置环境变量
vim /etc/profile
内容如下:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export HADOOP_HOME=/opt/module/hadoop
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
编辑core-site.xml
vim /opt/module/hadoop/etc/hadoop/core-site.xml
内容如下:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop/data/tmp</value> </property> </configuration>
编辑hdfs-site.xml
vim /opt/module/hadoop/etc/hadoop/hdfs-site.xml
内容如下:
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop03:50090</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/module/hadoop/dfs/name</value> <description> Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently. </description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/module/hadoop/dfs/data</value> <description> Comma separated list of paths on the localfilesystem of a DataNode where it should store itsblocks. </description> </property> </configuration>
编辑yarn-site.xml
vim /opt/module/hadoop/etc/hadoop/yarn-site.xml
内容如下:
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop02</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
编辑workers
vim /opt/module/hadoop/etc/hadoop/workers
内容如下:
hadoop01
hadoop02
hadoop03
编辑hadoop-env.sh
vim /opt/module/hadoop/etc/hadoop/hadoop-env.sh
内容如下:
export HDFS_NAMENODE_USER=hadoop export HADOOP_LOG_DIR=${HADOOP_HOME}/logs export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_HOME=/opt/module/hadoop export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
六、启动
在hadoop01服务器使用一下命令
start-all.sh
在hadoop02服务器执行命令:
start-yarn.sh
在各个节点使用jps命令查看状态
使用一下脚本查看所有节点状态
#!/bin/bash # 执行jps命令查询每台服务器上的节点状态 echo ======================集群节点状态==================== for i in hadoop01 hadoop02 hadoop03 do echo ====================== $i ==================== ssh jachin@$i 'jps' done echo ======================执行完毕====================
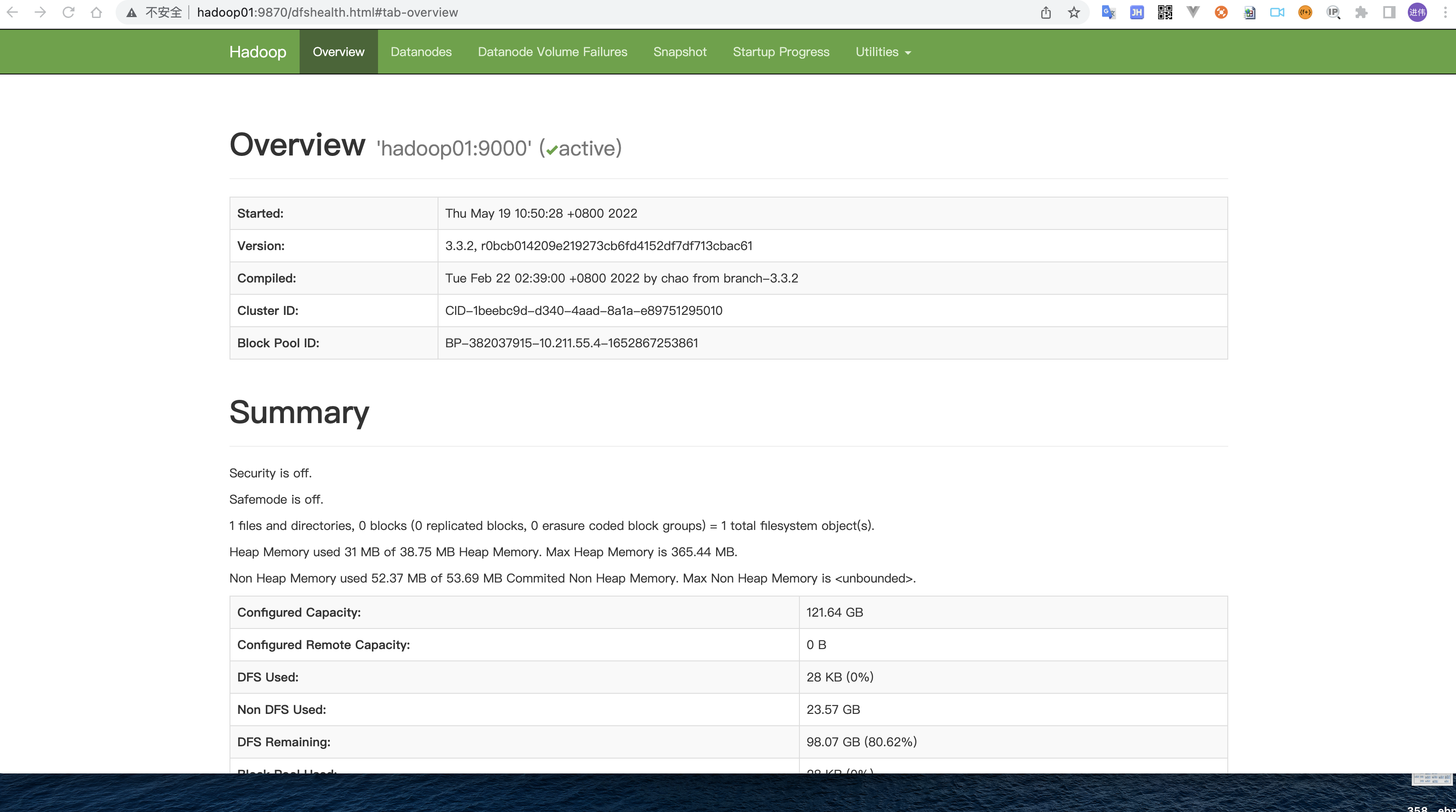
检查是否启动成功:
http://hadoop01:9870/dfshealth.htm


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构